
小麦品种知识图谱构建与可视化研究①
2021-06-28 06:28:22岳金钊赵锦鹏王亚坤马新明钱学霖
计算机系统应用 2021年6期
许 鑫,岳金钊,赵锦鹏,王亚坤,马新明,钱学霖
1(河南农业大学 信息与管理科学学院,郑州 450002)
2(河南粮食作物协同创新中心,郑州 450002)
3(河南农业大学 农学院,郑州 450002)
信息化已成为农业现代化的重要组成部分[1],生产数据结构复杂且类型多样,数据可视化技术可以实现复杂的数据直观化、量化和简化,能大力的推动农业信息化的发展[2].
知识图谱作为大数据可视化和人工智能的重要组成部分被广泛应用[3].Google 将知识图谱应用在搜索引擎上[4],百度和搜狗相继推出了“知心”和“知立方”[5],苏宁易购发布金融企业知识图谱系统.蒋秉川等[6]利用地理知识图谱结合交互式可视化分析COVID-19 疫情态势;车金立等[7]构建了军事装备知识图谱,实现了军事装备领域的知识问答;李晓雪等[8]利用领域知识图谱技术进行了农作物病虫害分析和分类;张善文等[9]提出了一种基于知识图谱与Bi-LSTM 结合的小麦条锈病预测方法;华东师范大学[10]利用深度学习和自然语言处理构建了农业知识图谱;叶帅[11]将知识图谱引入到煤矿领域.知识图谱在各个领域都有应用,但在农业领域的应用和技术体系尚待研究[12].
目前的农业数据分散化、种类多、连贯性差,挖掘有价值的信息是未来研究的重点[13].知识图谱技术可以将离散的、不集中的信息与可视语义网络关联[14],便于通过图的形式直观地掌握和分析关系错综复杂的领域知识,实现精确查询[12].
本研究以小麦生产知识为研究对象,获取网络中现存的凌乱复杂的知识,探索农业领域知识图谱的构建方法,设计小麦品种图谱实体和关系,通过知识图谱直观、清晰地展示错综复杂的品种知识,以期为小麦生产知识的精准推荐,农业知识图谱的构建提供技术方案依据.
1 小麦品种知识图谱框架设计
知识图谱可分为通用知识图谱和行业知识图谱[15].通用知识图谱都是常识性的知识,面向全领域,覆盖面较广,但深度不足,主要应用于互联网的搜索、推荐等业务场景,如:FreeBase[16]、DBpedia[17].行业知识图谱覆盖特定领域的知识,知识的深度相比通用知识图谱较深,行业知识图谱需要收集特定领域的数据,结合业务流程在领域专家的指导下来构建知识图谱模式之后构建数据层[18].本研究结合互动百科通用知识图谱和小麦生产行业知识图谱,通过获取小麦品种等生产数据,经过清洗、整理、知识抽取等步骤,构建小麦生产领域知识图谱,如图1所示.
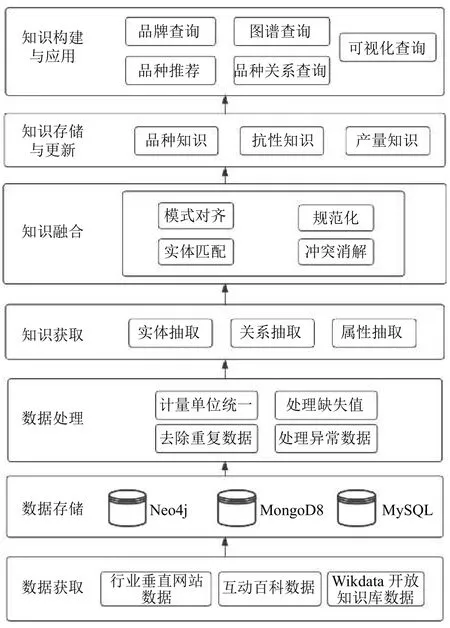
图1 图谱构建流程图
(1) 数据获取、存储与处理:数据获取之后需要对数据进行清洗、预处理,提高数据的利用率,增强知识图谱的准确性.本研究选取行业垂直网站、在线百科、开放知识库等多个源头获取数据,提升知识图谱的丰富性和有效性.对于不同源头的不同类型数据,进行分别存储.结构化数据存储在MySQL 数据库中,非结构化数据存储在MongoDB 数据库中.获取到的数据往往会存在残缺、错误、重复等问题,需要对数据进行计量单位统一、处理缺失值等处理.
(2) 知识获取:针对不同类型数据采用不同的知识获取方式,对于结构化数据,各项之间存在明确的对应关系,可以直接构建三元组;而半结构化数据,存在一定的结构,需要进一步提取,将半结构化数据转化为结构化数据.非结构化数据,利用自然语言处理(Natural Language Processing,NLP)技术对文本进行分段、分句、分词、去除停用词等处理,进而进行命名实体识别和关系抽取.
(3) 知识融合:不同来源数据会导致整体数据格式复杂,出现实体属性名称不一致,数据类型冲突等情况.所以需要把将要抽取的知识和知识图谱现有的知识做融合处理,以消除矛盾和歧义.选取实体的属性作为特征,构建特征向量,利用相似度计算,将新的实体与知识图谱中现有的实体进行链接[19].
(4) 知识存储与更新:在传统的关系型数据库存储中,存储大量关系复杂的数据之后,难以直观的描述实体与实体之间的关系,每次查询都需要联结大量表,造成查询效率低.而基于属性图形模型的Neo4j 数据库不仅能够直观的反应实体之间的关系,还能够大大地提高查询效率[18].利用Cypher 图数据库查询语言来解决知识更新问题,易于理解,方便用户对不合理的图数据进行更新操作.
(5) 小麦领域知识图谱的构建与应用.将收集和整理好的数据,结合小麦领域知识的特点,构建知识图谱.利用Neo4j 来负责小麦知识图谱的存储,将构造好的三元组——“实体-关系-实体”,利用Cypher 语言存储到数据库中.从用户自然语句中提取实体和属性,将实体和属性注入到Cypher 查询模板中,实现在小麦知识图谱中进行查询,在此基础上,研究开发小麦知识图谱查询系统,实现了品种推荐、实体查询、关系查询、可视化查询等功能.
2 关键技术设计
2.1 多源异构数据的获取与处理
数据来源主要包括3 个部分:从小麦行业垂直网站上得到小麦品种数据、在线百科获取百科数据、开放知识库获取领域实体及实体之间的关系数据.
品种数据作为小麦生产行业知识主要针对于某一特定领域的专业性网站或数据库,内容集中,专一,内容数据多偏半结构化数据,但在数据一致性和完整性方面与通用的知识库相比更加完善,通常需要先分析数据结构,获取数据后按照其结构解析[15];利用互动百科[20]中的微百科(category system)和词条信息模块构建本体;目前已有很多开放知识库,如德国马普研究所开发的Yago[21]、复旦大学开发的CN-DBPedia[22]、多语言并存的DBpedia[17]等.也有垂直领域的知识库,如浙江大学维护的新冠开放知识图谱、清华大学的影视双语知识图谱[23].本研究利用Wikidata[24]完善本地知识库中节点关系,以便构造“实体-关系-实体”三元组.
获取到的数据往往会存在残缺、错误、重复等问题.需要对数据进行清洗,剔除无用数据.数据清洗融合主要包含数据中含有干扰字符、字段冗余、非结构化文本处理、计量单位不统一等,按照不同的类型进行单独的处理与转换.
2.2 知识图谱的表示和存储
知识图谱的表示和存储是将学术实体以及实体之间的关系按照一定的数据描述模型,进行存储的过程[25].知识图谱中的知识表示方法是以本体为核心,以RDF的三元组模式为基础框架,但更多的体现实体、类别、属性、关系等多颗粒度多层次的语义关系.
知识图谱的表示和存储方法使用较广泛的有RDF存储、图数据库存储、关系型数据库存储3 种.国内的一些学者已将其成功的用于医学领域知识图谱的存储中[26,27].但由于RDF 存储模型设计上不够灵活,且查询时间复杂度高,所以不适合作为知识图谱的表示工具.Neo4j是一个图数据库,属于非关系型数据库,它具有高性能、嵌入式、轻量级的优势.Neo4j 以边、节点或属性的形式存储,而不是以表的形式存储,对于处理具有复杂关系的海量的知识数据来说是一个利器[28].Fatima 等[29]在社交网络场景下,比较了Neo4j 图数据库和MySQL 数据库的表现力.Neo4j 数据库的关系模型可以表达面向网络的数据,与关系数据库相比,Neo4j 可以在存储数据时连接数据,使其能够更快地遍历关联数据,从而存储数以万计的节点和关系,且随着图谱数据量的不断增大,关联查询的效率远高于关系型数据库,因此利用Neo4j 实现知识图谱表示和存储是较便捷、高效的方法.
2.3 知识图谱设计
知识图谱是一种对于事实的结构化表征,主要由实体、关系、语义3 部分组成.当数据量大,结构和来源复杂时,用知识图谱将结构复杂、碎片化数据关联的方式来表示知识会更加清晰准确.目前,通用知识图谱构建主要包含数据获取与处理、知识抽取、知识融合和图谱应用4 个阶段[30],如图2所示.
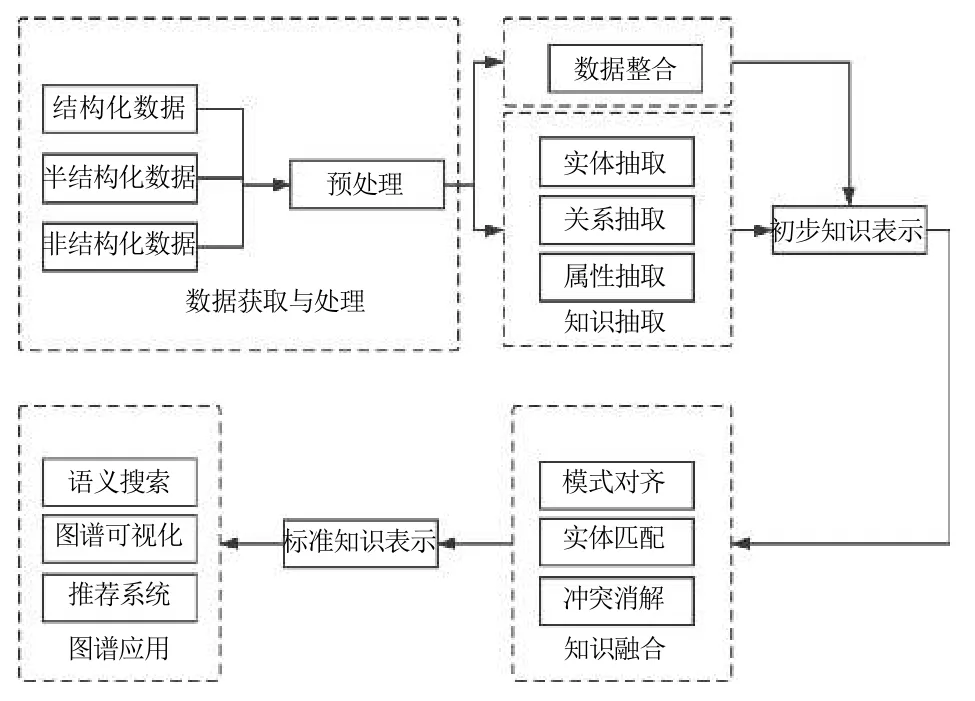
图2 知识图谱处理流程
数据是知识图谱的基础,从不同结构数据源获取到的领域相关知识做预处理,对不同来源不同类型的数据进行清洗和入库处理,目前有很多相关工具,如清华大学开发的THULAC[31].
知识抽取是从预处理后的数据中自动创建实体和实体关系的技术[32],是知识组织和信息融合的跨学科技术,根据数据结构的不同分为结构化、非结构化和半结构化的知识抽取.对于结构化数据,有明确的对应关系,可以直接构建.而半结构化数据是指存在一定结构但还需要加工整理的数据,抽取时可采用构建包装器的方式.非结构化数据处理起来较麻烦,所使用的方法有基于模板、基于监督学习等[19].
经过知识抽取后,根据表1设计小麦的实体类型和关系模型,从而构建“实体-关系-实体”三元组,实体设计如表2所示,关系设计如表3所示.
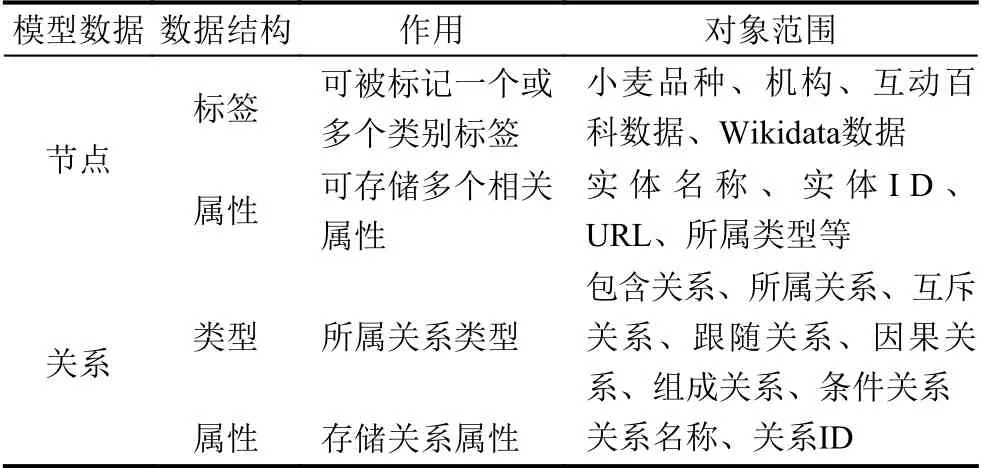
表1 实体、关系模型
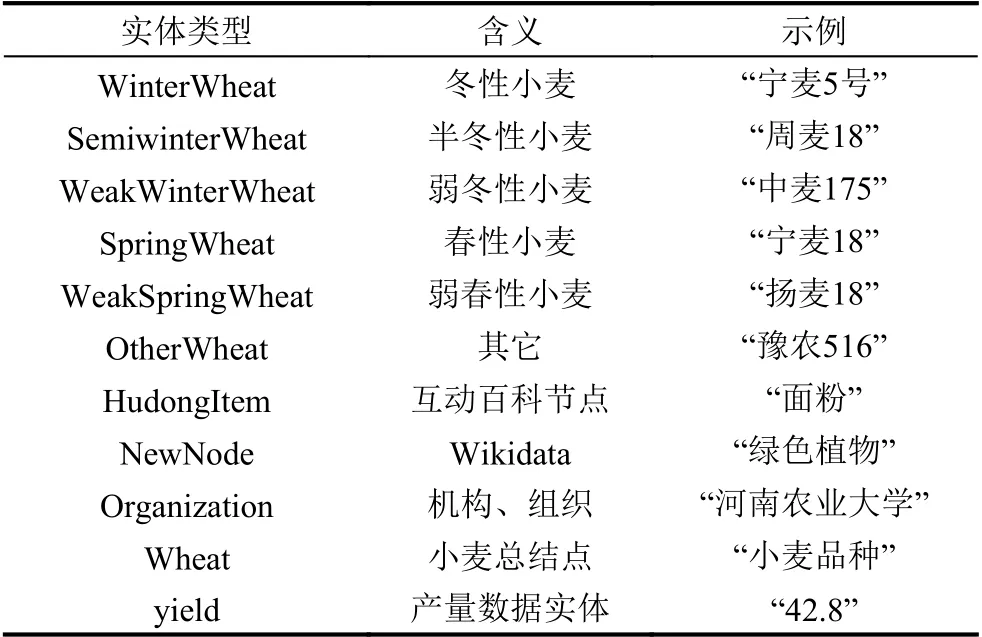
表2 小麦知识图谱实体设计

表3 小麦知识图谱关系设计
基于实体和关系的设计,将数据取出,通过Cypher语句存入Neo4j 数据库中,实体和关系都能拥有特定的标签,有利于节点和关系的分类,也方便后期查询系统进行查询.
在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,采用余弦相似度的方式表示两个实体对象的相似程度,相似度介于−1和1 之间,其中−1 表示两个对象完全不同,1 表示完全相似.例如,比较两个小麦品种时,选取小麦的重要特性(产量、特征特性、抗性等)作为特征值,接着将特征向量化,最后带入式(1)进行计算.
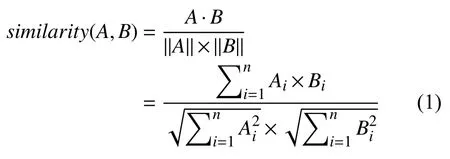
经过知识融合的处理,形成较为标准知识图谱,在知识图谱的基础上开发语义搜索、可视化管理等应用.
2.4 知识图谱数据物理存储设计
知识图谱数据类型多样化,为了提高效率,针对不同数据进行合理存储设计,数据的存储架构如图3所示.
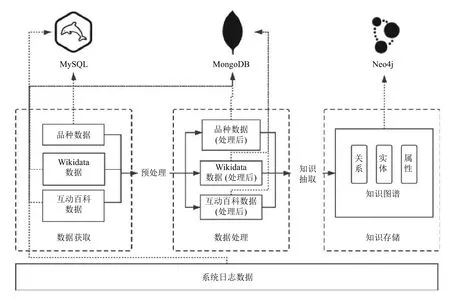
图3 数据库物理架构
在数据获取阶段,品种数据存储在MySQL 结构化数据库中,而Wikidata 数据和百度百科词条数据存储在MongoDB 非结构化数据库中.
在数据清洗阶段,处理品种数据中存在的字段冗余等问题后,品种数据含有的属性个数不一致,选取MongoDB 来存储处理后的数据,以减少冗余数据,提升空间利用率.处理后的Wikidata 数据和百度百科词条数据仍然存储在MongoDB 中,对处理后的实体、关系和属性数据存储在Neo4j 数据库中.
3 知识图谱系统构建与应用
3.1 品种知识图谱的构建与实现
选取“种业商务网”[33]来获取关于小麦品种的数据,用BJSON 的格式存储在MongoDB 数据库.MongoDB数据库采用,便于保存不同的属性数据,共获取1852条品种数据,品种类型丰富,包括冬性小麦、半冬性小麦、春性小麦、弱春性小麦、弱冬性小麦等多种.品种的信息包括审定编号、选育单位、品种来源、特征特性、抗性鉴定、品质分析、产量结果等多个维度.
将“农业”的微百科作为种子网站,爬取所有的微百科,然后获取微百科中的所有词条,共获取735 个微百科,词条数102 349 个,通过知识抽取出实体和实体与实体之间的关系,最终构建的知识图谱共有实体258 484 个,关系 328 933 个,采用图数据库Neo4j 来存储实体和关系,小麦知识图谱的局部结构,如图4所示,相同颜色的“圆”属于同一种实体类型,不同“圆”代表不同的实体,“圆”之间的箭头代表实体与实体之间的关系.“圆-箭头-圆”对应 “实体-关系-实体”三元组,例如:“徐农029–品种来源-淮麦20”表示“淮麦20”是“徐农029”的品种来源.并且,每种实体类型都有一个中心节点,用来描述该类实体,例如图中的“半冬性小麦”所指向的实体类型都是“半冬性小麦”.
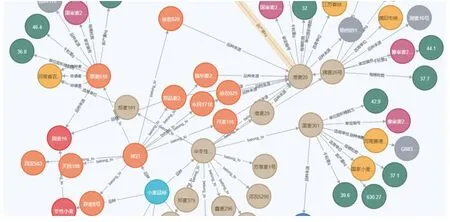
图4 小麦品种知识图谱
3.2 品种知识精准查询与可视化
由于Neo4j 数据库高查询性能以及查询语言可定制化,不仅可以查询实体与实体之间的关系,还可以实现品种的精确查询,以返回快速、精准、结构化的知识.品种知识的查询基于Neo4j 图数据库的可定制化Cypher 查询语言,将实体和属性注入到Cypher 查询模板中查询出相应的节点数据,然后将数据封装利用D3.js 可视化框架将数据可视化,从而实现图谱中结点和有向关系的直观展示,如图5所示,可以实现品种数据的实时可视化展示分析.
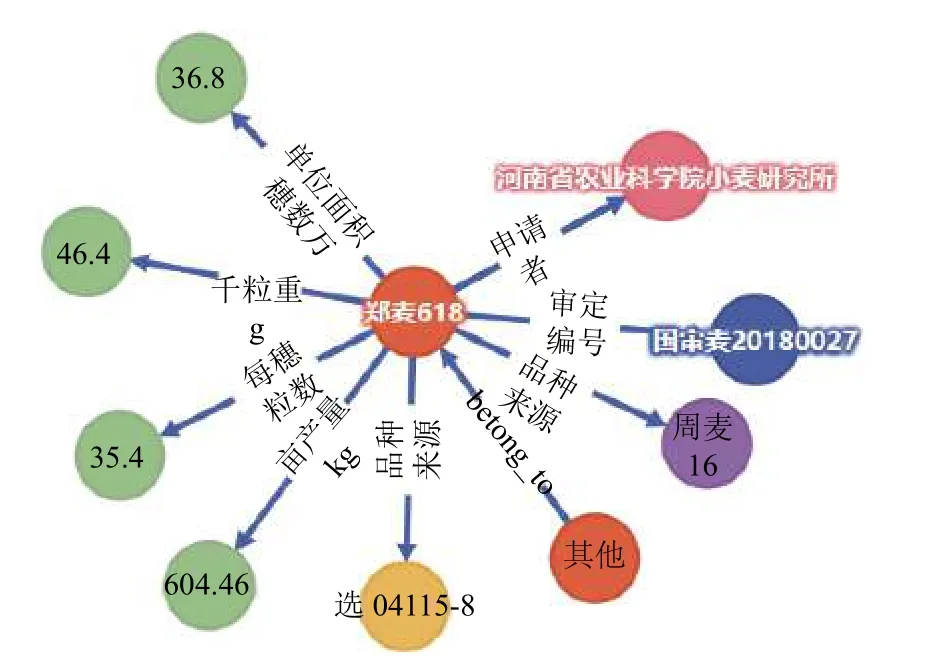
图5 知识图谱检索
4 结论与展望
本研究基于爬虫技术,利用Neo4j、NLP 以及图谱构建技术,经过数据收集与整理,知识获取,知识融合,知识存储等步骤,解决现存的知识重复、知识间的关联不够明确等问题.建立了标准的小麦品种知识图谱体系,在此基础上,使用Neo4j 图数据库存储小麦知识图谱,建立了小麦品种知识图谱查询系统,提供品种知识的关系查询、实体查询、品种推荐等功能,实现了品种知识的精准查询与可视化分析.
基于Neo4j 图数据库的定制化Cypher 查询,利用D3.j 进行数据可视化,为农业知识的精确查询和可视化提供了新的途径,同时也为知识图谱技术在农业生产的应用与落地提供了技术参考.在未来的研究工作中,要不断的充实建立的知识图谱体系与系统,实现知识的及时更新与充实.此外,利用NLP 技术,结合知识问答系统,实现农业知识的智能问答推荐也是一个很有价值的应用方向.
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19 13:34:44
少先队活动(2020年12期)2021-01-14 01:47:40
计算机教育(2020年5期)2020-07-24 08:53:00
创新作文(5-6年级)(2019年3期)2019-09-03 05:14:59
作文评点报·低幼版(2018年31期)2018-09-27 12:21:52
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
计算机工程(2015年8期)2015-07-03 12:20:35
小溪流(故事作文)(2014年6期)2014-07-31 14:21:14
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
