
基于传统能零比和自相关函数主副峰结合的端点检测法
2021-06-25 11:10蔡诚章小兵吕昊
电子测试 2021年4期
蔡诚,章小兵,吕昊
(安徽工业大学电气与信息工程学院,安徽马鞍山,243002)
0 引言
端点检测是语音信号处理的重要组成部分。端点检测可以从一段含噪或纯净语音中检测出语音的开始和结束对应的端点。在语音信号处理的过程中,如果输入信噪比很高,可以用短时能量区分语音段和噪声段,但在低信噪比环境下,仅用短时能量进行端点检测的效果会非常差,所以研究出具备高准确率且鲁棒性好的端点检测算法十分重要,本文首先利用改进的多窗谱减法对语音信号进行降噪,然后对短时能量取对数,然后用对数能量除以自相关函数主副峰值和过零率的乘积。结果表明,在低信噪比环境下,将对数能量和短时过零率,自相关函数主副峰值结合,该方法可以实现更精确的语音端点检测。
1 改进的多窗谱估计的谱减法
1.1 多窗谱估计的谱减法
1982年,Thomson在传统周期图方法的基础上提出了一种多窗谱估计算法。他的算法是在多个正交数据窗上重复使用同一数据序列,得到与数据相对应的直谱,然后对直谱值进行平均,得到误差和估计方差较小的谱估计。
多窗谱的定义为:
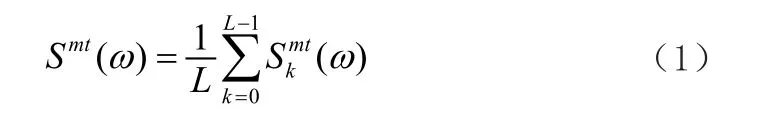
其中L是数据窗口的数量;S^mt是第k个数据窗口的频谱:
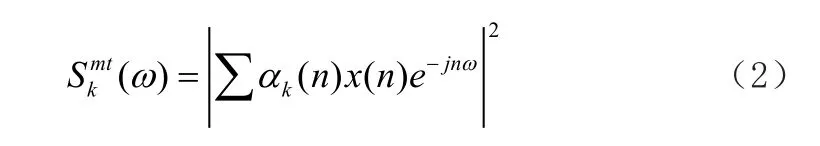
1.2 改进的多窗谱估计谱减法
MATLAB中有调用函数pmtm,该调用函数可以计算多窗谱的功率谱估计密度和增加削减因子,然后将多窗谱之间相减,从而降低噪声影响,得到语音信号的增强。
谱减流程如下:
(1)设带有噪声的语音信号为X(n),在通过预处理过后,可以得到语音信号Xi(m)。
(2)将语音信号Xi(m)进行傅里叶变换,得到了振幅谱|Xi(k)|和相位谱θI(k),并对2M+1相邻帧进行了平滑处理,得到平均幅度谱|Xi(k)|公式的X(n)是数据序列;n是序列的长度;Ak(n)是第k个数据窗口。
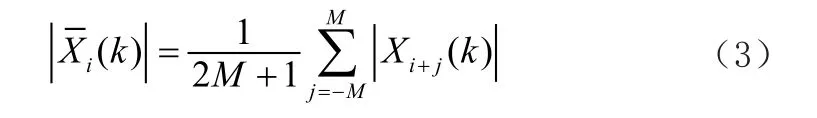
式子(3)将其中的第i帧作为中心,并各取中心前后M帧,一共取了2M+1帧,并将2M+1帧取平均值,一般情况下,M的值为1,并在以下帧数后,每过3帧取一次平均。
(3)将多窗谱的估计运算施加到语音信号Xi(m)上,然后运用MATLAB中具有的PMTM函数去进行多窗谱功率谱密度计算:
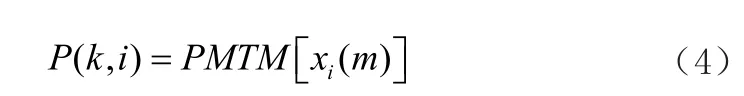
(4)对多窗谱功率谱密度进行估计后并重复相当于步骤2的操作,推算出平滑功率谱密度:
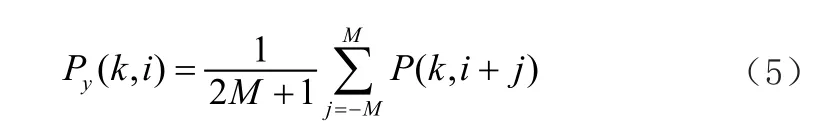
从上面式子我们可以看出来,以第i帧作为中心,并在前后各取M帧,一共取了2M+1帧,并将该2M+1帧取均值,一般情况下,M的值为1,即每2帧进行一次平均。
(5)假设有NIS帧前导无语音噪声段,结合下面给出的式子,我们可以计算出噪声平均功率谱密度值,该表达式为:

(6)谱减关系计算增益因子。
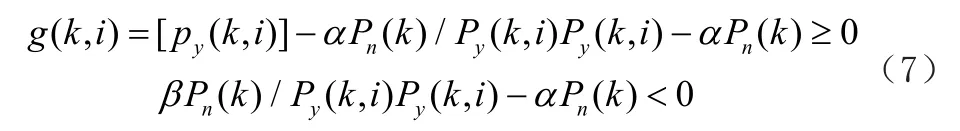
式中,α为过减因子;β为增益补偿因子,为了有效去除纯音中含杂的污染噪声,我们要选择适宜的α值,α值过大了会造成语音失真,过小了效果不明显。
(7)由式子(3)的|i(k)|和式子(7)的g(k,i)就可以计算出谱减幅度谱|Si(k)|值。
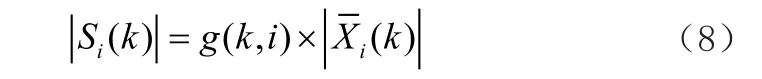
最后,将|Si(k)|与θi(k)结合到一起,然后进行离散傅里叶反变换(IDFT),将语音信号从频域转换到时域,通过上述运算后,可以得到增强的语音信号Si(m)。

为了在语音信号中获得更准确的信号,要先对语音信号进行多窗谱降噪处理,这样可使低信噪比环境下端点检测更加稳定和准确。
2 端点检测特征参数
2.1 短时能量
短时能量可以用来区分语音和噪音。在噪声环境中,语音能量加上噪声能量可以代表这一段能量的总和。在高信噪比情况下,语音的短时能量比噪音的短时能量大,通过计算这一段语音段的短时能量,可以区分语音和噪声。在高信噪比和不含噪音时,短时能量区分语音和噪音有着很好的效果,但是在低信噪比环境下,短时能量检测的效果会大大下降,短时能量为一帧语音信号能量的大小,短时能量定义:
假设语音波形的时域信号为x(n),加窗函数ω(n)得到的第i帧语音信号为Yi(n),则Yi(n)满足以下要求建议:
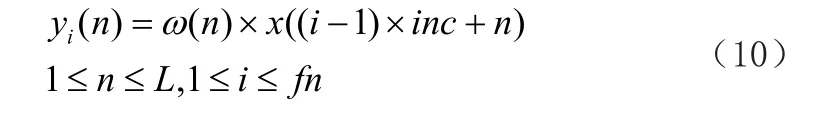
计算短时第i帧语音信号Yi(n)的能量公式可导出如下公式:
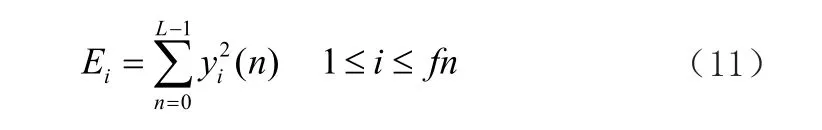
由此得每一帧的对数能量:
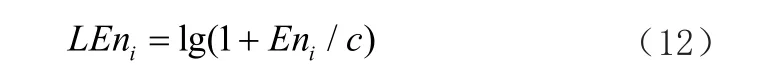
其中C是常数,通常大于1。C的引入可以减小En的某个值与前后值的差异,选择合适的常数C有助于区分噪声段和语音段,对数可以缓解伴随对数能量的剧烈变化幅度,语音信号的短时平均能量在噪声段非常稳定甚至接近0,但在语音段具有较高的幅值。此外,对数能量可以缓和短时平均能量的急剧变化,并在一定程度上提高平滑语音段的幅度。
2.2 短时过零率
短时平均过零率是语音信号波形在一帧语音中通过水平轴(零电频率)的次数。连续语音信号的时域波形用过零点的方式穿过横轴。离散信号相邻采样值的符号不同就判定为过零.所以短时平均过零率可以用单位时间内样本值改变符号的次数来表示,短时平均过零率的作用是区分清音和浊音。清音有着较高的过零率,而浊音过零率则较低.
短时平均过零率:
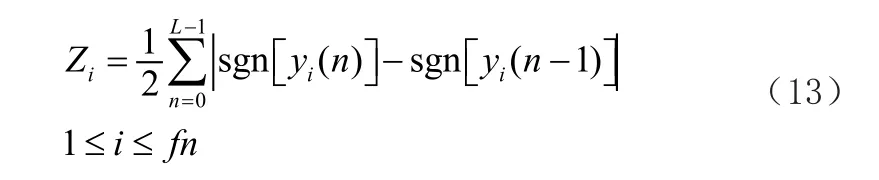
符号函数sgn[x]:

直流分量会对短时平均过零率造成一定的影响,所以在计算短时平均过零率前,需要先消除直流分量。
2.3 自相关函数主副峰比值
噪声帧和有话帧的自相关函数是不同的,图1和图2给出了噪声帧和有话帧短时自相关函数的曲线图,其中最大峰值都做了归一化处理.定义主峰和第一个副峰的比值:

图1 噪声信号自相关函数
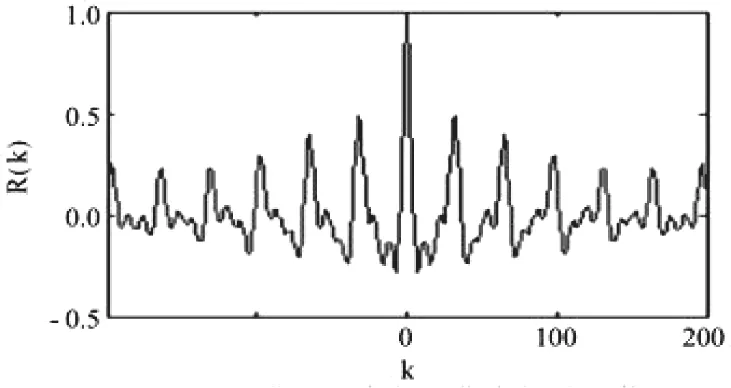
图2 带噪语音信号自相关函数

式中,R(0)为主峰值;Rm为第一个副峰值
从图1,图2中可以看到在噪声帧中最大的副峰值在0.1左右,主峰归1,所以噪声帧的Ca值为10左右;而在有话帧中第一个副峰值在0.5左右,主峰归1,所以它的Ca值为2左右.从中可以看到,噪声帧和有话帧之间主副峰的比值有很大的差距,所以可以利用这个特性来提取端点.
3 短时能自零比
上述逐一对短时能量,短时过零率,以及自相关函数主副峰比值做了分析,通过仿真实验得到的结果和查阅文献资料发现,在无噪音环境下或高信噪比的情况下,较为纯净的语音通过这三种特征参数单独来进行端点检测可以表现出非常良好的准确性,但是在低信噪比的情况下端点检测的准确率则会大大下降.为了使端点检测在低信噪比环境下更加准确,本文将短时过零率,短时能量,自相关函数主副峰值这三种语音端点检测特征参数检测算法来组合成一种新的端点检测算法,短时能自零比通过用对数能量除以短时过零率和自相关函数主副峰的积,从以上图中可以看出,在语音的有话区间能量是向上凸起的,而过零率则和自相关函数主副峰则相反,在有话区间向下凹陷.所以将对数能量除以过零率和自相关函数主副峰值的积,则可以更突出有话区间的数值,噪声区间的数值变得更小,拉开了有话区间和噪声区间的数值差距,更容易检测出语音的端点。其定义如下:
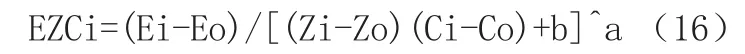
式中,Ei,Zi和Ci分别代表第i帧对数能量,短时过零率和自相关函数主副峰比值,Eo,Zo和Co表示前十帧的对数能量均值,短时过零率和自相关函数主副峰比值,b为一个较小的常数,防止(ZI-Zo)(Ci-Co)为0时出现溢出的情况。经过多次实验a取值为2.8。
能自零特征值提取的流程图如下:
短时能自零结合在一起的新型语音端点检测法,能够更好的发挥增大噪音和纯净语音差异的效果,可以更好的区分有话段和噪音段,在低信噪比的环境下具有良好的端点检测准确性和稳定性。
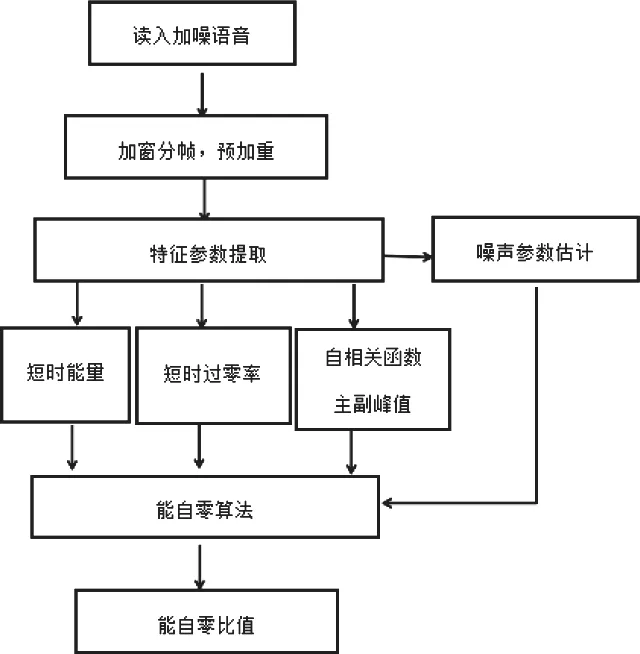
图3 能自零比特征值提取流程图
4 仿真实验与分析
实验中所用的语音样本是纯净不含噪语音,采样频率为8kHz,采样精度为16bit,实验通过改进的多窗谱降噪,通过添加噪声库中的白噪音,生成5db,0db和-5db三中不同信噪比情况下的matlab仿真波形图。图4-图9为传统端点检测法与本文的端点检测的效果对比。
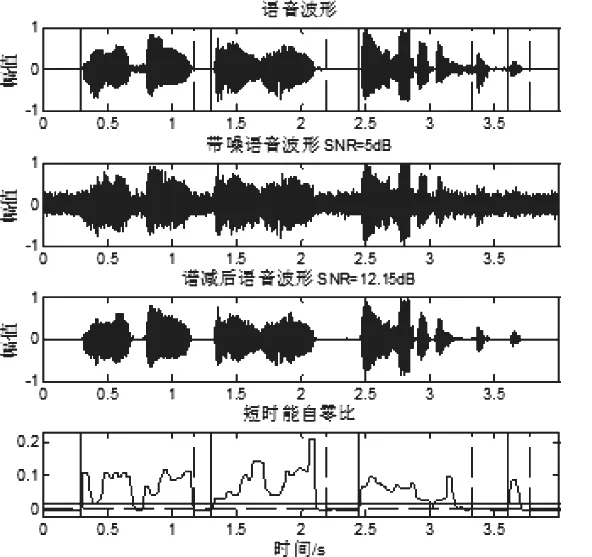
图4 SNR=5db白噪声能自零比的端点检测

图5 SNR=5db白噪声能零比的端点检测
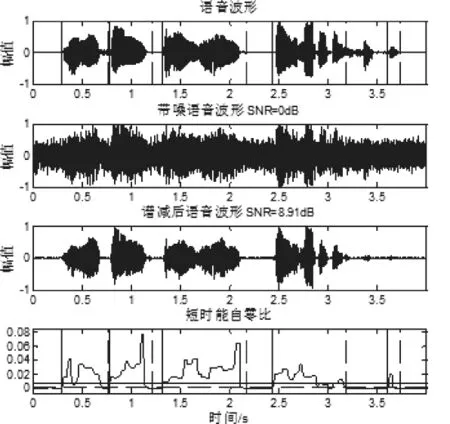
图6 SNR=0db白噪声能自零比的端点检测
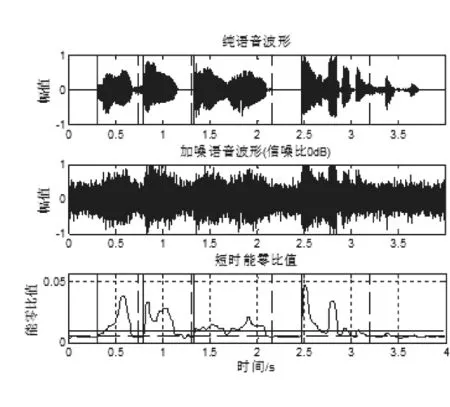
图7 SNR=0db白噪声能零比的端点检测
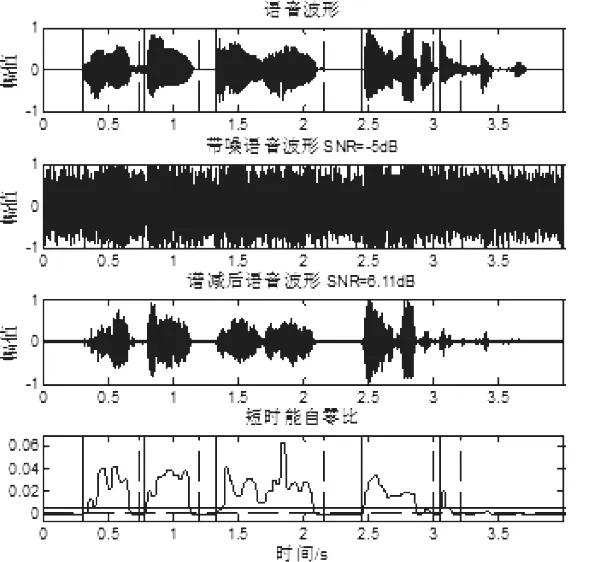
图8 SNR=-5db白噪声能自零比的端点检测
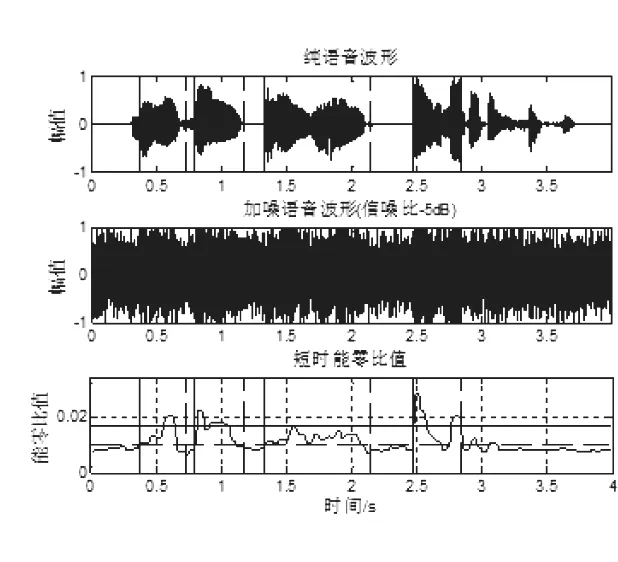
图9 SNR=-5db白噪声能零比的端点检测
与图4、图6、图8和图5、图7、图9相比,两种方法在信噪比较高时具有较好的精度,但在信噪比较低时,能自零比端点检测仍能正确检测语音信号的端点位置。例如,当信噪比为0dB时,传统的能零比检测方法漏掉了判断,而本文的端点检测方法可以检测到“大海”,当信噪比为-5dB时,传统的能零比检测方法已经基本失效,但本文提出的方法仍能进行更精确的端点检测,说明本文方法在不同信噪比下具有较强的抗噪能力和较好的检测效果。
5 总结
本文提出的新的端点检测算法,通过对语音信号进行改进的多窗谱降噪处理,然后将自相关函数主副峰比值和对数能量,过零率结合起来。通过大量的仿真实验之后发现,该算法比众多传统的端点检测法在低信噪比环境下检测更为准确,稳定性更强,鲁棒性更好,且对进一步研究低信噪比情况下的语音端点检测提供了参考。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2019年9期)2019-10-26
中学生数理化·教与学(2019年8期)2019-09-18
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
雷达学报(2017年3期)2018-01-19
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
