
基于深度学习的Android 平台车牌识别系统设计
2021-06-25 14:17曹海啸夏庆锋刘书铭张长屿游云飞
软件导刊 2021年6期
阚 希,曹海啸,夏庆锋,刘书铭,张长屿,游云飞
(1.南京信息工程大学滨江学院物联网工程学院,江苏无锡 214105;2.南京信息工程大学自动化学院,江苏 南京 210044;3.南京信息工程大学滨江学院自动化学院,江苏无锡 214105)
0 引言
车牌作为车辆识别与管理的重要标识,是智能交通系统相关领域研究热点[1]。随着我国机动车保有量高速增长及新能源汽车的日益普及,车辆有效识别与管理愈加复杂。在复杂自然场景中对车牌精确的识别可为城市交通、自动驾驶和城市管理等提供重要支撑。基于移动端的图像车牌识别成为深度学习领域的热点之一,随着Android 移动端计算性能的大幅提升,面向复杂环境基于深度学习的车牌识别模型移植成为现实[2]。
车牌识别算法经过数十年的研究发展,在学术界和工业界已形成成熟的体系[3],算法流程一般可分为车牌区域提取、字符分割与识别3 个主要步骤,但因为不同设备采集的图像质量差异较大,车牌识别算法各有侧重。早期传统方法主要依赖于人工特征提取,然后通过模式识别的方式完成车牌字符检测,需从原始图像中把感兴趣的车牌图像区域提取出来。传统算法主要根据车牌颜色特征、边缘特征、字符纹理特性等从背景图像中提取出车牌区域,然后利用字符分割与匹配达到车牌识别的目的,该类方法在背景受环境影响小、有固定场景的地点使用广泛,诸如单位卡口、公路收费站等。近年来,随着车辆交通行业的蓬勃发展,车牌识别算法需在复杂环境背景干扰下也能准确判识,基于形态与阈值的传统方法陷入了瓶颈。但随着计算机视觉的快速发展,使用机器学习方法进行车牌识别取得了很好的效果,主要有神经网络、支持向量机、Adaboost 分类器等方法[3-4]。
随着智能交通技术的飞速发展,基于PC 机的车牌识别系统已不能满足终端便携式需求。基于Android 平台的智能手机具有便携、快速、工作环境不受限等特点[5],成为车牌信息处理终端的重要载体。特别是智能手机计算能力的快速提升,使深度学习算法在Android 平台上的移植成为现实[6]。本文设计的车牌识别系统结构如图1 所示,使用U-net 网络进行车牌语义分割,对称的编解码器使高层特征图与低层特征图可进行有效拼接,高层特征图从低层特征图中获得丰富的上下文信息与细节信息,可获得精度更高的输出,以解决移动端拍摄角度不同和复杂背景造成的车牌提取困难,通过OpenCV 对车牌区域图像进行校正,最后利用共享Loss 的卷积神经网络进行字符判识,以提高识别准确率。

Fig.1 System structure图1 系统结构
1 Android 端移植技术
1.1 OpenCV 图像处理实现过程
OpenCV 是一个开源跨平台计算机视觉库,可运行在Linux、Windows、Mac OS 和Android 操作系统上,并提供多种语言接口[7],其最大优势在于包含很多免费的图像处理函数,几乎覆盖了图像处理与机器视觉的通用算法[8]。系统开发环境为Android Studio v3.5 版本,OpenCV SDK 版本为3.4.11,具体配置方法如下。
(1)官网下载opencv-3.4.11-android-sdk,在android studio 中File >New 选择Import modules 将下载的sdk/java项目导入项目。
(2)然后把opencv modules 添加到app modules 里,直接在app 目录下build.gradle 文件里dependencies 大括号下添加依赖项:dependencies{implementation project(‘:openCVLibrary’)}。
(3)在app/src/main 目录下创建jniLibs 目录,然后把sdk/native/libs 下所有文件复制到jniLibs 目录下,编译和运行以完成库的调用。
1.2 Tensorflow 机器学习实现过程
Tensorflow 是谷歌公司开发的开源机器学习架构[9],软件开发者使用该架构可轻松构建机器学习模型,省去繁琐的底层数学推导过程,从而可快速完成算法编写。Android端移植训练神经网络模型需4 个步骤。
(1)本文使用Tensorflow 高级API Keras 进行网络训练,所以首先需将模型xxx.h5 文件转换为xxx.pb 文件。
(2)在Android Studio App 目录下build.gradle 文件中添加Tensorflow-android依赖项:dependencies{implementation‘org.tensorflow:tensorflow-android:+’}。
(3)右击项目>New>Folder>Asset Floder,在应用程序目录中创建一个资源文件夹,再将xxx.pb 模型文件添加到资源文件夹内。
(4)在MainActivity(主活动)中初始化静态变量和调用静态方法:static{System.loadLibrary(“tensorflow_inference”);}。
2 图像获取模块
图像获取主要是通过调用系统拍照功能完成,创建Button.setOnClickListener(new View.OnClickListener())拍照按钮点击监听事件,实现onClick()类,包括4 个步骤:①初始化Intent 启动相机;②定义图片存储路径;③Intent.putExtra()更改系统默认存储路径;④设置startActivityForResul(t)相机返回活动,最后实现onActivityResul(t)拍照跳转界面,通过ImageView()读取存储路径显示图片。
3 车牌识别模块
3.1 U-net 网络车牌语义分割
在自然场景下,Android 移动端由于拍摄场景不固定,所以拍摄的图片受拍摄角度、光线、背景影响很大,造成车牌区域提取困难。本文使用基于深度学习的U-net 语义分割网络。U 型网络是一个经典的全卷积网络[10-11],面向像素级预测任务,可保持原始图像相同分辨率大小的预测图,网络可分为左右两个部分,左半部分为压缩通道,右半部分为扩展通道,又称为上采样和下采样两个部分,下采样进行特征提取,下采样过程中图像通道数翻倍,并且图像特征图维度减少为之前的一半。本文采用修正线性单元ReLU 激活函数,使神经网络适用于非线性模型,上采样的作用是把特征图尺寸还原成与输入图一致,以保持输入与预测维度不变,每次经过上采样层后特征图维度加倍,但是通道数减半,最终使图像恢复成原尺寸。压缩通道包含4 个收缩单元,每个单元包含两个卷积模块和1 个池化模块,下采样完成后再经过两个卷积模块进行上采样操作;扩展通道同样有4 个扩张单元,每个单元包含一个上采样模块和两个卷积模块,最后一个扩张单元中包含上采样层、两个卷积模块和一个1×1 大小的卷积模块,跳跃连接增加了压缩和扩展通道之间的通路,网络总体结构像字符U,所以称为U 型网络,常用于医学影像和交通标志语义分割。本文网络输入图像大小为512×512,网络结构如图2 所示,图3 为自然场景下网络车牌分割效果,可以看出网络对车牌定位分割效果很好,可以应对Android 移动端复杂背景干扰。
3.2 车牌校正
对于U-net[12]网络分割后得到的车牌区域,可以看出很多区域由于拍摄角度的问题产生了形变,如果直接进行车牌字符识别,由于畸变对后续车牌字符识别造成很大干扰,所以需要对畸变的车牌进行校正[13-14]。如图4(a)为分割后得到的车牌区域图像,使用OpenCV 的cv2.findContours()函数获得车牌区域,在使用cv2.boundingRec(t)函数获取车牌外接最小矩阵,如图4(b)所示;然后使用cv2.min-AreaRec(t)函数获取外接矩阵的水平夹角θ°,将车牌区域顺时针旋转θ°至水平,如图4(c)所示;最后根据车牌4 个顶点A、B、C、D 位置坐标和其最小外接矩形A’、B’、C’、D’坐标,计算车牌四边形4 个角点坐标,使用cv2.warpPerspective()投影变化函数完成畸变车牌的校正。车牌校正效果对比如图5 所示,校正后的车牌图像为卷积神经网络字符识别模型大小,即高80、宽240。
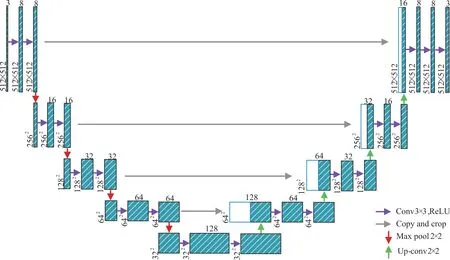
Fig.2 U-net neural network structure图2 U-net 神经网络结构

Fig.3 Semantic segmentation effects of license plate图3 车牌语义分割效果

Fig.4 License plate area correction method图4 车牌区域校正方法

Fig.5 License plate area correction effects图5 车牌区域校正效果
3.3 卷积神经网络字符识别
在数字图像处理领域,卷积是一种常见的运算。它可以用于图像去噪、增强、边缘检测等,还可以用于图像特征提取。卷积运算用卷积核矩阵从上到下、从左到右在图像上滑动,将卷积和矩阵各元素与其在图像上覆盖的对应位置上的元素相乘,然后求和,得到输出值。二维卷积计算过程如图6 所示。

Fig.6 Convolution calculation process图6 卷积计算过程
卷积网络[15]输入通常为多通道平面结构,其大小为高×宽×通道数,即输入为多通道二维特征映射。卷积核是卷积神经网络模型主要参数之一,每个卷积层多个卷积核从左到右、从上到下依次卷积整个图像,输出多个表征图像特征图,随着卷积层的增加可捕捉图像更为复杂、抽象的内部语义信息,经过多个卷积层运算,最后可得到图像在各个不同尺度的抽象表示,但是层数增加也会造成过拟合等问题。激活函数目的是为了给网络增加非线性映射,常用的激活函数有Softmax、tanh、ReLU 等,卷积神经网络结构如图7 所示。

Fig.7 Convolution neural network structure图7 卷积神经网络结构图
模型输入图片是语义分割和校正后提取的80*240 车牌区域的图片,由于普通车牌是由7 个字符组成,所以实现车牌端到端识别是多标签分类问题。每张输入图片有7 个标签,但是模型最后1 层输出前的结构可共享,只需将输出设定成7 个即可,7 个输出对应7 个Loss,总Loss 是模型7 个Loss 的总和。使用keras 框架搭建模型,使用rule 作为激活函数,最后全连接输出层连接7 个节点对应车牌7 个字符,使用Softmax 作为激活函数,dropout 参数均为0.3,每个字符均有65 种可能性。使用本文系统在不同光照背景下,不同拍摄角度采集500 张图片进行系统测试,分别使用多种图片处理验证方法有效性,系统性能如表1 所示。评价指标使用交叉比(Intersection over Union,IoU),它是在特定数据集中检测响应物体准确度的标准,用于测量真实值和预测之间的相关度,相关度越高,该值越高,计算方法是两个区域重叠的部分除以两个区域集合部分得出的结果。本文即为Unet 网络预测的车牌区域与标签真值区域重合部分除以集合部分,AP(Average Precision)标签为平均精确度,Time 为每次识别所运行的时间,单位为秒(s)。从实验结果可以看出,本文算法系统识别准确率为95.14%,较传统采用图像形态学与阈值法准确率有较大提高,原因在于本文使用Unet 车牌语义分割网络,首先对车牌区域有很好的提取效果,可解决复杂背景影响下车牌区域的分割;其次,采用共享Loss 的神经网络进行字符判识,可提高准确度、缩短运行时间,更可以减少形态学方法字符分割不均造成的误识别。

Table 1 Performance comparison of license plate recognition algorithms表1 车牌识别算法性能对比
4 系统测试
本文智能车牌识别系统APP 主界面如图8(a)所示,由两个按钮组成,右上方“Help”按钮,可以显示操作提示。点击“相机拍照”可调用系统相机,实现车辆现场拍照功能,然后点击“开始识别”按钮,系统将对拍摄的图片进行车牌字符识别,并将识别结果显示在主界面上,如图8(b)所示。
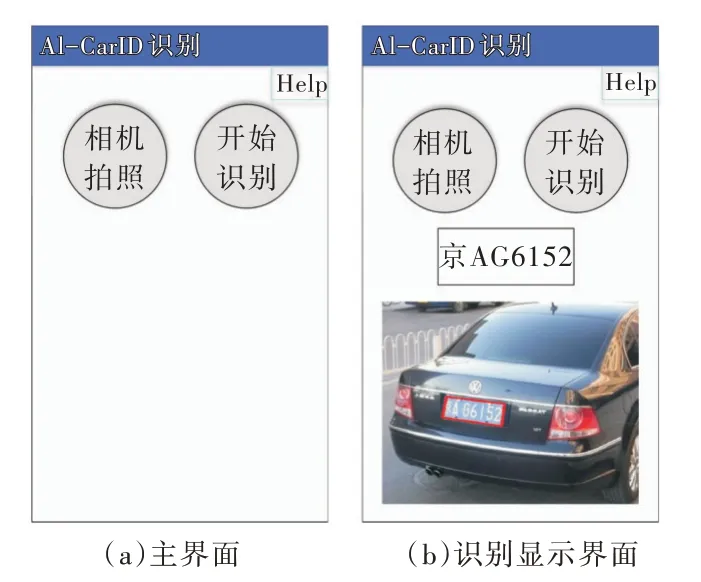
Fig.8 Mobile display图8 移动端展示
5 结语
本文使用深度学习方法,基于卷积神经网络与大量OpenCV 图像处理函数,设计并实现了在复杂背景干扰下Android 移动平台车牌识别系统。针对自然场景车牌区域定位提取和畸形校正,使用U-net 语义分割网络,给出了具体实现与移植细节。实地测试证明了系统准确性和实时性,可以安装在不同硬件的Android 移动平台上。后续将继续开发数据库存储和网络连接模块,提高系统完整性,拓宽其应用场景。
猜你喜欢
国学(2020年1期)2020-06-29
开放教育研究(2020年2期)2020-03-31
电子制作(2019年12期)2019-07-16
数学物理学报(2017年6期)2018-01-22
摄影之友(影像视觉)(2017年1期)2017-07-18
电子制作(2017年22期)2017-02-02
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
电子设计工程(2014年18期)2014-02-27
外语学刊(2011年1期)2011-01-22
