
基于改进深度度量学习算法的表面缺陷检测
2021-06-29 06:36:50余厚云
计算机与现代化 2021年6期
王 伟,余厚云
(1.南京航空航天大学机电学院,江苏 南京 210016; 2.南京航空航天大学无锡研究院,江苏 无锡 214187)
0 引 言
产品质量检测是工业生产中必不可少的一环,而大部分缺陷集中在产品表面,因此表面缺陷检测对于保证产品质量而言至关重要。近年来,很多国内外企业开始将基于机器视觉的表面缺陷检测系统引入到生产线上,替代人工进行产品表面质量检测。
对于结构和类型复杂的缺陷,常规图像识别方法的准确率很低,这时就需要通过神经网络等深度学习算法来检测缺陷。然而,传统的神经网络算法需要借助大量标注样本来对网络进行训练,无法适用于小批量、多品种的产品。因此,针对少量标注样本的小样本学习[1-2](few-shot learning)算法研究显得尤为迫切。
Aytar等[3]早在2011年就提出了基于迁移学习(transfer learning)的小样本学习方法,该方法认为相似任务之间的学习是有相同规律可循的,并且学习第n个任务比第一个任务要更为简单[4]。Koch等[5]于2015年提出了针对字符识别的深度卷积孪生网络(Siamese Network),此算法训练一个孪生网络对样本进行相似性判定;Finn等[6]于2017年提出了一种与模型无关的元学习算法(Model-Agnostic Meta-Learning, MAML),能够使用少量的迭代步骤将模型迁移到新的任务上。此外,针对小样本学习的研究还有对偶学习[7](Dual Learning)、贝叶斯学习[8](Bayes Learning)等方法。
但是,缺陷检测任务有其自身的特点:无缺陷样本的特征相似,而有缺陷样本的缺陷种类较多,即便是同一种缺陷类型,其缺陷特征尺寸、形状也不尽相同。由于样本数量少,有缺陷样本的特征无法覆盖各种缺陷类型,导致在应用上述小样本学习算法时的检测准确率偏低。为此,本文在深度度量学习算法(Deep Metric Learning, DML)的基础上,针对产品缺陷检测任务的特点进行了算法改进,以提高检测准确率。
1 深度度量学习算法
深度度量学习是在度量学习(Metric Learning)的基础上发展而来的。度量学习的核心是距离(Distance),其思想是寻找数据之间的相似性与距离的关系,即相似数据之间的距离应尽可能小,相似度较低的数据之间的距离应尽可能大[9-10]。这种思想在机器学习领域最著名的应用是最近邻算法[11](Nearest Neighbors, NN),该算法将待测样本归类为距离其最近的训练样本的类别。上述度量学习算法主要应用于维度较低且特征较为简单的数据上,对于图像这种维度高、特征复杂的数据,普通度量学习的分类准确率低。因此,Chopra等[12]与Hadsell等[13]分别于2005年与2006年提出了将深度神经网络引入度量学习,以便将高维度数据进行非线性的特征降维[14]。
深度度量学习的工作流程如图1所示。首先需要定义一个深度神经网络模型,网络的输入为待分类的高维数据,网络的输出为经过降维后的n维向量,此向量所在的空间称为隐空间(Latent Space)。在训练阶段,将带标注的训练数据通过神经网络映射到n维空间,每一个数据即为n维空间中的一个点。训练的目的是结合损失函数与梯度下降法对网络进行训练,以使得同一类别数据之间的距离尽可能小,而不同类别数据之间的距离尽可能大。在做推断时,将已训练好的网络参数固定,同时将待分类数据作为网络的输入映射为n维空间中的一个点,然后通过最近邻算法进行归类。
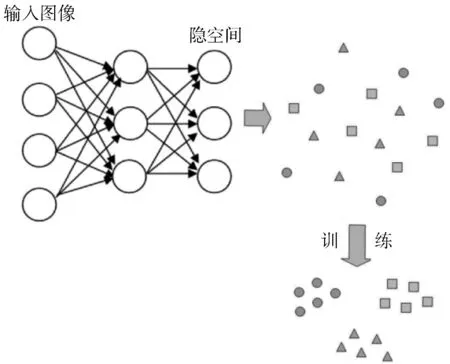
(a) 训练
(b) 推断图1 深度度量学习训练与推断过程
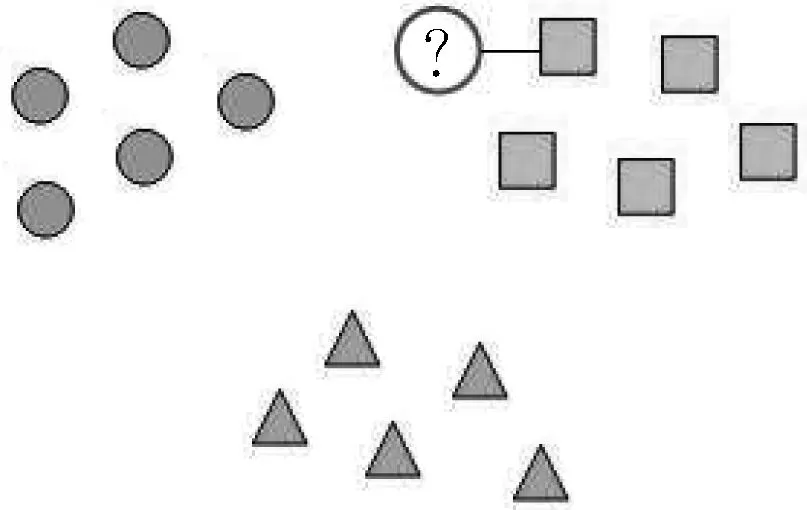
除此之外,深度度量学习还可以用于开集(open-set)分类[15],如人脸识别、指纹识别等。开集分类的特点是待分类样本不属于参与训练阶段的样本类别之一,此时深度度量学习的推断过程如图2所示,图中灰色神经元表示参数固定。将待分类的标注样本经过神经网络映射到n维空间,然后以此样本为基础使用最近邻算法进行数据分类。在开集分类的应用场景下,深度度量学习算法为元学习(learning to learn)[16]算法的一种,因此本文将参与神经网络参数训练的数据集称为元训练集(meta-training set),将推断时提供的带标注样本称为支持集(support set),测试样本称为查询集(query set)。
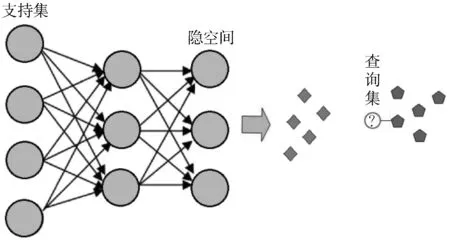
图2 开集分类推断流程
小批量、多品种工业产品的缺陷检测任务属于开集分类。本文根据缺陷检测任务本身的特性,对传统深度度量学习算法的损失函数、归类算法进行优化改进,并且在支持集上进行网络参数的微调,以使得其算法更适合缺陷检测任务。
2 条件三元组损失函数
深度度量学习的目标是使同一类别的数据之间的距离尽可能小,而不同类别的数据之间的距离尽可能大,这一目标体现在作为网络质量评判角色的损失函数上。根据分类任务不同,常用的损失函数有对比损失函数[13](contrastive loss)、中心损失函数[17](center loss)和三元组损失函数[18](triplet loss)等。
上述3种传统的损失函数的目标是使类内样本的距离最小化,而类间样本的距离最大化。但对于产品表面缺陷检测来说,无缺陷表面的图像特征较为一致,而有缺陷表面的缺陷种类较多,如大多数产品可能会出现形状不完整、划痕、颜色污染等,并且由于缺陷的严重程度不一样,导致即使是同一类型的缺陷,其图像特征也多种多样。因此,若按照传统损失函数进行训练,无缺陷样本的特征基本相同,经训练后样本的类内距离较小,不会影响分类。但特征多样的有缺陷样本训练后类内距离较大,若强行将其缩小,会导致模型拟合能力不足,降低缺陷检测准确率。同时,与对比损失函数和中心损失函数相比,三元组损失函数考虑了类内数据对与类间数据对的相互关系,保留了更多的训练集数据特征,因此在输入数据特征较为复杂时表现出更好的效果。为此,本文在传统的三元组损失函数的基础上进行改进,以便更加适应表面缺陷检测任务。
元训练集是由不同种类的有缺陷产品和无缺陷产品组成的。本文提出的条件三元组损失函数要求对于元训练集中相同种类产品的无缺陷样本和有缺陷样本分别分配相邻的偶数和奇数作为其类别标识。对于不同种类产品,分配不同的相邻整数对作为类别标识。并且需要在元训练集中任意选取样本作为锚点样本(anchor)Xa、与锚点样本同类的正样本(positive)Xp,以及与锚点样本不同类别的负样本(negative)Xn,共同组成公式(1)所示的条件三元组损失函数。
loss(Xa,Xp,Xn)=
(1)
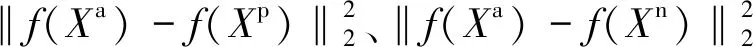
公式(1)表明,若锚点选取的样本为无缺陷样本,则按照传统的三元组损失函数进行计算;若锚点选取的样本为有缺陷样本,则损失值忽略锚点与正样本间的距离。
条件三元组损失函数通过调节神经网络训练的方向以完成网络参数的更新。在参数更新过程中,三元组视窗内样本间的距离变化如图3(a)所示。在元训练集视窗内,训练完毕后,不同的类别在隐空间中的分布状态应当如图3(b)所示。
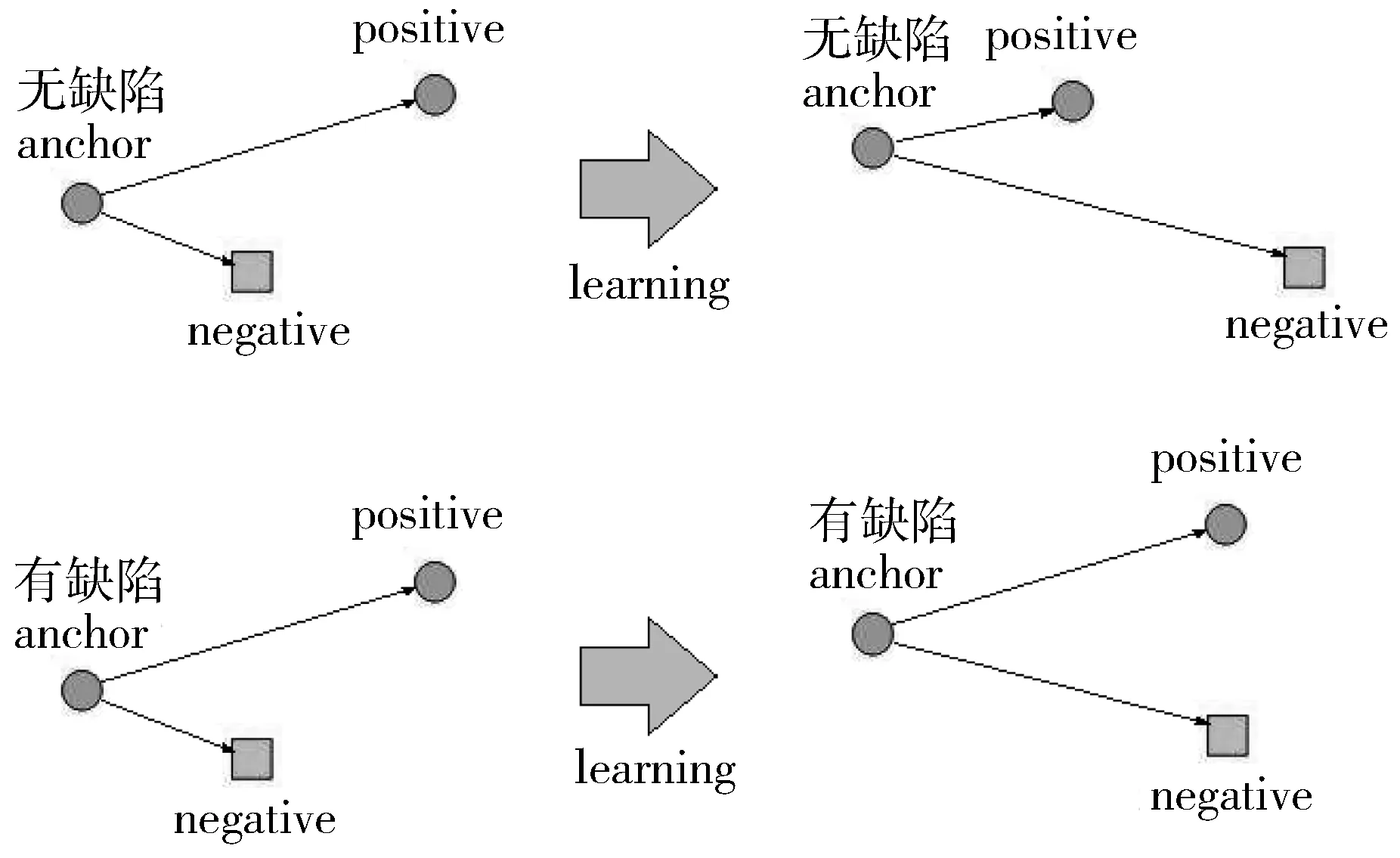
(a) 三元组视窗
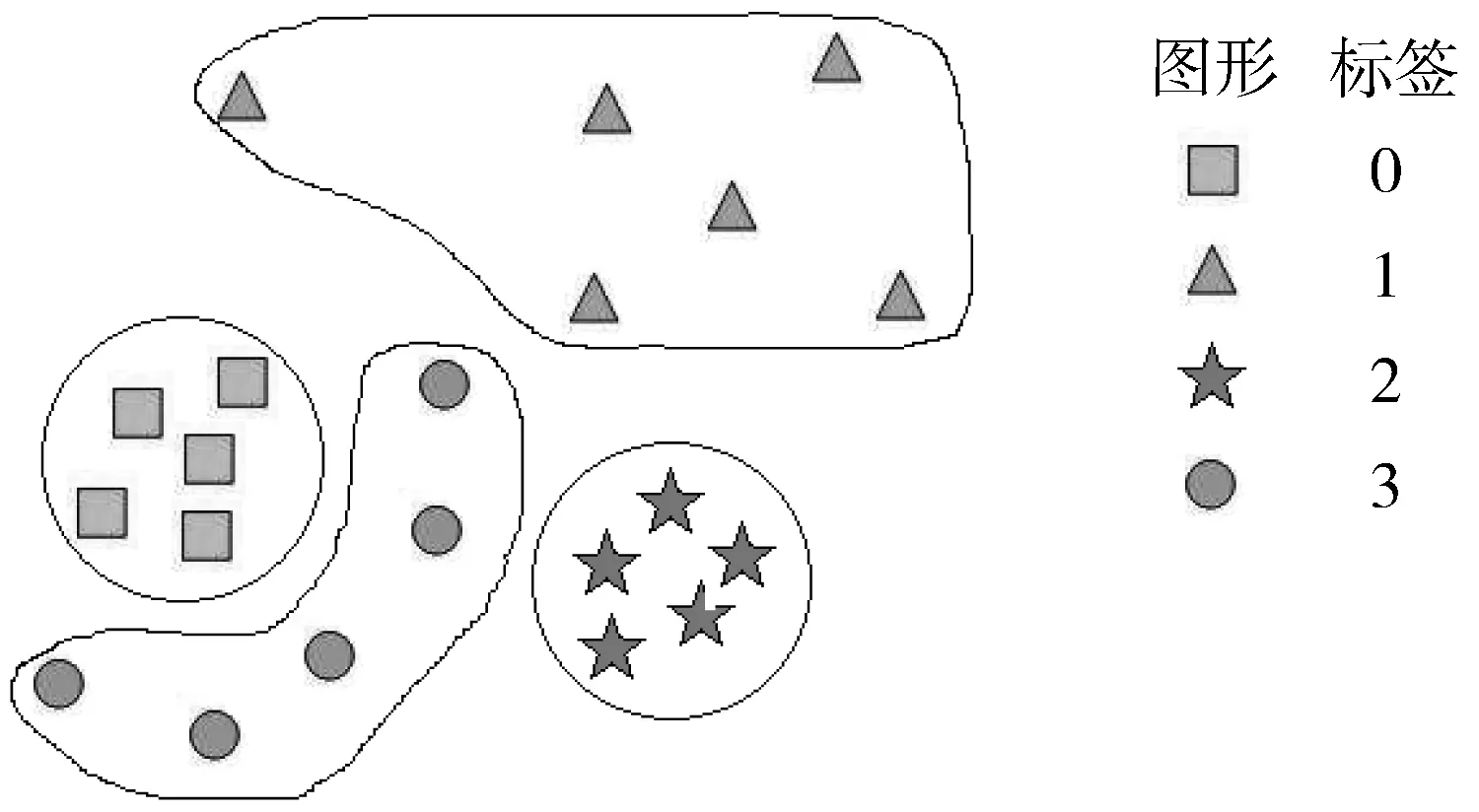
(b) 元训练集视窗图3 条件损失函数对网络训练过程的指导
最终的损失值为所有三元组损失的累加,如公式(2)所示:
(2)
式中,T表示训练数据集。此时,损失值的计算需要Ο(N3)的内存空间,N为元训练集数据量。此数量一般非常庞大,训练时的运算速度将大大降低,并且模型收敛缓慢。所以在上述条件三元组损失函数的基础上,使用难例挖掘(batch hard mining)[19]技术加快模型的收敛速度。难例挖掘在计算网络总体损失值的时候,不是累加全部的三元组损失,而是仅考虑让模型收敛最困难的三元组,基于难例挖掘的条件三元组损失函数计算由公式(3)给出:
Loss={da1,p|label(a1) and 2=0,label(a1)=label(p)}max-
{da2,n|label(a2)≠label(n)}min+m
(3)
在公式(3)中,第一项表示以无缺陷样本为锚点时,锚点与正样本的距离的最大值;第二项表示锚点样本与负样本的距离的最小值,m为类间距。
3 基于高斯分布概率的样本归类
在原始的深度度量学习算法中,图像类别划分采用的是K最近邻算法(K-Nearest Neighbor, KNN)[20],它是最近邻算法的扩展。但如图4所示,在采用条件三元组损失函数对网络参数进行训练后,神经网络未能将有缺陷纽扣在隐空间中进行聚类,并且由于支持集样本较少,无法较好地拟合有缺陷纽扣在隐空间内的分布,从而导致KNN归类算法失效。
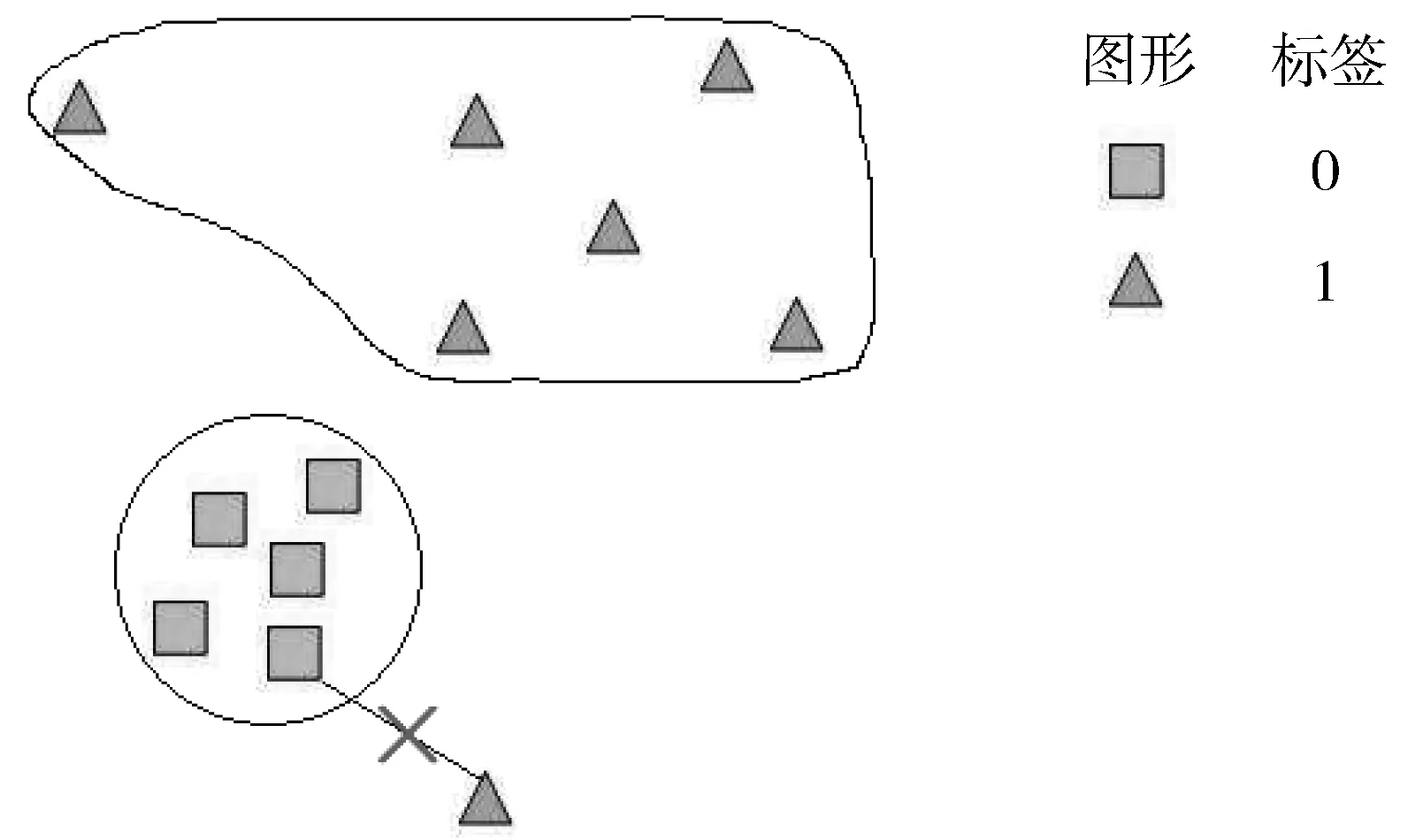
图4 KNN算法失效原因
另一方面,无缺陷样本是通过损失函数的指导进行聚类操作的,因此可以使用已有的支持集数据中的无缺陷样本对其分布进行拟合。然后在查询集当中,可根据数据在隐空间内属于无缺陷样本分布的概率来判断该数据的分类。当概率大于某个阈值时,将数据归类为无缺陷类别,否则认为是有缺陷类别。
现已知支持集中无缺陷样本在隐空间内的位置向量,假设满足高维高斯分布,其概率密度函数可由公式(4)给出:
(4)
式中,x为支持集样本在隐空间中的位置向量,μ与Σ为待估计参数,分别为总体均值向量与总体协差阵。本文使用极大似然估计法来计算这2个参数,计算公式为:
(5)
(6)
其中,Xi为支持集中的一个无缺陷样本在隐空间中的位置向量。为了使协差阵Σ满足正定矩阵的条件,在对Σ做估计时,将估计结果的主对角线元素加上一个很小的值,E表示与隐空间维度相同的单位矩阵。
对于查询集中的未知标签数据,定义公式(7)作为判断它符合此高维高斯分布的概率:
(7)
式中,X为待测数据在隐空间中的位置向量。
求得概率密度函数后,接下来根据公式(8)计算2个类别的分割阈值:
(8)
式中,P为支持集上所有无缺陷样本的集合,N为支持集上所有缺陷样本的集合。
4 网络参数的微调
综上所述,深度度量学习算法用于开集分类的步骤是:使用元训练集对网络参数进行训练,之后将支持集数据输入神经网络,并投影到隐空间中,最后对查询集上的数据使用基于高斯分布概率的归类算法进行分类。在此过程中,真正需要识别的对象支持集并没有参与网络的训练过程,而是使用与其特征相似的元训练集对网络参数进行训练,训练好的网络在支持集上的聚类效果并不好。因此,本文将元训练集上训练好的模型在支持集上进行参数微调(fine-tune)[21]。
执行缺陷检测任务的深度度量学习算法需要将原图像投影到隐空间,因此神经网络通常将较浅的层设置为卷积层,用来提取图像特征,而将较深的层设置为全连接层,用于对特征进行隐空间的映射。同时,卷积层较浅的部分可以对较为粗大的、共性的特征进行提取,而较深的部分可以提取到一些细微的特征。
神经网络总体结构如图5所示。元训练集与支持集上数据所对应产品的种类是一致的,型号或批次有所不同,因此它们的相互差别主要在于一些细微的特征。可以对卷积层的最后几层进行网络参数微调,而其它层的参数固定,在支持集上使用小学习率对网络参数进行训练。

图5 神经网络总体结构
5 改进算法精度验证
针对实际工程应用中的纽扣缺陷检测任务,采集5种不同类型纽扣的图像并制作成数据集,各数据集中无缺陷样本和有缺陷样本的数量均为500个,图像尺寸均为64×128像素。5种不同类型纽扣的数据集编号分别记为Btn1~Btn5,其示例图像如图6所示。
在网络训练过程中,一般会将训练集进行数据增强,以提高网络模型的泛化能力,减轻因数据量少引起的网络过拟合现象。
5.1 训练集数据增强
纽扣缺陷数据集采用的数据增强方法是随机旋转变换、水平翻转以及随机对比度调整。如图6所示,每个样本图像由左、右2个部分组成,分别为纽扣的正、反面。随机旋转变换是将图像正反面分别绕其中心旋转相同随机角度θ,结果如图7(a)所示。水平翻转则用来模拟纽扣采集过程中正反颠倒的情况,如图7(b)所示。随机对比度调整是将原图像由RGB色彩空间映射到HSV色彩空间,然后随机微调S平面与V平面的参数,最后再将图像转换回RGB空间,如图7(c)所示。

图6 数据集样本示例
5.2 实验结果
为了验证改进深度度量学习算法的表面缺陷检测精度,进行3组实验并将实验数据做了对比。3组实验分别为:传统深度度量学习算法、改进深度度量学习算法(无微调)、改进深度度量学习算法(支持集上微调)。
如表1所示,根据训练需要,将数据集划分为元训练集、支持集与查询集。
采用的神经网络结构是基于VGG16模型[22]的改进,它保留了VGG16的卷积层,而将全连接层改为2层,2层的输出维度分别为256维与128维,激活函数为ReLU。

(a) 随机旋转变换

(b) 水平翻转
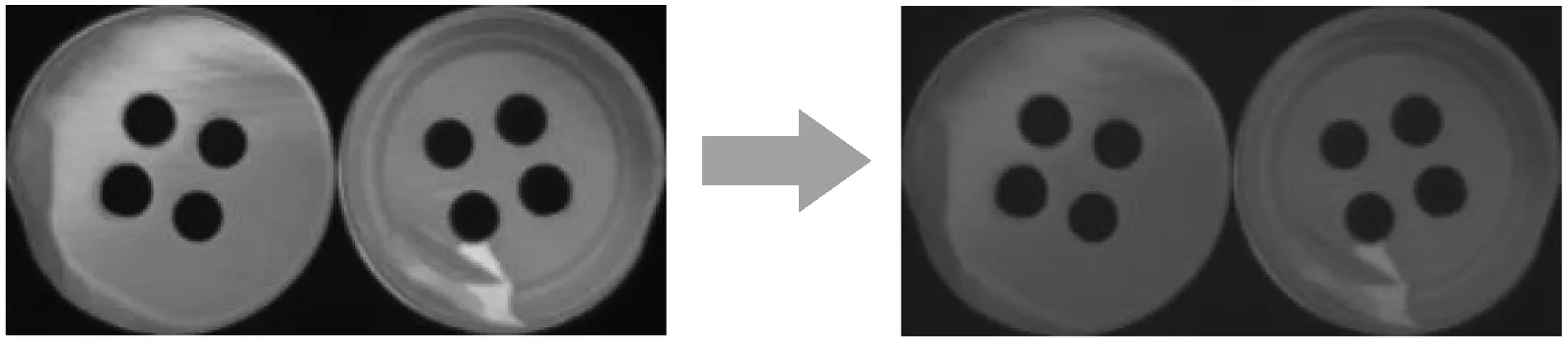
(c) 随机对比度调整图7 数据增强方法
实验一使用的是传统深度度量学习算法,网络训练时的学习率(Learning Rate)设置为1×10-5,批大小(Batch Size)设置为16,三元组损失函数的类间距(Margin)设为0.5,近邻数为3,且在损失值连续30个迭代周期不下降时停止训练。训练过程中元训练集上的损失值与查询集上的准确率随迭代次数的变化如图8所示。从图8可以看出,损失值呈稳定下降,最终达到0.0026。分类准确率在第一个迭代周期由55%上升至83.44%,在第9个迭代周期达到最大值89.56%。随后,网络产生轻微过拟合,在网络训练结束后的分类准确率为78.78%。训练完成后,将支持集图像投影到隐空间并使用KNN算法进行分类,检测结果如表2所示。
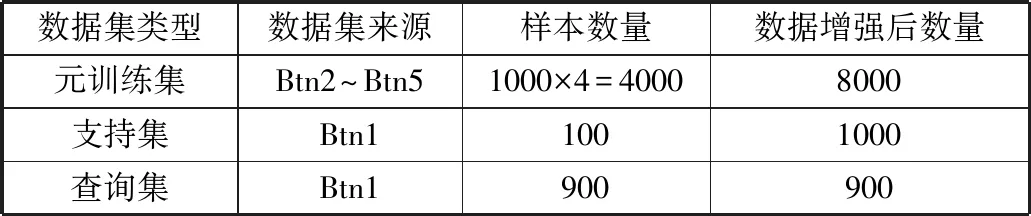
表1 数据集划分
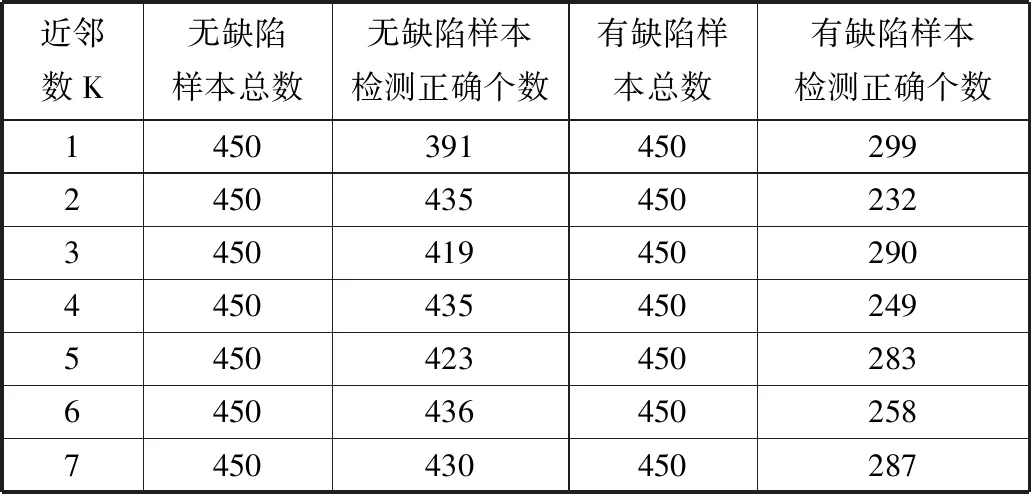
表2 实验一近邻数及其测试结果
实验二是在实验一的基础上,将损失函数改为条件三元组函数,并采用基于高斯分布概率的归类算法,网络训练时学习率为1×10-5,批大小设置为16,条件损失函数的类间距为0.5,当损失值连续30个迭代周期不下降时停止训练,训练过程如图9所示。表3给出了实验结果,可以看出,更换了损失函数和归类算法以后,由于没有学习到支持集上的数据特征,网络在查询集上的准确率最终只有63.78%。
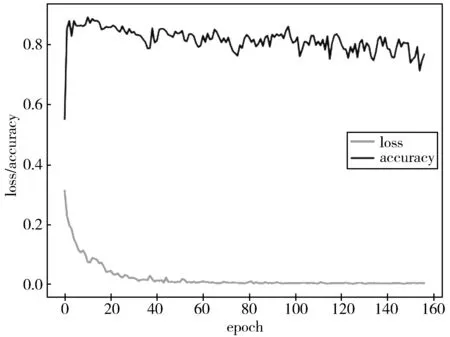
图8 实验一损失值和准确率随迭代次数的变化曲线
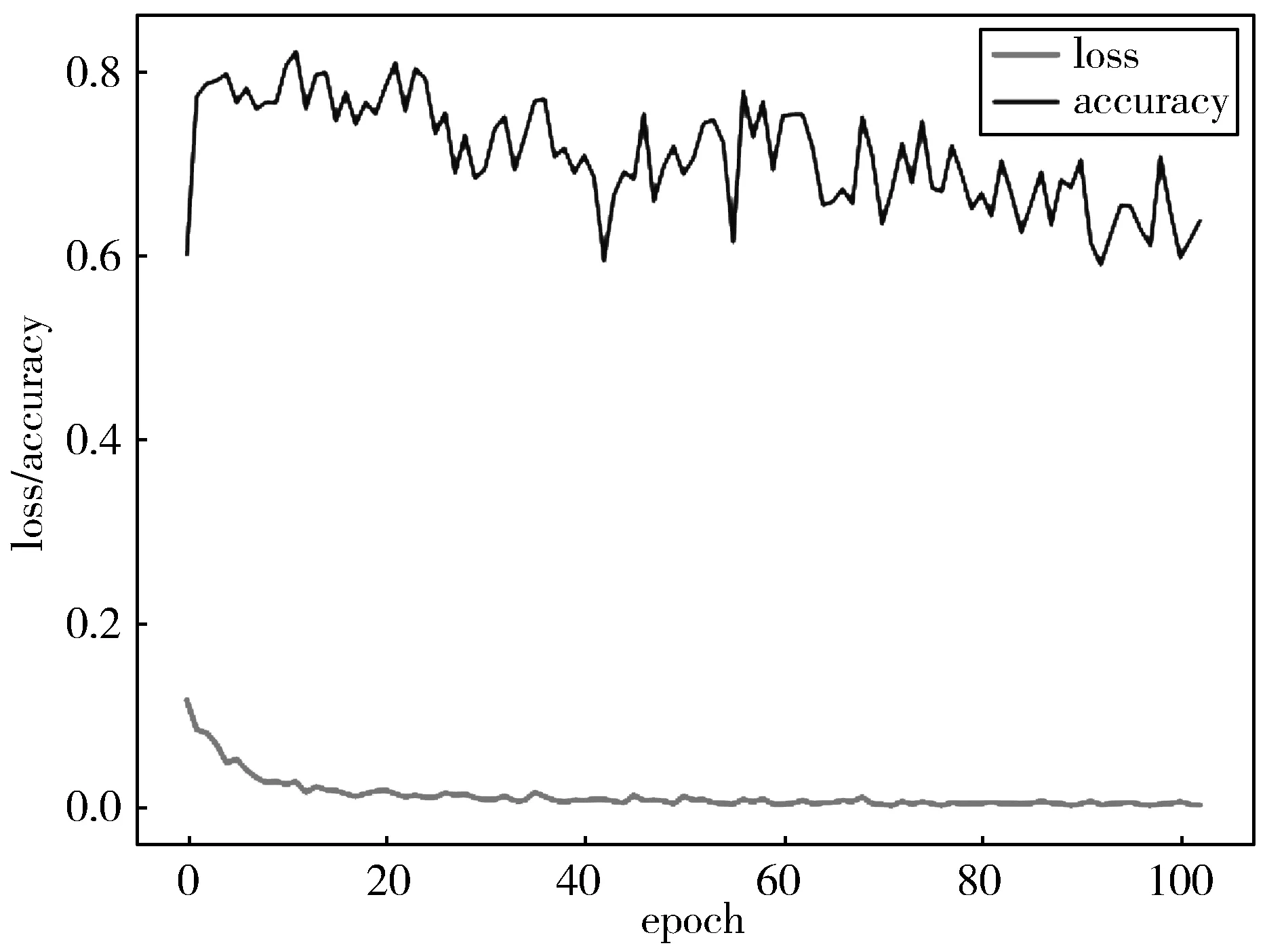
图9 实验二损失值和准确率随迭代次数的变化曲线
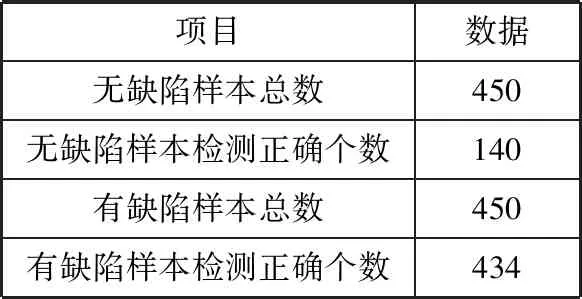
表3 实验二测试结果
实验三则是在实验二的基础上,使用本文提出的基于支持集的微调算法对最后3层卷积层的参数进行微调。微调时的学习率为1×10-5,并且损失值连续20个迭代周期不下降时微调过程停止。支持集微调迭代过程如图10所示,通过迭代曲线可以看出,网络训练过程稳定,收敛速度快,训练完成后在查询集上的测试结果由表4给出,分类准确率可达到92.89%。
此外,为了进一步验证本文算法的鲁棒性,使用K-Fold交叉验证做了5组实验,每组实验重复3次。并且在每一组实验中,神经网络初始化不同的参数来进行训练,实验结果如表5所示。每一组实验数据的支持集与查询集的切分比例与表1相同。从实验结果可以看出,所有实验的检测准确率均在90%以上,且各组实验具有很好的重复性,说明本文算法的整体鲁棒性较好。
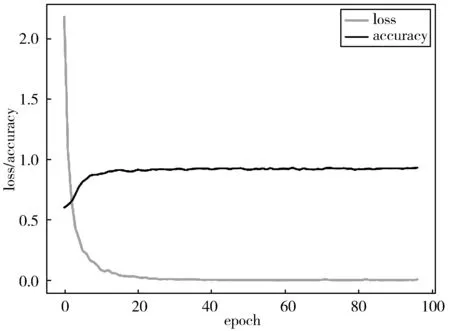
图10 实验三损失值和准确率随迭代次数的变化曲线
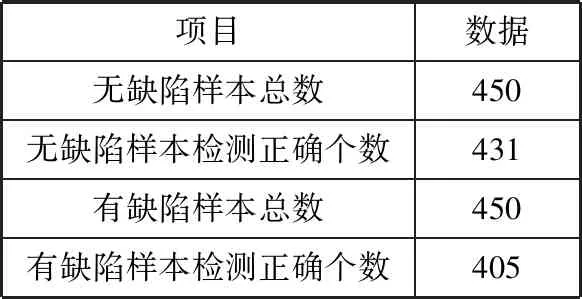
表4 实验三测试结果
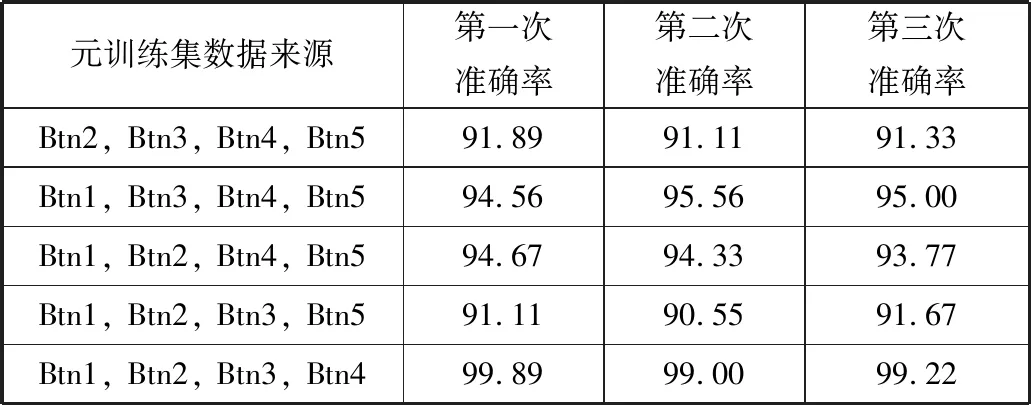
表5 K-Fold交叉验证结果 单位/%
5.3 模型评估
基于改进深度度量学习的产品表面缺陷检测实质上是关于图像的二分类算法,通常使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-score)这4个指标来对模型进行评估。这里,将有缺陷样本定义为正类,无缺陷样本定义为负类,使用混淆矩阵[23]描述的TP、TN、FP、FN的定义如图11所示。
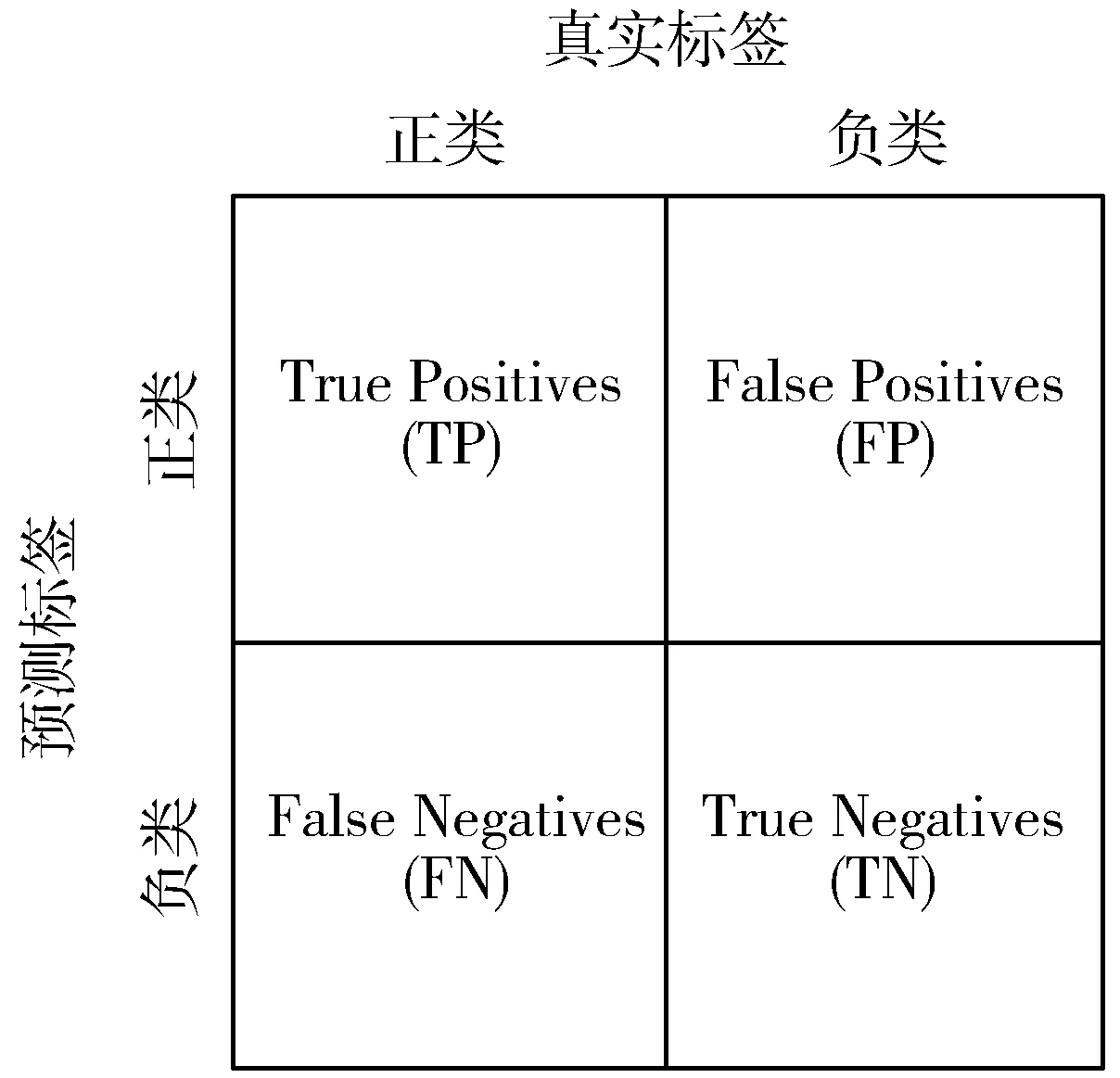
图11 混淆矩阵
由混淆矩阵所示,TP表示有缺陷纽扣被识别正确的样本数,TN表示无缺陷纽扣被识别正确的样本数,FP表示无缺陷纽扣被识别为有缺陷纽扣的样本数,FN表示有缺陷纽扣被识别为无缺陷纽扣的样本数。
准确率为所有预测结果正确的样本数占总样本数的比例:
(9)
精确率为正确预测的正类样本数占全部预测为正类样本的比例,反映模型预测缺陷样本的准确程度:
(10)
召回率为正确预测的正类样本占全部正类样本的比例,反映缺陷样本预测完备的程度:
(11)
F1值是结合了精确率和召回率的调和平均的指标,通常用来综合评估网络模型的性能:
(12)
由实验数据得到的上述指标的数值如表6所示。从表6数据可以看出,传统算法与无微调时改进算法的准确率较低,而在支持集上微调的改进算法准确率高达92.89%,且其精确率与F1值均较其他算法有明显优势。另外,在工业生产中通常希望通过缺陷检测降低产品的次品率,因此更关注模型的召回率,召回率越高,则漏检率越低。从实验结果来看,改进算法召回率达到90%,即在测试集中有10%左右的缺陷样本被误判成了正常样本,但是考虑到在实际的产品中,缺陷产品只占总产品数量的1%~2%,因此实际的漏检率在0.2%以内,能够满足工业检测要求。
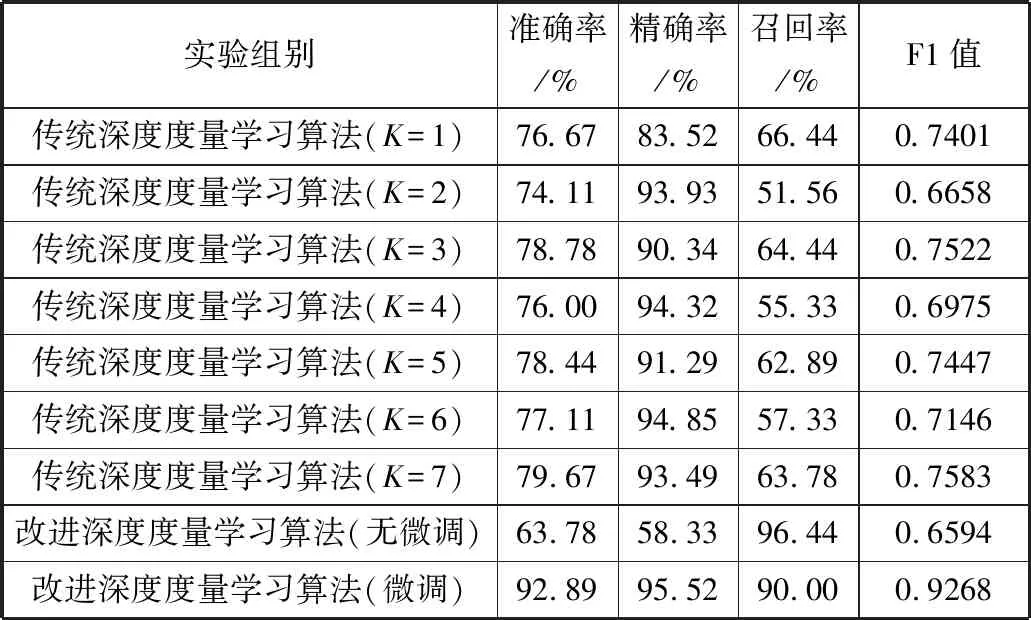
表6 模型评价结果
综上,本文提出的改进深度度量学习算法大幅度地提高了小样本情况下纽扣缺陷检测的准确率,并且具有较好的鲁棒性,可以实现对缺陷产品的快速智能检测。
6 结束语
1)针对小批量、多品种的工业产品表面缺陷检测,本文提出了一种改进深度度量学习的缺陷检测算法。算法在传统深度度量学习的基础上,修改了网络模型结构,创新性地提出条件三元组损失函数,并且使用基于高斯分布概率的归类算法对图像进行分类,同时,为了提高准确率,还在支持集上进行了神经网络参数的微调。
2)通过实验验证,该方法在纽扣缺陷数据集上的检测准确率高于传统深度度量学习方法,能够满足工业现场的检测需求。同时,该方法经过K-Fold交叉验证体现出较好的鲁棒性,并且对输入图像的敏感度较低,在支持集上网络训练速度与查询集上的推断速度快,可以实现对缺陷产品的快速智能检测。
猜你喜欢
软件工程(2024年12期)2024-12-28 00:00:00
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
计算机与数字工程(2023年5期)2023-08-31 08:40:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
数学物理学报(2017年5期)2017-11-23 07:51:31
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
