
基于IIOLR模型的意见领袖挖掘方法
2021-06-22 09:52黄立赫
情报杂志 2021年6期
黄立赫
(1.西北工业大学马克思主义学院 西安 710129;2.华北水利水电大学马克思主义学院 郑州 450046)
伴随着Web2.0的快速发展,以天涯、新浪等为代表的社交网络已日渐成为我国网民发表观点、宣泄情感的主要渠道。兴趣相似的用户围绕相关事件或话题展开讨论,逐渐形成网络主题社区(Network Topic Community)[1]。意见领袖(Opinion Leader)作为网络主题社区内引领舆情趋势、加速信息扩散的高影响力用户,能够对社会网络成员间的交互关系演化起到关键性作用[2]。因此,挖掘网络主题社区内的意见领袖,有助于提升虚拟化社会网络环境的治理能力,为网络舆情管控提供必要的决策依据。
目前,意见领袖的识别方法主要可分为基于用户内容和交互行为的识别方法[3,4],以及基于用户多特征的属性融合方法[5,6]。基于用户内容和交互行为的识别方法主要包括基于文本特征、交互关系、情感分析等的用户影响力计算模型,如陈芬等提出一种基于文本倾向性分析的意见领袖识别方法(TSA),该方法依据Word2Vec算法划分微博用户的情感倾向,识别虚假意见领袖[7]。吴渝等在PageRank算法的基础上提出基于用户影响力的意见领袖发发现算法(UILR),该方法依据提取的用户活跃度属性特征,确定用户间的链接关系,并以此为基础计算用户综合影响力[8]。樊兴华等提出一种基于改进的影响力扩散概率模型(IDPM),该模型将用户节点间的交互关系,转化成用户间在兴趣帖上的影响传播概率计算[9]。朱茂然等提出基于情感分析的意见领袖识别方法(LPR),该方法在主题空间上,通过构建用户情感权重矩阵,改善了评论文本中情感极性分布不均衡的问题,从网络结构和情感倾向角度识别正面意见领袖[10]。基于用户内容和交互行为的识别方法重点关注用户节点自身的单一属性特征,忽视了多维属性交互对影响力计算的作用。基于用户多特征的属性融合方法,本质上通过分析用户节点的交互行为、网络结构、情感语义等属性特征,实现用户影响力的综合排序。曹玖新等通过联合建模用户结构、行为以及情感特征,实现面向用户多维影响力分布的意见领袖识别(MFP)[11]。陈淑娟等提出面向主题社团的意见领袖挖掘方法(QMOLA),该方法通过构建基于用户兴趣的隐狄利克雷分布,获取用户间主题相似度,再依据传播特征与情感特征识别主题社团高影响力用户[12]。张继东等通过将用户交互关系与情感分析相结合,提出一种面向移动社交网络的影响力计算模型(IBET),该方法综合了用户节点的活跃度与文本情感极性,识别出具有较高支持率的意见领袖[13]。
综上所述,本文从社区用户的兴趣传播视角,研究了网络社区中用户兴趣在时间维上的演化特点,将兴趣继承概念引入用户节点多维属性分析,提出一种基于兴趣继承的意见领袖识别方法(IIOLR),该模型假设t时刻的网络社区是t-1时刻的兴趣后验,同时继承了t-1时刻的用户节点兴趣度。通过构建平滑时间维上的高影响力用户多维特征继承因子,度量用户在兴趣维上的影响力分布,实现意见领袖的在线识别。
1 兴趣社区意见领袖挖掘框架
兴趣社区是网络用户依据自身的爱好,围绕某一主题进行交流而逐渐形成的移动社交网络[14]。意见领袖可视为在特定时段内兴趣社区中具有相对较大影响力的用户,故可将t时刻基于特定兴趣主题的意见领袖识别问题,转化成用户影响力的计算与排序问题。兴趣社区的高影响力用户挖掘主要包括兴趣主题识别、兴趣社区构建、用户节点多维特征分析以及用户影响力计算。
总体技术框架如图1所示。a.兴趣主题识别。依据用户的文本信息进行主题识别,获取用户在不同兴趣维下的主题,建立用户与兴趣主题间的映射。b.兴趣社区构建。根据用户间的语义关系,完善兴趣社区拓扑结构,建立用户间加权边映射。c.用户节点多维特征分析。在分析兴趣社区中用户属性特征的基础上,利用节点的兴趣度继承信息,构建用户节点特征矩阵,形成目标用户集合。d.用户影响力计算。综合用户多维属性特征以及情感极性分析,计算用户综合影响力,从而识别出意见领袖。
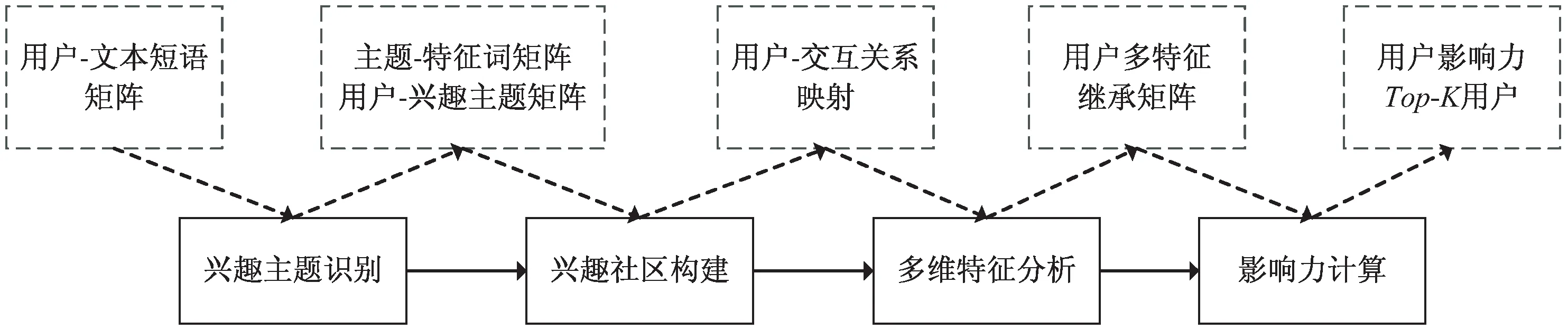
图1 兴趣社区意见领袖挖掘框架
1.1兴趣主题识别本文采用基于ATM(Author Topic Model)[15]的用户兴趣主题识别方法,该方法是在LDA主题模型的基础上增加作者信息,使其在分析文档主题分布的同时,获取用户的兴趣分布。ATM模型的核心是建立用户-主题概率分布,即假设用户文档中每个用户是用户-主题的混合多项分布,每个主题又是主题-词汇的混合多项分布。用户依特定的概率抽取主题,主题依特定的概率选择特征词汇。ATM是一个多层Bayes网络,如图2所示。

图2 ATM模型示意图
图2中,θ是文档的T个主题分布矩阵,φ是主题词分布矩阵,ad是用户集合,x是选定某个词的用户,z是词的主题,w表示词本身。ATM模型假设每个用户均存在K个主题的兴趣分布。首先从用户集合ad中选择给定的用户x,生成其对应文档的主题分布并生成主题,再从该主题的词汇分布中选择词汇。ATM模型的联合后验概率分布如公式(1)所示。将公式(1)通过Gibbs抽样,获取用户-主题分布以及主题-特征词分布。
(1)
1.2兴趣社区拓扑构建兴趣社区构建主要通过分析在线社交网络用户的文本数据,抽取具有不同偏好需求的用户兴趣主题,并建立用户与主题间的关系映射[16]。为便于表述,本文使用三元组(U,R,W)表示兴趣社区I,其中,U为用户节点集合,R为用户节点间的边集合,W是边上的权重。兴趣社区拓扑构建主要分成两个过程:首先基于ATM模型识别用户-兴趣主题矩阵,建立用户-主题映射和主题-特征词映射,并通过用户-文档矩阵,实现主题-用户的语义关联,构建用户节点集合U。其次,获取集合U内任意(ui,uj)间关联关系,建立用户节点间的加权边,得到兴趣社区的拓扑结构。兴趣社区拓扑构建过程如图3所示。

图3 兴趣社区拓扑构建图
2 兴趣社区意见领袖特征分析
现实场景中,用户影响力往往随着用户兴趣变化而波动,意见领袖的识别需要考虑兴趣社区拓扑结构的动态演化[17]。意见领袖作为影响力数值较高的一类用户,其在时间维上往往表现出较为强烈的动量特性,即用户u在t时刻对某一主题的兴趣度会对其在t+1时刻的影响力产生影响,且在没有环境突变的情况下,表现出一种缓慢传递的特性。如意见领袖因“兴趣迁移”,使得其兴趣特征值降低,但其在兴趣社区内的综合影响力会因为其以往在大众传播中的“优势地位”,而不会骤然降低。本文将用户兴趣度在时间维上对影响力变化产生的作用称为兴趣继承。IIOLR模型认为兴趣社区的形成主要依赖于两种内在牵引力,即兴趣牵引力与情感牵引力。兴趣牵引力主要由环境特征、主题特征以及行为特征所决定,环境特征主要指由长期兴趣关注而出现的好友关注、圈友关联等,主题特征主要指由短期兴趣变化引起的主题分布漂移等,行为特征主要指由不同兴趣强度而产生的用户社区活跃度与传播度等。情感牵引力主要通过分析用户节点的文本情感极性,挖掘用户间的语义情感倾向。由于用户的兴趣继承性质,作用于用户影响力的节点特征需要综合考虑多种牵引力继承因子。因此,用户节点兴趣继承可细化为环境特征继承、主题特征继承、行为特征继承和情感特征继承。
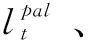
(2)
(3)
(4)

(5)


(6)

(7)
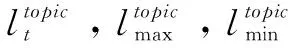
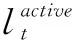
(8)
(9)
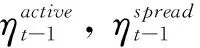
(10)

t-1时刻的上述三种特征分量通过节点的兴趣属性实现“继承传递”,并以兴趣牵引力的形式作用于t时刻的兴趣社区。因此,依据t-1时刻的社区兴趣牵引力,构造t时刻的兴趣继承算子,计算t时刻用户兴趣牵引力ITRt(ui),如公式(11)所示。
(11)
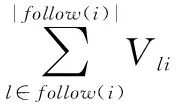
2.4情感特征继承在外部环境不发生强烈变化的条件下,用户对兴趣主题的情感通常具有“惯性”特征,表现为意见领袖在社区情感上具有较强的倾向性引领[18]。群体用户对某一用户文本的正向评价次数,往往能够体现对其支持的程度,从而增加其作为意见领袖的概率。同样,反向评价则会减少其作为意见领袖的概率。情感字典的情感极性包括正面情感、负面情感和中性情感[19]。依据情感字典获取用户文本的情感特征词,进行情感极性分析,得到用户节点对其兴趣主题的情感值,计算如公式(12)所示。兴趣社区用户群的情感牵引力计算如公式(13)所示。
(12)

(13)
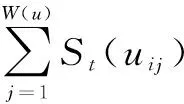
2.5用户影响力计算用户影响力需要综合考虑用户节点在社区结构中的兴趣牵引力,以及用户节点间信息传递所产生的情感牵引力。本文用户节点兴趣继承综合分析了环境特征继承、主题特征继承、行为特征继承和情感特征继承,利用t-1时刻的兴趣继承算子构建t时刻的特征向量分布,由此得到t时刻的用户影响力INFt(ui),计算如公式(14)所示。
(14)
其中,σ、1-σ分别为用户兴趣牵引力与情感牵引力的权重参数;ITRt(ui)max为用户ui在t时刻兴趣牵引力的最大值。用户影响力计算具体实现如算法1所示。
算法1 兴趣社区意见领袖挖掘算法
输入:用户节点集合U,用户间加权边集合
输出:用户节点影响力排名TOP-K
1. Initializeφ//初始化支持度阈值
2.Compute Et(ui) //计算节点ui的环境特征
3.Compute Ct(ui) //计算节点ui的主题特征
4.Compute Bt(ui) //计算节点ui的行为特征5. If (ITR(uij) >φ) //选取兴趣支持度大于阈值周围节点
6.Bt(ui) = Bt(ui)+ ITR(uij)
7.ITR(ui)= Et(ui)+ Ct(ui)+ Bt(ui)//计算节点ui的兴趣牵引力
8. ComputeSt(ui) //计算邻居节点对ui的边情感特征值
9.ComputeINF(|U|) //计算节点集合U的影响力
10. Sort (INF(|U|)) //进行用户影响力排序并输出数值较大的K个节点
3 实 验
3.1实验数据实验数据来源于天涯微博社区,通过设计多线程爬虫工具收集2020年7月1日-8月30日的网站用户发帖及回帖数据,获取有效用户评论372459条,涉及用户64533人。在经过文本分词,去除停用词等预处理后,建立用户-文本短语映射矩阵Maru。选取规模较大的“科研人员集体出走”、“腾讯起诉老干妈”、“林丹退役”、“源代码泄露”等四个事件作为兴趣主题集,分别标记为MaruD1-MaruD4,统计信息如表1所示。以每个事件的发生时间作为数据流起始点,以“周”为划分单位,连续统计4周,标记为t1-t4,并分别创建相应时间片下的兴趣网络拓扑。
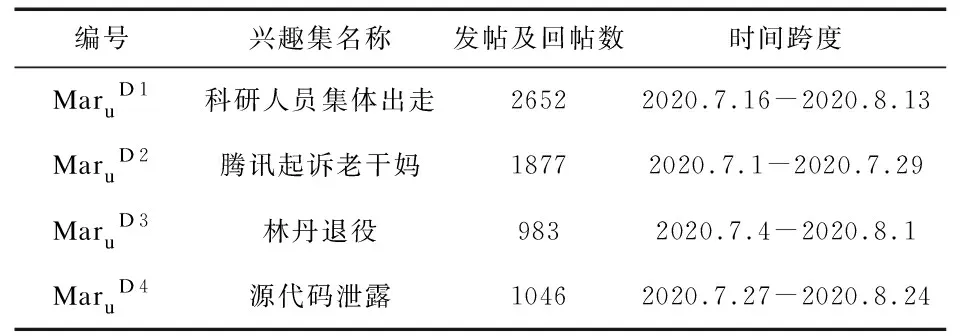
表1 四类兴趣主题集信息
3.2参数分析IIOLR模型通过构建高影响力用户多维特征继承因子,计算用户在兴趣维上的影响力分布,实现意见领袖的在线识别。在计算用户影响力之前,需要确定模型中相关参数的取值。为便于说明,本文将IIOLR模型中的参数整体划分为三类:继承类参数,特征分量参数以及特征牵引力参数,具体见表2。

表2 IIOLR模型参数对照表

(15)


图4 行为特征分量参数的相关性分析
兴趣牵引力σ与情感牵引力1-σ反映了兴趣因素与情感因素对意见领袖识别的影响程度。本文通过对比不同情感牵引力1-σ的取值,预测高影响力用户在社区情感上的准确率,选择最能表达情感牵引力变化的权重参数,计算如公式(16)所示。
(16)

图5 情感牵引预测准确率对比

3.3实验结果与分析
3.3.1 用户兴趣群体识别 依据最小困惑度[20],计算不同兴趣主题集在连续时间片下的最优主题数,分别确定t1-t4时间片的最优主题数。采用主题分析ATM算法及Gibbs抽样,以MaruD1为例,构建的部分用户-主题映射表如表3所示。
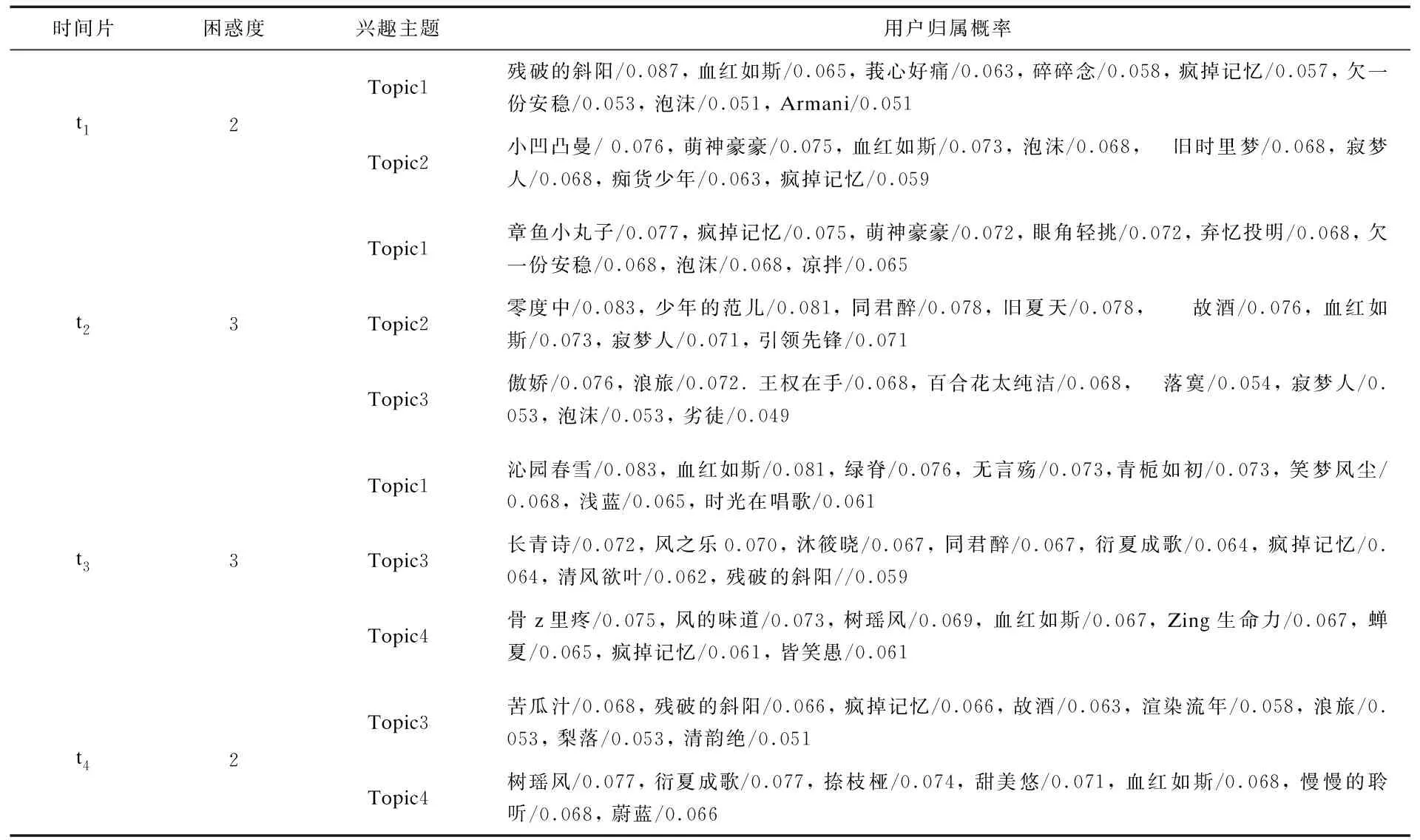
表3 “科研人员集体出走”社区用户-主题映射表(部分)
3.3.2 节点影响力计算 依次构建“科研人员集体出走”事件在4个时间片下的社区拓扑结构,并将其带入IIOLR模型,分别计算对应时间片内所含用户节点的影响力INFt(ui)。图6是以t1时间片下影响力数值较高的“血红如斯”“砍柴少女”“小飞侠”“残破的斜阳”“泡沫”等五位用户节点为例,绘制在t2时间片存在话题共存现象(Topic2与Topic3)的影响力演化图。

图6 不同主题下用户节点的影响力演化图
分析图6可知,用户节点的影响力存在如下演化信息:在时间维上,a.用户的影响力呈现出波动的特点。如“血红如斯”用户的影响力值在t3时刻急剧下降,结合用户-主题映射表可知,其在t3时刻的主题特征继承值较低,兴趣迁移较明显,使得其在Topic2的影响力变化较大。b.部分用户在一段时间内具有相对较稳定的影响力。如Topic3的“小飞侠”与“泡沫”用户。在兴趣维上,c.不同兴趣主题下,用户的影响力存在差异。如“砍柴少女”用户在Topic2与Topic3内,在t1-t4时间片下的影响力数值差异较明显,经人工分析发现该用户的认证身份为领域技术专家,该类用户发展为“单一型”意见领袖的可能性较高。d.个别用户在不同兴趣主题下,影响力均较靠前。如“血红如斯”用户,分析后发现,其认证身份为社会知名网友(大V用户),其在t1-t4时间片下的行为特征继承值较高,该类用户通常具有“综合型”意见领袖的潜质。
3.3.3 意见领袖识别 意见领袖作为是兴趣社区中具有较高影响力的用户,通常是在线社区中热门话题的发起者或意见(情感)的引领者。前者往往通过其自身较高的活跃度,形成一定的舆论影响力;而后者则通过自身的情感表达,引领大众用户发生情感变化[23]。因此,本文将上述两类群体作为意见领袖识别对象,通过分析t时刻意见领袖的兴趣牵引力与其所在主题社区普通用户在t+1时刻兴趣牵引力的相关性,识别第一类意见领袖。类似地,通过分析t时刻意见领袖的情感牵引力与其所在主题社区普通用户在t+1时刻情感牵引力的相关性,识别第二类意见领袖。具体识别过程如下:首先计算MaruD1中4个主题在不同时间片下的用户影响力INFt(ui),选取影响力指数较高的TOP-400用户,再分别计算ti时刻用户ui与其所在主题内其余用户群体在ti+1时刻的兴趣牵引力以及情感牵引力之间的相关系数,最终选出相关系数最大数值下的TOP-K意见领袖。以t1和t2时刻共存的Topic2主题为例,图7是TOP-400用户的牵引力相关性示意图。
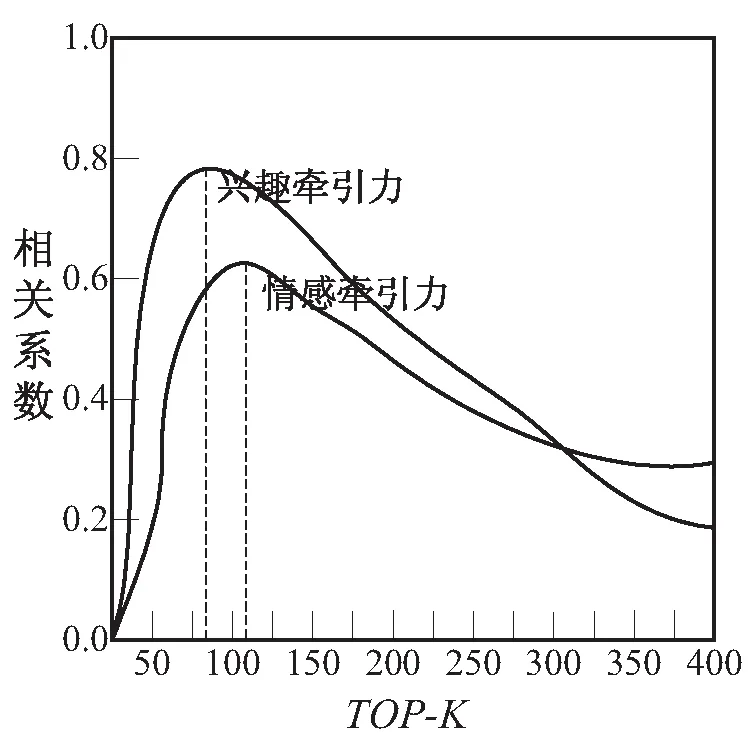
图7 Topic2中TOP-400用户的牵引力相关系数
依据图7,当K分别为83和108时,t1和t2时刻的意见领袖与普通用户在兴趣牵引力以及情感牵引力上的相关系数取到最大值,故选取相应的高影响力用户作为Topic2社区的意见领袖。
3.4模型分析
3.4.1 评价指标 为了相对客观的验证本文提出的IIOLR模型的有效性,实验使用覆盖率和支持率两种评价指标进行对比分析。覆盖率主要从兴趣主题的传播视角,衡量意见领袖在兴趣牵引力方面的影响力,具体计算如公式(17)所示。支持率主要从话题情感的扩散角度,衡量意见领袖在情感牵引力方面的支持程度,具体计算如公式(18)所示。
(17)
其中,|forward(uj)|表示兴趣社区内转发用户ui的用户数,N表示兴趣社区内的用户总数。
(18)
其中,|Positive(uj)|表示兴趣社区内对用户ui持有正向评价的用户数,N表示兴趣社区内的用户总数。
3.4.2 对比实验 为了验证IIOLR算法的有效性,实验分别选取标记为MaruD2“腾讯起诉老干妈”、MaruD3“林丹退役”数据集,按照上述实验流程,分别与MFP[11],UILR[8],IDPM[24],QMOLA[12]四种方法进行对比分析,依据各自算法计算用户节点影响力指数,并根据TOP-K排序,综合评估算法在MaruD2上的覆盖率(结果见图8),以及在MaruD3上的支持率(结果见图9)。

图8 算法覆盖率的实验对比 图9 算法支持率的实验对比
由图8的实验结果,可以得出以下结论:首先,基于多特征的影响力计算方法IIOLR、MFP和QMOLA的覆盖率要明显高于基于用户单特征的意见领袖挖掘算法UILR、IDPM,该结论进一步验证了在大规模社会网络中,面向用户节点真实状态的多维属性文本分析,能够有效还原意见领袖在用户交互以及观点传递方面的中介作用。其次,IIOLR算法在250≤K≤600的范围内,覆盖率值明显高于QMOLA与MFP算法,其主要是因为MFP算法虽然能够融合网络拓扑特征与话题情感倾向,实现社会网络内容的语义感知,但未考虑到节点属性间在时间维上的传递依赖;而QMOLA算法虽然在意见领袖较少时,在数据集上的主题覆盖率较高,但后期随着意见领袖数的增多,覆盖率逐渐下降,其原因是该模型将多维网络传播特征作为用户间主题相似度的决定因素,与情感特征的融合度较低,无法有效解决复杂网络下用户影响力中断问题。而IIOLR算法通过计算不同时间快照下的用户兴趣牵引力,有效融合用户节点的环境特征、主题特征以及行为特征,从而降低了虚假影响力的扩散可能。
分析图9可以得到以下结论:a.UILR与IDPM算法均基于用户节点的局部特征,无法将用户文本情感与主题特征进行联合建模,因而算法在话题情感方面的支持率较低;b.MFP算法依赖于独立时间片下的情感识别,没有将意见领袖的属性特征变化与在线社区的兴趣演化相关联,难以捕获社交网络的动态特性;c.QMOLA算法虽然将用户兴趣属性融入主题社团划分,但未考虑到用户因兴趣迁移而发生的情感遗传问题[25];d.IIOLR算法在K≥650时,模型的支持率较高,其原因主要是IIOLR算法利用t时刻意见领袖与t+1时刻社区一般用户间情感牵引力的的相关性,建立面向兴趣维的情感传递,从而提高了意见领袖的识别精度。
4 总 结
本文将兴趣继承概念引入意见领袖节点挖掘中,提出一种多属性继承的主题社区意见领袖识别方法(IIOLR),该方法通过捕获t-1时刻用户节点的环境特征、主题特征、行为特征和情感特征,实现t时刻用户节点影响力的先验分析,然后基于用户综合影响力TOP-K用户,计算社区普通用户在t+1时刻的牵引力相关系数,最终实现意见领袖精准识别。通过与传统意见领袖挖掘算法进行对比验证,证明了该模型在动态网络环境中,具有相对较高的覆盖率与支持率。然而,考虑到复杂社会性网络中意见领袖的时空特性,未来可从话题与意见领袖联合演化,意见领袖动态兴趣识别等角度,提升算法的鲁棒性。
猜你喜欢
黄河之声(2022年6期)2022-08-26
好日子(2019年4期)2019-05-11
NBA特刊(2018年14期)2018-08-13
当代陕西(2018年12期)2018-08-04
科技创新与应用(2017年26期)2017-09-12
科技创新与应用(2017年1期)2017-05-11
人大建设(2017年11期)2017-04-20
中学生数理化·高一版(2016年4期)2016-11-19
科技与创新(2016年6期)2016-04-21
艺海(剧本创作)(2015年1期)2015-12-19
