
基于HBase的大数据架构下负载平衡技术
2021-06-29 06:36:56姜罕盛武国良赵玉娟
计算机与现代化 2021年6期
雷 鸣,姜罕盛,武国良,赵玉娟,梁 健
(天津市气象局信息中心,天津 300074)
0 引 言
随着大数据技术的发展,数据规模在网络中不断增加,使得负载均衡问题日益突出[1-6]。而负载均衡技术是伴随集群而出现的,其定义是指所用服务器平均资源的利用率达到均衡。透过负载均衡技术完成资源利用率的平衡,即:全部物理服务器的内存利用率、CPU、网络宽带等的利用率基本上是一致的[7]。因为负载均衡是集群效率提高的关键,往往会影响整个集群的性能。与此同时,大数据所具有的计算数据的巨大性与灵活性等,也常常增加了管理难度[8-10]。因此,在实际当中,必须采取有效而合理的资源调度策略,并调整负载均衡来充分保障云计算的高性能和高可靠性[11]。
目前,负载均衡技术实现的案例有很多,如:孙兰芳等人[12]利用服务质量降价、准入控制等方法达到动态负载均衡,然而其处理性能较差,仅能处理在某算子所处节点可处理的窗口范围;Ghadah等人[13]负载均衡的实现是透过利用集群节点上的分布算子提供的伸缩性实现的。但是该方法在数据规模和类型不断增加的情况下,会出现处理能力不足的问题,最终会导致数据流拥塞的问题;李梓杨等人[14]利用深度优先法,将数据流节点看作小的单元,从源节点向上发送到更高层节点,从首层节点再继续转发到目的节点,最终利用贪心技术选取最空闲链路。但该方法仅适合规模较小的体系,因为它忽略了整个体系的负载分布。相似算法还有很多[15-20],但除了在气象模式预报中应用之外,罕有针对气象行业的负载平衡算法应用研究[21-23]。
气象行业的数据访问,具有自己独特的访问特点:用户往往会集中于某段时间内大量集中并发访问。同时,其他闲散时间,有时也存在着少用户,但却是长序列大数据量的访问情况。
本文针对天津省级气象大数据服务中心,提出一种基于大数据下的负载均衡策略,该策略能够较好地解决系统大量并发访问、长序列和服务器单点故障问题,提高系统的效率性、稳定性和可靠性。负载均衡技术通过负载均衡集群(软负载)实现。
1 系统物理架构设计
目前,天津省级气象大数据服务中心的私有云存储主要由2个部分构成:虚拟机和物理机。全部服务器共计25台,其中物理机为7台,其余则为虚拟机。其具体设计为3台HBase数据库物理机,4台GBase数据库物理机,其余则均为虚拟机,分别设置如下:1台HBase数据接口服务器,2台HBase数据采集服务器,1台图形产品接口服务器,3台数据处理服务器,1台页面服务器,6台GBase数据库服务器集群,1台综合数据库服务器,1台测试服务器,2台APP数据推送服务器,1台共享网BBS服务器。整个系统架构设计如图1所示。
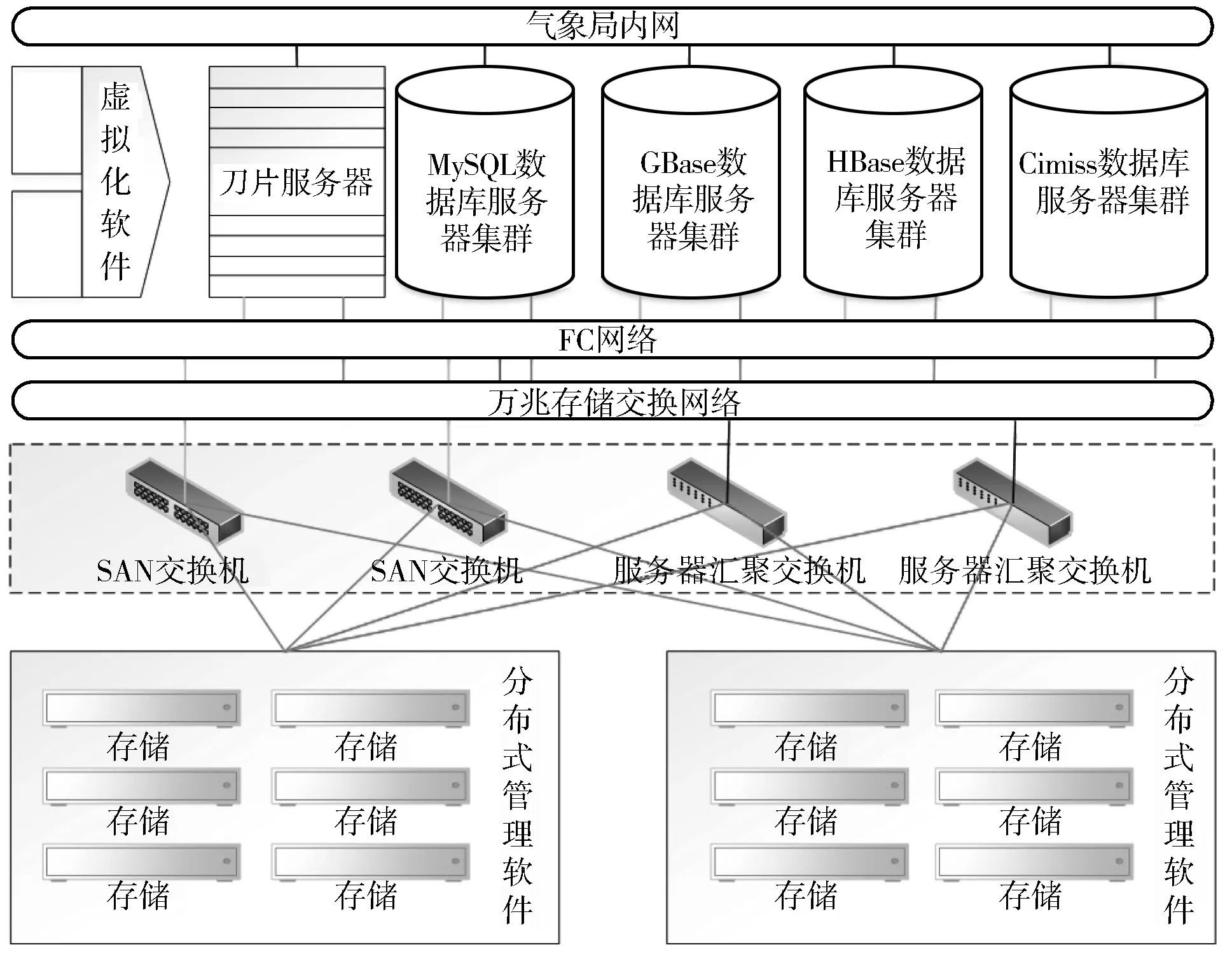
图1 系统物理架构设计图
2 基于HBase的非结构化数据存储
气象数据一般分为结构化数据和半/非结构化数据。结构化数据处理相对简单,可以直接通过分布式关系型数据库GBase进行处理。而对于各类服务产品、泛气象数据等半/非结构化数据,其结构化程度低,数据大小不定,数据参数一致性低,采用通用的结构化存储方式,会导致数据在存取方面出现问题,无法满足实际业务需要。故采用非结构化HBase数据库进行存储。
HBase是一种比较适合的选择。首先它的数据由HDFS做了数据冗余,具有较好的集群安全性,以及服务于海量数据的能力。其次HBase本身的数据读写服务没有单点的限制,服务能力可以随服务器的增长而线性增长,达到几十上百台的规模。同时,LSM-Tree模式的设计让HBase的写入性能非常良好,单次写入通常在1 ms~3 ms内即可响应完成,且性能不随数据量的增长而下降。
逻辑上,HBase的数据存储于表中,其表是由列与行构成,每行则由任意多的列与一个可排序的主键组成,列又归属于不同的列族。HBase是面向列的稀疏存储,其列族是固定不变的,在创建表时被定义,相当于表结构。HBase将同一个列族下的数据存储在同一个目录下。而列族中的列成员声明灵活,可以在表实时运行中动态定义。
在实际实现中,可以预先根据半/非结构化数据类型去定义所需列族,并提前预留一定冗余列族以备后续扩展之需。各半/非结构化数据在存储之时,只需要将数据存入到自身对应列族中。相应地,在数据读取时,就可以根据列族索引快速检索到所需的数据。整个系统架构如图2所示。
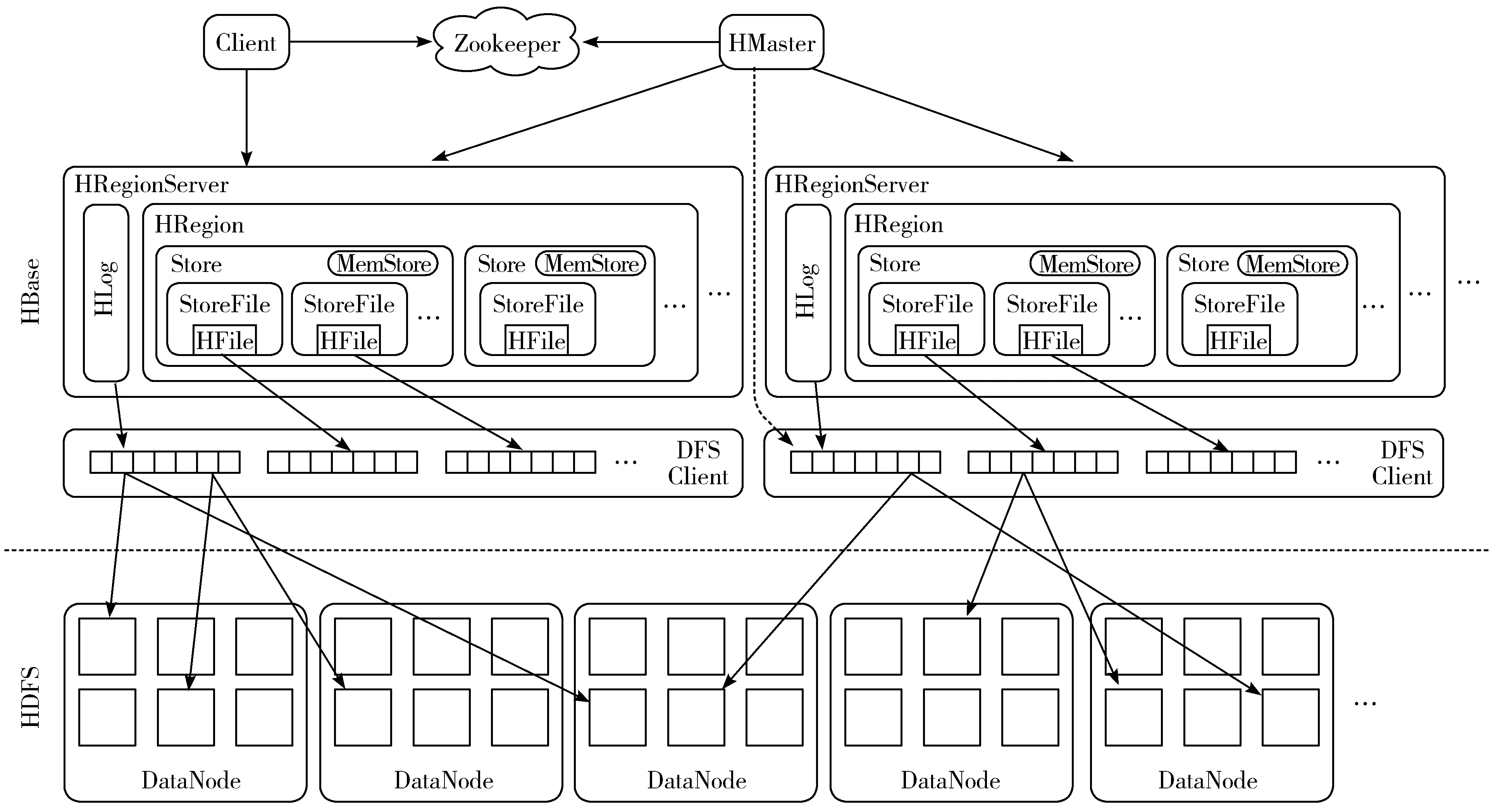
图2 基于Hadoop的HBase分布式存储架构
整个系统的存储策略设计如表1所示。
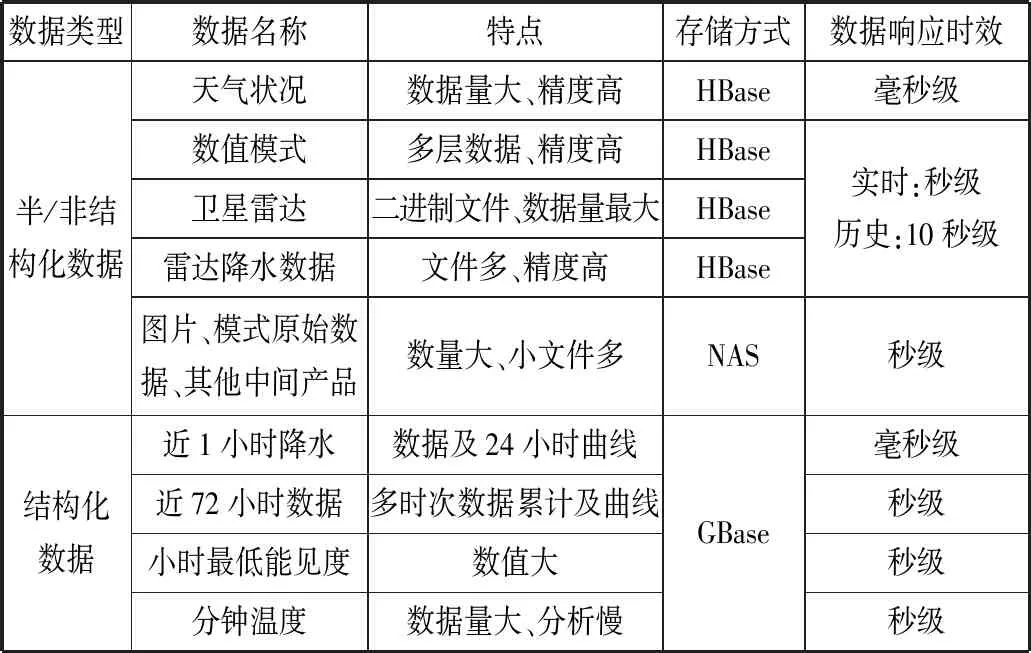
表1 数据存储方式
为了获取更快的访问速度,特别将NAS作为HBase的数据源来提供输入数据,从而获得毫秒级的数据响应能力。
3 系统负载平衡技术算法
HBase在执行负载均衡操作时,如何判断各个RegionServer节点上的Region个数是否均衡,需要通过以下步骤来进行:
1)计算均衡值的区间范围,通过总Region个数以及RegionServer节点个数,算出平均Region个数,然后在此基础上计算最小值和最大值。
2)遍历超过Region最大值的RegionServer节点,将该节点上的Region值迁移出去,直到该节点的Region个数小于等于最大值的Region。
3)遍历低于Region最小值的RegionServer节点,分配集群中的Region到这些RegionServer上,直到大于等于最小值的Region。
4)重复上述操作,直到集群中所有的RegionServer上的Region个数在最小值与最大值之间,集群才算到达负载均衡,之后,即使再次手动执行均衡命令,HBase底层逻辑判断也会执行忽略操作。
HBase共有3种调节cluster load的方法:随机交换策略(RandomRegionPicker)、region数目均衡策略(LoadPicker)、本地性最强的均衡策略(LocalityPicker),图3展示了LocalityPicker的策略流程图。
3.1 负载均衡关键技术实现
Region的负载均衡是由HMaster来完成的。HMaster有一个内置的负载均衡器,当Region不断增大,最终分裂之后,Region服务器之间的Region数量差距变大时,就需要执行负载均衡来调整部分Region的位置,使每个Region服务器的Region数量保持在合理范围之内。本文整个集群中总共存在3台RegionServer,
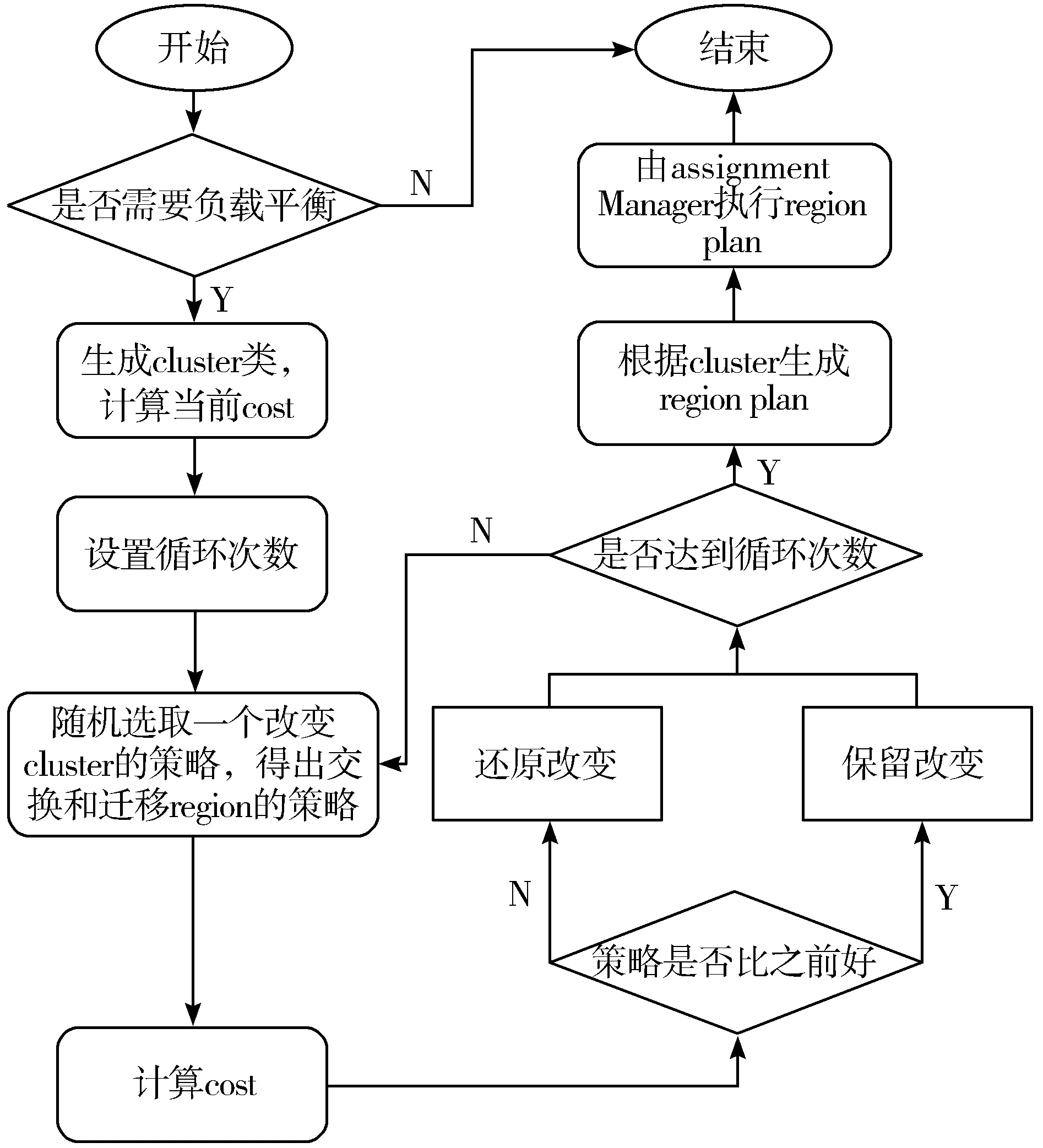
图3 系统基于LocalityPicker的负载均衡策略
按照前述的算法策略,具体关键技术实现如下:
1)是否负载均衡阈值的计算。主要根据如下语句计算:
floor=Math.floor(average*(1-slop))
ceiling=Math.ceil(average*(1+slop))
其中,slop的数值范围为[0,1]之间的小数,默认的值是0。当集群负载最小值大于floor,且最大值小于ceil时,不需要进行负载均衡。
2)计算每个RegionServer需要承载的Region的最大值max和最小值min,其实也就相当于对average取ceil和floor操作。
3)遍历RegionServer中的负载量,若当前负载量比max大,则使用shuffle算法随机打乱Region(类似于洗牌),重新计算需要从该RegionServer上转移的Region的数量。反之,如果找到的RegionServer上的负载量比min小,也就找到了存在的饥饿RegionServer的存在,这时同样是从负载最高的RegionServer遍历,从每个RegionServer中摘除一个Region,直到能够将饥饿RegionServer填饱为止。
4)如果这时还存在需要移动的Region没有指定目的地址,按照负载从小到大的顺序遍历RegionServer,如果遍历的RegionServer承载的Region数量小于max,则重置Region的目的地址为该RegionServer,该遍历的终止条件是该RegionServer上的Region数量大于等于max。
3.2 系统负载均衡的核心代码
HBase可以根据当前集群的负载以Region为单位进行rebalance。在HMaster中,后台会开启一个线程定期检查是否需要进行rebalance,线程叫做BalancerChore。线程按hbase.balancer.period的配置定期执行master.balance()函数,hbase.balancer.period配置值默认为300000 ms,即5 min。每次balance最多执行hbase.balancer.max.balancing,如果没有配置则使用hbase.balancer.period配置项的值。master.balance()首先通过loadBalancerTracker去zk上看load balance是否开启,如果开启,则从AssignmentManager中检查当前是否有Region处于in transition状态,如果有,则直接返回。否则将集群的状态发送给balancer以便后续做决策,Hmaster通过assignmentManager维护一个表,该表表明哪些机器上分别有哪些Region。对于每台机器上的该表,都会执行balancer.balanceCluster()方法。
HBase中负载平衡(load balance)的策略是可定制的,使用者可以根据业务的需要开发自己的load balance策略。在HBase中,是通过接口LoadBalancer类来实现该策略。具体使用哪个load balance策略由配置项hbase.master.loadbalancer.class决定,默认使用StochasticLoadBalancer。所有的逻辑都在StochasticLoadBalancer这个负载均衡器的balanceCluster()方法中。
负载平衡的部分核心代码如下:
double initCost=currentCost;
double newCost=currentCost;
//设置循环的次数和cluster的region server的总数和region总数有关。最大值mapSteps为1000000
long computedMaxSteps=Math.min(this.maxSteps,
((long)cluster.numRegions*(long)this.stepsPerRegion*(long)cluster.numServers));
long step;
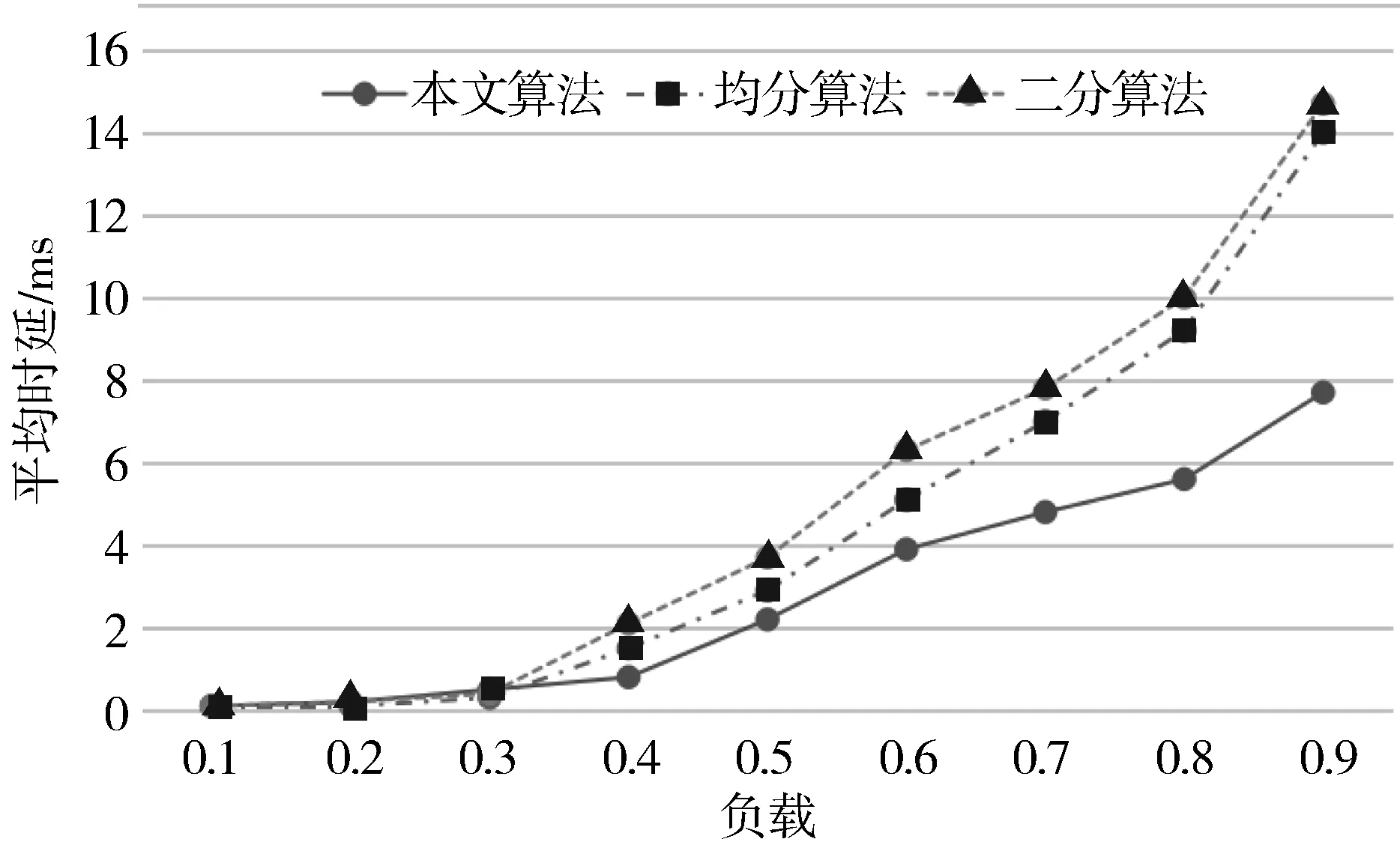
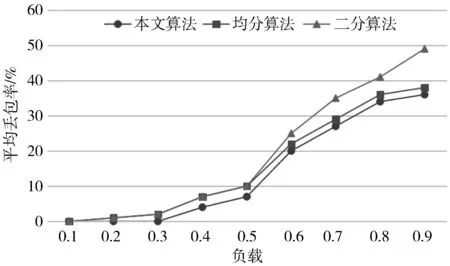
for(step=0; step int generatorIdx=RANDOM.nextInt(candidateGenerators.length); CandidateGenerator p=candidateGenerators[generatorIdx]; Cluster.Action action=p.generate(cluster); if(action.type==Type.NULL){ continue; } cluster.doAction(action); updateCostsWithAction(cluster, action); newCost=computeCost(cluster, currentCost); 天津省局的天津气象大数据共享网用户共有463人,而天津省级气象大数据服务中心前端所支撑的业务访问平台即为天津气象大数据共享网。在实际使用中,该平台的并发访问用户数一般在几十个左右。因此,将系统总体的访问性能指标定为:在100个并发场景下,要求速度控制在2 s内。 为了测试系统的性能,采用的测试条件如下: CPU:2U4核16线程,Intel(R) Xeon(R) CPU L5520 @ 2.26 GHz;内存:64 GB;磁盘:2 TB,SATA 3.0, 6.0 Gbit/s;带宽:千兆网络。共计3个数据节点、4个查询节点、1个并发测试节点。 同时,为了实现增速,对数据使用了分块存储技术,而由于并发测试只有一个节点,数据响应也同样需要资源,无法真实模拟100个用户,因此测试时间只是数据查询时间,而不包括请求数据的返回时间。 由于在实际场景中,100个用户同时请求同一大块数据的情况较少,因此模拟了以下更接近真实情况的场景,即每个查询节点分别同时请求不同时间数据,每个节点并发25个请求,共计查询4张表100个并发。测试结果如下: 1)源数据范围:纬度:5°~55°,经度:70°~140°,间隔:0.04,格点数:1250×1750。 2)查询数据范围:纬度:5°~45°,经度:70°~110°,分块:30。 3)实际查询格点数:1250×1250,返回格点数:1000×1000,返回数据大小:5.7 MB,查询结果如表2所示。 4)实际查询格点数:1250×1750,返回格点数:1250×1750,返回数据大小:12.5 MB,查询结果如表3所示。 表2 多节点综合测试结果1 表3 多节点综合测试结果2 通过实际测试,可以看到,系统可以满足200多万个格点、100个并发的场景,查询速度在2 s内,能够有效满足实际业务需要。 而相同数据查询情况下(与表2条件相同),不使用负载平衡技术,则单节点查询结果如表4所示。 表4 单节点测试结果 可见负载平衡的效果还是比较明显的,基于负载平衡条件下的查询,查询时间提升效果显著,数据响应速度提升了42.69倍。同时,多节点访问能够有效避免单节点故障问题。从而使得系统的访问效率、稳定性和可靠性,均得到了有效的提高。 为了进一步验证本文算法的有效性,利用Mininet网络仿真模拟平台进行测试对比。图4和图5给出了本文算法与传统算法中均分负载算法和二分负载算法的对比结果图。 图4 系统平均时延对比图 图5 系统平均丢包率对比图 可以看到,本文所提的算法在时延和丢包率上,比均分负载算法和二分负载算法都有一定程度的提高。在负载不大的情况下,这种差别并不明显,但是随着负载的增大,本文算法的优势就会逐渐体现出来。 随着海量数据的不断增长,大数据下的应用场景也越来越多。本文基于HBase系统的负载平衡技术,在大数据的数据环境下,针对气象领域中的半/非结构化数据进行了存储、查询和测试。结果表明:基于本文所提的负载平衡算法和策略,系统的数据查询性能有较为明显的提升,可以很好地解决高并发访问的问题,并能有效提高访问质量,使整体系统数据服务能够较好地满足实际业务需要。4 实验测试



5 结束语
猜你喜欢
艺术启蒙(2025年2期)2025-03-02 00:00:00
作文周刊·小学一年级版(2022年24期)2022-06-18 13:11:03
内蒙古气象(2021年2期)2021-07-01 06:19:58
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
领导决策信息(2018年46期)2018-04-20 04:00:42
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
