
基于XLNet的物联网领域命名实体识别
2021-06-18 06:47葛海波车虹葵赵其实
西安邮电大学学报 2021年2期
葛海波,车虹葵,赵其实,安 康
(西安邮电大学 电子工程学院,陕西 西安 710121)
命名实体识别(Named Entity Recognition,NER)是自然语言处理中一个重要领域[1],旨在检测给定文本中的实体,并将其分类到预定义的类别中。NER生成的结果是问答系统、机器翻译和对话系统等许多下游任务的关键。
近年来,物联网领域发展迅速,其设备外延从传统的感知器、执行器向更多元化发展。为解决物联网实体多样化带来实体信息形式多样化和对实体信息的理解能力不足的问题,研究者们将语义网[2]中的智能化特征引入到物联网中。由此,物联网由传统的物联网(Internet of Things,IoT)向基于语义技术的万维物联网(Web of Things,WoT)迈进,WoT技术的核心是构建一个高可用实体库。目前,针对物联网领域暂无已经做好标注的语料,且无特定的物联网领域命名实体模型。对于物联网领域的命名实体识别研究的难点主要体现在物联网实体种类多样化和实体命名不规范等方面。在研究过程中需要根据物联网实体特征构建模型,把握好实体边界的划分。
如何自动化构建物联网本体库是WoT发展的核心需求,而构建物联网本体库的前提是能够在非机构化的语料中识别出物联网实体,针对上述问题,研究自然语言处理中的NER技术,将NER应用到物联网领域中,提出基于XLNet的物联网领域NER模型,以期在物联网数据集中取得较好效果。
1 相关工作
1.1 NER技术
NER的主要技术方法包括基于规则的方法、基于机器学习的方法和基于深度学习的方法[3]。基于规则的方法依赖领域专家制定规则模版,其识别效果对规则的依赖性高,且不同场景下的实体识别规则不同,可扩展性弱。
基于机器学习的方法主要是对于特征的学习,并将特征添加到特征向量中,主要方法有隐马尔可夫模型 (Hidden Markov Model ,HMM )[4]、支持向量机 (Support Vector Machine ,SVM )[5]和决策树[6]等。该类方法对特征的选取要求较高,比较依赖语料的质量。
随着深度学习的发展,利用深度神经网络模型完成NER别任务成为一种趋势。Hammerton[7]首次使用长短期记忆模型(Long Short Term Memory,LSTM)进行NER任务。以LSTM为基础,后续产生较好的LSTM-CRF命名实体识别框架。Tomas等[8]提出Word2Vec模型,对文本进行了低维稠密的向量化表示,但是Word2Vec不能解决多义词的向量映射问题。Peter等[9]提出词嵌入模型(Embeddings from Language Models,ELMO)有效解决了一词多义问题。Alec等[10]针对中文电子病例命名实体识别,提出基于Transformer的NER模型,F1值高达95.02%。Devlin[11]等提出了BERT(Bidirectional Encoder Representation form Transformers)预训练模型,杨飘等[12]将BERT模型应用在命名实体模型,提高了中文命名实体识别效果。BERT模型基于Transformer模型并结合遮罩(Mask)语言模型,使得模型考虑到文本的上下文信息,Mask语言模型在预训练和微调中阶段的不对称性在具体任务时会影响精确度。Yang等[13]提出广义自回归语言模型(XLNet),该模型引入排列语言模型思想,在预训练阶段应用Transformer-XL[14]相对位置编码,能够考虑序列历史信息,使得该模型有强大的表义能力,基于XLNet优秀的语义表征能力,并考虑模型在实体识别中标签依赖问题,基于XLNet在上层搭建模型解决物联网领域命名实体识别问题。
1.2 物联网实体命名方法
许多组织及个人针对物联网不同应用场景下的语义需求,提出不同概念的系统本体,欧盟首次将语义技术引入物联网[15]。Sheth[16]提出使用设备自描述信息中的时空信息以及传感观测信息对感知数据进行标注,该方法包含的语义属性较少,缺少与通用知识库数据的对齐。物联网行业的快速发展,其外延在不断扩大和发展,感知器、执行器、各种智能设备和微电子机械被包含其中,进一步加剧物联网系统的泛在性和动态性特征。为了应对物联网更智能化的需求,需要一种更为高级和抽象的数据模型表示物理网领域设备和数据服务。
为了对物联网内数据及服务进行语义化标注,在传统物联网架构增加了资源抽象层,由物理设备层、数据层、资源抽象层和应用服务层等4层组成,其整体架构如图1所示。
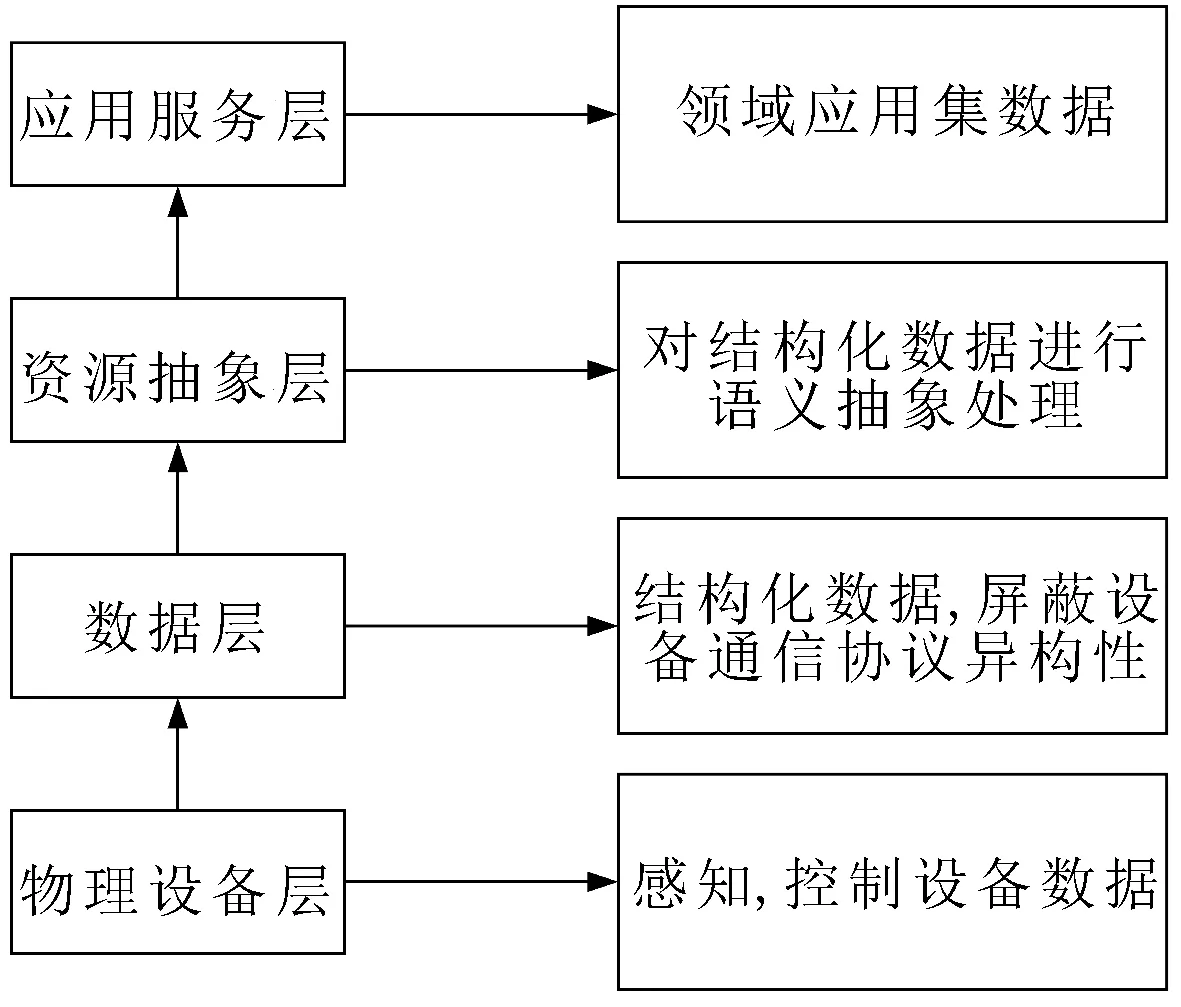
图1 物联网架构模型
物理设备层包括物联网系统中所有完成物理环境感知和控制任务,数据层是对物理设备层的软硬件进行分类抽象,资源抽象层是对物联网应用系统内的数据、服务进行语义化标注,应用服务层为开发者所搭建的服务应用。为了正确表示物联网领域实体,需要涵盖几个重要概念,如表1所示。

表1 物联网领域实体模型标签
参考自然语言处理通用实体划分,根据物联网领域特点加入领域内主要概念类型,并去除领域关联较少的实体,将物联网实体分为人物、地名、组织机构名、时间、传感器、执行器、应用名称、电子器件名称、数据流名称和其他实体。
1.3 数据集介绍
1.3.1 数据预处理
语料数据来自Wiki百科中文数据集以及爬取物联网领域相关文本。通过爬取获得的语料数据,存在大量非文本标签影响文本标注。通过预定义的清理规则,删除非法格式的文本数据,获取规范的物联网语料库数据。
1.3.2 数据标注
实体标注使用BIO标注方式,其中,B表示实体开始,I表示实体结尾或者中间部分,O表示其他实体或非实体。根据物联网实体命名分类,实体标签如表2所示。
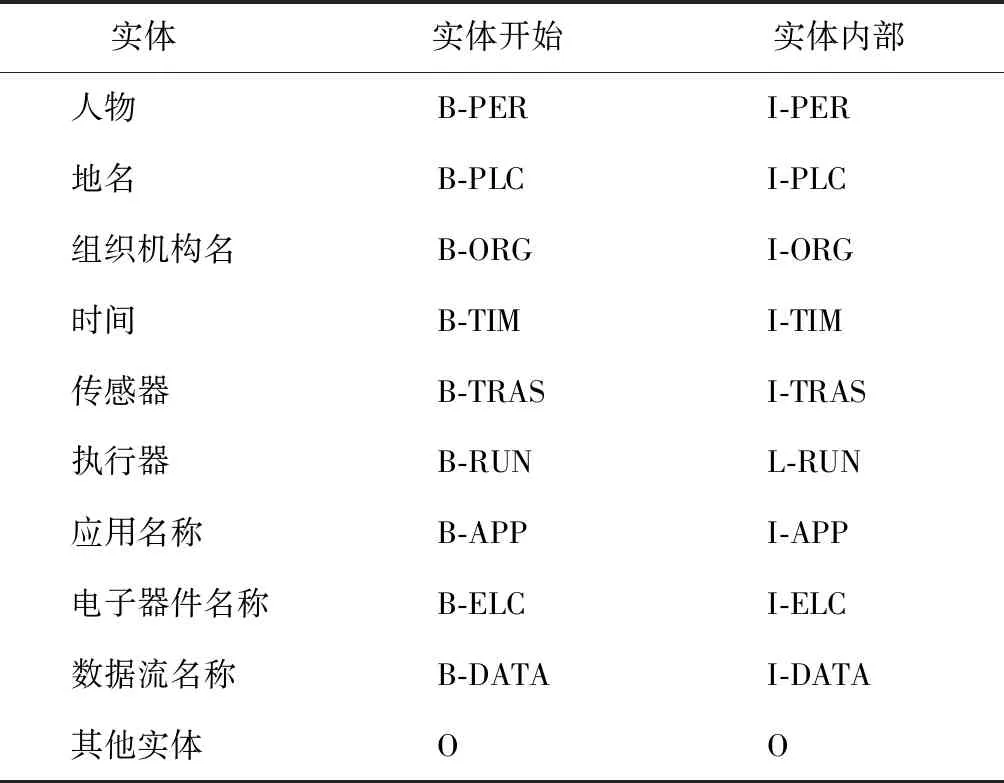
表2 物联网领域实体标签
2 基于XLNet的命名实体识别模型
基于XLNet强大的语义表征能力,提出了基于XLNet命名实体识别模型,该模型由XLNet层、Bi-LSTM层、Attention层和CRF层等4个部分组成,结构如图2所示。该模型通过XLNet模型提取字向量特征,将字向量拼接后作为Bi-LSTM层输入,经过Bi-LSTM层对语义进一步编码获取隐藏层输出并输入Attention层,CRF层专注于上下文注释信息,最终输出概率最大序列标签。该模型使用XLNet可以获得更佳的词向量表示,再经过“Bi-LSTM+Attention”层利用字符上下文信息,最后通过CRF层降低非法标注出现的概率。

图2 “XLNet+Bi-LSTM+Attention+CRF”模型结构
2.1 XLNet层
无监督学习模型分为自回归(Autoregressive,AR)语言模型和自编码(Autoencoding,AE)语言模型。与传统AR语言模型不同的是,以BERT为代表的AE语言模型实现了双向预测。


图3 XLNet模型Mask机制
给定序列长度为T,排序方式总数m=T!,模型可以通过m种排列方式学习到各种上下文,在实际应用中,XLNet随机采样m中的部分排列,其全排列模型的公式为
(1)
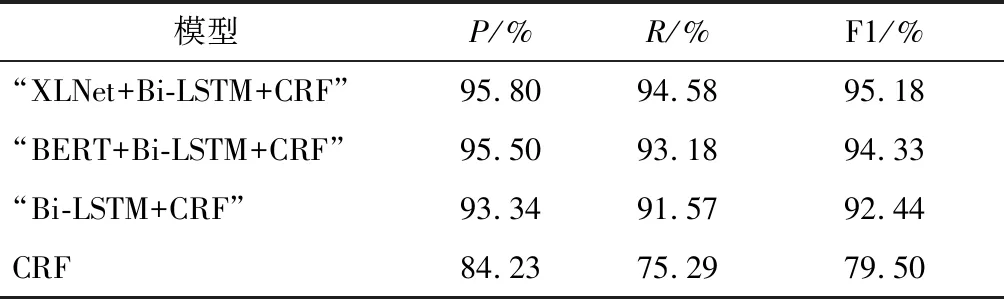
其中:E表示序列集合;z~ZT为所有可能的文本排列方式;xz,t表示当前词;Xz XLNet的核心为Transformer-XL,在Transformer结构基础上引入相对位置编码思想和循环机制。Transformer在训练中规定输入序列是定长序列,长序列在训练中分割后模型利用不到片段之间的联系,会造成信息缺失问题。Transformer-XL在片段之间插入隐状态信息,在当前段的预测通过隐状态信息可以利用前一段的信息,模型可以学习更为长远的语义信息。两个片段之间循环机制的信息传递方式如图4所示,灰线表示记忆信息,在Sgment2段训练中可以利用Segment1段的Cache信息,XLNet通过该机制实现历史信息的传递。 图4 XLNet循环机制 Transformer通过正弦函数的形式将绝对位置编码成一个向量,上层可以通过该向量学习两个词的相对位置的关系,计算公式为 hr+1=f(hr,Dsr+1+U1:L) (2) hr=f(hr-1,Dsr+U1:L) (3) 其中:hr表示r时刻向量编码;Dsr表示当前片段文本向量位置编码;U1:L表示位置编码,不同片段中U1:L一样,模型无法通过向量准确判断是哪个片段的具体位置。绝对位置编码对于每个片段的相同位置编码都是相同的,而Transformer-XL可以利用不同片段的历史信息,考虑到片段不同而位置编码相同的词对于当前片段的信息贡献度不同,因此,Transformer-XL使用相对位置编码思想,其在计算Attention时根据当前位置和需要利用到的位置计算相对距离。 XLNet以Transformer-XL框架为核心,通过引入循环机制和相对位置编码,充分考虑双向语义信息和挖掘较为长远的历史信息,可以获得更为准确的词向量表示。 LSTM是一种特殊的循环神经网络(Recurrent Neural Network,RNN),其单元结构如图5所示。传统循环神经网络在实际应用存在梯度消失和梯度爆炸的问题,其记忆长度有限。LSTM通过控制门选择“记忆”当前信息和“遗忘”历史信息,解决了长依赖问题,其内部包含输入门、输出门、遗忘门和记忆单元等4个部分。 图5 LSTM单元结构 LSTM单元具体实现的方程组为 (4) 其中:it为输入门;ft为遗忘门;ot为输出门;ct和ht指t时刻的候选记忆单元、新记忆单元和隐藏状态;ct-1和ht-1指模型t-1时刻的记忆单元和隐藏状态;σ是Sigmoid的函数;W为权重矩阵;b表示偏置。 实验采取双向LSTM实现对上下文信息的共同编码。Bi-LSTM层的输入为从ALNet层得到的词向量,该层由多个Bi-LSTM单元组成,并分别输出各时刻的隐状态。 考虑实体在文本中多次出现且表述方式不同,通过Attention机制计算实体不同时刻的特征向量权重,关注实体的重要特征信息,减少实体标注不一致问题。Attention层实现的方程组为 (5) 式中:s为当前时间字符得分;v表示当前状态;A表示当前字符权重;M表示得分的总数;g表示含有各字符信息的特征向量。通过Attention机制增强语料中上下文之间实体联系,得到更准确的实体信息。 在标记序列中,标签之间存在着依赖关系,该依赖性可以看作约束条件。如实体标记的第一个字应该为B,不能为I;一组实体序列开始与结尾标记类型应该相同。CRF可以关注标签之间的相邻关系得到最优标签序列,提高实体识别精度。 给定输入n维序列x=(x1,x2,x3,…,xn)和对应标签序列y=(y1,y2,y3,…,yn),定义评价方法的表达式为 (6) 其中:Vyi-1,yi表示标签转移分数;Qi,yi表示该字符被定义为第yi的概率。CRF的训练使用最大条件似然估计,似然函数表达式为 (7) 其中,概率Q的表达式为 (8) 在构建的物联网领域数据集上验证模型的识别性能。该数据集约57 780条句子,将该数据集按比例8∶1∶1分为训练集、验证集和测试集,各类实体统计如表3所示。 表3 标记实体类型统计 3.2.1 环境配置 实验运行环境如表4所示。 表4 实验环境 3.2.2 参数设置 实验中模型参数配置如表5所示。 表5 参数配置 对于命名实体识别的评价标准为精确率P、召回率R和模型评价标准F1值,其定义分别为 (9) 其中:TP表示模型所正确识别的实体总数;FP表示模型识别错误的实体总数;FN表示模型未能识别出的实体数。 为了验证模型的效果,实验选取机器学习中的CRF模型、基于深度学习中的“Bi-LSTM+CRF”模型和“BERT+Bi-LSTM+CRF”作对比,与所搭建“XLNet+Bi-LSTM+Attention+CRF”模型对同一数据集进行训练和验证,对比结果如表6所示。 表6 实验结果 由表6可以看出,CRF模型评价结果最低。Bi-LSTM可以融合输入序列的上下文语义信息,有着更强的语言表征能力,因此,“Bi-LSTM+CRF”模型F1值比CRF模型高12.94% ,提高了命名实体识别的F1值。Word2Vec只是在句子的表面对上下文信息进行提取表示,没有融入更多的内部特征,而BERT可以利用到上下文信息,能够更好地挖掘语义信息,因此,“BERT+Bi-LSTM+CRF”比Bi-LSTM模型F1值高出1.98%。基于XLNet的“XLNet+Bi-LSTM+Attention+CRF”模型,通过XLNet训练得到具有更好的表征能力字向量,识别效果最好,优于其他模型。 “XLNet+Bi-LSTM+Attention+CRF”有着更好的实体识别效果,该模型对于物联网各个实体的识别效果如表7所示。 表7 实体评价结果 表7中,时间、组织机构、传感器、数据流和电子器件这几类实体规律性,如“组织机构”类实体一般格式为“××地××组织”,命名方式规范。因此,这几类实体识别效果较好。“应用名称”类命名规律性较差,且该类数据集较少,训练出的模型对于该类的识别效果较差,导致F1值较低。 基于物联网本体的语义特征,归纳出物联网核心语义概念,提出新型命名模型,该模型涵盖物联网领域中物理设备层、数据层、资源抽象层和应用服务层,将其具体化为感知单元、计算单元、执行单元、消息单元、服务单元、位置单元和观测单元,基于该命名规范特点搭建4个物联网领域本体命名实体识别模型。通过实验分析对比,可以得出“XLNet+Bi-LSTM+Attention+CRF”模型的效果最好,为以后该模型的下游任务应用的研究奠定了基础。对于后续研究,主要考虑基于知识蒸馏对于原有模型进行压缩,使得模型满足物联网应用场景轻量化的需求。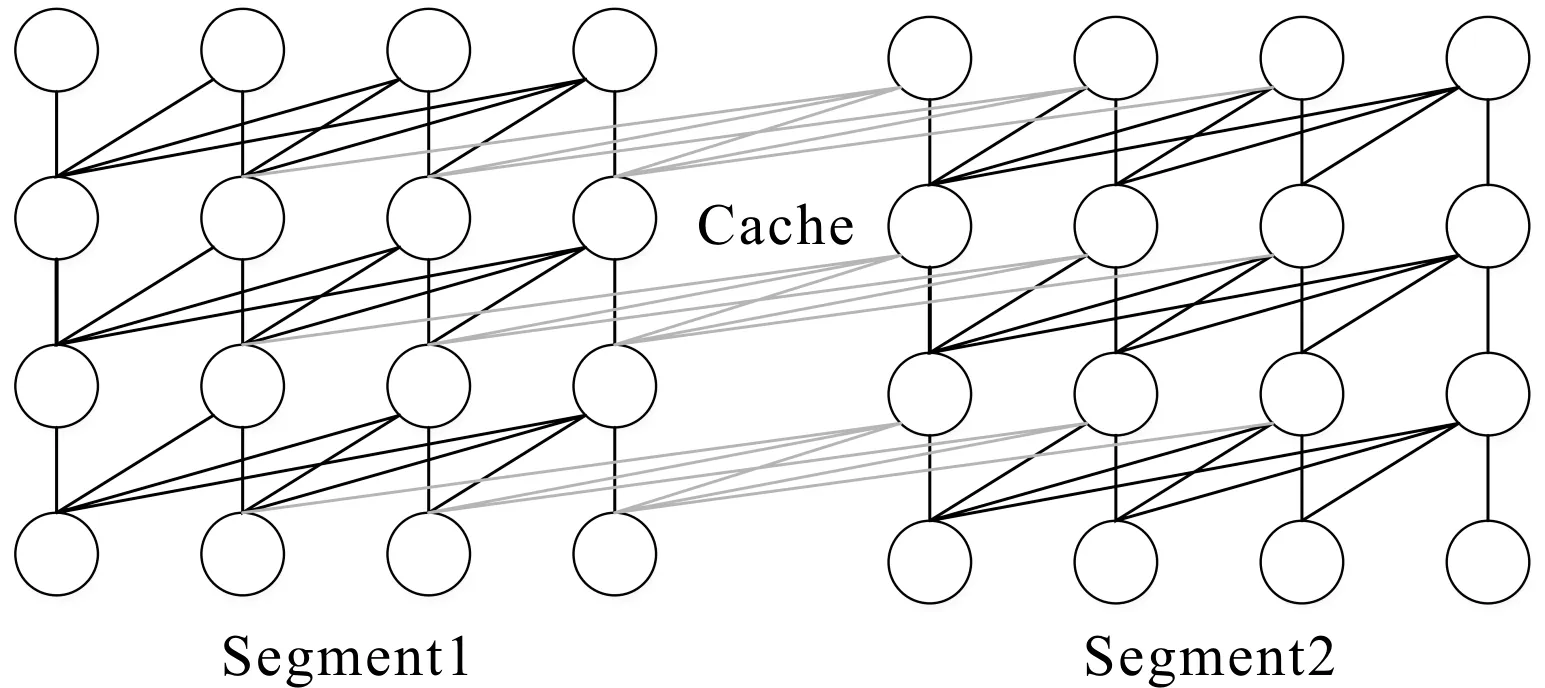
2.2 Bi-LSTM层

2.3 Attention层
2.4 CRF层
3 实验及结果分析
3.1 实验数据

3.2 实验环境

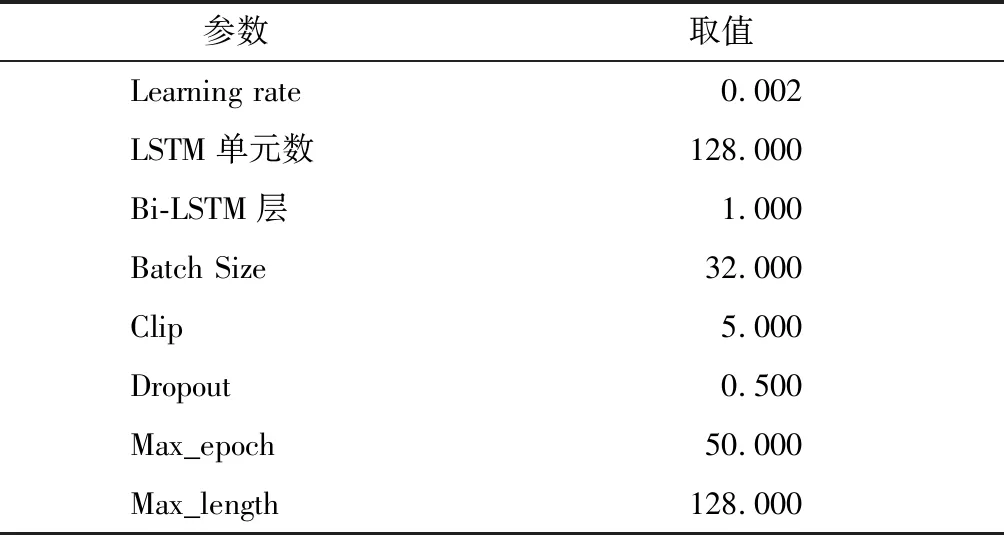
3.3 评价标准
3.4 实验结果与分析

4 结语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小学生学习指导(中年级)(2021年12期)2021-12-30
昆明医科大学学报(2021年4期)2021-07-23
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
华人时刊(2020年21期)2021-01-14
疯狂英语·新读写(2018年3期)2018-11-29
东方女性(2018年3期)2018-04-16
中国诗歌(2017年12期)2017-11-15
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
