
基于Hadoop的视频网站推荐算法研究
2021-06-29 02:08张文泽
科学技术创新 2021年17期
张文泽
(长江大学电子信息学院,湖北 荆州434000)
随着当今互联网的快速发展,每天会有海量信息产生,互联网用户容易迷失在信息海洋中无法找到目标内容。为了解决这种问题,推荐系统孕育而生。推荐系统是解决在“信息过载”下,用户如何高效获得自己感兴趣目标信息的问题。从工程的角度来推荐系统可以分为两大部分:数据部分和模型部分。数据部分主要指推荐系统所需数据流的工程实现。大数据优于好算法是指基于小数据的推荐效果不如拥有大量可用数据的推荐效果理想。而模型部分指的是推荐模型的相关工程实现,根据应用阶段的不同,可进一步划分。
1 Ha doop平台与系统设计
1.1 Hadoop平台架构
Hadoop是能够对海量数据进行分布式计算处理的框架,它的核心是分布式文件系统(HDFS)和MapReduce。HDFS支持处理超大规模的文件,采用了主从结构模型,通常一个HDFS集群包括一个名称节点和若干个数据节点。名称节点它负责管理文件系统的命名空间以及客户端的访问请求。而数据节点它负责处理文件系统客户端的读写请求。MapReduce它将复杂的并行计算的过程抽象到两个函数:Map和Reduce。通过Map对数据进行分割,然后shuffle过程会对Map的输出进行排序和合并,最后交给Reduce处理。
1.2 批处理大数据架构
批处理大数据架构采用了分布式文件处理系统,MapReduce代替了原来传统文件系统和数据库的存储和处理方式,批处理大数据架构示意图如图1所示。

图1 批处理大数据架构示意图
2 推荐系统
2.1 推荐系统概述
推荐系统在获知“用户信息”“物品信息”“场景信息”的基础上,通过构建好的函数模型,预测用户对候选物品的喜好程度,再根据喜好程度对候选物品进行排序生成TOP-N列表。图2是根据推荐系统的定义,抽象得到的逻辑框架图。

图2 推荐系统逻辑框架图
2.2 协同过滤算法
协同过滤是协同所有的反馈对海量的信息进行过滤,从中筛选出目标用户可能感兴趣信息的推荐过程。按照推荐内容划分,主要有基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。UserCF主要是用户相似度的计算,目标用户的相似用户对目标物品的评价是正面的,则可以预测目标用户对物品的评价也是正面的。而ItemCF主要是计算物品的相似度,找到目标用户的历史正反馈的物品,通过与正反馈物品相似度进一步排序和推荐。两者应用场景也有不同,UserCF具有社交特效,不会集中在固定的内容范围。因此适用于新闻推荐等场景。ItemCF更适用于兴趣变化较为稳定的推荐场景,因此用它来推荐视频是更好的选择。
2.3 基于物品的协同过滤算法流程
ItemCF是通过计算共现矩阵中物品向量的相似度得到相似矩阵,再通过与历史正反馈物品的相似度,进一步得到推荐物品的列表。具体步骤如下所示:
(1)根据用户的所有历史数据,构建用户为行坐标,物品为列坐标的共现矩阵。
(2)计算共现矩阵两两列向量的相似性,构建n*n维的物品相似性矩阵。
两个向量之间通常采用的相似度计算是余弦相似度来衡量,计算两个物品向量之间的夹角大小,夹角越小,余弦相似度越大,两个用户越相似。

但是对于式(1)来说,为了消除热门因素带来的影响,使用平均分因素对各评分进行修正,减小了用户评分偏置的影响,采用皮尔逊相关系数对其修改完善。
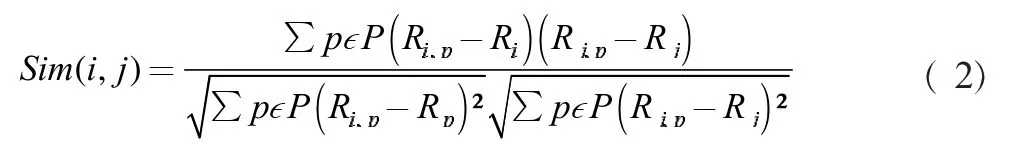
其中,Ri,p代表用户i对物品p的评分。Ri代表用户i对所有物品的平均评分,P代表所有物品的集合。
仅仅针对用户评分进行相似度计算,而忽视了实际当中每个人打分习惯的不同,通过引入物品平均分的方式,减少评分偏执的影响,如式(3)所式。

其中,Rp代表物品p得到所有评分的平均分。
3 实验与分析
3.1 推荐系统的评价标准
推荐算法的评价指标主要分为在线评价和离线评价,在线评价是通过实时点击率得到推荐算法的性能衡量。但是在线评价不利于实验的开展,因此我们采用离线的方式。离线的方式是将训练集的信息作为算法的输入进行推荐,再将最后推荐的结果与测试集的结果作为对比。
在离线实验中,在对单个物品的评分预测任务中,我们一般会采用计算预测评分与真实评分之间的绝对误差(MAE)或者均方根误差(RMSE)进行评估。
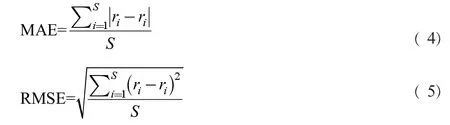
其中ri是第i个样本点的真实值,ri是第i个样本点的预测值,s是样本点的个数。
3.2 数据集
本文使用的数据集是Netflix比赛的,整个数据集只有600MB,而实际的业务会达到GB,TB。数据集每行包含三个标签字段,分别是用户的ID,电影的ID,用户对电影的评分。
3.3 环境配置
本文集群搭建是利用VMware搭建的,有一个Master节点和两个Slave节点。系统使用的环境是Linux CentOS 7.0 ,配置如表1所示。

表1 分布式集群配置表
3.4 实验分析
(1)测试MapReduce的运行速度(图3)

图3 Ha doop平台运行效率
结果表明,MapReduce会把一个存储在HDFS中的数据集切分成许多独立的小数据块处理,节点的个数越多,运行效率会越高。
(2)为验证算法的有效性,与传统的协同过滤进行比较,使用相同数据集,在相同节点下进行RMSE值对比实验,所得结果如表2所示。

表2 对比实验结果
结果可以看出,在减少打分偏置和减低个人打分习惯因素下,基于物品的协同过滤比基于余弦相似度的协同过滤具有较低的RMSE值,RMSE值反映了预测值与真实值的偏离程度,即改进后推荐效果更加理想。
4 结论
借助大数据技术的推荐系统能很好地排除了用户不需要的冗余信息的干扰,改善了用户平时观看视频的体验,推荐系统的研究是一个重要的研究方向,未来在该领域内拥有更加广阔的空间。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
小学生学习指导(低年级)(2022年5期)2022-05-31
新班主任(2022年4期)2022-04-27
疯狂英语·初中天地(2021年11期)2021-02-16
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
少年漫画(艺术创想)(2019年2期)2019-06-06
World Journal of Diabetes(2019年3期)2019-04-16
汽车观察(2019年2期)2019-03-15
