
基于深度学习的行李检测系统的设计
2021-06-22 03:22:54徐铭源杨艳红
电脑与电信 2021年4期
徐铭源 杨艳红
(苏州大学应用技术学院,江苏 苏州 215325)
1 引言
传统的安检措施,主要是通过安检员肉眼的观察来判断物品的种类,这样的方式往往效率较低,且人员调动复杂,并且由于汽车站、火车站以及飞机场等交通枢纽具有客流量大、人员复杂、流动性高等因素,传统的安检方式已经不能满足当前的需求。为了缓解安检的压力,采用深度学习算法,实现实时的智能化检测。目前,基于深度学习的目标检测方法主要有两类:一类是以Faster(F-CNN)、R-CCN[7]、SPP-Net[9]为代表的基于候选框的双阶段目标检测算法,这类算法检测精度高,但速率较低;另一类是以SSD[2]、YOLO[1]为代表的单阶段目标检测算法,此类算法检测速度较高[5]。与YOLO 算法相比,SSD算法能够兼顾大小目标的检测且效率高,因此基于深度学习的行李检测系统选择使用SSD算法。
2 系统设计
系统由检测模块、Java 后台模块和Web 前台模块组成。系统结构如图1所示。

图1 系统结构
检测模块分为两部分,一部分是先期的学习,另一部分是后期的识别与预测。学习阶段,将制作和处理好的数据集放入SSD 模型中,通过框体间的对比,将学习好的参数存入模型,以便后期使用。后期,根据实际生产环境,调用模型,实时对新的行李进行追踪与识别。Java 后台模块采用Tomcat 服务器和SpringBoot 框架,负责报警机制的设定,连接Web前台、检测模块和数据库,进行数据的传递,实现前后台的交互。Web 前台模块采用Vue 框架,使用TCP/IP 协议,响应客户端的请求,将处理好的数据传送给客户端;使用Web-Socket协议,实现Web服务器对客户端的请求。
3 SSD算法(SSD algorithm)
3.1 SSD模型结构
SSD是一个端到端的多尺度检测的模型,所有的检测和识别的过程都是在同一个网络中进行的。网络使用经典的VGG-16[18]为主干网络,这一层主要是对数据集进行预训练。在此网络的基础上将VGG-16网络层的fc6和fc7[3]两个全连接层分别用3*3 卷积层Conv6(Conv6 采用带孔卷积Dilation Convolution以及3*3大小,dilation rate=6的膨胀卷积)和1*1 卷积层Conv7。然后移除dropout 层和fc8 层,并新增一系列卷积层,在检测数据集上做Fine Tuning。紧接着从后面新增的卷积层中提取Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2 作为检测所用的特征图,加上Conv4_3 层,共提取6 个特征图,其大小分别为(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1)。这样,SSD 一共可以预测8732 个边界框。得到特征图后,特征图进行3*3卷积得到检测结果。最后,根据置信度、阈值和非最大值抑制NMS[10]对卷积后的检测结果进行筛选,筛选后的预测框就是检测结果。SSD 模型结构如图2所示。

图2 SSD模型
3.2 框体检测结构
在框体处理模块中运用了分类算法、回归算法、Jasscard系数计算、在线难挖掘(hard Negative minging)机制以及对损失函数的设计。SSD中,先验框与真实框的匹配遵循两个原则。原则一,从真实框出发,每个真实框与先验框进行比较,计算两者最佳的Jaccard(重叠)。Jaccard 系数为两个有限集的相似度,Jaccard系数越大,相关性越高。Jaccard系数计算公式为:

通过计算找到与真实框拥有最大Jaccard 值所对应的先验框,这样就可以保证每一个真实框都可以匹配到一个先验框,同时,此时的先验框被分类为正样本。如果,一个先验框没有与任意一个真实框进行匹配,那么这个先验框就只能与背景进行匹配,这时,就把先验框分类为正样本。但是,由于一张图片里真实框远远少于先验框,所以第一个原则无法满足需求。在第二原则中,将剩余还没有与真实框配对的先验框与预先设定好的阈值进行比较(阈值一般设为0.5)。将IOU大于0.5的先验框分类为正样本,IOU小于0.5的先验框分类为负样本。IOU[4]为交并比(Intersection over Union),反映了先验框与真实框的交集,假设真实框的面积为S1,候选框的面积为S2,交集的面积为S,则交并比的计算公式为:

考虑到负样本的数量远远大于正样本的数量,如果不加以调整直接训练的话会导致网络偏向于负样本,因此,SSD中通过使用在线难挖掘(Hard Negative Mining)机制,根据置信度损失值将负样本进行排序,挑选置信度损失值高的负样本框进行训练,通过这个机制,将正负样本之比调整为1:3。得到正、负样本之后,依据最小化损失函数的原则来训练先验框。SSD 的损失函数为用于分类的log loss 与smooth L1的损失函数之和,总损失函数[5]计算公式如下:

loc的损失函数(smoothL1)的计算公式如下:

框体设计如图3所示。

图3 框体设计
3.3 Anchor机制
SSD 算法与YOLO 算法的最大区别就是SSD 采用多尺度特征图的预测方法,使得SSD模型可以检测多个物体。多尺度特征图算法是在每一个特征图上设置不同尺寸和不同长宽比的候选框,每个特征图上的候选框[4]的计算公式如下:
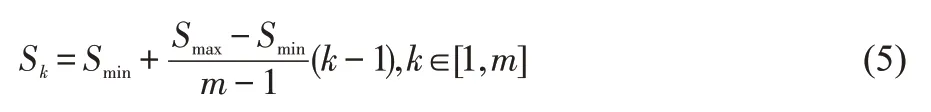
式中,Sk为第k个特征图的默认框的大小相对于网络输入的比例,Smin为最小比例,Smax为最大比例,k代表m个特征图中的第k个,其中m为特征图个数。
Anchor_box的计算与Anchor_size和ratios有关。如图4所示,Anchor_size是box的边长,ratios为每个box的长宽比,则长宽的计算公式如下:

图4 box

因此,越靠近输入层,box越小,越靠近输出层,box越大,所以SSD的底层用于检测小目标,高层用于检测大目标。
4 报警机制与安全评估
为了方便用户快速了解当前的检测情况,系统设计了报警机制和安全评估。将识别到的数据按照“危险”“警告”和“安全”三个级别,分别用红色、黄色和绿色进行标注。报警机制与安全评估设计如图5所示。

图5 报警机制与安全评估
客户端向系统发送请求,Web 模块接收并调用Java 接口,将请求传送给Java 后台;后台保存图片,生成作业信息,向云端数据库请求数据沉淀并唤醒检测进程;检测模块进行识别、划分等级,然后将扫描结果沉淀到云端数据库中,同时唤醒Java 进程;Java 模块查询并组装结果,将信息传送给Web 模块;Web 模块进行判定,然后按照报警和安全评估两条线路进行。报警线路中,依据等级信息,用红、黄、绿三种颜色分别标注。安全评估中,统计各等级的数量并绘制图表。最后将结果在客户端进行实时的可视化展示。实现效果如图6和图7所示。

图6 报警机制

图7 安全评估
5 数据增强
考虑到较少的样本会导致过拟合,实验中采用数据增强的方法,从翻转、颜色两方面增加数据集的数量。
6 实验与分析
6.1 数据集
本实验的数据集采用互联网上的公开数据集,数据集包括易爆类、刀具类、电子产品类、生活用品类等6872张行李图片。实验中,随机划分其中的5726张为训练集,1146张为测试集。通过LabelImage 工具,标注待检测的物品,生成对应的XML 文件,最后将图片和对应的标注文件按照TFRECORD格式进行存储。
6.2 实验结果分析
实验中,由于待识别的物品种类较多,采用单一的网络架构只能学习一个类别的物品,为了解决这一问题,系统采用Anchor 机制,同时,采用精确率(Precision)和召回率(Recall)作为评价指标[6]。其中,精确率是指被正确检测出来的行李类别占所有被检测到的类别的百分比,计算公式如(7)所示;召回率是指被正确检测出来的行李类别占待检测行李类别的百分比,计算公式如(8)所示。

图8 数据增强

其中,TP表示正确识别出的行李类别数量,FP表示非待检测行李类别被检测出的数量;FN 表示未被检测出的行李类别的数量。
由表1 可以看出,使用数据增强将检测结果提高了36.07%。检测效果有了较好的提升。实验对比如图9所示。

表1 检测准确率

图9 数据增强与Anchor机制
7 结语
系统首先选取长短不一的视频进行试验,通过评价指标分析,系统能够很好地定位与识别移动中的物品,并进行实时的报警和安全评估。随后,在地铁站进行实地试验,经过多次测试,系统可以较好地检测通过安检机的X 光行李,实时将数据传到云端,不间断地进行报警与安全评估。系统的检测率达到73.9%,检测效果良好,满足安检需求。
猜你喜欢
红领巾·探索(2022年11期)2023-01-06 09:19:22
防爆电机(2022年4期)2022-08-17 05:59:50
中国眼镜科技杂志(2019年9期)2019-11-11 12:15:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
小学生导刊(2018年22期)2018-11-30 07:09:19
小天使·四年级语数英综合(2018年10期)2018-10-16 01:21:42
自动化学报(2017年5期)2017-05-14 06:20:44
学生天地(2016年31期)2016-04-16 05:16:06
探测与控制学报(2015年4期)2015-12-15 15:00:56
东南法学(2015年2期)2015-06-05 12:21:36
