
基于深度学习的医疗数据智能分析算法研究
2021-06-27 03:26:02朱铁兵柏志安
电子设计工程 2021年12期
朱铁兵,柏志安
(上海交通大学医学院附属瑞金医院计算机中心,上海 200025)
在现代医疗技术中,医疗预测的成本较大,在可用性上也受到了限制,现代电子病历的智能分析[1-2]有望成为一种迅速、低成本的解决方案。电子病历由医务人员在临床医疗活动中使用健康信息系统捕获,包含详细描述患者健康状况的文字、符号、图表、图形、数字与图像,主要由结构化与非结构化数据组成。其中,非结构化数据包括自由样式的文本[3-4],如主要症状、病程进度与出院总结。尽管这些文本特征便于记录疾病、症状、测试和治疗,但对自动挖掘医疗信息以构建智能辅助诊断的临床决策系统造成了障碍。为消除这些障碍,命名实体识别技术被广泛应用于电子病历中疾病、症状、测试与治疗信息的抽取[5-6]。但目前国内外对命名实体识别的研究,主要集中在传统的命名实体模型能否有效识别EMRs中的命名实体。此外,由于缺乏可供研究的资源,从中文命名实体中挖掘命名实体的研究较少[7]。
近年来,深度学习技术作为一种流行的大数据分析方法,在一些研究中被应用于提高网络学习机器的性能[8-10]。然而,目前的研究主要集中在利用传统的NER 方法从EMRs 中挖掘命名实体[11-12],且没有一个模型能够在无需传统机器学习模型的帮助下通过深度学习的方式在EMRs 中实现[13-14]。虽然深度学习已成为构建神经网络模型的一种有效的特征提取方法,但在复杂的特征提取与选择的过程中必须依赖于传统的机器学习模型,如支持向量机(SVM)或条件随机场(CRF)来构建这些神经网络模型[15-16]。因此该文尝试在不使用传统机器学习模型的情况下,设计一个基于卷积神经网络与单词嵌入的NER 模型来完成EMR-NER 任务。该文构建了一个带注释且在电子病历首页增加了质控核查的电子病历语料库,然后提出了一种基于CNN 的多类分类方法来完成EMRs 中的NER,通过实验验证了方法的有效性,并根据研究结果给出了潜在的研究方向[17]。
1 EMRs中的命名实体识别
命名实体识别信息抽取技术的一个关键子任务,是将由单词组成的命名实体在文本中分类为预定义类别。NER 可以定义为一个多分类问题,即对一个实体词进行分类,如式(1)所示。

其中,N与T分别表示单词数与命名实体类型数。此任务也可以用序列标记任务,例如:x可以标记为,y可以标记为其中,l表示单词与标签的数量,表示第i个字,表示第t个字。
在该文研究中,注释数据被标记为BIO 格式用于构造NER 方法。其中,每个单词被分配到3 个类中的一个,B:实体的开始;I:实体内部;O:实体外部。电子病历中的命名实体识别是指从临床笔记中挖掘概念或事件作为实体,用于构建辅助决策的信息系统,帮助医务人员进行决策。图1 给出了电子病历句子中以BIO 格式标注实体的示例。每一个单词的标签均是根据其实体类型标注的,类型由专业医生确定,并用BIO 格式手动标记的。例如,将“青霉素过敏史”分为“青霉素”与“非青霉素过敏史”,“青霉素”与“过敏史”分别标上“B 病”与“I 病”。其中“B”与“I”分别表示词在命名实体中的位置信息,“病”表示命名实体的类型,NER 技术则应用于自动标记这些标签。

图1 命名实体识别标记结果示例
2 数据集
该文研究是基于某医院不同科室的992 份电子病历进行的,这些病历中包含的私人信息已被删除。每份电子病历的记录由两位医生(A1 与A2)独立注释,若两位医生均给出相同的意见,则注释是固定的;若意见不一致,则进行深入讨论,直至就注释达成一致。在经过两轮注释,最终获得了包含992个EMRs 的金标准。
最终的金标准使用5 类命名实体,即疾病、症状、治疗、测试与疾病组的诊断和治疗过程。在对语料库进行注释后,使用注释间一致性(IAA)来评估两个注释者的一致性水平。两位医生的IAA 值为94.20%,说明利用标注的语料库作为数据集对模型进行训练与测试是可靠的。
表1 给出了数据集的一些统计数据,包括文档、句子、字符与实体的数量。在992例EMRs中,每种命名实体的分类为47.69%的症状、20.96%的疾病、17.60%的检查、13.20%的治疗与0.56%的疾病组。治疗与测试命名实体几乎平均分布在出院总结与病程记录中,而症状实体主要分布在急诊室。这些数据集分为5个部分:4个部分用于训练模型,一个部分用于测试模型,并使用五折交叉验证来评估NER方法。
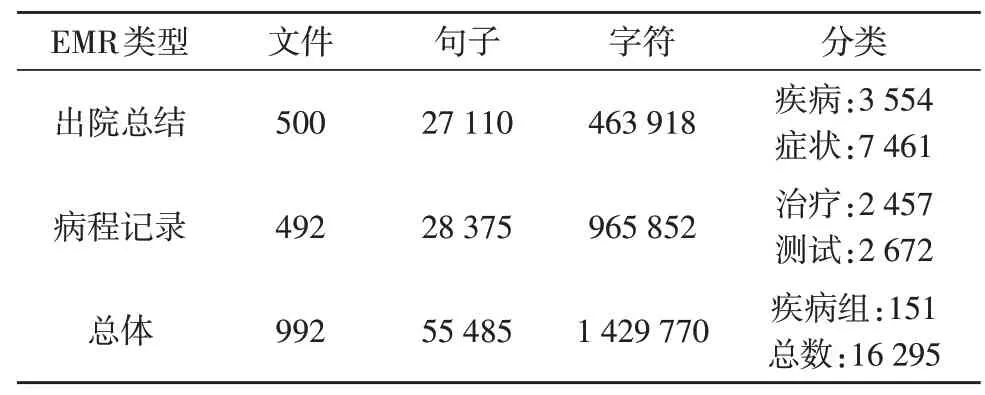
表1 电子病历中文件、句子、字符和实体的数量
3 设计方法
该文基于CNN 的EMRs 命名实体多类分类方法分为两个阶段:在第一阶段,对EMRs 进行预处理,选择与提取特征并标记单词;在第二阶段,建立基于CNN 的多类分类模型。该方法的两阶段框架如图2所示。在第一阶段中,使用文本提取器从EMRs 中提取句子并删除相同句子。

图2 基于CNN的神经网络多类分类模型框架
在第二阶段,首先使用词向量来表示样本,样本表示为一对标签与一组词向量。例如,单词wi可以使用其自身的标签与相邻词的词向量表示,表达式为
其中,l表示其命名实体类型的标签,wvi表示wi的单词向量。然后使用一对一策略将样本划分为子集,并在这些子集上训练模型。其过程如图3 所示。样本集根据标签对的划分被分割成多个子集。例如,若样本集中有3 种标签(即a、b与c),则集合将根据标签对的组合(如{(a,b),(b,c),(a,c)})被划分为3 个子集。其次,利用CNN 对每一个子集训练一个二值分类器,从而得到多个分类模型。在预测过程中,根据这些分类器对预测的投票结果来生成测试样本的标签。

图3 基于CNN的模型训练框架
4 实验分析
4.1 特 征
给定一个句子,S=wk-2wk-1wkwk+1wk+2wk+2…,其中在特征集中定义wk和以wk为中心的n个图形:
1)以一元语法与二元语法形式显示令牌的字级信息;
2)以一元语法、二元语法与三元语法形式显示POS(词性标注,Part-of-Speech)标记的语法信息。
特征模板使用的是Stanford 分词器与Stanford 单词分析器中的特征模板,以便在包含朴素贝叶斯(Naive Bayes,NB)、最大熵原理(Maximum Entropy,ME)、SVM 与CRF 的传统机器学习模型的基础上构建NER 模型。对于文中的方法,使用Tensorflow11 提供的CNN 来构造多类分类方法,关键参数有:面板为3×3,池为2×2,层数为2。
4.2 评价指标
文中从NER 的评价指标(即准确率、微F-Mesure值与宏F-Mesure 值)方面来评估NER 方法的性能。微F-Mesure 数值受样本数量的影响大于其他类别,其计算方法如下所示。

其中,true positive(c) 表示c类中与金标准相同的实体标签计数;false positive(c)表示c类中与金标准相同的发散标签计数;false negative(c)表示c类中与金标准不相同的实体标签计数。
宏F-Mesure 值(F)由准确率值(P)与召回率值(R)定义,如式(5)~(7)所示。

其中,TP表示与金标准相同标签的实体标签计数;FP表示已识别实体标签中与金标准相同的发散标签计数;FN表示已识别实体标签中与金标准不同的标签的计数。
宏F-Mesure 值的计算方法如下所示:

其中,Nc是实体类别数,Pi、Ri与Fi表示第i类实体的识别数值。
4.3 实验结果
实验分别用宏值、微值与准确率来评估传统方法与文中所提方法的性能。从表2 与表3 的结果可见,多类分类方法较基于CRF 方法的整体精度低。然而由于识别长实体的结果存在误差,其准确度低于微F-Mesure 值。换言之,若实体由多个单词组成,则这些单词的实体类型不能同时使用正确的标签进行标记。不同实体类型的识别结果比较表明,测试实体的识别准确率最高,而疾病组实体的识别准确率最低。
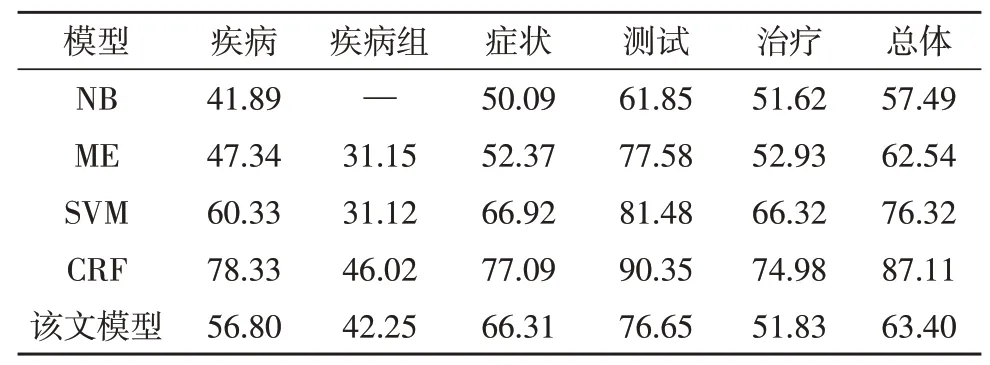
表2 所提方法与传统方法在出院总结的准确率比较(单位:%)
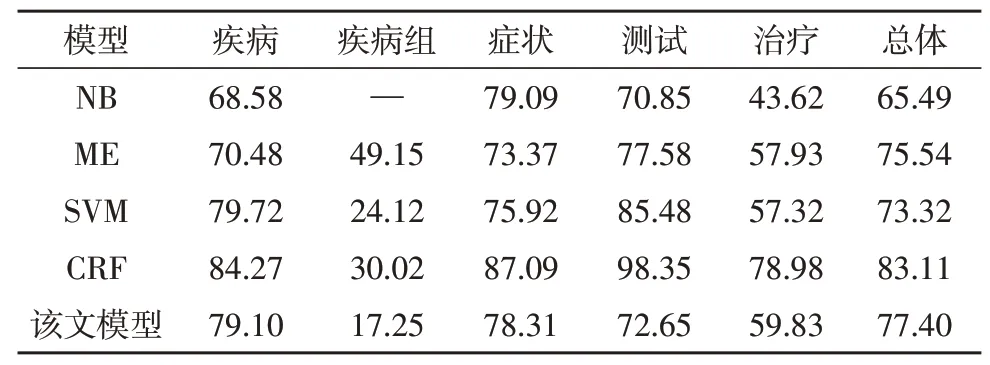
表3 所提方法与传统方法在进度注释的准确率比较(单位:%)
由于实验模型与传统模型未使用相同特征的训练集来训练,所以上述的比较并不是在相同的条件下进行的。因此,还需要使用相同特征的模型进行训练再比较结果。最终结果如表4 所示。结果表明,多类分类方法与基于CRF 方法在出院总结的NER 模型性能差异约为3.77 %,而在病程记录上的性能差异约为3.39 %。虽然该文设计的方法在性能上低于基于CRF 的NER 模型,但这恰好说明了所提出的方法在电子病历中的实用性。

表4 所提方法与同类方法的性能评估比较(单位:%)
5 结束语
该文构建了一个由992 个电子病历组成的语料库,并用5 种实体类型进行人工标注。然后,研究文中提出多类分类方法在语料库中识别医学命名实体的性能。实验结果表明,分词与词性信息均可为构造NER 方法创建有用的特征。该方法在出院总结与病程记录上的微F值分别为88.64%与91.13%;而基于CRF 的NER 方法的微F值分别为92.41%与94.52%,高于传统方法略低于CRF 方法。实验结果验证,基于CNN 的多类分类方法对电子病历中命名实体的挖掘是有效的。为进一步提高NER 的性能,下一步可以通过建立一个解析器系统来提取信息的特性,如POS 特性以获取更多信息。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18 05:52:42
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:16
中国外汇(2019年18期)2019-11-25 01:41:54
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国卫生(2016年10期)2016-11-13 01:07:44
