
区域环境质量可视化分析方法
2021-06-25 01:17:48刘世泽范书瑞刘权锋贾颖淼
科技和产业 2021年6期
刘世泽,范书瑞,刘权锋,贾颖淼
(1.北京航空航天大学 软件学院,北京 100191;2.河北工业大学 电子信息工程学院,天津 300401)
随着城市化的发展,空气质量也必然会受到影响,而环境质量问题也逐渐受到了人们的关注[1]。现如今,大数据已经成为时代的热潮,城市中的空气质量数据主要来自当地的空气质量监测站,这些站点负责对空气质量进行自动检测和数据的自动存储,在城市的环境空气质量和污染源的研究分析中,都起到了非常重要的作用[2]。可视化技术[3]有助于解决在大数据环境下难以寻找数据之间联系的问题。通过各种便于观察的可视化图形来观察拥有的数据,发现数据中蕴含的多种规律,这样可以便于相关的科研人员结合获得的数据来对环境问题提出很好的解决方法。
1984年,全国环境监测工作会议提出“监测站点网络化、采样布点规范化、分析方法标准化、处理数据计算机化、质量保证系统化”的目标[4],并于1999年确定建设城市空气质量自动监测系统。
目前,在中国已经形成了4级环境监测网络,一共有4 000多个监测站点,包括专业监测站点和行业监测站点,其中有2 000多个监测站点负责环保系统监测,有2 600多个站点主要负责行业检测。有103个国家级环境监测站,113个酸雨监测站点,135个水质量监测站点。除此之外,还有区域检测网、噪声监测网等监测系统[5]。
到2005年,中国环境监测控制网络做出了调整[6],在之前的基础上对监测站的数量有所增加。其中环境空气监测调整为226个,监测点的数量为793个。酸雨检测系统为239个,监测点数为472个;调整升级197个水质检测系统,监测断面1 000余个;生态监测系统15个。
目前,中国针对环境问题已经制定了400多项环境标准[7],其中包括土壤、水质、噪声、辐射、固体废物等领域。并且已经开展了很多项应急监测,包括环境质量、环境周报、日报、污染源搜索、污染源控制等监测项目。
现主要研究空气中PM2.5污染性气体的分布情况,结合当地多个气体检测站点的检测情况,对收集到的气体整理分析。寻找一种新的处理大量数据的方法,利用Python对[8]已有数据进行数据处理及数据可视化[9]。将很多地区看作一个单位,即把唐山地区所有的覆盖气体检测站点的地区看作一个整体来研究唐山地区的空气质量情况。利用热力图以及散点图对唐山地区空气质量情况进行可视化,比较分析两种方法的区别,同时对污染气体之间的相关性进行分析。
1 可视化分析方法
获得监测站点空气质量数据后,首先利用Python对数据进行处理,主要涉及的方法为k-means聚类算法以及numpy库和Pandas库,对数据进行合理的整理整合。
k-means聚类算法[10]也称k均值聚类算法,是一种基于距离的聚类算法。通过对已有数据中给出的经纬度位置,再通过迭代的方式把所有站点分为几个小区域,数据整理则以达到可以直接使用的标准。数据整理则对已有数据按照站点名称和气体采集时间的标准,对数据分类,为可视化作图做准备。
可视化部分的研究方法同样以Python为基础,利用Pyecharts等工具,结合数据绘制热力图和散点图,分析比较两种显示方法的优缺点。除此之外,对于空气中各项污染气体的研究使用特征相关性热力图分析方法,可求得各个气体成分之间的相关系数,并绘制出相关性热力图。通过对比各种污染性气体之间的相关性,可以得到更加科学的环境治理方法。可视化研究流程如图1所示。
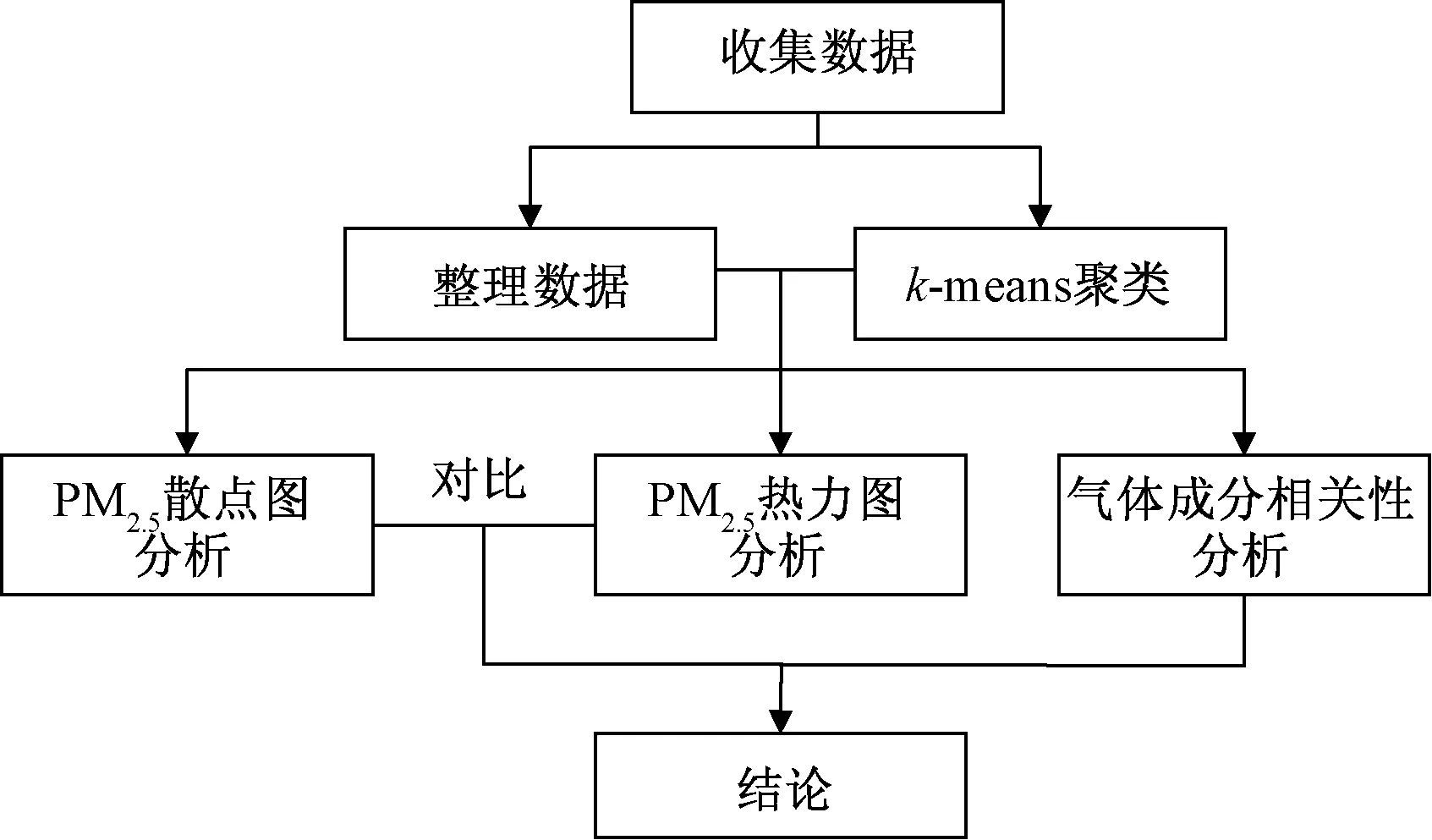
图1 可视化研究流程
2 环境数据预处理
2.1 数据来源
研究区域为唐山地区。唐山地区为河北省地级市,位于华北平原东部,渤海湾北岸。近几年,京津冀地区空气污染情况严重,大部分地区的雾霾天气已经严重影响城市居民的生活。在此情况下,唐山在全市内中车、唐山钢铁、丰润污水处理厂、中煤集团等代表性地区设立了400个微型空气质量观测站,以及在唐山供销社、雷达站、物资局、陶瓷公司等重点地区设立了6个国家控制空气质量检测站。获得了唐山地区2018年2—4月400个微型站和6个国控站空气成分数据情况,其中包括AQI、PM10、PM2.5、NO2以及空气温度、湿度等数据值,去掉数据中的部分空缺值,将数据处理后合理利用,进行可视化分析。
2.2 整理数据
研究唐山地区大气污染物的时空分布包括时间和空间,数据需要从时间、空间两方面进行处理。对反映空气质量的数值进行时空分布可视化,可以直观地看出该地区空气质量发展情况和分布情况[11]。在时间上,将唐山地区400个站点的数据全部筛选出来并存到csv文件中,对每一个站点的某一段时间内的变化进行分析;在空间上,则是对相同时间段内的不同站点进行分析,绘制出唐山所有站点在地图上的数据可视化图。进行时间处理后的数据见表1,空间处理后的数据见表2。
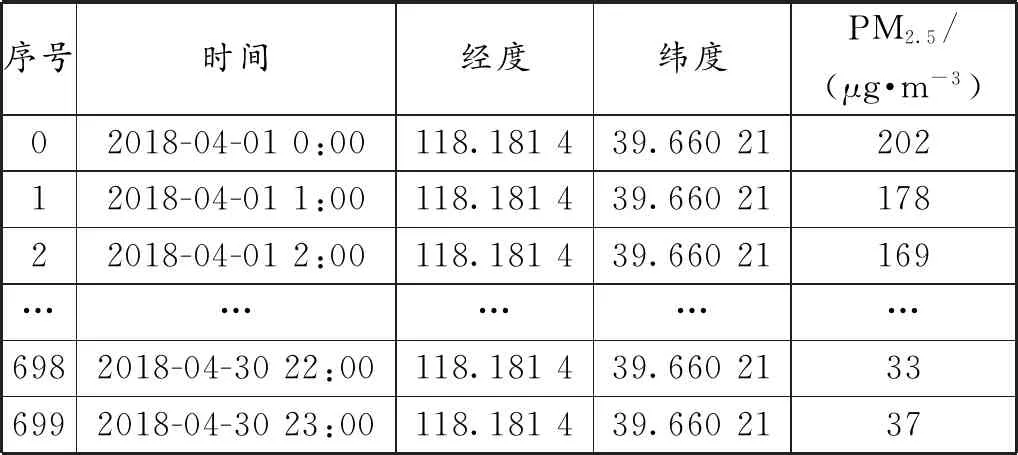
表1 时间处理后的数据

表2 空间处理后的数据
2.3 k-means聚类算法
k-means聚类算法是一种反复迭代求解集合分析算法,其阶段首先将数据分为k组,然后随机选择k个对象,计算所有对象和所有种子的中心距离,将所有对象安排在最近的集群中心和分配对象表示一簇,每次分配样品时,根据集群中的现有对象重新计算集群中心。此过程会反复到满足结束条件为止,终止条件为不再有新的点被分到某个类别,所有的聚类中心不会再产生数量和大小上的变化。
聚类算法过程如下:
1)选择k个对象,把这k个对象作为初始聚类中心,计算每个个体和种子组的中心距离,每个对象被指定为最接近的群体。聚类的中心点和分配给他的所有的点就表示一个聚类群。
2)在分配好所有的点之后,聚类的中心和分配对象根据内部物体重新计算每个组的中心,这一过程一直重复,直到完成条件得到满足。满足的条件可以是下面的任意一个:①不再有新的点分配到某一个类群;②类群在数量和大小上不再发生变化;③误差平方和局部最小。
利用k-means聚类将所有的站点进行聚类,分出合适的类群后,对每一个小类进行空气质量分析。这对于处理庞大数据来说是一个很方便的做法。
通过对k值的多次尝试,结合当地空气质量监测站点的数量,最后确定在k=8时分出的类群最合适,如图2所示,将所有站点分为8类,大幅度减少因数据过大造成的使用不便,后期数据的使用将会更加方便快捷。

图2 k-means聚类效果
3 数据可视化分析
3.1 散点图
Python为用户绘制散点图提供了多种多样的形式,包括Folium提供的交互式散点图、Pyecharts提供的可选择世界任何地方的地图。
利用Pyecharts库进行散点图的绘制时,选取唐山地区作为地图背景设置相关参数,为便于观察,在可视化中对不同浓度的点进行了不同颜色的显示,图中加了可调节显示功能,通过读取csv文件中最大值和最小值,自动确定浓度范围。图3为调节PM2.5浓度在2月和3月不同浓度区间的分布图。
结合图3中显示点的地区以及2月和3月对比可分析出,荣义焦化厂、印刷厂、钢铁厂等建筑物周围PM2.5浓度过高,这些地区污染物排放较多,环境较差,对空气质量产生影响;而唐门一品、写字楼、高速口等地的PM2.5的浓度处于较良好的情况,PM2.5呈现较低状态,原因为住宅区重工业较少,污染物排放较低,而高速口虽有汽车流动,但处于较偏远地区,地势空旷,环境较好。可以得知,人们的生活规律以及企业的工作内容对空气质量的影响非常大,工业区密集的地方污染尤其严重。

图3 PM2.5分布散点图
Folium库可支持API接口调用,利用Folium库去实现可视化,可以调用百度地图,将唐山各站点数据导入到地图中,同样可以随时观测每一个站点的数据情况,包括站点名称和PM2.5浓度值。相对于上文提到的Pyecharts绘制的地图,Folium库调用的地图背景更加详细,可以清晰地显示唐山各个街道、住宅小区、高速公路以及各乡县的情况。可以通过当地的建筑情况和周边环境,结合该站点的PM2.5浓度值,分析该地区周围的环境质量问题,如图4所示,点击站点,可以清晰地显示出站点信息和PM2.5浓度。
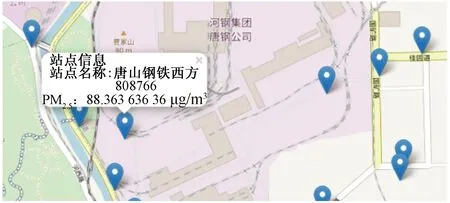
图4 交互式散点图
在时间上分析唐山空气质量情况,选取了唐山钢铁西方站点、新兴隆钢铁西北角、嘉润蓝湾3个站点,读取站点2、3、4三个月的PM2.5浓度值,绘制出浓度变化曲线,如图5所示,结合曲线分析出唐山地区在3月时PM2.5明显高于2月和4月,可断定在3月唐山地区空气质量较2月和4月来看相对较差。资料显示,2018年3月份空气质量较差城市河北7城上榜,唐山倒数第一,随后唐山15日20时采取应急减排措施,要求在执行非采暖季生产要求的前提下,钢铁企业烧结限产50%,在确保生产安全的前提下,焦化企业出焦时间延长至36 h,铸造行业全部停产,极大地改善了空气质量。

图5 PM2.5浓度变化曲线
3.2 热力图显示
利用Folium库的Heatmap函数在地图上进行热力图的绘制,热力图将所有站点的浓度情况向周围进行了延伸,虽然和散点图表现出了不同的效果,但是在图形绘制的方法上却和散点图大同小异,同样是读取数据和把数据导入到地图中,并设置相关参数。绘制的热力图如图6所示。
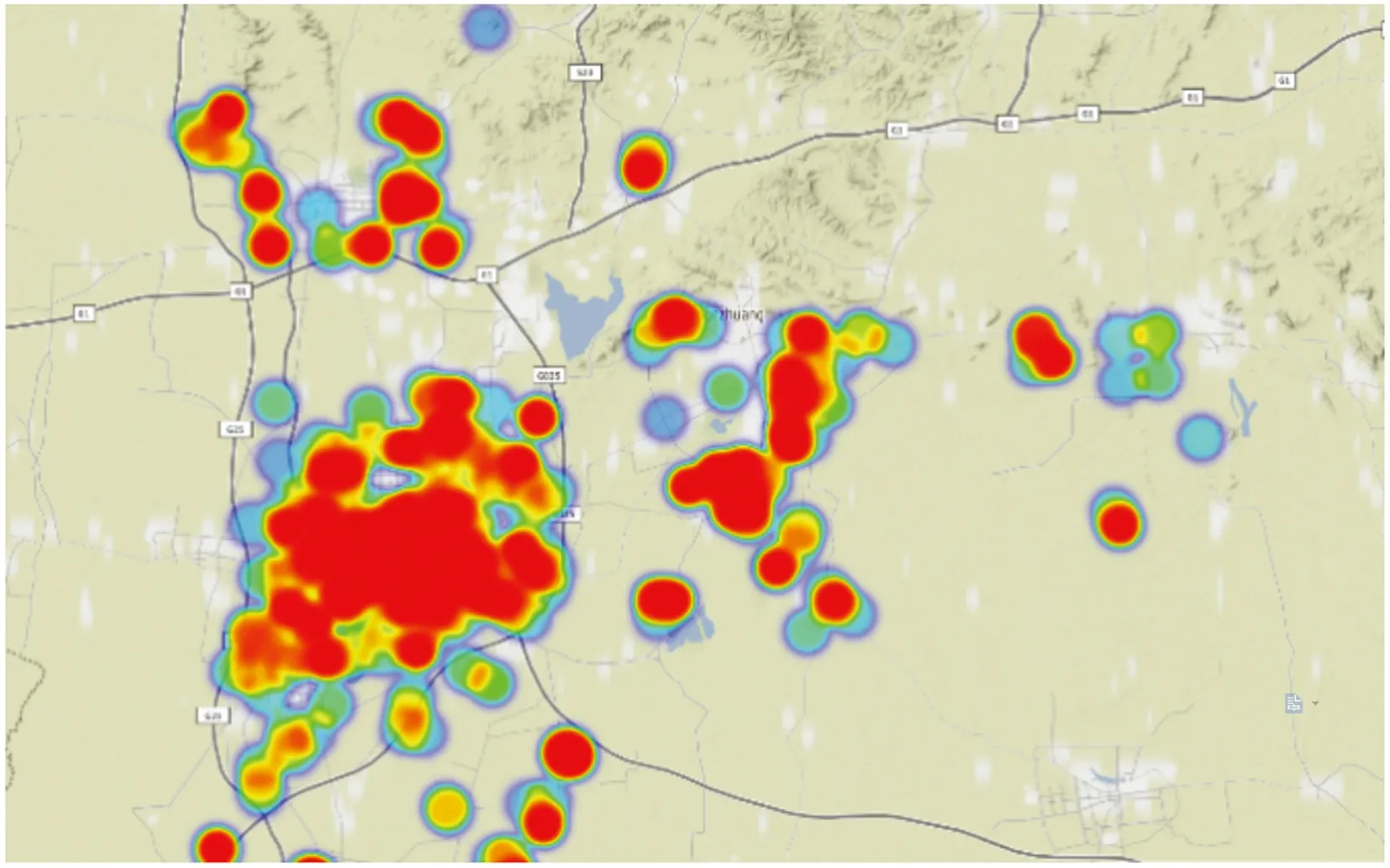
图6 唐山地区热力图
相对于散点图对每一个点的精准度,热力图更能表现出整个区域的PM2.5分布情况。通过地图上不同浓度不同颜色的显示,可以观测出哪一部分的空气污染物排放严重,然后结合该区域所包含的建筑物以及周围环境,分析出导致环境质量下降的原因。
4 污染气体相关性分析
4.1 污染气体变化趋势
本节主要对唐山6个国家控制站点的所有气体统一对比分析,包括气体的变化趋势和气体之间的相关性。将已有的数据整理出来,分别在一个月内的空气质量变化趋势、一周内工作日和非工作日的空气质量变化趋势、一天内各个时间段的空气质量变化趋势三方面进行分析。主要以不同的时间作为背景,结合人们的出行习惯和工厂的运作时间,分析各污染成分在时间上受到的不同影响,以此得出更加全面的、覆盖性更强的结论,提出科学合理的治理方法。
图7为唐山供销社国控站2月份各气体的变化趋势,从图可以看出,按照整个2月份趋势来看,PM10和PM2.5在2月份的下半月浓度相对于上半月整体呈现出上涨的趋势,但是也存在上下波动较大的现象。除了PM2.5和PM10以外,其他的气体如SO2、NO2、O3、CO这些在时间上整个月份来看并没有太明显的变化趋势,都是在该月份内上下波动。因此如果以月份为参照对象对空气质量进行时序变化的分析的话效果并不是很明显,很难在其中发现变化规律。
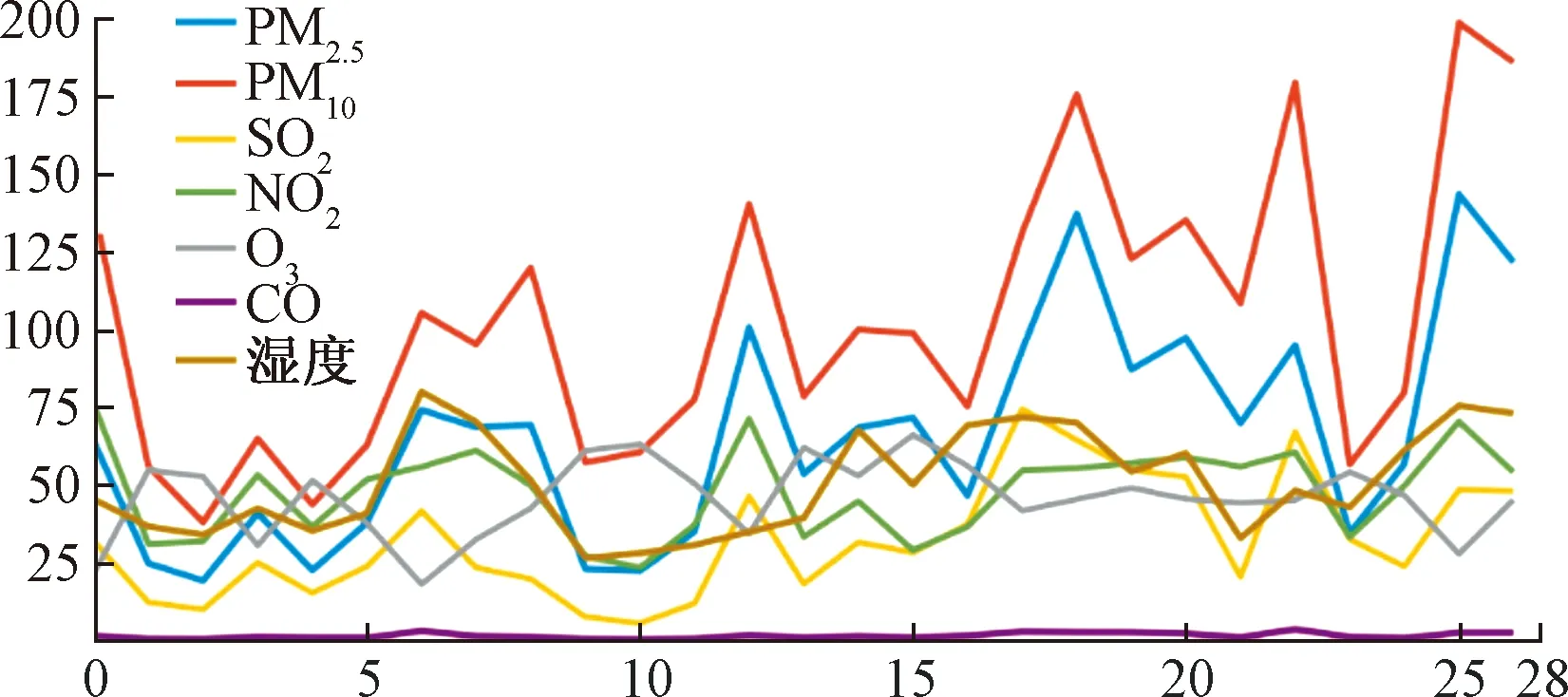
图7 国控站一个月内气体变化趋势
图8显示的是供销社站点从2月5日到2月11日一周内的气体成分变化趋势。从图中可以看出,在一周内的周一到周五PM2.5、PM10、NO23种污染性气体明显增高。原因应该是在这段时间大量工作人员的复工、工厂营业对空气质量的影响比较大。而周六、日很多居民会有双休日,工作单位的生产量也会随之降低,空气质量也会在这两天得到改善。O3的浓度在工作日内却和其他气体表现出了不同的趋势,O3在周日以后呈现出了下降的趋势,而在周二开始又逐渐上升,到了周五则提升到了最大值,然后一直在周六、日的休息日保持在了最大的浓度。
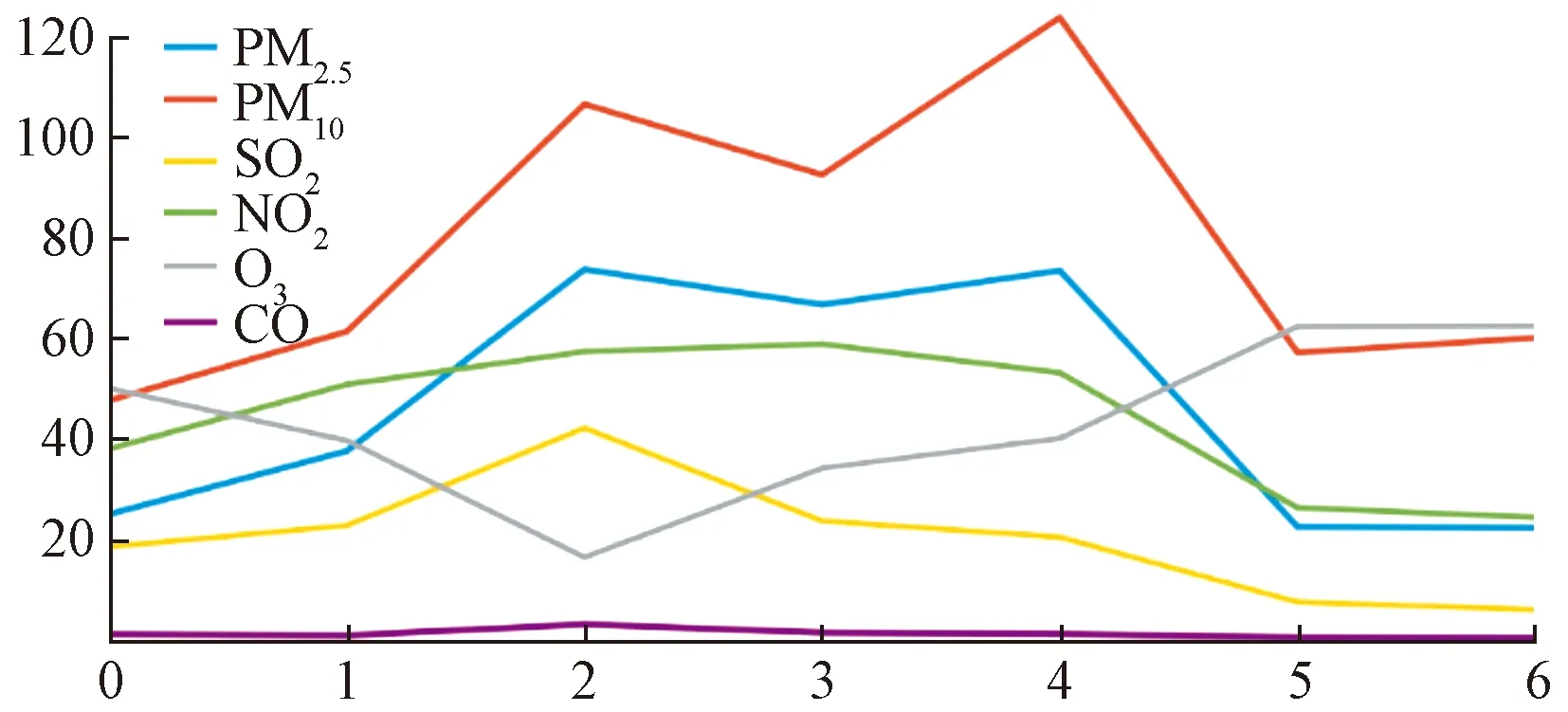
图8 国控站一周内气体变化趋势
图9显示的是供销社站点在15日当天24 h内空气中气体的变化趋势。从15日当天情况来看,PM2.5和PM10在晚上有明显上涨的趋势,空气中O3的成分则主要集中在下午,呈现出增加的状态,空气湿度则在凌晨较高。也可以看出,在空气湿度最高的一段时间内,PM2.5和PM10也是最低的时候,能看出空气湿度对空气中可吸入颗粒有很好的抑制效果。
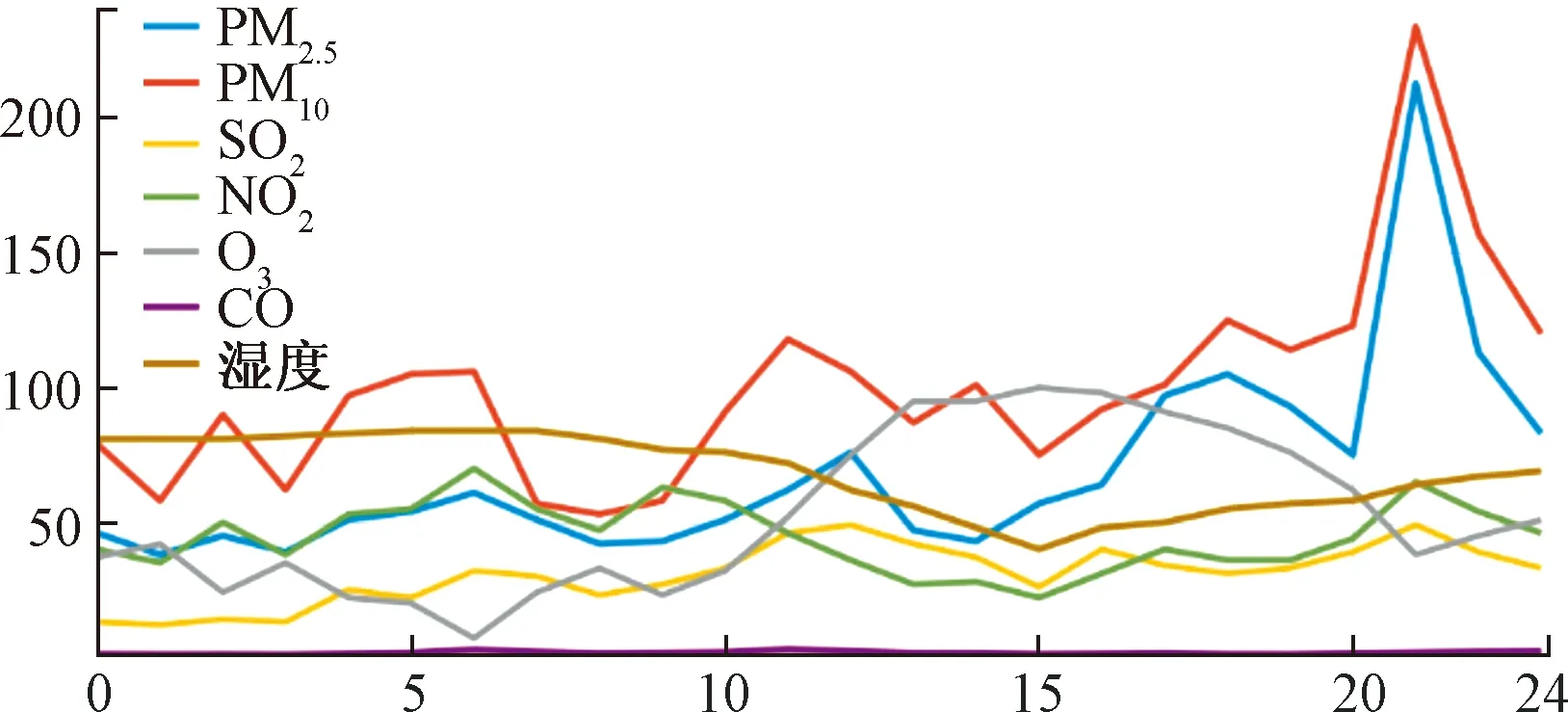
图9 国控站一天内气体变化趋势
4.2 空气成分相关性
PM2.5、SO2、NO等气体都是影响空气质量的重要因素,利用Seaborn库绘制特征相关性热力图可以清晰地看出各个气体之间存在的相关性。选取唐山十二中国控站点3月12日0点到23点这24 h的数据。数据包括24 h内AQI、PM10、PM2.5、SO2、NO2、O3、CO 7项指标的情况,并计算各个气体之间的相关性,得到图10所示的热力图。
图10中横纵坐标全部为影响空气质量的变量,右侧为相关系数范围。相关系数在0~1区间的颜色逐渐渐变。颜色越深表示两种变量之间的关系最大。在0~-1上颜色越深,负相关系数越大,两种成分呈现出负相关的关系。一种变量增大,另一种变量会减小。
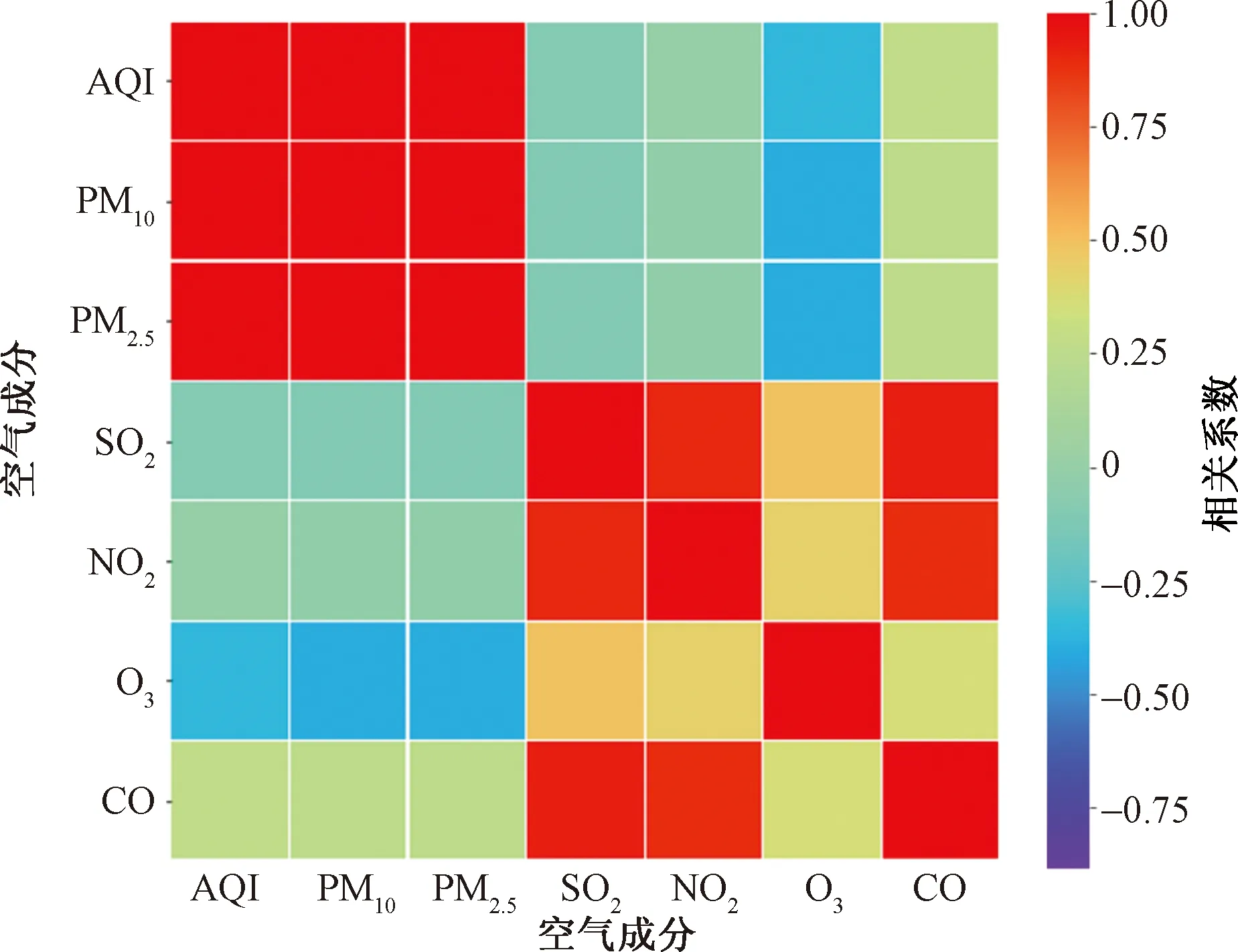
图10 空气成分特征相关性热力图
结合图10,以PM2.5为例,其与AQI和PM10的相关性最高,其次与空气温度和湿度相关性也比较高。因为AQI反映的是空气质量情况,所以可以得出PM2.5是影响空气质量的重要因素。同时,SO2、NO2、O3、CO 4种气体相互之间都呈正相关,每一种气体的增长,另一种气体也会随之呈现出不同程度的增长趋势。
特征相关性热力图不仅可以分析出不同成分之间的正相关系数,也能分析出不同成分之间的负相关系数。在图中可以看出来,O3与AQI、PM10、PM2.53种变量呈现出负相关,而SO2、NO2、CO与PM10、PM2.5表现出很小的相关性。
5 结论
区域环境质量可视化对于分析空气质量问题起到了方便快捷且直观的效果,但是通过绘制散点图和热力图两种方法对比,产生了不同的效果,明显感觉到两种方法存在的差异。通过各种不同的可视化方法对唐山环境数据进行分析,得到如下结论:
1)散点图与热力图相比,散点图可以直观地显示出某地区对环境造成的影响,绘制出来的地图更加美观,可用性更强;热力图对空气质量分析不能提供非常直观的效果,只能显示一个模糊的范围;交互式的散点图则为区域环境质量分析提供了很好的帮助,它可以随时观测站点的数据情况,结果直观,效果最好。
2)季节性变化和地理位置的变化对空气质量的影响程度非常大,季节性的变化可能会通过影响人们的出行规律和企业的工作内容间接影响空气的污染程度。地理位置的变化则直接由于地区的建筑物情况、周围污染排放源等问题导致空气质量受到影响。
3)通过对国控站各空气成分的可视化对比分析可以看出,空气质量系数AQI与空气中的PM2.5和PM10相关系数最大,由此可见影响空气质量的主要因素为空气中可吸入颗粒,同时PM2.5和PM10两种成分的相关系数也接近于1,可见两种气体的产生原因应该存在一些关联,并在趋势图中两种气体的变化趋势也表现出接近一致的状态。
猜你喜欢
英语文摘(2021年4期)2021-07-22 02:36:30
现代临床医学(2019年4期)2019-09-10 07:44:02
成都信息工程大学学报(2019年1期)2019-05-20 09:14:50
四川环境(2019年6期)2019-03-04 09:48:54
中学历史教学(2017年12期)2018-01-19 03:00:23
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
中国环境监察(2016年8期)2016-10-23 05:41:42
