
基于Python的数据挖掘技术在创业担保贷款中的应用
2021-06-18 03:38高键季禹伶
电子测试 2021年8期
高键, 季禹伶
(1.内蒙古科技大学信息工程学院,内蒙古包头,014010;2.河南大学经济学院,河南开封,475000)
0 引言
创业担保贷款是由国家人社部、财政部、人民银行出台的一项普惠性的贷款政策,主要面向城镇失业人员、高校毕业生、返乡创业的农牧民等在金融信贷方面的弱势群体,为其提供5到20万的信贷支持,并给予一定数额的贴息补助。2019年全国创业担保贷款约发放1000亿元,为创业者补贴利息约67.5亿元。
随着大数据技术的蓬勃发展,挖掘庞大数据体量背后的潜在价值成为大数据领域研究的热点。通过数据挖掘技术,可以实现预测研究主体的趋势和行为、变量关联分析、目标聚类分析、偏差检测等功能。本文以包头市为例,将数据挖掘技术应用到创业担保贷款这项惠民政策中,通过构建创业者创业能力评估模型,可以根据创业者的实际情况,合理测算出创业者的实际用款需求,实现国家财政资金合理分配的目的。
1 设计过程
本文基于Python语言实现,通过matplotlib实现对数据的可视化,pandas实现对样本数据的分析和处理,sklearn机器学习库实现数据从预处理到模型训练的各个步骤。具体的设计流程图如图1所示。
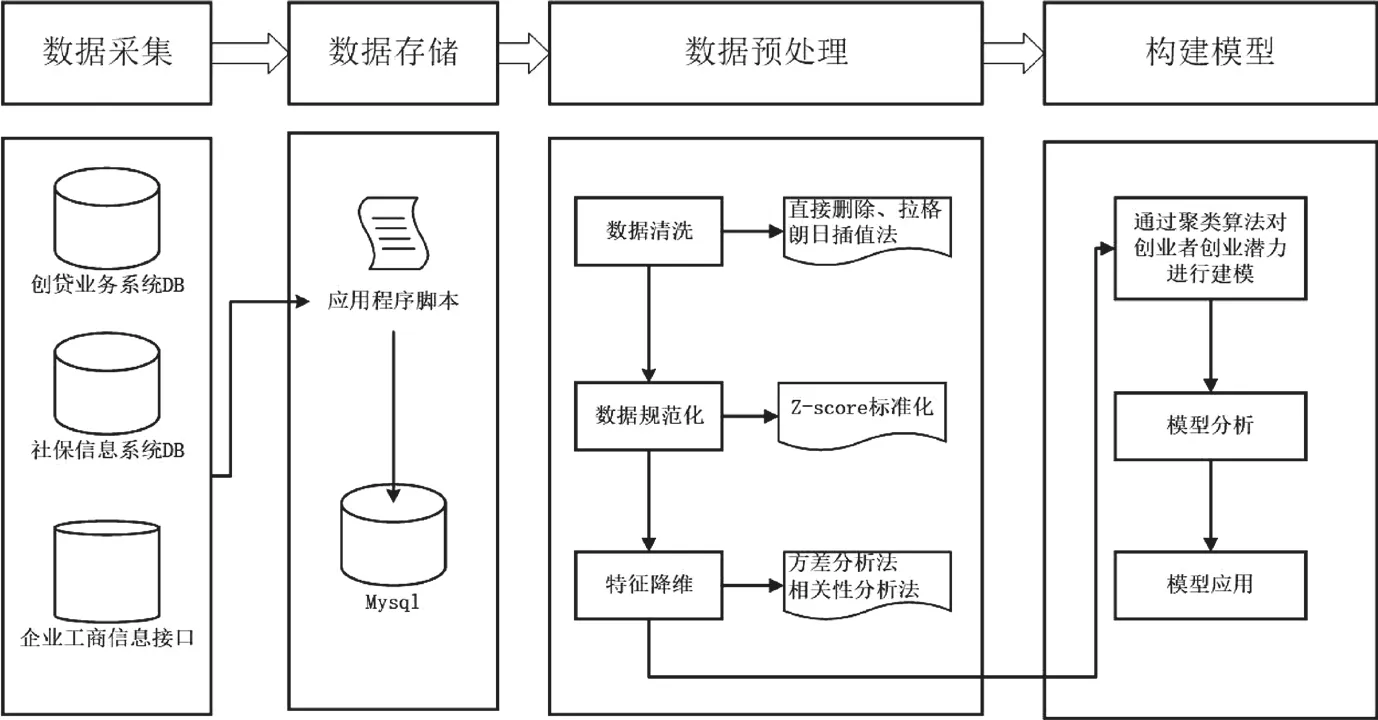
图1 基于Python的数据挖掘技术在创业担保贷款中的应用设计流程图
■1.1 数据采集
数据采集是进行数据分析的第一步,采集的数据主要分为历史数据与实时数据。基础的历史样本数据集主要来自于业务系统,包括创业担保贷款本身的信息管理系统、社会保险信息管理系统以及工商部门的企业信用公示系统。创业担保贷款本身的信息管理系统提供了创业者申请创业担保贷款的历史数据,包含申贷次数,申贷金额、经营情况等信息。社会保险信息管理系统获取了创业者的社会保险信息,包含就业失业状态,就业困难人员认定以及零就业家庭认定等信息。工商部门的企业信用公示系统主要获取创业者的企业信息,包含企业的营业执照、经营项目等信息。因创业担保贷款的用款周期为两年,创业者在按时还款后,仍然可以继续申请,为避免这些再次申请的数据对模型构建产生影响,选取的样本数据为近两年的贷款数据。实时样本数据由各个部门的工作人员实时向业务系统导入。
■1.2 数据存储
数据存储的目的在于将采集到的样本数据持久化,以便后续的分析与处理。因样本数据取自不同的业务系统,所以通过Python的requests库分别向各个业务系统发送http请求获取需要的数据,并对获取到的数据进行整合,最后存储到Mysql数据库中。
■1.3 数据预处理
数据预处理是指对样本数据进一步加工,得到一组仍包含原始信息且适合进行建模的数据集。包含数据清洗、数据规范化与特征降维等步骤。数据清洗是对采集而来并存储到数据库中的数据进行校验与纠正的过程,包括对缺失值、异常值、重复值等数据的处理。采集的数据主要来自业务系统,在业务系统中,已对数据的输入进行了校验,因此不存在异常值与重复值,所以主要是对缺失值进行处理。
对缺失值的处理用到了删除存在缺失值的记录以及插补的方法。例如在对申请创业担保贷款的人员身份进行可视化分析时,通过pandas读取样本数据集后,调用groupby函数对人员身份信息进行分组统计,结果如表1所示。
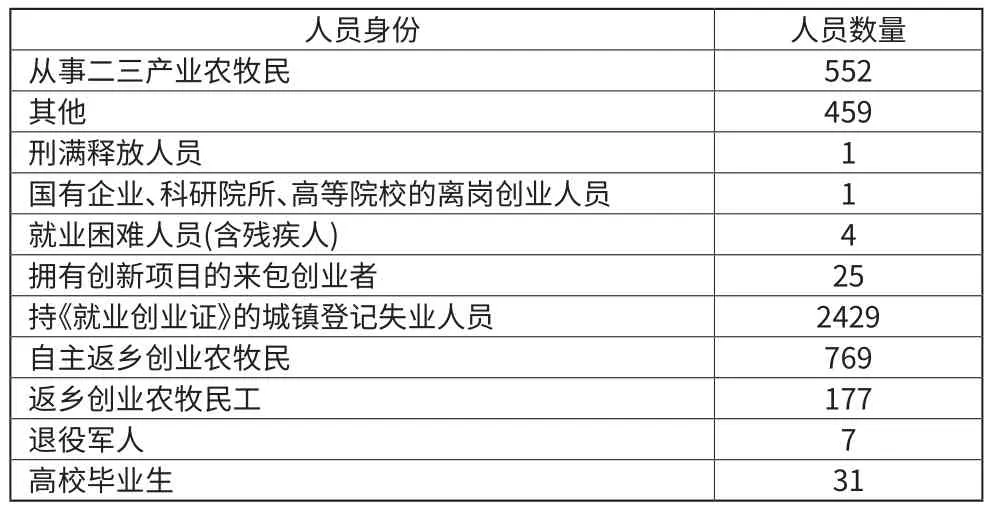
表1 不同身份人员申请创业担保贷款数量统计表
其中,“其他”类人员属于缺失值,并且占比相对较高,将会对其他数据的建模造成较大扰动,所以该类缺失值采取删除记录的处理方式。在对创业者创业潜力分析时,企业聘用的员工数量是分析创业潜力的重要指标,由人为因素导致的某些企业该项数据特征的缺失,采用插值法对缺失的数据进行填充。在具体的操作中,对贷款次数记录小于2的记录进行删除,贷款次数记录不小于2的记录可通过查询聘用员工数量的历史数据然后利用拉格朗日插值公式计算本次申请贷款时缺失的聘用员工数量近似值。
■1.4 构建模型
得到了可以建模的数据后,可以根据挖掘目标与数据形式建立分类与预测、关联规则、聚类分析等模型。基于Python语言的sklearn机器学习工具包,涵盖了所有机器学习算法,并且提供了简单高效的数据挖掘和数据分析工具。本文利用sklearn对建模过程中的参数进行了调试和优化,最后建立了创业者创业能力的聚类模型。
2 系统设计与应用
■2.1 挖掘潜在的申请群体
创业担保贷款申请的前提条件一般要求创业者持有工商营业执照,通过对包头市各个旗县区申请创业担保贷款人数与整理的工商户数据进行贡献度分析,并利用matplotlib将分析结果数据可视化,得出的结论如图2所示。
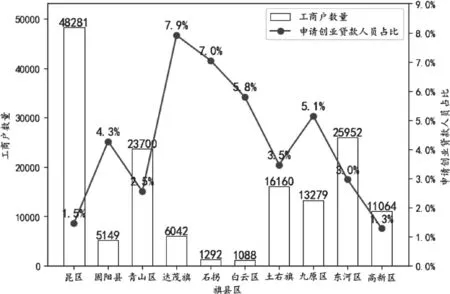
图2 包头市各旗县区工商户数量与已申请创业担保贷款人员占比情况
从图2中可以看到,距离市中心较远的“外五区”申请创业担保贷款的人员占当地工商户数量的比重明显比繁华的“市五区”较高,一般是因为“外五区”地大人稀,人口密度低但聚集较为集中,所以宣传效果较好,而“市五区”人口密度高,人口聚集地较多且不集中,因此导致政策覆盖面不够广泛。所以主管部门可以进一步加大在“市五区”内的宣传力度,扩大政策覆盖的广度与深度。
■2.2 创业者创业能力分析
在创业担保贷款的实际工作中,创业者的实际用款额度由审批单位根据创业者的经营状态认定,这种认定往往是带有经验性的主观认定,存在一定的弊端。通过对创业者经营情况的一些具体数据进行量化,构建创业者创业能力的聚类模型,可以将创业者按创业能力分类,进而为其匹配相应的贷款额度。
从Mysql数据库中获取到关于创业者的基本信息,导入pandas进行分析,取前5行数据,创业者数据的一些特征及数据如表2所示。

表2 创业者信息前5行数据预览
不同特征的数据之间差距较大且单位不一致,需要对数据进行规范化处理,消除量纲间的差距。通过对一些主要特征的数据绘制正态分布函数图,可以发现这些特征近似符合正态分布,因此采用z-score标准化对数据进行去量纲化操作。之后对数据进行特征降维,去除例如姓名、学历等一些无关的特征,通过方差分析法,发现贷款次数的方差较小,不足以区分每个样本在该特征上的不同,因此去除该特征。最后确定年龄、员工人数、创业年限、年利润、企业占地面积5个特征的数据进行模型训练。
采用K-Means算法对创业者的特征数据进行聚类分析,通过对不同簇数k下的聚类结果进行对比,当k取5时,聚类效果较好。因此设定n_clusters的值为5对数据进行聚类。通过绘制雷达图对聚类结果进行分析,如图3所示。
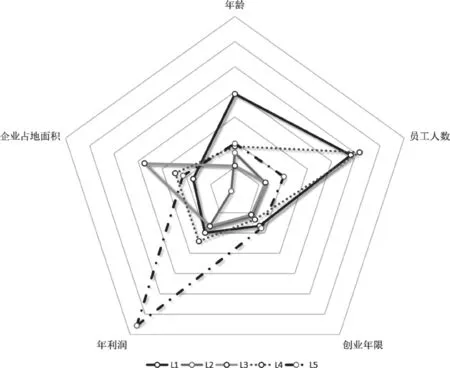
图3 基于聚类结果的创业者创业能力雷达图
从图3中可以看到,不同群体在各个特征之间的表现存在较大的差异,例如L5群体在年利润特征上表现突出,通过结合业务情景,该类创业者往往能创造较高的经济价值,可以认定为具有极强创业能力的创业者,可以继续给予较高额度的创业担保贷款支持。L1群体虽然在年利润特征上表现不足,但在员工人数特征上表现突出,表明该类创业者当前给社会带来较多的就业岗位,在原有贷款额度的基础上,可以给予重点扶持。
3 结束语
目前大多数的政府机构基于业务流程的控制开发了数据信息管理系统,但挖掘数据背后的潜藏价值,使其更好的应用于管理与服务中,仍是需要解决的问题。本文在已有业务数据的基础上,利用数据挖掘技术,对创业担保贷款的业务数据进行了分析与挖掘,构建了创业者创业能力分析模型,实现了对创业者创业能力的准确评估,为政策决策提供了有效的数据支撑。
猜你喜欢
今日农业(2021年13期)2021-08-14
大众投资指南(2021年35期)2021-02-16
铁道通信信号(2019年6期)2019-10-08
中国商界(2017年4期)2017-05-17
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
瞭望东方周刊(2016年40期)2016-11-02
信息通信技术(2015年6期)2015-12-26
电子设计工程(2015年6期)2015-02-27
创业家(2015年1期)2015-02-27
