
面向多尺度交通标志的快速识别算法∗
2021-06-29 08:41姚兆骁郑尧成
计算机与数字工程 2021年6期
姚兆骁 郑尧成 陈 洋
(上海工程技术大学 上海 201620)
1 引言
交通标志本质是提供有用信息的视觉语言[1]。在智能交通系统(ITS)中,交通标志识别是先进驾驶员辅助系统(ADAS)的重要组成部分,它提供驾驶员警告和指导信息,它是无人驾驶车辆中最重要的领域之一,保持车辆的有序和安全。交通标志识别系统分为交通标志检测和交通标志识别。检测阶段是定位兴趣区域,分类阶段是识别候选者或拒绝候选者。
检测阶段,传统的检测方法包括颜色分割、形状匹配。这些方法简单直接,但对光照、遮挡等因素较为敏感。相比较单一地使用交通标志较为浅层次的颜色或形状特性,也有不少学者将两种方法进行结合[2]。但这些传统结合的检测方法极其耗时且不变性差,同样无法满足本文研究对象检测相关指标。
目前,最常用的方法是利用机器学习进行检测。尤其,具有优秀的自适应学习能力卷积神经网络在交通标志检测领域大显身手[3~4],并解决了人工定义特征的缺陷[5]。2014年,Girshic等最早将R-CNN(regions with CNN)引入目标检测领域算法,从而实现目标检测的端对端训练,提升了速度和精度。FPN算法[6]引入特征金字塔,为多尺度检测带来福音。YOLO系列算法[7~9]进一步简化检测问题。SSD算法[10]实时性表现优秀,但因其高分辨率特征有损,仍不能够满足交通标志多尺度检测要求。
分类识别阶段,传统方法包括手工制作的功能和常规分类器。通常,设计合适的手工制作功能具有挑战性且耗时。研究表明,CNN提取的特征更加稳健,这在德国交通标志识别基准(GTSRB)[11]上得以证明。Jin J[12]等以整体方式提出了一个三阶段CNN模型。Cireşan D[13]等通过平均几个深CNN模型的输出来呈现MCDNN。Zeng Y[14~15]等使用CNN提取深层特征和ELM进行分类。Razavian A S[16]等使用CNN模型提取的特征,并通过线性SVM在许多数据集上实现了良好的性能。以上所有这些都表明CNN比传统方法表现更好。
然而复杂自然环境中多尺度的检测以及快速准确的识别依然是交通标识避不开的技术难题。因此,本文提出一种多尺度交通标志检测和快速识别的改进方法。首先,提出了一种基于多通道融合的原图预处理方式;然后,研究了一种注意力机制与多尺度特征相结合的交通标志检测算法;最后,构建了一个多辅支卷积神经网络,如图1所示。

图1 交通标志识别流程整体框架图
2 多通道融合输入
多通道融合是在传统意义图像通道上的一种衍生,进一步挖掘像素值信息与原始边缘信息,从而大大减少了在复杂环境中错检现象。
1)第一个通道:YUV颜色空间变换后的128×64Y通道图像。
2)第二通道:YUV空间的三个通道64×32图像串联,并且空白处填零(64×32的全0矩阵组成)获得。
3)第三个通道:YUV三个通道经过Sobel边缘检测器计算水平和垂直边缘的大小形成的边缘图为前三个block,前三个边缘图中最大值为第四个block,四个大小相等的block组成第三个通道。多通道融合,如图2所示。

图2 多通道融合
3 本文检测算法的总体结构
为解决多尺度,尤其是小尺度交通标志的错检、漏检问题,本文在Faster RCNN算法的基础上提出一种改进算法。本论文引入特征金字塔(FPN)算法,使RPN获得自己相应的多个尺度特征并生成目标候选区域,从而获得目标的多尺度特征;同时为提升目标特征的判别能力,论文引入候选区域注意力模块,通过分析注意力模块中目标邻域特征提取上下文信息,最后交给分类器进行交通标志的检测的就不仅有多尺度特征,兼有上下文信息。其总体结构如图3所示。

图3 本文检测算法的总体结构
3.1 多尺度提取
3.1.1 特征金字塔FPN(Feature Pyramid Network)
特征金字塔网络分为自下而上路径,前馈计算,逐层增加特征尺度并逐渐分配强语义,直到达特征金字塔的底部,该路径特征映射目标定位能力强,但语义信息有限。论文中计算步长为2,卷积层5层,并提取得到各自特征图,特征图与输入图像的尺度比例分别为{4,8,16,32,64}。自上向下的路径作用为提高分辨率、丰富语义信息,该路径特征映射目标定位能力有限但其具有丰富的语义信息。横向连接主要起桥梁连接作用,合并自下而上路径与自上向下的路径中空间尺度等同的特征映射,从而增强特征表现力。最终融合后的特征图为{P2,P3,P4,P5,P6},其空间分辨率对应之前的{C2,C3,C4,C5,C6}。
3.1.2 基于FPN的RPN网络
常规的RPN由于落后的特征图感受野,无法满足实际环境中多尺度目标检测。为此,论文提出一个基于FPN的RPN网络。该网络中,金字塔每层的特征图上都分别增设一个RPN网络,这样RPN的输入不单单只来自于conv4卷积层,每层的RPN输入分别来自于对应卷积层处理得到特征图。不同层的RPN将生成不同尺度的锚框,扩大感受野,覆盖更多检测目标。通过IOU(intersec⁃tion-over-Union)与设定的阈值Th比较,分出正负样本。锚框由大到小进行排序后,非极大抑制运算筛选出一定数量的候选目标。
3.1.3 RoIAlign
常见的RoIPool算法操作会使特征图与真实图存在一定单位的像素差。对于大尺寸交通标志而言可能实际影响较小,但是对于一些小尺寸交通标志,其造成的影响是很大的。论文采用一种改进的候选RoI池化算法:RoIAlign,其主要思想就是取消了RoIPool中所采用的量化操作,从而避免RoIPool中量化带来的损失误差。
3.2 注意力模块
针对交通标志检测时,建筑、树枝等复杂背景的遮挡,都会造成很大程度的错检、漏检现象,论文引入了注意力模块。注意力模块本质上是引进一种空间位置软注意力机制,该机制中的上下文信息可以用于判断目标在图像中是否出现,并且从复杂背景中区分出交通标志。目标和背景区域的卷积特征,经过RoIAlign池化操作后,获得最终的融合上下文信息的多尺度特征。
4 多辅支卷积神经网络
卷积神经网络的全连接层后面通常接的是softmax分类器,softmax分类器是多类线性分类器。所以卷积神经网络(CNN)可以将原始的图像空间转移到线性可分离空间。同时,我们发现有些交通标志利用CNN提取低层特征就可以被分离出去,而并不用遍历整个卷积神经网络一直到最后才被分离出来。图4显示了CNN模型中从不同层提取的特征的分布。我们很容易发现矩形角形和三角形标志在前一层被隔离,而速度限制标志在后一层被隔离。符合认知,很容易识别形状(矩形,圆形和三角形),而识别限速标志较为困难。
根据这个发现,我们构建了一个多辅支卷积神经网络,该网络使部分交通标志在较浅层即被分离出来,在保持精度情况下,大大加快了交通标志的识别速度,如图5所示。

图4 CNN不同层特征提取分布图
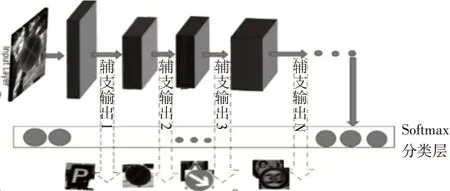
图5 多辅支卷积神经网络结构图
4.1 训练softmax分类器
在卷积神经网络中通过端到端方式训练soft⁃max分类器,在此不做过多赘述。
4.2 优化多辅支卷积神经网络
实验告诉我们提高识别速度并不是简简单单在卷积神经网络的每一层添加辅支。比如,一个很难识别的样本,需要到很深的层才能识别,如果每一层都添加辅支,那么这个样本通过前面每一层的辅支将消耗大量时间,这违背我们构建这个快速识别网络的本意。所以,这要求我们寻求最佳辅支组合策略:
Ci(i=0,1,2,…,n,n+1)表示第i层所添加的辅支。如果Ci=1,则意味着Li层添加辅支,如果Ci=0,则意味着Li层不添加辅支;ti(i=0,1,2,…,n,n+1)表示一个样本通过Ci辅支平均消耗时间;Si(i=0,1,2,…,n,n+1)表示样本集通过Ci辅支被分离出来所消耗时间;|S|表示样本集S中元素的数量。
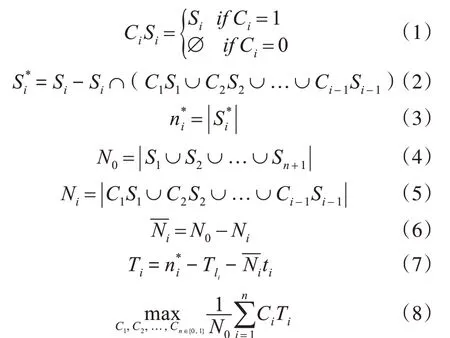
这是一个组合优化问题,我们很容易通过遗传算法优化该问题。
5 训练共享卷积神经网络与数据集
5.1 共享卷积神经网络策略
为简化网络,论文采用交替训练方式,共享ResNet卷积特征提取网络,分两个阶段迭代。
首先,直接选用预训练模型参数来初始化两个网络中卷积层的参数,其次,训练候选区域生成网络时,共享卷积层参数由候选区域分类网络中卷积层的参数来初始化,并微调不共享的卷积层以及其他层参数。训练候选区域分类网络时,固定共享卷积层参数,非共享卷积层的相应参数做微调,至网络收敛时,网络训练结束。
5.2 损失函数设置
论文实现了交通标志检测与识别的端到端训练,所以总损失包含两部分:检测阶段的损失Lp,识别阶段的损失Lc。

第i个锚框预测为目标的概率值为pi,则为真值,预测边界框的坐标用gi表示,则为坐标真值。计算Lreg时仅考虑正样本的边界框坐标。Lc为各辅支累计损失之和的最小值。最终网络模型参数通过最小化损失函数来优化,并实现其效果。
5.3 数据集训练
本文实验的数据集来源于两个公开数据集:德国交通标志检测数据集(GTSDB)和德国交通标志识别数据集(GTSRB)。GTSDB数据集包含了900幅图像,其中600幅用来训练,300幅用来测试。数据集中不同种类的交通标志样本数量不等,论文采用平移、旋转以及灰度变换等数据增广方法扩展数据集为3848张,3078张图像建立训练集,其余图像建立测试集。从而减轻训练模型的过拟合。GTSRB数据集总共包含51839张不同种类的交通标志图片,它包括43类不同种类的交通标志,并且都是在自然采集条件下获取的交通标志图片,其26640张图片用来训练,其余图像建立测试集。
6 实验与分析
本文算法在深度学习框架Caffe下利用Python语言实现,操作系统为Linux Ubuntu 16.04,实验硬件平台为Intel Xeon E5-1630 v3@3.7GHz四核处理器,Nvidia GTX 1080Ti 11GB GPU显卡,16GB内存。算法在两个数据集上测试的平均速度为4f/s。
6.1 检测阶段的实验结果与分析
检测阶段,主要任务是准确、高效提取目标候选域。目前,主流的提取目标候选区域的方法有Faster R-CNN,YOLOV2,YOLOV3,SSD,R-FCN等。上述主流方法对于大尺度目标有较好的检测效果,然而对于小尺度目标的检测效果并不理想。现实交通标志检测过程中,因拍摄距离的远近等因素导致尺度大小不一,所以交通标志在图像中所占据的比例大小也不尽相同。因此,根据交通标志在图像中所占据像素大小划分为三个区间:小型交通标志(0<面积<48像素×48像素),中型交通标志(48像素×48像素<面积<128像素×128像素),大型交通标志(面积>128像素×128像素)。在三个区间尺度下,本文方法与四种主流算法做了三组实验,图6为实验结果,图7和图8为不同场景下五种算法的检测效果对比图。

图6 本文方法与四种主流算法对多尺度交通标志检测的PR曲线
6.2 识别阶段的实验结果与分析
基于GTSRB数据集,我们选择AdaBoost算法、ZFNet卷积神经网络和VGG-16卷积神经网络三种经典识别算法与本文算法进行实验对比,从而验证本文所提出的识别算法是否具有高效性。我们做了两组实验,分别测试了四种不同算法对于四类交通标志的分类效果和实时性,实验结果如表1,表2所示。

图7 五种算法在场景一的检测效果对比图

图8 五种算法在场景二的检测效果对比图
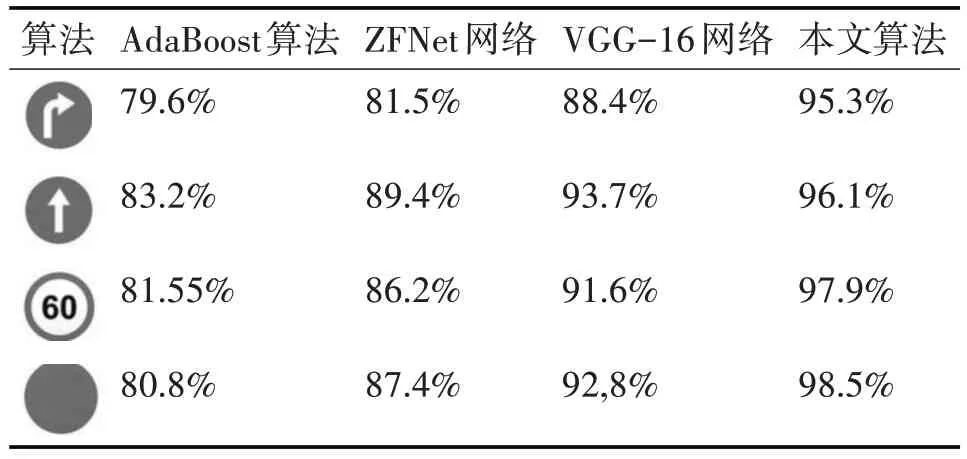
表1 四种算法中四种交通标志的分类准确率
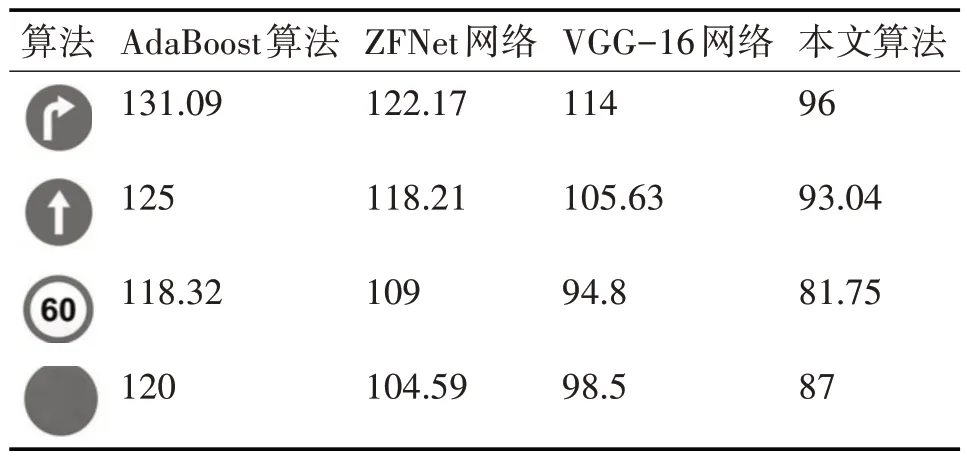
表2 四种算法中四种交通标志的识别时间(ms/帧)
表中实验数据显示,在准确率方面,四种算法中,本文算法是最高的。这是因为我们增加了多通道融合的预处理过程,同时也离不开检查阶段优秀的目标候选区域提取。
表中实验数据表明,在从实时性来说,本文的算法相比其它三种算法也是最快的,可以达到平均90ms/帧。这是因为识别阶段的多辅支网络结构的快速识别性能以及共享卷积网络使得整个网络的参数大大减少。
7 结语
本文首先采用多通道融合预处理方法。同时,提出了一种注意力机制与多尺度特征相结合的交通标志检测算法,该方法显著提高了对多尺度,尤其小尺寸的交通标志检测效果。最后,构建了一个多辅支卷积神经网络,在保持精度情况下大大提升了识别速度。通过在GTSDB和GTSRB数据集上训练测试,表明了本文算法对交通标志的尺度、形态变化以及复杂场景等影响因素具有良好的鲁棒性,可以更好地满足交通标识的实际需求。如何在提高多尺度交通标识召回率的情况下,进一步提高检测准确性和识别速度将作为下一步的研究内容。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
汽车实用技术(2022年9期)2022-05-20
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
小天使·一年级语数英综合(2016年8期)2016-05-14
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
小天使·一年级语数英综合(2014年7期)2014-06-26
