
基于改进的度折扣方法研究社交网络影响力最大化问题
2021-06-19 06:46张海峰
电子科技大学学报 2021年3期
夏 欣,马 闯,张海峰*
(1.安徽大学数学科学学院 合肥230601;2.安徽大学互联网学院 合肥 230601)
在线社交平台如Twitter、Weibo、WeChat、Facebook等已经成为人们生活中不可或缺的重要工具,引起了不同领域的学者对社交网络的广泛关注与研究,如社交网络上的影响力最大化问题、链路预测、社团发现及推荐系统等[1-4]。其中影响力最大化问题因其普遍的应用场景而被广泛研究,如在广告投放和市场营销中如何用有限的成本选择具有较大传播力度的人物、地点投放广告,使得了解并且购买该产品的用户最多,从而获取最大收益。在疾病和谣言的传播链中,控制网络中影响力大的节点可以避免其大规模快速传播[5-6]。
影响力最大化问题是指在一个网络中选择一定数目的节点作为种子集,通过激活这些种子节点,使得信息在网络中传播,最终希望网络中被激活的节点数最多。影响力最大化算法主要分为3类:贪婪算法、中心性指标和启发式算法。
在贪婪算法中,文献[7]将影响力最大化问题定义为一个离散的优化问题,证明了在独立级联模型和线性阈值模型下该问题是一个NP-Hard问题。并进一步提出了近似比为(1−1/e)的爬山贪心算法,在每一步迭代中都选择当前边际传播范围最广的节点加入种子集。文献[8]利用子模性提出了CELF(cost-effective lazy forward)算法,该算法大大减少了计算时间。文献[9]提出了改进的CELF++算法,减少了不必要的计算次数。文献[10]提出NewGreedy算法,以传播概率保留网络中的边,根据子图的连通性考虑节点加入种子集的增益。由于NewGreedy算法无法保证子模性,文献[11]提出了一个静态的贪婪算法StaticGreedy算法,能够解决影响力最大化中的精确度可扩展性问题。贪婪算法虽然能找到影响力较大的种子节点,但其时间复杂度太高,不适用于大型网络。
第二类解决影响力最大化问题的方法是基于网络的拓扑结构对节点的影响力排序,使用中心性指标对网络中的节点排序,选择前K个中心性指标最大的节点作为种子节点[12]。基于网络结构定义的中心性指标有度中心性指标、接近度中心性及介数中心性等[13-16]。文献[17]系统回顾了关键点识别中的概念和度量,并对问题和方法进行了分类,通过广泛的实证分析,比较不同方法的适用性。此外,很多学者提出新的影响力排序方法,如文献[18]认为种子节点应该分散在网络中,定义了GCC (generalized closeness centrality)指标。文献[19]提出网络节点的H指数衡量节点的重要性。文献[20]通过构造算子说明了节点的度、H指数和核数之间的关系,该关系被定义为DHC定理。文献[21]结合节点的K-shell值和节点间最短路径长度,将K-shell值看做节点重力,提出重力中心性指标。
使用中心性指标选取种子节点,忽略了节点间的重叠性,可能造成传播过程中的冗余,为了寻找更加高效的解决方法,启发式算法被相继提出。如文献[22]考虑局部影响区域迭代节点的全局影响力提出了IRIE (influence ranking influence estimation)算法。文献[23]通过节点间的简单路径近似计算节点的传播影响力,并且考虑不同的优化方法减少扩展中迭代调用的次数,提出了Simpath算法。文献[24]介绍了识别网络中单个有影响力节点的方法、特点和性能,同时介绍利用启发式算法寻找多个影响力节点的研究方法。文献[25]考虑种子集到其他节点的最短路径得到种子集影响范围,提出SPM(shortest-path model)算法。文献[26]基于节点相似性提出了启发式的聚类算法,选取聚类质心作为种子节点获得较大传播范围。文献[10]基于节点的度提出了启发式的度折扣(degree discount,DD)算法,度折扣算法比贪婪算法的运行速度快了近千倍,并且能达到与贪婪算法较为接近的效果,因此受到广泛关注。
虽然度折扣算法具有快速、高效的特性,但该算法还有许多需要改进的地方,这些不足之处是制约该算法性能进一步提升的关键因素。首先,度折扣算法在计算节点的期望影响力时没有考虑邻居的差异性,而是简单地认为每个未激活的邻居节点对该节点期望影响力的贡献是相同的,导致计算期望影响力的公式不够精确。其次,度折扣算法没有考虑节点之间共同邻居数的影响,不能充分降低传播的冗余性,比如节点i和j之间有许多共同邻居,如果节点j已被选择为种子节点,则节点i被感染的可能性也很高,因为他们之间有多条可能的传播路径,此时再选择节点i作为种子节点会导致传播的冗余效应[27]。针对以上两个问题,本文首先对度折扣算法中计算期望影响力的公式进行修正,然后基于共同邻居数引入冗余弱化效应进一步改进度折扣算法。
1 影响力最大化与传播模型
1.1 影响力最大化问题描述
用网络图G=(V,E)表 示社交网络,其中V是节点集,代表社交网络中的用户;E是边集,代表社交网络中用户之间的关系。影响力最大化问题就是在网络中找出K个节点作为种子集S,然后按照规定的传播模型将信息传播给邻居节点,使得最终能影响的节点数最多。在特定的传播模型M下,任意种子节点集S的影响力可以表示为σM(S)。因此,网络上影响力最大化问题的形式化定义为:
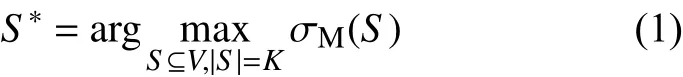
1.2 独立级联模型
在独立级联模型(independent cascading model,IC)中,网络中的节点有两种可能的状态:未激活态和激活态。同时为网络中的每条边(i,j)分配一个[0,1]间的概率值βij作为信息在该条边上的传播概率。IC模型具体传播过程如下:
1)在t=0时刻,选定K个节点构成种子集S0,仅将种子集中节点设为激活状态,其余节点为未激活状态。
2)在t+1时 刻,每一个激活节点i∈St,以概率βij尝试激活邻居中的未激活节点j。若激活成功,则该邻居节点j由未激活状态转为激活状态,否则仍保持未激活状态。并且每个激活节点只有一次激活邻居的机会,无论是否成功激活,该节点在下一轮将不具有激活能力。节点j有多个种子邻居时,每个种子邻居都独立的激活节点j,如种子节点i和h均 为节点j的邻居,则j被激活的概率为1−(1−βij)(1−βhj)。
3)直到某个时刻,网络中所有节点都不再具有激活其他节点能力时,传播过程结束。
2 改进的度折扣算法
2.1 度折扣算法
度折扣算法的基本思想是:假设节点j是节点i的邻居,如果j已被选为种子节点,那么在基于度中心性指标考虑节点i是否作为种子节点时,应该对连边(i,j)打 折扣,因为i对j不能产生额外的影响。假设所有边的激活概率都相同,均为β。当节点i的邻居中有si个激活种子时,i被激活的概率为1−(1−β)si, 此时i节点能被邻居节点激活,其期望影响力与直接将i节点选为种子节点的期望影响力相同,即此时选择节点i作为种子节点不增加额外的影响力(对期望影响力的贡献为0)。由于节点i没有被激活的概率为(1−β)si,当节点i被选为种子时,其能激活的节点数为1+(di−si)β,其中“1”表示节点i被激活,“(di−si)β”表示被激活的邻居数。因此考虑节点i选为种子时,其产生的期望影响力为:

当节点i邻居中没有种子节点时,i作为种子节点产生的期望影响力为:1 +diβ≜B。设 γ是对邻居中每个种子节点的度折扣,则siβγ≜B−A,可以得到γ=2+(di−si)β,因此,当节点i有si个种子邻居时,它的度折扣值定义为:
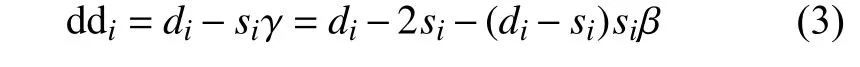
度折扣算法的基本步骤为:第一轮中没有种子节点,所有节点的度都没有被折扣,所以直接选择网络中度最大的节点作为第一个种子;接下来每一轮根据式(3)计算每个未被激活节点的度折扣值ddi,并选择最大的一个节点加入种子集;循环更新计算直到选出K个种子节点加入种子集S。
2.2 一阶改进的度折扣算法
度折扣算法认为所有非激活的邻居对节点i贡献的期望影响力都是相同的,即为β。实际上这些未激活邻居对节点i贡献的期望影响力是不同的,如节点i有两个未激活邻居j和l, 如果节点j的邻居中已经有很多种子,而节点l的邻居中没有种子节点,如果节点j和l均 被激活,则节点l有更大的可能性是被i激活的,而节点j很可能被其他节点激活。因此节点j和l对 节点i期望影响力的贡献是截然不同的,如图1a所示,其中实心黑色节点处于激活状态,空心节点为未激活状态。基于此,本文对计算期望影响力的公式进行如下修正(IDD1算法):
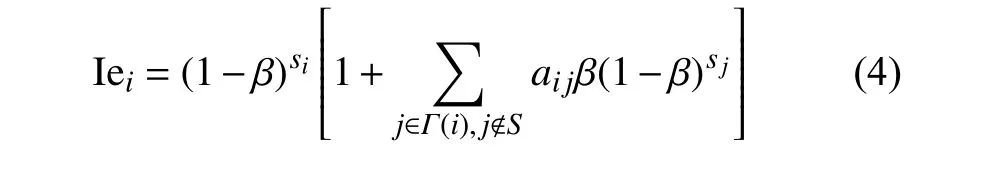
式中,aij表示邻接关系,aij=0表示节点i与j没有连边,aij=1表 示节点i与j有连边。在考虑节点i的期望影响力时需要考虑非激活邻居节点自身邻居中种子节点的数量,若这些非激活邻居周围种子节点越多,则对i贡献的期望影响力越小。
IDD1算法的基本步骤为:第一轮中直接选择网络中度最大的节点作为第一个种子;接下来每一轮根据式(4)计算每个非激活节点的期望影响力Iei,选择最大的一个节点加入到种子集;循环更新计算直到选出K个种子加入S。
2.3 二阶改进的度折扣算法
在选择多个节点作为种子节点时,除了要考虑节点自身的重要性,另一个重要因素是如何确保种子节点在网络上分布充分分散,避免传播的冗余性。考虑如下情景:节点i与节点j之间有许多共同邻居,对于IC模型而言,若节点j已经被选择为种子节点,则节点i有很大的概率被激活(通过直接连边激活和多个共同邻居激活),此时再选择节点i作为种子节点对提高传播影响力的作用是非常有限的,因此选择的种子节点之间应该避免有多个共同邻居的情况,如图1b所示。基于此,本文在IDD1算法基础上引入基于共同邻居数的冗余弱化机制,保证种子节点的分布足够分散。令Cij为节点i和j的共同邻居数,定义节点i的影响期望力为Cei,则:
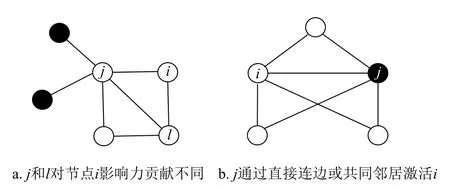
图1 网络示例图

式中, α>0是可调参数,如果 α太大会导致所有邻居的贡献为0,若 α太小会导致邻居的贡献差异性被忽略,本文取α =0.05。
IDD2算法的基本步骤如下:首先选择网络中度最大的节点作为第一个种子;之后每一轮根据式(5)计算其他未激活节点的Cei,选择 Cei值最大的节点作为种子;循环更新计算直到选出K个种子加入S。
3 实验与分析
本文在4个真实网络上对本文提出的IDD1算法和IDD2算法进行性能测试,使用IC模型与一些启发式算法进行比较,包括度折扣算法(DD)、度中心性算法(degree)以及随机选择种子算法(random)。本文没有与贪婪算法进行比较,一方面是因为贪婪算法的时间复杂度太高,对于规模上万的节点非常耗时。另一方面,如文献[10]所述,度折扣算法虽然是一种启发式算法,但是该算法的性能接近于贪婪算法。实验结果表明了本文提出的IDD1算法和IDD2算法性能均优于度折扣算法,因此更接近于贪婪算法。另外这两个算法均是基于局部网络结构的启发式算法,与度折扣算法的时间复杂度接近。
3.1 数据集与实验设置


表1 4个经验网络的结构性质
本文使用IC模型作为传播模型,每条边上的激活概率均为β,从最终激活节点的比例、传播速度以及运行时间3方面比较不同算法的优劣性。为了保证结果的可靠性,所有方法均独立传播1000次取平均结果。
3.2 实验结果
3.2.1独立级联模型
本文在4个真实网络上比较了不同算法选择种子集的影响范围和传播速度,并且定义了种子集的平均度和平均最短路径长度解释模型的有效性。
1)影响范围
图2显示了不同算法产生的最终传播范围随着种子数K的变化情况,用 σ(S)表示激活节点占网络的比例。前3个网络的传播率均设为0.1,由于第4个网络传播阈值较小,传播率设置为0.06。由图2可知:度折扣算法比度中心性算法以及随机算法更能提高传播范围,而本文提出的IDD1算法虽然只是对度折扣算法的公式进行简单修正,但实验结果表明该算法在4个真实网络均优于度折扣算法。当考虑冗余弱化机制时,IDD2算法能够更加明显地提高扩散范围。对于网络规模比较小的TAP网络而言,在种子数较小时,IDD1算法优势比较明显,而对于较大的网络而言,IDD1的优势在种子数较多时能更加凸显。
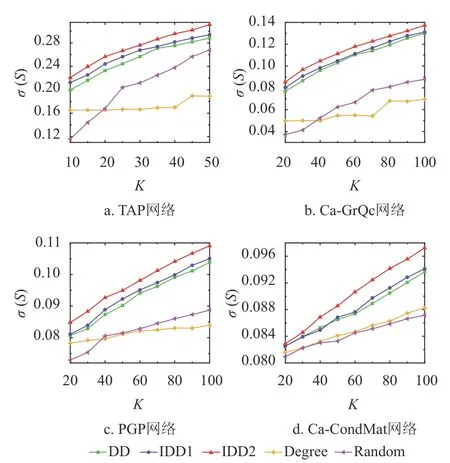
图2 最终影响范围随着种子数的变化情况
图3是在固定种子数的情况下进一步研究最终传播范围随着不同传播概率β的变化情况,其中TAP网络20个种子,Ca-GrQc和PGP网络50个种子,Ca-CondMat网络70个种子。实验结果再次表明,IDD1算法比度折扣算法更能提高扩散范围,而引入冗余弱化机制的IDD2算法则在所有网络上都是效果最显著的。
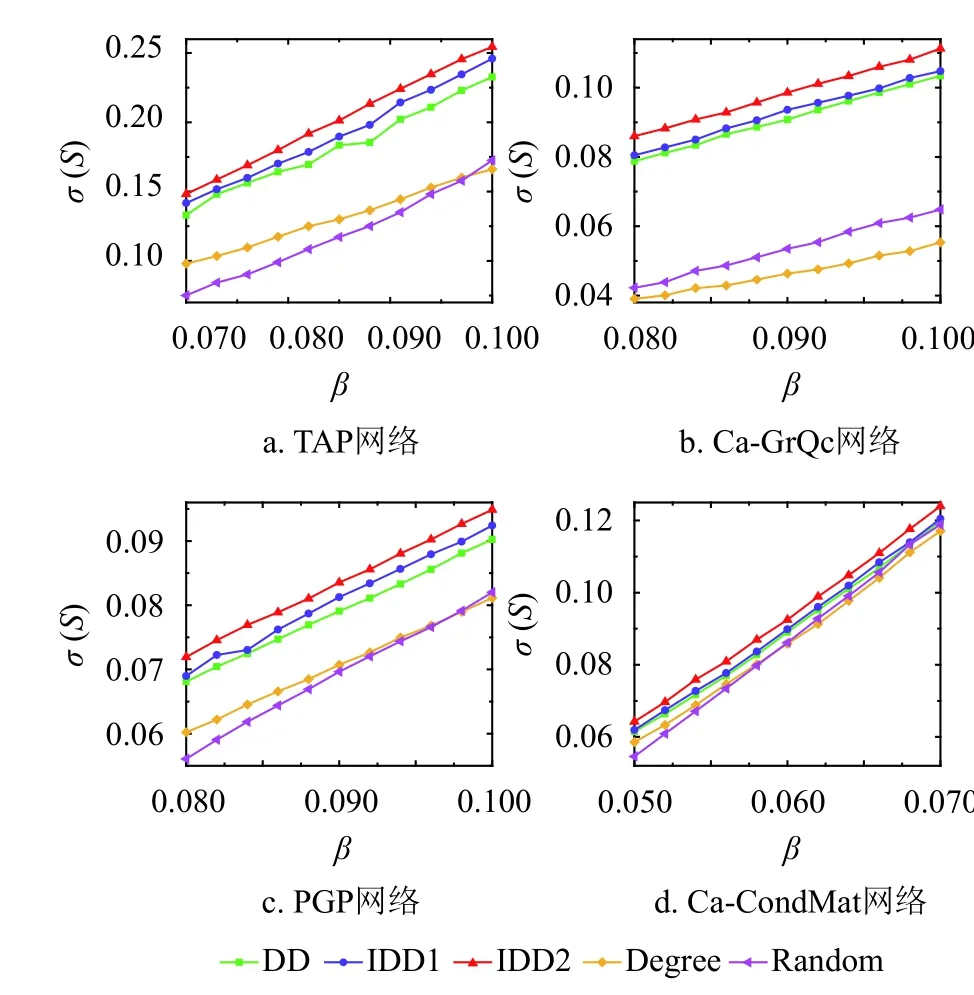
图3 最终影响范围随着传播率的变化情况
2)传播速度
本文在固定种子数量以及传播率β的情况下,比较不同算法对传播速度的影响,如图4所示。其中,TAP网络固定β=0.1,K=20;Ca-GrQc网络和PGP网络固定β=0.1,K=50;Ca-CondMat网络固定β=0.06,K=70。t表示信息传播的迭代过程,用σt(S)记录每次传播后网络中激活节点比例。从实验结果可以看出IDD1算法从一开始就以较快的速度扩散信息,并且最终传播范围也高于已有算法。

图4 影响范围随着时间的变化情况
IDD2算法在前几步传播过程中传播范围略低于度折扣算法和IDD1算法,这是由于IDD2算法选择的种子在网络中较为分散,因此需要经过一个短暂的酝酿过程。经过一小段时间后(3~6个时间步),IDD2算法的传播速度快速反超其他算法,并且得到的最终传播范围在所有算法中最广。从图2~图4可以发现,无论是最终传播范围还是传播速度,相比于其他算法,IDD1和IDD2算法都能取得更好的性能。
3)种子集性质

式中,Lij是 节点i和节点j的最短路径长度;〈L〉S指标越大,种子之间越分散。
此外,种子节点的平均度〈d〉S随种子数的变化情况如图5所示,而种子节点间平均最短路径〈L〉S随种子数的变化情况如图6所示。其中TAP网络、Ca-GrQc网络和PGP网络的传播率设为0.1,Ca-CondMat网络的传播率设为0.06。从图5和图6可以发现,虽然度中心性算法能保证种子节点的〈d〉S最大,但是基于该算法得到的〈L〉S值均小于度折扣算法以及IDD1和IDD2算法对应的值。反之,虽然随机算法能保证种子节点的〈L〉S值最大,但是 〈d〉S值最小。度中心性算法和随机算法只能保证影响力最大化中两个关键因素中的某一条:1)种子节点自身很重要;2)种子节点足够分散地分布在网络上。度折扣算法以及改进算法得到的〈d〉S值虽然小于度中心性算法对应的值,但是远高于随机算法得到的值,并且〈L〉S大于度中心性算法对应的值。因而度折扣算法及改进算法平衡了种子节点自身的重要性和种子节点之间距离两个因素,可以更有效地扩大传播范围。尤为重要的是,虽然IDD1选择的种子节点的〈d〉S值以及〈L〉S值和度折扣算法对应的值都非常接近,但是该算法的传播范围更广、传播速度更快(如图2~图4)。因为IDD2算法充分考虑了冗余弱化机制,所以该算法得到的〈L〉S值比其他非随机算法得到的值都大。当然,基于IDD2算法选出的种子节点的〈d〉S值也一定程度地变小,但是远高于随机算法得到的〈d〉S值。IDD2算法在IC模型中的最优性能也说明,对于IC模型而言,种子节点间的分散程度是能否保证影响力最大化的一个尤为重要的因素。
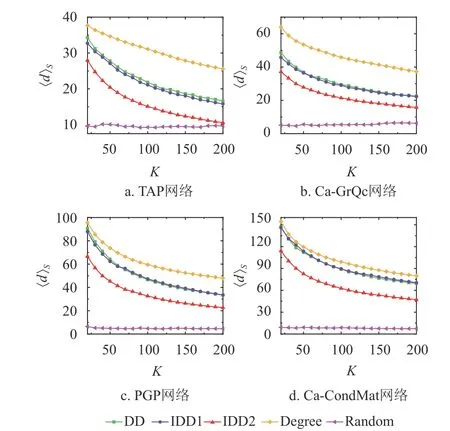
图5 种子节点间平均度随着种子数的变化情况

图6 种子节点间平均最短路径随着种子数的变化情况
为了更为直观地表明改进算法选取出种子节点的特点,本文对Word网络[31]进行可视化分析,图7中节点的大小与度成正相关。分别使用度中心性算法、IDD1算法和IDD2算法选取20个种子节点,传播率设为0.1。种子节点在网络中用实心黑点标记,通过可视化可以直观地看出,IDD1算法选出的种子节点仍包含了部分大度节点,IDD2算法选取的种子节点则更加均匀地分散在网络中,种子节点的度也相对减小。

图7 Word网络种子节点可视化图
另外也测试了这些算法在线性阈值模型(linear threshold model,LT)中的性能,IDD1算法效果仍优于度折扣算法,然而IDD2算法在LT模型中效果一般,这是由于当种子节点过于分散时,LT模型的激活条件难以满足,故不适用于LT模型。
3.2.2未知传播率
在度折扣算法中,作者假设节点真实传播率是已知的,因而利用真实传播率计算节点的期望影响力,但在实际情况下,鉴于问题的复杂性,很难知道真实传播率的大小。为了解决此问题,一个科学、折中的方法是用传播阈值近似代替真实传播率,这样做的合理性在于:传播率太小信息不能传播,而传播率太大时,任何一种方法都能使得信息大范围传播,此时再研究哪种方法能保证影响力最大没有太大意义。接下来的问题是:如果基于传播阈值计算式(3)~式(5),IDD1算法和IDD2算法是否仍然具有更优异的表现。
图8显示了传播阈值近似代替传播率时最终影响范围。将前3个网络的真实传播率设为0.1,第4个网络的真实传播率设为0.06,而期望影响力是用 βth代 替 β计算得到的,然后比较了不同算法对最终影响范围σ(S)的影响。从图8可以发现,对于IC模型而言,IDD1算法依然优于度折扣算法,IDD2算法在检查影响力最大化方面的性能更加突出。

图8 传播阈值近似代替传播率时最终影响范围
3.2.3敏感性分析
考虑IDD2算法中参数α的取值情况,本文进行了敏感性分析,其中TAP网络固定 β=0.1,K=20;Ca-GrQc网络和PGP网络固定 β=0.1,K=50,Ca-CondMat网络固定β=0.06,K=70。针对不同的网络,如果网络较为稠密,则节点共同邻居数较多;若网络较为稀疏,共同邻居数很少。此时若α太大,指标将趋于0,若α 太小,邻居的贡献差异性易被忽略,因此本文在[0,0.1]的范围内观察IDD2算法的性能。当α=0时,IDD2算法退化为IDD1算法,即为IDD1算法的最终影响范围。从图9可以看出 α取值在0.01~0.1时,IDD2算法效果均优于IDD1算法,并且α取值为0.02~0.1时,效果相对稳定,因此本文将实验参数统一为0.05。

图9 参数α 对IDD2算法的最终影响范围的影响
3.2.4运行时间
图10比较了不同算法选择50个种子的运行时间,TAP网络、Ca-GrQc网络和PGP网络传播率设为0.1,Ca-CondMat网络设为0.06。由图可知,IDD1算法和IDD2算法的运行时间略高于度折扣算法。考虑冗余弱化机制的IDD2算法运行时间最长,这是因为在考虑节点度折扣时需要考虑每个邻居节点的种子邻居数,故复杂度要高于原度折扣算法,但度折扣算法相较于贪婪算法仍然具有高效性。

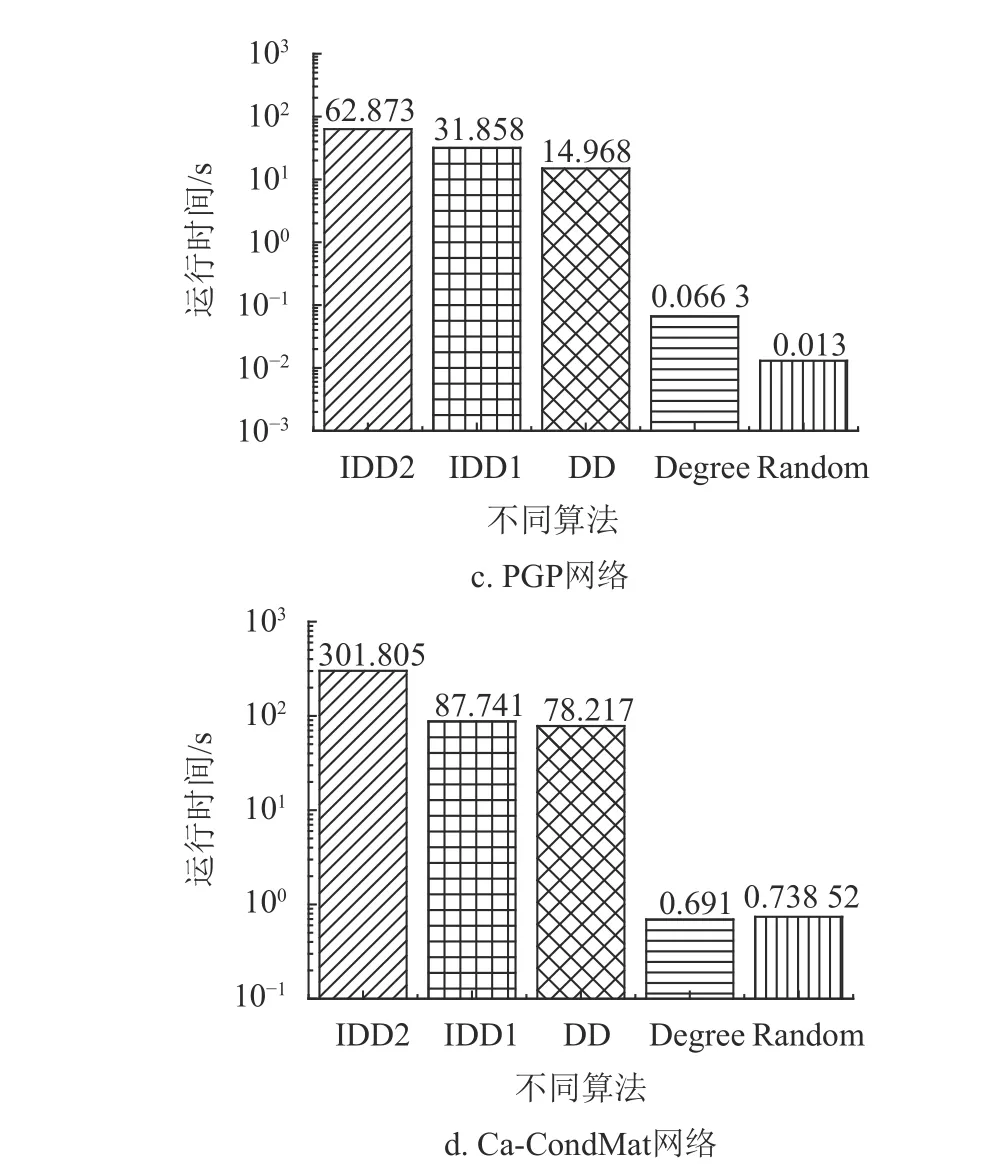
图10 不同算法选择种子节点的运行时间
4 结束语
研究社交网络影响力最大化问题具有重要的理论意义和应用价值,在众多检测算法中,由于度折扣算法具有快速、高效的性能,受到学者们的广泛关注。考虑到度折扣算法在计算节点期望影响力时没有区别对待邻居中未激活节点的差异性,本文对计算期望影响力的公式进行了修正,得到了一阶改进的度折扣(IDD1)算法。为了进一步保证选择的种子节点充分分散地分布在网络上,本文提出了二阶改进的度折扣(IDD2)算法。通过在4个真实网络上的实验结果表明,IDD1算法影响的最终传播范围和传播速度均优于度折扣算法,而IDD2算法在IC模型上扩大影响力范围的效果尤为突出。通过计算种子节点之间的平均度以及平均距离,阐述了为何本文提出的算法能更有效地扩大传播范围。此外,考虑到真实传播率难以获取,本文利用传播阈值代替真实传播率计算期望影响力,研究结果表明本文提出的算法依然有效。
猜你喜欢
当代陕西(2021年1期)2021-02-01
考试与评价·高二版(2020年3期)2020-09-10
华人时刊(2019年15期)2019-11-26
儿童时代·幸福宝宝(2019年9期)2019-10-28
NBA特刊(2018年14期)2018-08-13
莫愁·家教与成才(2017年7期)2017-07-11
人大建设(2017年11期)2017-04-20
中国卫生(2015年8期)2015-11-12
瞭望东方周刊(2015年12期)2015-04-14
人间(2015年21期)2015-03-11
