
基于三支决策的组织关联知识推送服务
2021-06-18 06:06张建华叶建文
系统管理学报 2021年3期
张建华,刘 柯,叶建文
(郑州大学 管理工程学院,郑州 450001)
在知识经济时代,知识的地位和作用有如资本之于工业经济、土地之于农业经济,已经上升为首要的生产要素。高效应用知识、实现其价值,成为广受关注的话题。知识的价值实现依托于知识的传播、应用、创新和服务,是组织进步和发展的重要驱动力。面对知识体量的快速增长,知识推送作为一项基础性知识服务方式,可以有效解决广大知识用户的“知识迷向”问题,能够促进组织内知识的传播、共享与应用,确保知识价值的有效实现;同时,高效的知识推送亦能对组织的知识创新形成有效支持,从而为组织自身增益。
推荐技术是知识推送服务的基础与核心。目前对推荐技术的研究主要包括4大类:
(1)协同过滤推荐算法基于“物以类聚,人以群分”的思想,利用用户-项目行为矩阵计算用户之间或项目之间的相似度实施知识推荐。它不考虑项目的具体内容以及用户的具体兴趣,是目前研究和应用最为广泛的推荐算法,在电子商务、社交媒体等领域的应用中均取得了良好的效果;但该类方法存在冷启动、评价稀疏等问题,且基于用户评分的相似度计算方法亦存在主观性过强的问题。
(2)基于内容的推荐算法主要利用项目相对客观的内容信息,将用户特征与项目特征匹配,从而为用户推荐相似项目,推荐结果易解释;但该类方法基于用户以前喜欢的项目范畴,在一定程度上受限于用户视野,不利于创新。
(3)基于数据挖掘的推荐主要表现为基于关联规则的推荐。它根据用户的偏好集产生关联规则,进而根据关联规则将新项目推荐给用户[1]。此方法通过挖掘并利用关联规则这一内隐知识产生用户意想不到的结果;但关联规则的发现耗时且有时难以理解,质量或难以保证。
(4)由于各类推荐算法兼具优缺点,在实践中,人们常采用混合推荐算法[2]。该方法将两种或两种以上的推荐技术相融合,以此来弥补各算法的不足,从而优化推荐结果。目前常用的融合方式有加权、变换、混合、特征组合、层叠、特征扩充以及元级别融合等。
王道平等[3]基于协同过滤算法,综合考虑用户兴趣和项目属性因素,利用内容相似度解决了用户-项目评分矩阵的数据稀疏性等问题。周明建等[4]提出基于属性相似度的知识推送算法,通过对用户所浏览知识的属性相似度进行分析得到用户的兴趣信息,然后将新知识与用户兴趣信息进行匹配,从而得到推荐结果。郭均鹏等[5]利用混合推荐策略,将基于内容的推荐与基于项目的协同过滤推荐技术相结合,从而克服冷启动问题及用户-项目评分矩阵稀疏性问题。然而,若只将基于内容的推荐算法与协同过滤算法相融合,因其只以知识相似性度量为基准对用户实施推荐,推荐结果只能反映知识之间的相似性,却未能兼顾知识间的关联度。相似度低但关联度高的知识有利于激发用户的创新思维,而过于相似的知识对用户而言因冗余而增加成本、耗费精力。由此,曲朝阳等[6]将知识关联度与相似度相结合,共同作用于推荐结果、提高推荐质量。
成本是组织运营需要考虑的重要因素。大部分推荐算法都将推荐决策划分为推荐和不推荐两种,非此即彼、缺乏包容性,增大了因错误分类而产生的成本。在现实生活中,人们认知和解决问题常常基于一种三元思维。例如,将对某种观点的态度划分为接受、中立和拒绝,将过程控制划分为事前、事中和事后,专家在论文评审过程中接收、拒稿或返修再审[7]。三支决策最早由YAO 提出[8]。作为符合人类认知规律的模型,已经应用于信息咨询、管理决策、医疗和工程等多个领域并取得了良好成效[9]。Zhang等[10]兼顾学习成本和误分类成本,把三支决策模型与随机森林整合,建立了一个新的推荐系统,实验证明应用三支决策产生的推荐成本低于传统的二分法。Zhang等[11]提出了一个基于回归的三支推荐模型,并寻找最优阈值来最小化推荐成本。叶晓庆等[12]考虑了推荐成本以及项目特征对用户评分的影响,将三支决策思想和粒计算思想引入,从而提高了推荐质量并降低了推荐成本。
有鉴于此,本文以基于知识属性的视图相似度衡量知识间的相似度,以用户偏好集为基础,采用Apriori算法挖掘并利用关联规则这一内隐知识衡量知识之间的关联度,将两者融合得到一种新的知识相关度模型,并据此预测评分。如此,不仅能缓解传统协同过滤算法的数据稀疏问题,也将知识关联度考虑在内,可更好地满足组织知识推送需求。而后,在推荐决策中引入三支决策,提出基于三支决策的组织关联知识推送算法,并用Movie Lens数据集检验了该算法的效果。
1 相关定义
1.1 知识视图相似度
针对知识多样性,根据其所属领域、可解决问题类型等赋予知识不同的属性,从而依据知识属性集进行知识建模,实现组织对知识的统一管理。
本文通过基于计算知识属性的视图相似度来表征知识间的相似度,为此构建如表1所示的知识-属性矩阵Kattr。

表1 知识属性矩阵
其中,aij表示知识i是否具有属性j,其取值如下所示:

基于知识属性文本特征和集合性,选用Jaccard相似系数表征两条知识之间的属性相似度,相应的计算公式为

基于每条知识所具有属性的不同将知识加以区分,并兼顾不同属性对知识区分度的作用差异,通过信息熵的大小为属性赋权,得到信息加权的Jaccard知识视图相似度[13]:
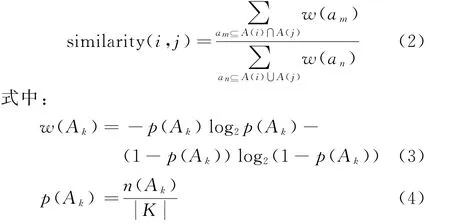
式(3)中:w(Ak)为属性Ak的信息熵;p(Ak)为属性Ak出现的概率,其计算公式如式(4)所示。其中:为知识的总数目;n(Ak)为属性Ak出现的次数。
1.2 知识关联度
通过知识视图相似度可以辨别相似的知识,但相似的知识对于组织成员的效用有限,因为不完全相似但存在关联的知识反而有利于拓展组织成员的思维,进而激发他们的创新行为,提高知识的利用价值。因此,基于组织成员的知识偏好集,本文基于经典的关联规则挖掘算法——Apriori的基本原理,采用改造后的算法挖掘两两知识之间的关联规则,并以关联规则的置信度表示知识之间关联度的大小。
算法步骤:①遍历所有用户知识偏好集,对每条知识进行计数得到候选项集C1,将支持度计数等于0的知识项剔除,得到频繁1项集;②再次扫描数据集,计算所有候选2项集的支持度计数,设置2项集支持度阈值c,将支持度计数小于阈值的候选集的置信度设置为0;③计算所有候选2项集的置信度conf,建立知识关联度矩阵,并将空缺值补为0;④由于关联规则知识i→知识j以及知识j→知识i的意义不同,其各自的置信度conf(i,j)和conf(j,i)亦不同,故知识i、j之间的关联度可融合计算如下所示:
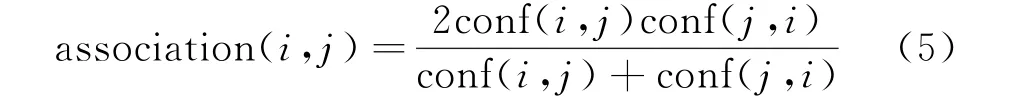
1.3 协同过滤算法
协同过滤算法以用户-项目评分矩阵为基础,自提出以来就被广泛应用并取得了良好效果。其按原理不同可划分为两类:基于用户的协同过滤算法和基于项目的协同过滤算法。其中,前者从计算用户相似度出发,根据与目标用户相似的近邻用户对项目的评分预测目标用户对某项目的评分;后者则以计算项目相似度为起点,根据与目标项目相似的、目标用户已评分的近邻项目预测目标用户对目标项目的评分[14]。知识推送系统的作用在于依据用户日常浏览的知识范畴为用户推送相关知识,故选取基于项目的协同过滤算法,依据组织成员的历史知识偏好为其推送相关知识。
1.4 三支决策
三支决策是对概率粗糙集的语义扩展,是粗糙集理论和决策理论的一种融合,为粗糙集理论在实际决策问题中的应用建立起一座桥梁[9]。绝大部分推荐算法都只有推荐和不推荐两种推荐决策。显然,这种二支决策模型(见表2)的决策划分非此即彼、缺乏包容性,增大了因错误分类而产生的成本。

表2 二支推荐模型
有鉴于此,基于对知识推送成本的考虑,将已有基于决策粗糙集的三支决策模型引入,以此建立本文的知识推送模型,如表3所示。该模型基于用户对知识的两种偏好,根据对应决策区域划分的“正域”“边界域”和“负域”分别定义了“推送”“延迟推送”和“不推送”3种知识推送决策。相较于二支推荐模型,本文的知识推送模型增加了在掌握信息不充分时应采取的延迟策略,以此来降低因错误分类进而采取错误决策而导致的推送成本。

表3 三支推送模型
在表2、3中,P(X|[x])表示任何一个实体在属于等价类[x]的条件下,属于类别X的条件概率。
2 基于三支决策的关联知识推送
基于三支决策的关联知识推送主要包括两个部分:①基于项目最近邻的协同过滤的关联知识评分预测。首先计算知识之间的相关度,然后采用传统的基于项目的协同过滤算法根据最近邻预测用户评分。②三支知识推送决策。以所得的预测评分为基础,根据基于决策粗糙集的三支决策模型实现三支知识推送。
2.1 基于协同过滤的关联知识评分预测
考虑知识特性,本文改变传统协同过滤推荐算法中依据用户评分来计算项目之间相似度的思路,而是首先通过知识所具有的属性计算知识之间的相似度,并采用关联规则挖掘算法测度知识之间关联度;然后,将两者按最优融合系数加以融合,建立新的知识相关度指标,用它来衡量知识之间的关系;最后,以对知识的平均打分为基础、以知识相关度为权重预测用户对未评分知识的评分。
(1)知识相关度计算。在分别计算知识间视图相似度和关联度后,需对两者进行融合得到新的指标——知识相关度。线性融合是融合的经典思路,其关键在于融合系数的确定。采用实验研究方法,确定使得推荐结果误差最小的融合系数,并通过下式计算得到两两知识之间的相关度:
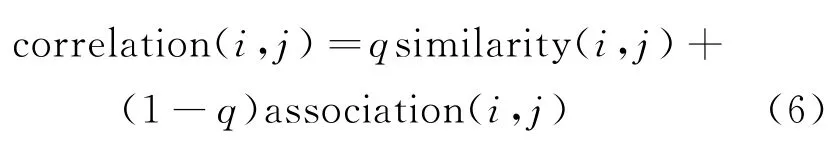
式中:q为融合系数;similarity(i,j)是由式(2)得到的信息熵加权的知识视图相似度,association(i,j)是由式(5)得到的知识关联度。知识相关度矩阵Kcorr如表4所示。

表4 知识相关度矩阵
(2)寻找最近邻。在寻找知识的最近邻时,基于固定数量的邻居原则,根据知识相关度矩阵Kcorr,选择与每条知识相关度最大的前k条知识作为其最近邻知识。
(3)预测评分。根据知识间相关度以及每条知识近的邻知识的评分记录,预测组织成员对未评分知识的评分,其计算公式为
2.2 三支知识推送模型
根据预测评分、知识推送成本,借助基于决策粗糙集的三支决策模型做出最后的知识推送决策。该模型包含3个部分:①基于用户对知识的“有帮助”和“无帮助”两种偏好,根据对应决策区域即用户未触及知识的“正域”“边界域”和“负域”划分,分别定义3种知识推送决策:推送(PP)、延迟推送(PB)和不推送(PN);②根据误分类成本和学习成本,建立一个如表5 所示的成本矩阵;③根据此成本矩阵,计算各决策区域的划分阈值α和β。

表5 知识推送成本矩阵
基于用户对知识的两种偏好,用H表示用户认为“有帮助”的知识的集合,用U表示用户认为“没有帮助”的知识的集合。如表5所示,不同决策行为对应不同的成本。如果一条知识被某用户认为有帮助(H),则λPH、λBH和λNH表示对此知识采取推送(PP)、延迟推送(PB)和不推送(PN)3种决策对应产生的成本;如果一条知识被某用户认为没有帮助(U),则λPU、λBU和λNU表示对此知识采取不同的推送决策所产生的成本。
至此,对知识库中的知识采取不同决策行为的期望成本为:

根据贝叶斯决策过程中的最小风险原则,可得如下区域划分规则:如果CP≤CB且CP≤CN,则将知识x划入正域;如果CB≤CP且CB≤CN,则将x划入边界域;如果CN≤CP且CN≤CB,则将x划入负域。
基于知识用户对知识的两种偏好划分,则有

在知识推送过程中,误分类成本一般比延迟推送所需的学习成本要高,而学习成本一般比正确推送的成本要高。将属于H的知识x划分到正域的损失小于或等于将x划分到边界域中的损失,并且这两种损失都严格小于将x划分到负域的损失;类似地,属于U的知识x同理。这符合三支决策的一个基本前提条件[8],即:

基于条件式(9)、(10),可将区域划分规则式(8)重新表达为:如果P(H|[x])≥α且P(H|[x])≥γ,则将知识x划入正域;如果P(H|[x])≤α且P(H|[x])≥β,则将知识x划入边界域;如果P(H|[x])≤β且P(H|[x])≤λ,则将知识x划入负域。
由式(8)~(10)及区域划分规则,可得α、β和γ的表达式为:

式中,γ为二支推送决策中的划分阈值。
同时,根据决策粗糙集,还需考虑另一条件:

至此可得0≤β<α≤1。前述区域划分规则可进一步表达为:如果P(H|[x])≥α,则将知识x划分入正域;如果β<P(H|[x])<α,则将知识x划入边界域;如果P(H|[x])≤β,则将知识x划入负域。
若要将用户未触及的知识划分决策区域,除了需要划分阈值外,还需知道用户认为某知识“有帮助”的概率pu,i。预测评分的高低反映了用户对知识评价的高低,用户对某知识的评分越高,表明此知识对用户有帮助的概率越大。将预测评分转化为用户认为某知识有帮助的概率,其计算公式为
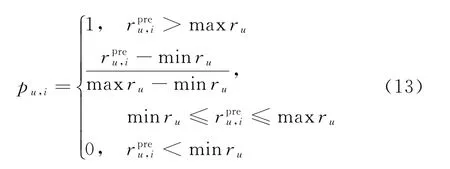
根据用户认为某知识“有帮助”的概率值pu,i以及决策区域划分阈值α和β,即可将知识划入正域、边界域或负域中,进而做出知识推送决策。
3 实验与分析
实验选用众所周知的Movielens数据集,并根据本文算法的适用场景选择Movielens-100k 数据集的前10 000条评分数据作为实验数据。这其中包含了93名用户对1 682部电影的评分信息,且每个用户至少对20部电影进行了评价。实验随机将数据按80%和20%的比例划分为训练集和测试集。实验将每部电影作为知识单位(结构体),将电影类别作为知识属性,以用户平均打分为界限,若评分大于或等于用户平均打分,则认为用户喜欢该电影;否则,用户不喜欢该电影。如此,每个用户喜欢的电影集合亦即用户认为“有帮助”的知识集合。
首先,通过实验确定计算知识相关度所需的融合系数,然后通过与传统推送模型的对比分析,测试本文推送模型的效果。实验对关联知识二支推送模型、关联知识三支推送模型、基于传统ICF 的二支推送模型和基于传统ICF 的三支推送模进行两两比较,对比它们的推送效果。推送效果评价指标包括平均推送成本、准确率、召回率和覆盖率。
3.1 推送效果评价指标
采用平均成本来衡量二支和三支模型的推送成本。根据成本矩阵(见表5),推送总成本和平均推送成本的计算方式如下所示:

式中:TC为推送总成本;NPH、NBH和NNH分别为将用户认为“有帮助”的知识推送、延迟推送和不推送给用户的数量,NPU、NBU和NNU分别为将用户认为“无帮助”的知识推送、延迟推送和不推送给用户的数量。基于现实情况及三支推送决策中成本约束(见式(10)、(12)),实验设定的成本矩阵如表6 所示。相对而言,本文将正确决策的成本视为零,即λPH=λNU=0。
知识推送的目的在于将合适的知识推送至用户,故推送的效果可用推送的准确度来衡量。准确率(Precision)和召回率(Recall)是信息检索和统计学分类领域常用的两个指标,同时也广泛应用于推荐领域[15]。它们将所得的预测评分转化到分类问题上,用分类准确度代替评分精确度,适用本文的实际应用场景,故采用准确率和召回率来衡量二支和三支模型推送的准确度,两者在本文中的计算方式如下所示:

式中,NPH、NPU和NNH的含义与推送总成本相同。准确率表征了推送结果被用户认为“有帮助”的水平,召回率表征了用户认为“有帮助”的知识被推送的能力,故准确率和召回率越高,推荐系统的推荐效果越好。
在推荐算法常用的测评指标中,覆盖率(Coverage)反映了算法对项目的平均推荐能力。本文采用覆盖率来衡量推送模型对知识的推荐率,其计算方式为

式中:R(u)为用户u的知识推送集;I为总的知识集;为相对应的个数。覆盖率表征了推送模型对知识的平均推送能力,其值越高,对冷门知识的推荐能力越高。
3.2 支持度阈值的确定
前已述及,知识关联度的计算受支持度阈值的影响。根据本文推送模型的应用场景及本实验所选数据集的特点(包含93名用户),设定当支持度阈值c=3时,即至少有3名用户共同认为某两条知识“有帮助”时,将置信度的大小作为知识之间的关联度。
3.3 融合系数的确定
因为用户的偏好集并不局限于特定的属性范畴,所以由此得到的知识关联度与知识之间基于属性的视图相似度不同。根据实验所得数据,有些项目之间相似度很低但关联度很高,同样亦存在有些项目之间相似度很高但关联度很低的情形,故采用md来说明。其为每个项目的相似度与关联度之间差异的均平方,计算方式如下所示:

经计算得md=0.382 3,这体现了项目之间的关联度与项目之间的相似度的差异性。
在进行算法效果的对比实验之前,还需确定计算知识相关度时所需的融合系数q的大小,即知识相关度中知识属性相似度和知识关联度各自所占的比重。采用实验的方法,通过计算并比较不同融合系数下的预测结果误差,选择使得误差最小的融合系数作为最终的融合系数。具体地,实验在支持度阈值c=3,最近邻数目k=10的条件下,在0.1~1范围内以0.1为跨度设置q,并以预测评分的平均绝对误差MAE来衡量预测结果误差,计算方法为


图1 不同融合系数q 下的MAE
3.4 实验结果与分析
为比较不同推送模型的推送成本、准确率、召回率和覆盖率,实验根据不同模型评分预测方式、决策方式及对应决策成本的不同,分别计算了不同最近邻数目下基于传统ICF的二支、三支推送模型和关联知识二支、三支推送模型的平均推送成本、准确率、召回率和覆盖率,实验结果见图2~5。
(1)推送成本。由图2可知,在相同的评分预测方式下,三支推送模型在不同最近邻数目下的平均推送成本均低于二支推送模型;而在相同的决策方式下,关联知识推送模型的平均推送成本均低于基于传统ICF的推送模型。总体而言,三支关联知识推送模型的平均推送成本最低,较传统ICF 二支推送模型平均降低3.25 单位成本,较传统ICF 二支推送模型平均降低23.98%。

图2 不同最近邻数目下的平均推送成本
(2)准确率。由图3可知,在相同的评分预测方式下,三支推送模型在不同最近邻数目下的准确率均高于二支推送模型。三支决策方式下,在最近邻数目为2~18,关联知识推送模型的准确率均高于基于传统ICF的推送模型;当最近邻数目大于18后,两者趋于相同。二支决策方式下,情况类似。总体而言,三支关联知识推送模型的准确率更高,较传统ICF二支推送模型平均提升7.15%。

图3 不同最近邻数目下的准确率
(3)召回率。由图4可知,在相同的评分预测方式下,三支推送模型在不同最近邻数目下的召回率均高于二支推送模型;而在相同的决策方式下,关联知识推送模型的召回率均高于基于传统ICF 的推送模型。总体而言,三支关联知识推送模型的召回率更高,较传统ICF 二支推送模型平均提升20.2%。
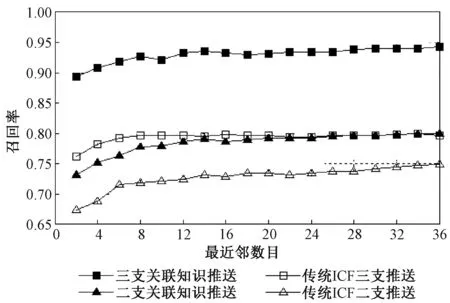
图4 不同最近邻数目下的召回率
(4)覆盖率。由图5可知,在相同的评分预测方式下,三支推送模型在不同最近邻数目下的覆盖率均低于二支推送模型;而在相同的决策方式下,关联知识推送模型的覆盖率均高于基于传统ICF 的推送模型。本文的三支关联知识推送模型的覆盖率较传统ICF 二支推送模型平均降低18.09%,但较传统ICF三支推送模型平均提升7.99%。
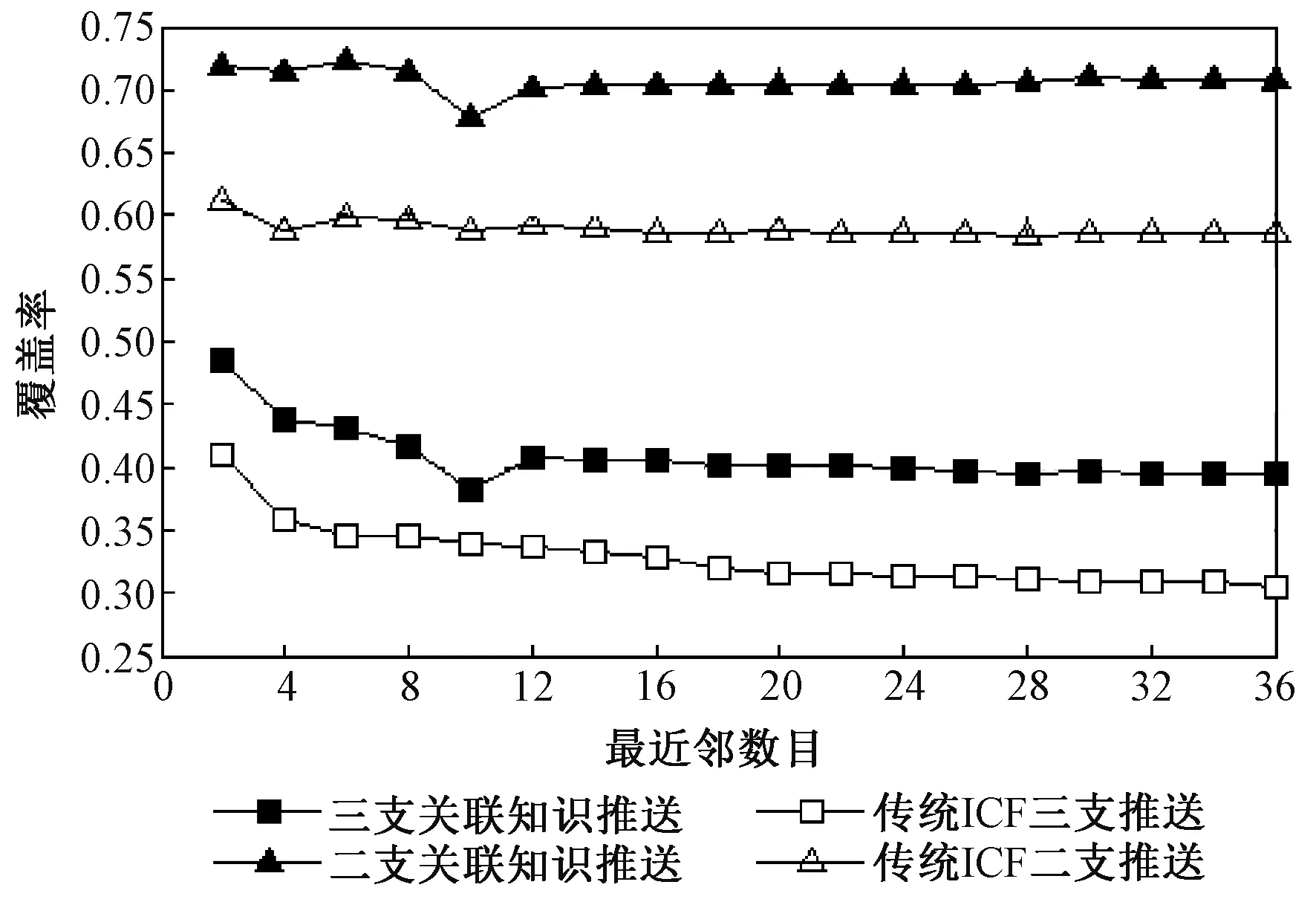
图5 不同最近邻数目下的覆盖率
综合上述实验结果,可得出如下结论:①三支关联知识推送模型在平均推送成本、准确率和召回率的平均表现均优于其他3个推送模型。②本文提出的三支关联知识推送模型的覆盖率虽低于二支推送模型,但从侧面反映了三支关联知识推送模型牺牲了一定的覆盖率、缩小了推送知识的范围,从而提升了推送的准确率、降低了推送成本。
4 结语
考虑到知识关联度的重要性以及传统推送决策的二分性质,本文提出了一种基于三支决策的关联知识推送算法。为挖掘并利用知识之间的潜在联系,将知识关联度融入评分预测中,构建了融合知识相似度和知识关联度的知识相关度模型。同时,为了减少传统二分法中因错误分类而产生的推送成本,在最终的推荐决策中引入了三支决策思想,实现了三支推送,并通过实验验证了三支推送模型的推送成本、准确率和召回率均优于二支推送模型,但覆盖率表现不如二支推送模型。在本文构建的知识推送系统中,尚未考虑用户评分偏好的问题,项目冷启动问题依然存在,欠缺对延迟推送决策项目的后续处理,课题组将在后续研究中继续优化与补充。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
纺织科学研究(2021年9期)2021-10-14
当代陕西(2019年15期)2019-09-02
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
学苑创造·A版(2018年11期)2018-02-01
水利科技与经济(2017年12期)2017-04-22
读者(2017年5期)2017-02-15
电源技术(2015年11期)2015-08-22
河南科技(2014年16期)2014-02-27
郑州大学学报(理学版)(2013年2期)2013-03-11
