
基于MySQL 的数据库查询性能优化
2021-06-27 03:25宋永鹏
电子设计工程 2021年12期
宋永鹏
(山东气象信息中心,山东济南 250031)
MySQL 是现今最流行的开源关系型数据库,MySQL+PHP 的开发环境是使用最广泛的Web 应用开发组合,文中测试环境使用山东省气象部门图片资料云平台的MySQL 数据库。数据库的查询操作越来越成为整个应用的性能瓶颈,对于Web 应用尤其明显[1],一个应用的吞吐量瓶颈往往出现在数据库的处理速度上。随着应用程序的使用,数据逐渐增多,数据库的查询压力也逐渐增大。查询语句的性能体现在数据库的响应时间上,过多的重复查询以及耗时过长的操作会影响数据库的性能。而数据库的性能无法只依靠数据库管理员的日常维护来提升,同样是程序员需要去关注的。优秀的库表设计结构和数据库操作(尤其是查询数据表的SQL 语句)可提高数据库的响应速度,进而提高应用的用户体验度,缩短Web 应用的响应时间并避免对其他应用组件的影响[2]。
1 测试环境
测试硬件为Dell 一体机+4G 内存;测试软件为Win7 操作系统+MySQL5.5+山东省气象部门图片资料云平台Pic 数据表(表1)。为了测试4 种查询优化技术在不同数据量下的影响,利用数据库存储过程对Pic 表分批次插入海量的数据,分别是3 000 条、3 万条和30 万条。
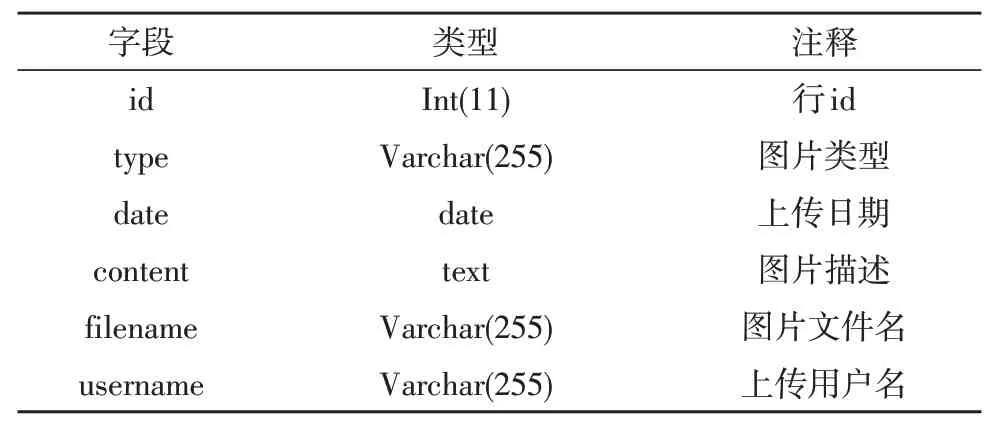
表1 山东气象部门图片资料云平台Pic表
2 索引的使用
索引是从数据中提取的具有标识性的关键字,并且包含对应数据的映射关系,为特定的数据库字段进行算法排序,能够帮助存储引擎快速找到记录[3]。MySQL 索引的建立对于数据库的高效运行很重要,类似通过汉语字典的目录页按拼音和部首查字的功能,查询语句通过对字段的索引能够大大提高检索速度[4]。
2.1 数据库响应
开启MySQL 性能分析功能后,对Pic 表使用Show Profile 语句,分别计算Pic 表包含索引和不包含索引时的数据库响应时间。分别在3 000 条、3 万条和30 万条的测试数据背景下,通过查找date 字段特定值数据的查询语句测试不包含索引和包含索引时数据库的响应时间。图1 所示为数据表中包含3 000条数据时date 字段不带索引和带索引的查询语句以及数据库响应时间。
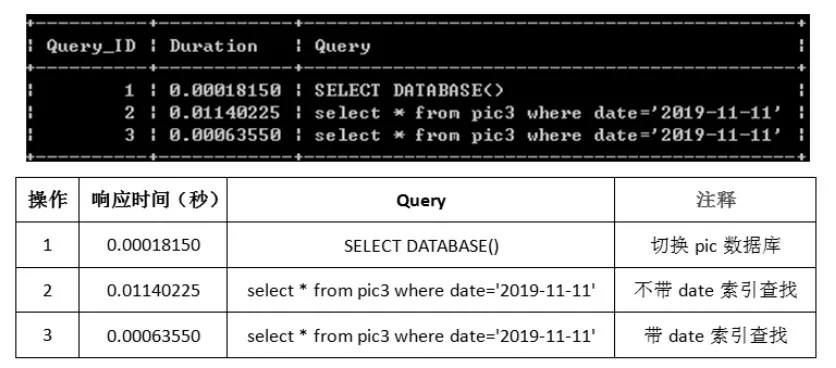
图1 索引对3 000条数据量的查询影响
图1 的黑色背景是MySQL 自带命令行的截图,白色背景是由文中整理所得结果。当查找date 字段值是2019-11-11 的数据时,不带索引与带索引的数据库响应时间分别是0.011 4 s 和0.000 636 s,带索引的响应速度是不带索引的18 倍。使用存储过程依次向Pic 表中插入3 万条和30 万条数据,分别进行条件为date 字段值是2019-11-11 的查询测试,结果如表2 所示。
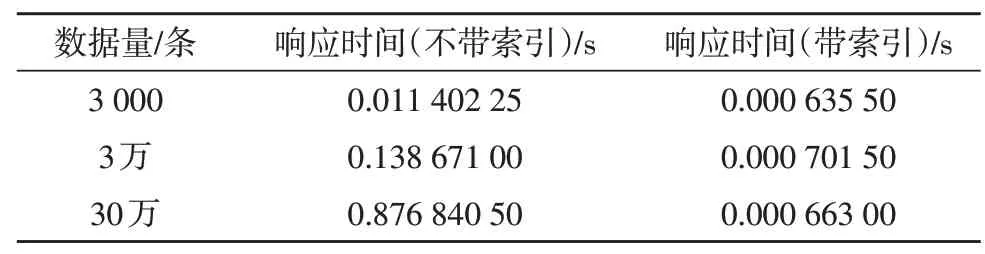
表2 索引在不同数据量下的查询性能影响
由表2 可知,Pic 表有3 万条数据量时,不带索引与带索引的数据库响应时间分别是0.138 671 s 和0.000 701 5 s,带索引的响应速度是不带索引的197倍;表中包含30 万条数据量时,不带索引与带索引的数据库响应时间分别是0.876 840 5 s 和0.000 663 s,带索引的响应速度是不带索引的1 323 倍。将数据量和数据库响应时间分别作为X、Y轴,作出带索引和不带索引的excel 对比折线图,如图2 所示。

图2 索引对于数据量搜索的影响图
通过图2 分析可知,带索引的搜索和不带索引的区别是,带索引的数据表搜索在3 000 条至30 万条的数据量之间数据库的响应时间接近0,而且几乎不变;不带索引的搜索随着数据量的增多会延长数据库的响应时间。
2.2 页面加载
上一节内容已说明索引对数据库响应速度的影响,对30 万条数据进行查询的数据库响应时间比不带索引缩短0.88 s 左右,文中利用Google Chrome 开发者工具对页面加载时间进行对比分析。创建索引时,需要的索引应用在SQL 查询语句的条件中,一般作为where 子句的条件,索引就像汉语字段的目录页,可以按照拼音和偏旁笔画快速查到需要的字[5]。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以在进行表的插入、更新和删除操作时,MySQL 不仅要操作数据,还要操作索引[6]。
不带索引的搜索页面加载时间为2.5 s,带索引的页面加载时间为1.5 s。现代快节奏的生活使得web 应用自然倾向于加载更快和使用更便捷的趋势,1 s 的性能提升对用户友好度有着巨大的影响。
索引的有效使用需要查询语句的配合,当查询语句的条件以%开头时,引擎会跳过索引进行全表扫描,导致索引失效,对索引列的<>、not in、not exist和!=的操作会产生同样的效果[7]。数据唯一性差的字段(比如性别)只有两种可能性,无异于全表扫描。对于同样频繁更新的字段(例如Logincount 登陆次数),频繁的数值变化也导致索引频繁变化,这两种情况下的索引反而会增大数据库的工作量[8]。
3 SQL优化
一般在项目上线初期,由于业务数据量相对较少,一些SQL 的执行效率对程序运行效率的影响不太明显。而随着时间的积累,业务数据量逐渐增多,SQL 的执行效率对应用程序运行效率的影响逐渐增大[9],而且优化并不总是在一个单纯的环境进行,还很可能是一个复杂的已投产系统,业务的稳定性和可持续性通常比性能更重要,因此在开发初期对SQL 的优化很有必要[10]。开发初期针对SQL 语句优化的重要两点是在Select 子句中避免使用“*”和对查询结果的记录使用limit 进行限定。
3.1 select子句中避免使用“*”
MySQl 在解析的过程中,会将查询语句中的“*”依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着会耗费更多的时间,应尽力避免对全部字段进行列表,而应只列出所需的字段名[11]。当SQL 的查询功能是搜索Pic 表特定用户上传的图片名时,分别对select * from pic2 where username=′testname′和select filename from pic where username=′testname′进行Show Profile 分析,对30 万条数据使用“*”的全部字段名搜索,耗时为0.901 688 75 s,对特定字段名搜索,耗时为0.403 017 5 s,速度提高了124%。为避免全列名搜索,可只将业务需要的字段在select 语句中列出,从而提高查询语句的效率。页面加载时,由于where 语句限定条件而不会对全表进行检索,因此速度也提高了50%左右。
3.2 使用limit对查询结果的记录进行限定
使用查询语句时,经常要返回前几行或者中间几行数据,limit 子句就是被用于强制select 语句返回指定的记录数[12]。当数据量很大时,如果只需要查询一部分数据,那么就要避免全表扫描,才能提高查询效率。当搜索Pic 表特定用户上传的一个图片信息时,分别对select * from pic2 where username=′testname1′limit 1和select*from pic2 where username=′testname1′进行Show Profile分析,不带limit和带limit的查询语句的数据库响应时间分别是2.338 571 25 s和0.405 127 25 s,速度提高了478%。不带limit 的查询语句为了搜到这条数据会进行全表扫描,加上limit 1 后,只要找到对应的一条数据,就不会继续向下扫描,效率就会大大提高,此外,limit 还应用于分页查询功能。
4 分页查询
当业务需要对全表进行检索而表中数据较多时,一次性全表查询的效率会变得很低,查询效率的降低随着数据量的增加更加明显,客户端一次性展示过多的数据会导致页面卡死,这时需要使用分页查询,一次只显示一部分数据正是分页查询功能的本质[13]。分页查询包括数据限定和id 限定两种使用方法。
Select * from pic limit 1000,100 语句完成了基本的数据限定分页查询功能,搜索Pic 表中从第1000条数据开始之后的100 条数据;id 限定分页查询由Select * from pic where id>1000 limit 100 语句实现,表示搜索Pic 表中id 字段大于1 000 的前100 行数据。由于id 字段的默认值是由1 开始并逐1 递增,所以两者实现的功能相同,都是从表中1 000 开始取前100 行数据。
文中针对两种分页查询功能进行4 次测试,分别从1 000 行、1 万行、10 万行和20 万行开始查询前100 行数据的响应时间,结果如表3 所示。
通过表3 可知,对于数据限定分页查询方式,随着开始查询行数的增大,查询时间急剧增加,特别是10 万行之后,这种分页查询方式会从数据库第一条记录开始扫描,所以查询的数据越多,查询速度越慢。对于id 限定分页查询方式,由于数据表的id 字段默认是连续自增的,所以使用id 限定优化的方式能够优化分页查询速度。文中根据查询的页数和查询的记录数可以算出id 的范围。将起始行和数据库响应时间分别作为X、Y轴,作出对比分页和id 限定分页的excel 折线图,如图3 所示。
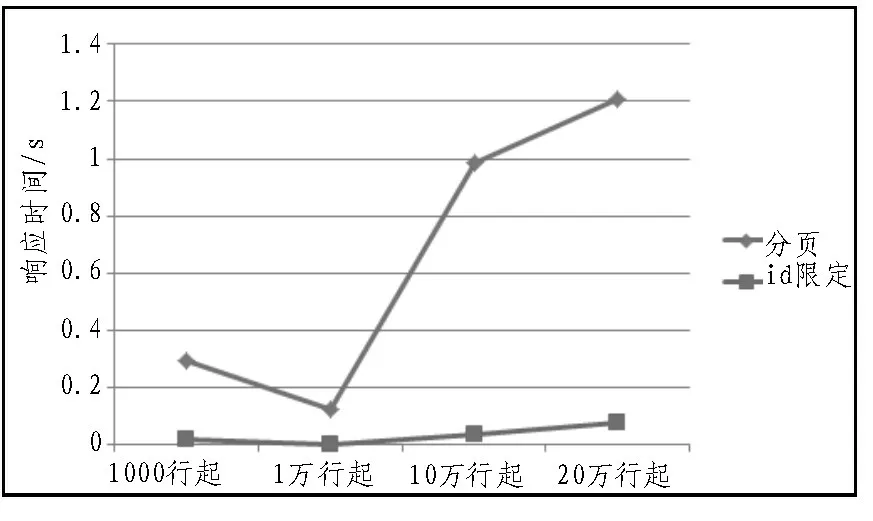
图3 id限定分页查询的影响图
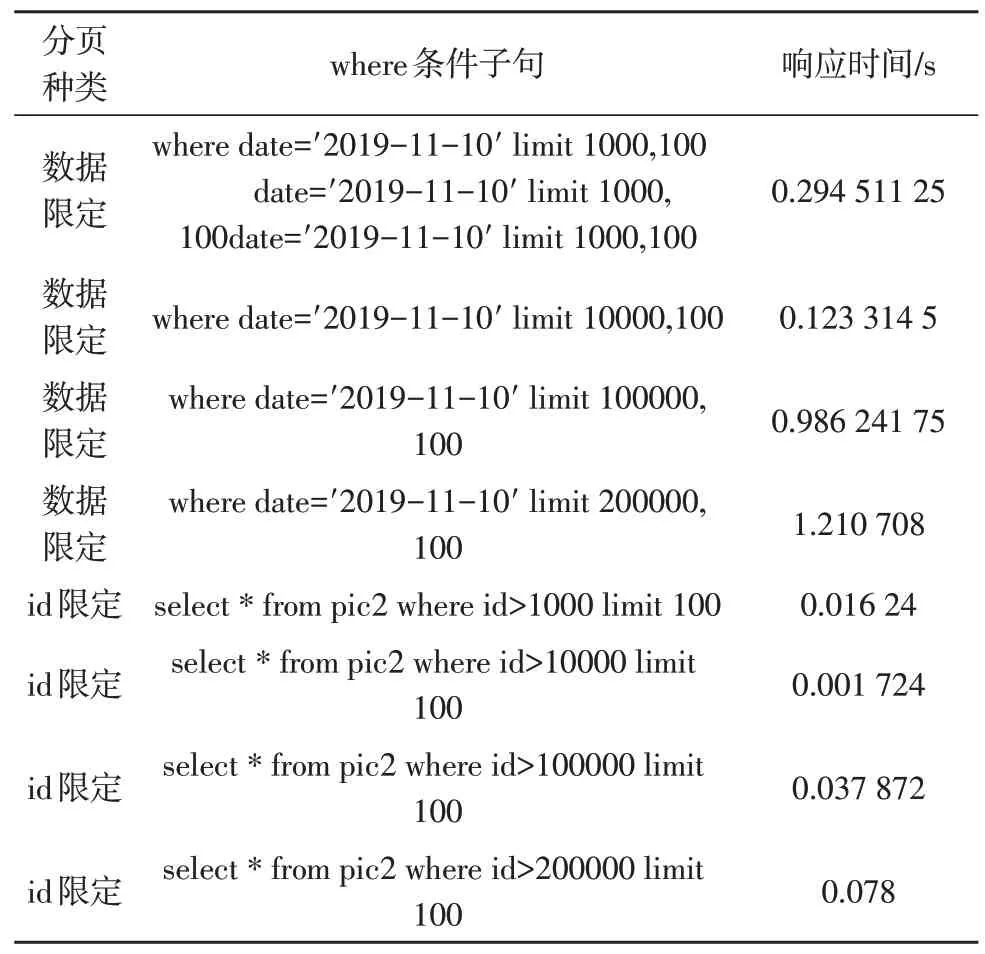
表3 两种分页查询功能的效率对比
通过图3 分析可知,数据限定分页查询和id 限定分页查询的区别是,数据分页查询随着起始行数的增多会延长数据库的响应时间;id 限定分页查询随着起始行数的增多产生的数据库响应时间的变化微乎其微。对于页面的加载速度,由于包含了图片的加载时间,虽然没有像数据库的响应速度一样呈现几何级数的增长,但是也大大提升了用户的体验。
5 查询缓存
查询缓存是MySQL 在内存中建立的一个存储空间,用于保存Select 语句的返回结果。当同一个Select 语句再次查询时,会直接返回之前的结果,而跳过解析、优化和执行的阶段[14]。由于无须经过数据库的检索,而是直接将已有结果返回,所以对应用程序查询性能的提升是不言而喻的。图4 是开启数据库查询缓存功能后Select 查询语句的执行过程。

图4 查询缓存执行过程
通过SHOW VARIABLES LIKE′%query_cache%′命令来查询是否开启,该功能将新Select 语句和该查询语句的结果集做了一个HASH 映射,并保存在一定的内存区域中。当客户端发起SQL 查询时,查询缓存的查找逻辑先对SQL 进行相应的权限认证,接着进行缓存查找,该查找对SQL 语句严格限定,包括字母的大小写、字符集以及空格。当相同的SQL 语句在缓存中被找到时,将保存数据集结果并返回应用程序;反之,将新的SQL 语句写入缓存并搜索数据库返回应用程序[15]。
查询缓存功能不需要经过Optimizer 模块进行执行计划的分析优化,更不需要与任何搜索引擎的交互,减少了大量的磁盘I/O 操作和CPU 运算,所以效率是非常高的。
当表结构或者数据发生改变时,也就是Insert、Update、Truncate、Alter Table 或Drop Table 等操作导致缓存数据失效,那么该表相关的所有缓存数据都将失效,而且数据表发生变化时有可能对应的查询结果并未发生变更,所以虽然查询缓存的机制看起来效率较低,但是代价是很小的,对于一个非常繁忙的系统是非常重要的[16-18],所以查询缓存功能适用于有大量查询的应用而不适用于大量数据更新的应用。
6 结束语
常见的数据库查询优化方法包括由运维人员完成的数据库所在服务器的内核优化、分表以及MySQL 配置参数的优化(进行压力测试来进行参数的调整)。而索引优化、SQL 优化、分页查询和查询缓存优化是程序员在开发过程中直接面对的问题,是数据库查询性能、应用程序响应速度和用户体验的关键。
猜你喜欢
电子设计工程(2022年15期)2022-08-17
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
光通信研究(2020年2期)2020-06-15
党员生活(2020年2期)2020-04-17
电子制作(2019年13期)2020-01-14
科技创新与应用(2019年17期)2019-06-09
铁道通信信号(2018年10期)2018-12-06
中国石油企业(2014年4期)2014-11-30
