
基于Python的美食数据爬取及可视化研究
2021-06-28 17:46依力·吐尔孙艾孜尔古丽
电脑知识与技术 2021年10期
依力·吐尔孙 艾孜尔古丽

摘要:本文主要研究中国菜谱里面的美食词汇资源的爬取、构建、数据处理并对词汇资源进行数据可视化分析。本文首先采用Python语言使用Scrapy框架进行数据爬取并对目标网站的网页进行页面分析,采集的是豆果美食网里最新发布的中国菜系菜谱,然后用Pandas、Numpy等库进行清洗数据并做可视化分析。除此之外,用Pyecharts库制作各大菜系菜品量的饼状图。最后通过Jieba库进行中文分词处理,筛选出高频词汇并制作了词云图。为了使乏味的文本数据散发活力,深入分析数据,以词云图展示数据分析的结果,增加数据可视化。
关键词:美食词汇;Python;网络爬虫;数据分析;词云图
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)10-0019-02
Abstract: This paper mainly studies the crawling, construction, data processing and data visualization analysis of Chinese cuisine vocabulary resources in Chinese recipes. In this paper, we first use Python language to Scrapy framework to crawl data and analyze the web pages of the target website. We collected the latest Chinese cuisine recipes from the Douguo Cuisine Network. Then we use libraries such as Pandas and Numpy to clean the data and do visual analysis. In addition, Pyecharts library is used to make pie charts of the quantity of dishes in each major cuisine. Finally, word segmentation is carried out through JIEBA library to screen out high-frequency words and make word cloud map. In order to make boring text data exude vitality, in-depth analysis of the data, the word cloud map to show the results of data analysis, increase data visualization.
Key words: food vocabulary; Python; Web crawler; Data analysis; Word cloud
非典、新冠肺炎等致命性疾病讓人们更加意识到健康饮食习惯的重要性。人工智能、大数据的发展对饮食词汇数据的处理方面带来了便利。不仅,计算语言学、统计学等交叉学科的发展使得处理饮食词汇资源的数据引来了新思路和新角度,而且处理这些饮食数据资源促进了中国饮食文化、膳食结构、营养学、预防疾病学等学科方面的研究。
构建饮食词汇资源并进行数据可视化对研究民俗饮食有着重要作用,这些数据有利于分析各地民俗饮食的结构。为进一步开展食物资源和增加菜谱品种方面的研究,对各个地方不同菜谱的原料及其用料使用情况、食品加工、饮食制作、饮食命名和饮食传承有关的信息进行数据采集并对数据进行可视化研究是有必要的。
1 美食文本采集技术研究
1.1美食文本采集思路
随着人工智能和大数据的发展,网络上越来越大的数据量成为一种重要资源,如何从这些海量数据中快速有效的提取和分析有效数据并排除无效数据是信息处理技术的研究热点。获取网络上有效数据的方法是网络爬虫技术。实现Web爬虫技术,编写好网站爬虫的关键是利用更高效的爬虫工具和爬虫框架。于是Python语言提供了很多方便的爬虫框架。Scrapy是基于Python开发的一个高层次的快速的网页抓取框架,用于抓取Web站点信息并从页面中提取结构化的数据[1]。因此本文完成网站的数据提取任务时便用到了Scrapy框架。文中采用了Scrapy框架来对数据进行提取,爬取的对象是豆果美食网站菜式菜系的中国菜。
在进行爬取豆果美食网站数据之前,为了编写好代码的逻辑并更有效地提取该网站数据,应该要弄明白并且分析美食网站的域名结构和层次。分析研究的网站,其URL链接结构以主域名为中心?[2],主域名下分有豆果美食网站的首页、菜式菜系、中国菜等子域名,也就是导航部分。在子域名下是更详细的各种菜系URL信息。此网站的结构进行分析就能提取菜系菜品所有URL,但是会回到首页,因此进行URL的去重,建立环路。
该文爬取豆果美食网站菜式菜系里的所有中国菜系的菜品,获取的内容包括菜谱链接、菜谱、用户、用料、图片、评分、菜系。通过对网站页面的分析。通过美食网站的最新菜系页面提取全部菜谱数据代码,而不需要爬取所有URL。通过“最新菜系”网站获取全部菜谱的策略是对比页面跳转URL的变化,因此可以通过对数字的递增而得到所有数据。
1.2美食网站环境分析及采集
1.2.1美食网站页面分析
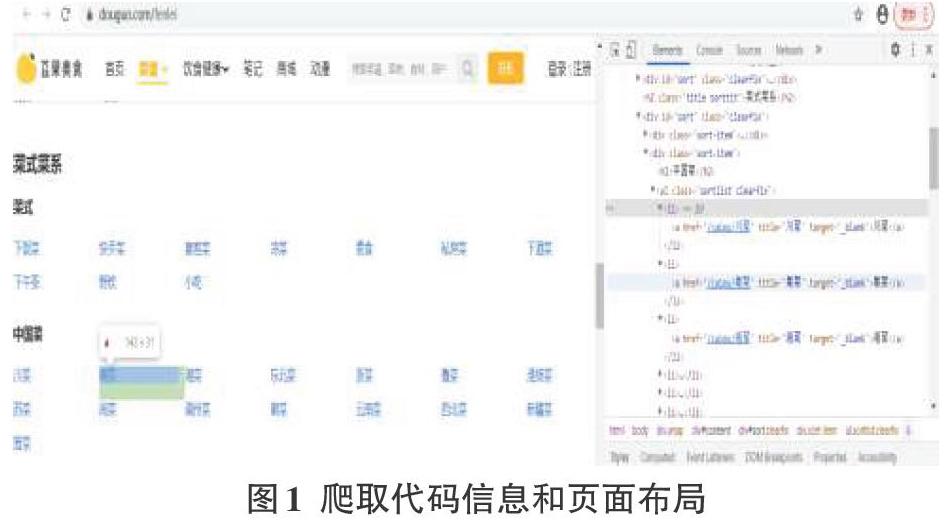
想要得到爬取规则和相应的代码信息,首先需要对美食网站内容进行结构分析。因此,进入豆果美食网,打开全部分类,找到菜式菜系目录下的中国菜。本次需要爬取的内容是中国菜下的苏菜、新疆菜、东北菜等十五个中国菜系。这里面有效处理提取的数据是各大菜系中的菜谱名,菜谱链接、图片、评分、用户名、用料、菜系。打开Chrome浏览器进入豆果美食网站后,查看全部分类找到对应的菜系,按F12键就能看到页面的布局和源代码信息。查看并分析这些中国菜的菜系标题都包含了属性为class的
通过源代码和页面布局分析,下面利用xpath表达式进行该网站的解析。为了解析每一条信息的语句,编写了一下语句:response.xpath("//div[@class='pages']/a/@href").extract()。该表达式不仅能匹配当前节点和文档中的节点,而且直接从全文中搜索所有id为'list'的结点。这样就能得到了该节点之后按照菜系所在的位置在该节点内部进行遍历搜索。这个程序就能得到了每条菜谱的详细页码连接和菜谱信息。
1.2.2数据处理及保存
经过以上表达式,让爬虫程序提取到了美食网站内的菜谱页面信息,可是想要进行完全处理数据,那么利用item对它进行格式化。文中定义一个名为DouguoItem的类,该类之后需要从网页中获取数据内容的集合,它们分别是menu:用来存放菜谱的信息,menu_link:用来存放菜谱链接,score:用来存放评分,user:用来存放用户名,img_link:用来存放菜谱图片,ingredient:用来存放用料信息,classify:用来存放菜系。
为了进行进一步的数据处理、数据分析以及数据可视化,因此有必要对这些数据进行保存。由于本实验数据量不大,而且Scrapy提供了多种格式的数据保存形式,因此使用简单的excel文件的形式保存数据。
2美食数据处理技术研究
为了方便后续的可视化分析,还需要对爬取数据进行处理。美食词汇处理过程分为数据清洗,删除重复项,缺失值处理,评分字段清洗和添加用料数字段等。由于本研究保存的是excel文本格式,为了更加高效地处理Excel中的数据使用到了pandas库。还用到了Numpy库,用这个库来整合爬取数据。本文用jupyter notebook来运行代码,首先,导入爬取到的菜谱数据,这个过程用了pd.read方法,并添加了列名。预览数据如下:
其次,用drop_duplicates方法来刪除爬虫过程中重复抓取的少量菜谱数据并通过dropna方法来删除缺失值。为了方便后续计算,提取到的评分字段里含有多余的object类型的字符串,需要替换到多余字符串并转换为数字类型。由于用料词汇中间都是以逗号分隔开,先算逗号数加一就能得出用料数。最后,利用用料词汇统计每个菜谱的用料数量,这样有利于分析菜谱用料。
3美食数据可视化技术研究
数据时代,通过数据分析来挖掘数据的价值,本文数据分析过程分为以下几个步骤:数据获取,数据读取,数据计算,数据可视化以及数据分析。分析代码和数据如图2所示。
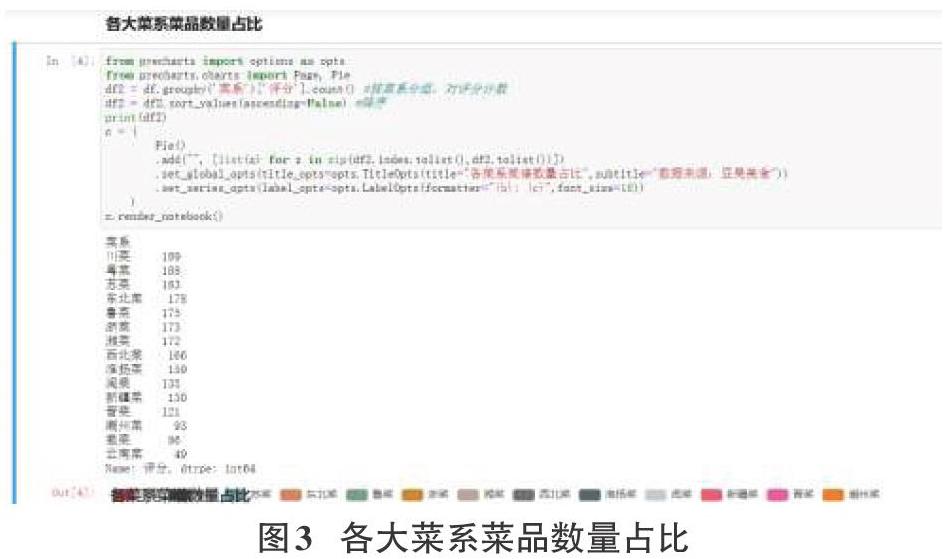
总爬取了2968个菜谱数据,通过数据处理,除掉缺失值和没有评分的数据后得到了最后的2197纯菜谱数据。数据分析后用Pyecharts库制作各大菜系菜谱数量占比饼状图展示出效果。
除此之外,为了充分利用中国菜谱数据,采用Jieba库来处理中文分词,然后进行词频统计便挑选出高频词汇,最后制作词云图来展示效果。尺寸越大表明该词汇的词频率越高,尺寸越小表明该词汇的词频率越低。
以上词云图里尺寸大的、比较显眼的菜谱用料是主要的川菜用料,比如花椒、干辣椒、大蒜和豆瓣酱。其他各大菜系菜谱用料的词云图也一样表示出该菜系菜谱用料情况。
4总结
本文首先探讨构建饮食词汇资源库在饮食文化中的重要作用。其次开展饮食词汇资源的获取和饮食词汇数据的充分利用。本研究涉及了网络爬虫技术、文本预处理技术、数据可视化等文本采集和数据加工技术并详细地给予该资源库的资源爬取、数据处理、数据分析以及数据可视化等过程和相关代码。
从高频词汇的分布情况分析可以为健康饮食模式推广提供多维视角与参考,健康饮食模式和膳食结构不仅影响人类健康,而且对我国经济发展、医疗支出、了解中国饮食文化等方面产生一定的影响。为了完善饮食词汇资源库,后续研究待需要爬取其他美食平台数据来补充资源。美食的烹饪涉及的影响因素还有很多,还需要思考和探索。
参考文献:
[1] 杜鹏辉,仇继扬,彭书涛,等.基于Scrapy的网络爬虫的设计与实现[J].电子设计工程,2019,27(22):120-123,132.
[2] 李培.基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程,2019,47(6):1415-1420,1496.
【通联编辑:唐一东】
猜你喜欢
中国新通信(2016年21期)2017-01-06
商场现代化(2016年22期)2016-10-18
