
改进Adaboost算法对县域粮食作物产量的预测
2021-06-25 01:17赵洪凯李晓彤
科技和产业 2021年6期
赵洪凯,李晓彤
(扎兰屯职业学院,内蒙古 呼伦贝尔 162650)
中国是一个农业大国,粮食生产是确保经济高速发展的基础保障,粮食产量的变化直接影响国民经济的发展稳定[1-3]。目前中国粮食产量连续增长,农业生产已经进入新的历史阶段,但仍然面临考验,粮食增长与粮食消费需求呈反比,阶段性供应关系失衡。一方面,在农业上科技创新成果产出局限性突出,影响国家粮食安全战略性宏观调控政策的实施。另一方面,国家层面的城镇化建设的加速推进,导致粮食生产的土地资源、生态资源和生产要素的不断流失,现阶段中国农业生产环境具有不断恶化的趋势。系统地研究粮食生产发展规律是确保中国粮食安全生产的客观需要,也是中国现阶段应对国际复杂变化,确保国民生活基本水平不变的经济学研究课题[4]。
粮食产量的预测是国家进行宏观调控的主要依据,关系到国家可持续发展的科学性和合理性。而粮食生产又受到多种客观因素影响,人口、耕地面积、水资源、环境、气候的变化等都对粮食的产量具有显著影响[1]。近年来针对粮食产量的预测的相关研究中国科学家取得了丰硕的成果。在选用预测模型时主要采用单一预测模型和组合预测模型两种类型,以往研究中针对不同的数据量级,采用不同的预测模型都取得了不错的效果。吕晶[5]利用灰色Elman-NN神经网络模型对陕西省1997—2011年的粮食人均占有量和粮食单产量数据进行了预测和分析,模型评价误差3.64%。杨玉时等[6]结合粗糙集理论和神经网络技术对中国1983—2005年的粮食产量进行了预测,预测效率较之传统的预测方法显著地提高。施瑶等[7]使用优化后的LSSVM模型对中国1978—2017年的中国粮食产量进行预测,相关系数达0.989 3。以往大多数预测模型采用地区以上规模数据集,由于人工智能算法模型优劣与数据集大小有直接关系,采用县域范围的数据进行训练的案例相对较少。
1 Adaboost模型
通过对实验地区1950—2012年气象因素、土地因素、政策因素、经济因素等数据进行处理和选择,利用DWTAdaboost算法和Adaboost算法对选择数据进行建模,并利用交叉验证法对模型进行参数调优,最终对实验地区的粮食作物产量进行预测。整个流程如图1所示。

图1 Adaboost模型总流程
2 数据选取和处理
2.1 数据准备
数据主要来源为地区政府部门提供的1949—2012年的本地区的统计年鉴,资料大多为纸质影像材料,通过人工进行相关数据的提炼,并记录到excel文档中。原始数据因为时间跨度较大,不同的区域行政区划分,以及粮食作物的统计单位都不相同,通过人工进行转换和纠正,使数据格式和单位相统一。初步收集特征34个,分别为年份、平均温度、平均最高温度、平均最低温度、极端最高、极端最低、降水量、平均风速、最大风速、社会消费零售总额、一产全年生产总值、二产全年生产总值、三产全年生产总值、人口总数、工业企业单位数、工业总产值、农牧业总产值、农业人口数、耕地面积、稻谷产量、小麦产量、玉米产量、薯类产量、大豆产量、大小生畜头数、牛年末、马、猪、基本建设投资年末、财政收入、财政支出千、工农业生产总值、工业生产总值、农业生产总值。
统计数据在不同时段的统计内容也有所差距,本着尽量保全样本数量的原则,进一步对统计年限较少的数进行舍弃。最终保留数据较为完整的1958—2016年25个特征。具体数据情况如图2所示。
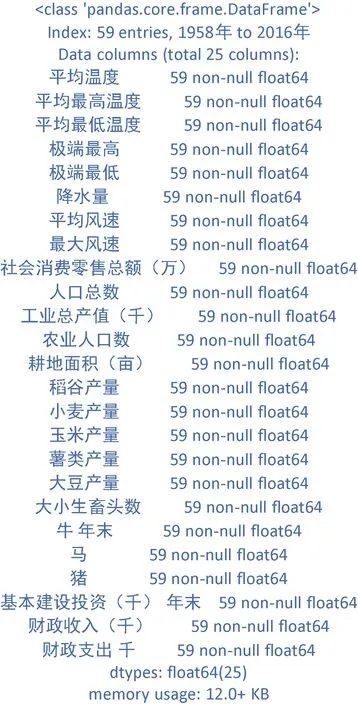
图2 数据集详表
研究过程主要是对粮食作物的总产量进行预测,现有数据缺少年粮食作物总产量的特征,将数据进行重组处理,对稻谷产量、小麦产量、玉米产量、薯类产量、大豆产量数据进行合并加和得出年粮食作物的总产量。
2.2 数据预处理
通过对数据的分析,不同特征的量纲和数值得量级都是不一样的,这对后期的预测的程影响较大,需要进一步对数据进行标准化处理,使得不同的特征数据处于相同的区间范围内(Scale)。本次研究使用min-max标准化(min-max normalization):
(1)
式中:μ为特征内均值;σ为特征数据的标准差;x为特征值;x*为进行标准化后的值。经过归一化处理的特征值均值为0,标准差为1。
2.3 特征提取
首先将前期处理的1958—2016年数据,以年粮食作物的总产量为标签,其他特征作为样本,通过皮尔森相关系数进行特征选择。筛选出得分前5的特征,分别是社会消费零售总额、工业总产值、玉米产量、大小生畜头数、财政支出。
3 Adaboost算法原理
Adaboost算法的原理是将多个弱分类器,例如决策树、knn等算法进行整合,使其成为一个强分类器。Adaboost是基于迭代的思想,训练好的弱分类器在下一次迭代参与使用形成一个新的参数的分类器,经过N次迭代,最终的分类器的参数是之前N-1次分类器的不断调优生成的。Adaboost算法有效地解决了单个弱分类器不适合用于解决复杂数据的问题[8-11]。
试验采用算法是基于Friedman等提出的DWTAdaboost,DWTAdaboost算法通过对Adaboost算法每次迭代的分类器样本进行裁剪,利用样本分布与裁剪比例生成相应的裁剪阈值,通过裁剪阈值对数据集进行抽取形成新的样本集合,再次调用弱分类器进行训练,从而在保证相较传统Adaboost算法准确率不变的前提下提升算法训练的效率[12]。
DWTAdaboost算法流程如下。
输入:训练集D由样本集X和Y标签集组成,X={x1,x2,…,xm},Y={y1,y2,…,ym};弱分类器F,迭代数量。
初始化权值:每个样本的权值设为d1(i)=1/m。
算法逻辑:
1)进行N次迭代,n∈(1,2,3,…,N)

(2)
3)本轮迭代下生成的fn在当前Dn下错误率

(3)
当εn≥0.5且Dβ=D,则停止迭代,当εn≥0.5且Dβ≠D,则β=β/2,跳转至2)。
4)通过fn对集合的样本进行加权计算,加权系数为
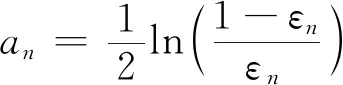
(4)
5)更新样本分布
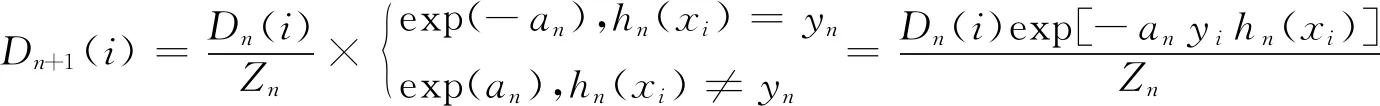
(5)
6)输出:
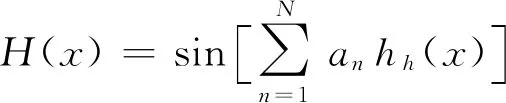
(6)
4 结果分析
粮食产量预测的数据是一个典型的回归问题,项目试验是基于DWTAdaboost算法与原始的Adaboost算法对比进行的预测,测试的数据是来源于本地区的政府职能部门的年统计信息,经过前期的筛选和标准化等处理的无异常样本数据,测试的载体是利用VMware虚拟机搭建的2核4线程的测试虚拟机,利用网格筛选模型最优参数,利用最优模型对测试数据进行测试。
4.1 两种算法模型准确率
基于实验数据其中DWTAdaboost算法和Adaboost算法的最终准确率为73.68%和75.12%。但在测试数据集上训练迭代次数为100次,每次迭代测试集的准确率变化如图3所示,从图中可看出前期DWTAdaboost算法对数据进行裁剪,准确率相对于Adaboost算法偏低,但在周期准确率达到了与Adboost算法相同的水平。
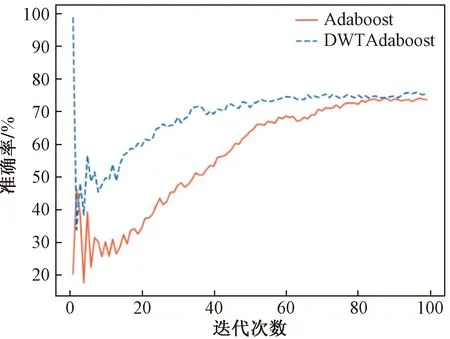
图3 两种算法的准确率变化情况
4.2 两种算法模型训练时间
基于实验数据Adaboost、DWTAdaboost两种算法的在每次迭代所用时间的变化趋势如图4所示,前期两种数据集的训练时间变化较大,总体上Adaboost算法的每次迭代所用的时间在0.35 s浮动,DWTAdaboost算法在前40次迭代时间变化较大,但很快稳定在0.25 s,最终两种算法的训练时间为0.25 s和0.35 s,相差0.1 s。
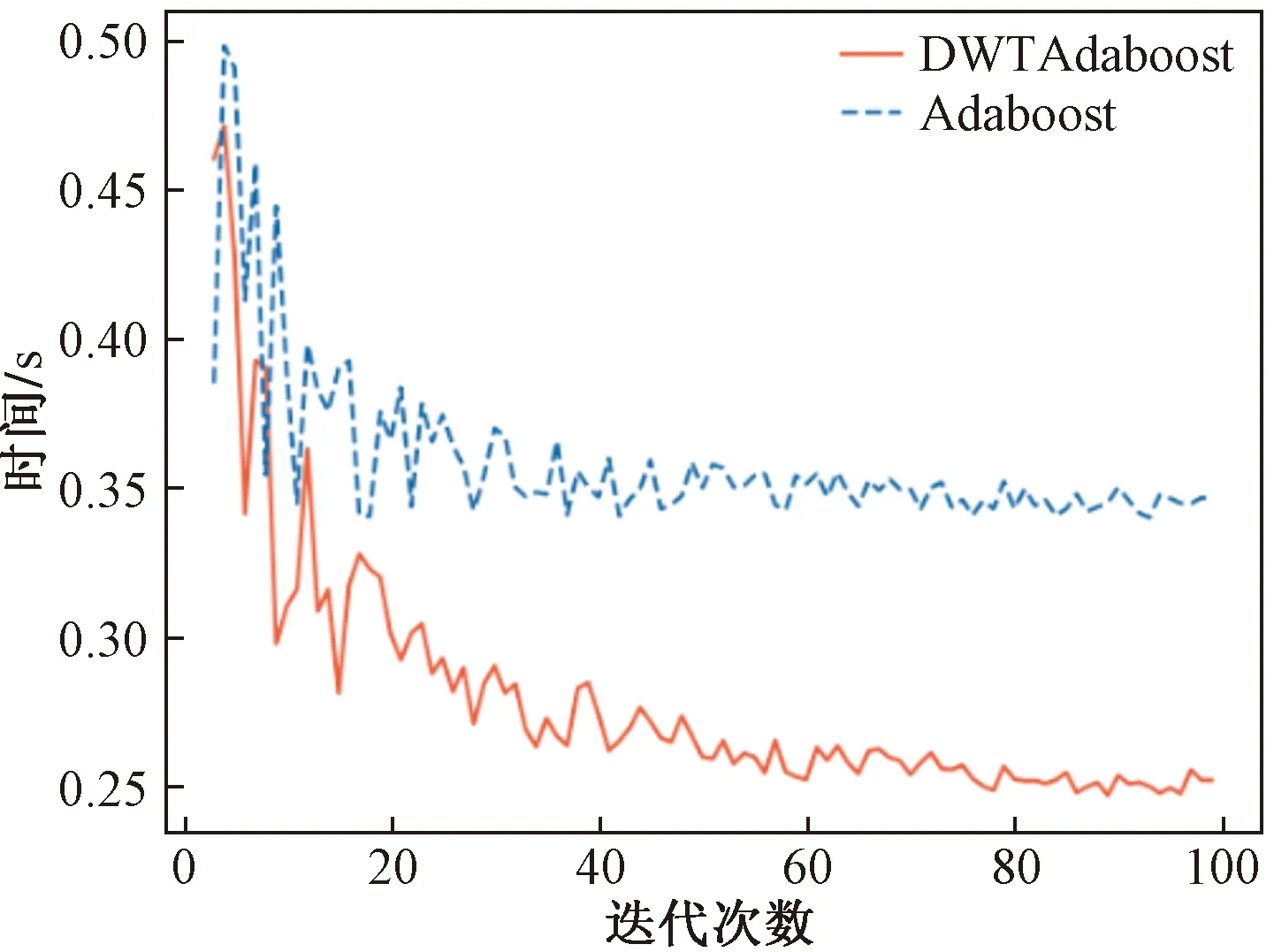
图4 两种算法的训练时间变化情况
5 结论
DWTAdaboost算法在训练前对数据进行裁剪处理,因此训练的数据集样本数量相对于Adaboot算法要少,所以在训练时间上DWTAdaboot算法要明显少于Adaboost算法。DWTAdaboost算法在每次训练中,会将本次的训练的有关信息传递给下一次迭代中,因此最终的两种模型准确率上相差不大。总体而言,在保证一定迭代次数的基础上,两种算法模型的准确率几乎相同,但在时间效率上,DWTAdaboost算法要优于Adaboost算法。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·高一版(2021年2期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
电子技术与软件工程(2019年18期)2019-11-18
领导决策信息(2018年16期)2018-09-27
电子技术与软件工程(2017年14期)2017-09-08
