
基于GBDT-LR融合算法的胎儿窘迫预诊模型研究
2021-06-17 08:37曾冬洲郑宗华谢婧娴
自动化仪表 2021年5期
曾冬洲,郑宗华,谢婧娴
(1.福州大学电气工程与自动化学院,福建 福州 350108;2.厦门大学附属妇女儿童医院,福建 厦门 361003)
0 引言
胎儿窘迫是指胎儿在子宫内因缺氧导致的呼吸窘迫综合症,是造成围产期胎儿死亡的主要原因[1]。胎心监护是胎心胎动宫缩图(cardiotocography,CTG)的简称,是一种对胎儿宫内健康状况进行检测评估的主要手段。临床上的CTG信号采用胎心率电子监护仪实时监测并记录下不断变化的胎儿瞬间心率。CTG信号包含胎心率(fetal heart rate,FHR)信号曲线和宫缩(uterine contraction,UC)信号曲线。通过这两条信号曲线,医生能够实时地了解胎动和宫缩时胎心的反应,并对宫内胎儿的缺氧程度进行评估。但是CTG评估的结果容易受到医生主观经验的影响,导致漏诊胎儿错过最佳医生干预时间或者误诊胎儿剖腹产出,使医疗资源得不到有效的利用。因此,为了降低胎儿窘迫的漏诊和误诊率,临床上有必要采用一种更为客观的评估方法来辅助医生作出准确、有效的诊断决策。
近年来,随着机器学习技术的发展,机器学习的算法模型在医疗决策领域的应用也越来越多,因此有不少学者尝试先利用计算机软件自动化提取FHR信号特征和UC信号特征,然后引入机器学习技术对提取到的特征数据进行分类预测。文献[2]将支持向量机算法应用到胎儿窘迫数据集上,取得了较好的分类预测效果。文献[3]利用神经网络模型,很好地克服了胎儿窘迫数据的非线性问题,也取得了较好的分类效果。文献[4]提出使用XGBoost算法建立胎儿健康评估模型。该模型分类的准确率和效率较其他算法模型都有一定的提升。文献[5]基于模糊算法对胎儿状况进行分类评估,也取得了良好的诊断效果。综上可以看出,这些胎儿窘迫诊断问题的单一模型已经有了相对广泛的应用与研究,而对于多模型融合的诊断方法还有进一步研究的空间。文献[6]通过采用梯度提升决策树(gradient boosting decision tree,GBDT)和逻辑回归(logistic regression,LR)模型相互融合的方法对个人信贷风险进行了预测。预测结果表明,融合后的模型较单个模型的预测效果有显著的提升。本文将这种模型融合的方法应用到胎儿窘迫预测中,基于真实的CTG信号数据建立胎儿窘迫分类模型,并对分类结果进行评估。
1 模型介绍
1.1 逻辑回归模型
LR是一种广义的线性回归模型,具有算法实现简单、运行速度快和内存占用少等优点,因而被工业界广泛地应用于分类问题中。对于二分类问题,逻辑回归模型的基本实现思想是利用Logistic函数将由线性回归计算得到的目标值映射至[0,1]区间,然后比较映射后的值与分类阈值间的大小:大于阈值的可归为一类,小于阈值的归为另一类。记输入的训练集为{(x1,y1),…,(xi,yi),…,(xN,yN)}。其中:xi∈R;yi∈{0,1};i=1,2,…,N。则可设xi属于Y=0和Y=1的概率分别为:
P(Y=1|x)=π(x),P(Y=0|x)=1-π(x)
(1)
由式(1)可推导出其似然函数,即联合概率分布函数设为:
(2)
对式(2)取对数,可得:
(3)
式中:w为权重向量;w×xi为w和xi的内积。


(4)

(5)
对于待分类数据x,只需把x分别代入式(4)和式(5)中。若P(Y=0|x)>P(Y=1|x),则x属于Y=0类;否则,x属于Y=1类。
1.2 GBDT模型
GBDT是一种迭代的决策树算法,其基础决策树模型选用分类回归树(classification and regression tree,CART)。在采用原始的数据特征生成首棵决策树后,GBDT模型在后续迭代生成决策树的过程中,都是以当前合计损失函数最小化为目标生成新的决策树,生成过程直至损失函数的残差趋近于零时停止。此时将会得到若干棵决策树。因此,当有新的数据样本输入GBDT模型时,将模型中所有决策树的输出结果进行线性加权,即可得到最终的分类结果[7]。
GBDT算法的核心流程如下。
输入:训练集记为{(x1,y1),…,(xi,yi),…,(xN,yN)}。其中:xi∈R,yi∈{0,1},i=1,2,…,N。
(1)对弱分类器进行初始化:
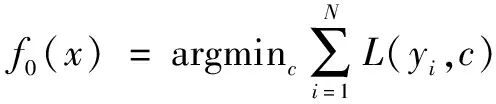
(6)
式中:f0(x)为初始决策树;L(yi,c)为损失函数;c为满足L(yi,c)最小化的常数。
(2)对于迭代轮数m=1,2,…,M,计算如下。
①逐个计算样本i=1,2,…,N的负梯度如下:
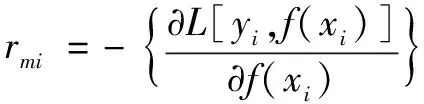
(7)
式(7)中,f(x)满足:
f(x)=fm-1(x)
(8)
②利用所有样本及其负梯度方向(xi,rmi)构建出决策树Tm。其包含有J个叶子节点,且第j个叶子节点对应的区域为Rmj(j=1,2,…,J)。
③对决策树Tm的J个叶子节点,逐一计算最佳拟合值:
(9)
④本轮迭代可得分类器如下:
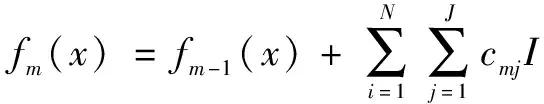
(10)
式中:I为训练样本i在第j个叶子节点区域的示性函数。
I满足:
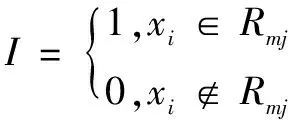
(11)
(3)将由步骤(2)中产生的M个分类器线性加权求和,可以得到最终的分类模型如下:

(12)
1.3 GBDT-LR融合模型
从1.1节逻辑回归模型的算法原理中可以看出,对于特征关系简单的数据集分类问题,逻辑回归模型具有多方面的处理优势。但是当数据集的特征关系较为复杂时,逻辑回归这种线性模型相比于其他非线性模型来说,其对数据特征关系的学习表征能力有限,进而不能充分挖掘特征数据集中包含的潜在信息。因此,为了提升逻辑回归模型对特征非线性关系的学习能力,在训练该模型之前,需要人工进行复杂的特征工程,增加数据集的有效特征和特征组合,使特征关系趋于线性化。其缺点是有效的特征工程需要在与数据集相对应的业务背景专家指导下展开,这将增加数据处理的成本。
GBDT是基于Boosting方法的决策树集成模型。而决策树的每一个非叶子节点都对应数据的某一特征,自顶部根节点至底部叶子节点的所有路径都代表着数据样本集中可能存在的特征组合形式。且由1.2节中式(12)可知,所有决策树在GBDT算法中都会被分配不同大小的权重。决策树的权重越大,其内含路径对应的组合特征重要度越大。为了从GBDT模型中获得有效的组合特征,可以对数据样本训练所得GBDT模型的叶子节点分布情况进行观察。当某数据样本通过GBDT模型时,其在每一棵决策树上都将激活一个叶子节点,记录下所有被激活叶子节点的位置并进行编码。按此方法对所有样本激活的GBDT叶子节点位置编码进行统计,挑选被激活次数较多的叶子节点作为组合特征加入至原始数据中。此外,对GBDT选取合适的决策树棵数和最大叶子节点数,既可以对数据特征进行有效的组合,又可以避免其过拟合,从而充分挖掘数据中的隐藏信息。
综合上述对GBDT模型和LR模型的分析,可采用GBDT与LR融合的方式建立有效的胎儿窘迫预诊模型。首先,利用原始数据训练GBDT模型,这样得到的每颗决策树上的每个叶子节点都将是新的特征向量的一个维度。如果对得到的所有决策树上的叶子节点进行独热编码,则在新特征向量中有样本落入的叶子节点对应的特征位编码值取1,其余特征位编码值取0。GBDT-LR模型分类流程如图1中所示。
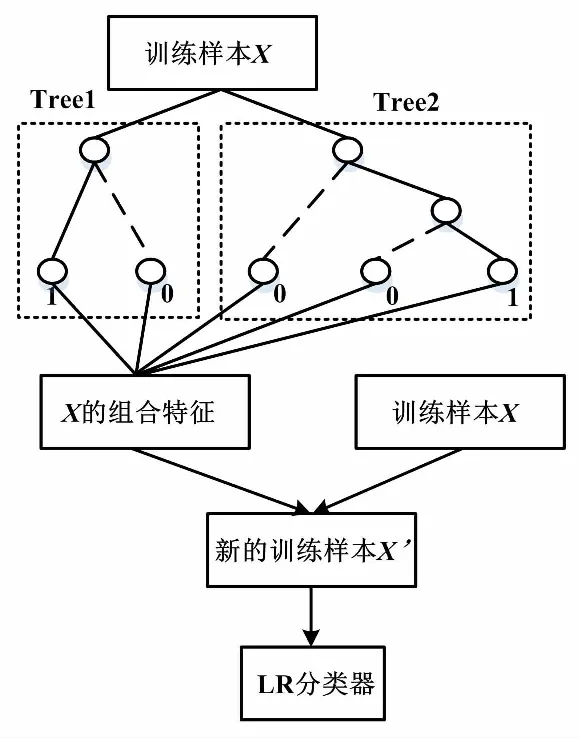
图1 GBDT-LR模型分类流程图
对于包含有Treel和Tree2两棵决策树的GBDT模型,当输入某训练样本X时,假如其分别激活了Treel上的第一个叶子节点和Tree2上的第三个叶子节点,则与这两个叶子节点位置相对应的新特征向量中的元素编码为1,剩余元素编码为0。因此得到的新特征向量可表示为[1,0,0,0,1]。最后利用合并后的新特征和原始特征一起训练LR模型,得到最终的分类结果。
2 试验数据与环境
2.1 数据描述
本试验采用来自福建省某医院的脱敏临床数据。CTG信号曲线如图2所示。

图2 CTG信号曲线
通过广州三瑞医疗器械有限公司开发的SRViewCTG软件,可以基于国际妇产科联合会(international federation of gynecology and obstetrics,FIGO)指南[8],对曲线特征进行提取。提取后的特征属性和类别标签描述如表1所示。其中的类别标签Y为临床医生根据胎儿分娩后的真实情况进行的分类:0表示正常;1表示异常。特征提取后的数据集共含1 958个有效样本,其中包括1 795个正常样本和163个异常样本。

表1 胎儿CTG数据的特征描述和类别标签
2.2 数据预处理
本文在试验前对数据的预处理工作主要包括:对含有缺失值的样本采用划分正常和异常的方法通过各自特征属性的均值分别进行填充;对二元属性特征X10、X12和X14进行数据转换。另外,为了消除各特征属性间量纲的影响,对所有数据样本采用零均值标准化的归一化方法进行处理。归一化公式如下:
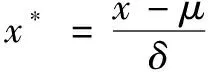
(13)
式中:μ和δ分别对应于原始数据的均值和方差。
2.3 样本均衡处理
在医疗诊断领域中,一般定义异常样本为正类样本(少数类),正常样本为负类样本(多数类)。试验过程中,在进行模型训练之前需要对数据中的正负类样本比例进行观察。如果样本类别不均衡时直接使用原始样本进行模型训练,则将使得模型倾向于关注占比高的那类样本,即对医疗诊断问题的负类(正常样本)的识别率高、对正类(异常样本)识别率低。所以在训练模型前需要对样本进行均衡处理[9]。对于正负类样本数量不均衡的情况,通常有两类方法可以保持正负类样本数量的平衡:使正类样本的数量增加的方法称为过采样;使负类样本数量减少的方法称为欠采样。本文采用Borderline-SMOTE算法[10]对正类样本进行过采样。Borderline-SMOTE算法的基本思想如下。
①对每个正类样本,确定m最近邻样本(包括正类样本和负类样本)。
②对每个正类样本,计算其最近邻的m个样本中负类样本的个数n。

由上述思想可以看出,该算法利用正负类间边界附近的正类样本随机生成若干新的正类样本。
本试验原始数据的正负样本比接近1∶11。将原始数据集的70%划分为训练集和验证集、剩下的30%作为测试集,在划分的同时选用了分层划分法保证这70%的数据和30%的数据中正负样本比接近相等,防止测试集中出现少数类样本占比极低的情况。然后,利用Borderline-SMOTE算法对上述70%的数据进行均衡处理。处理完成后,其正负样本比接近1∶1。
2.4 试验环境
本试验的软件环境为Windows10_64 bit,Python 3.5,Jupyter Notebook 5.6.0。硬件环境为Intel(R)6 Core(TM)i3-3240 3.39 GHz CPU,8.0 GB内存。
3 试验与分析
3.1 模型评估指标
模型评估指标需要针对具体问题进行选取。有效的评估指标将有助于各模型在分类性能上的对比分析。本文结合胎儿窘迫漏诊率和误诊率两个指标的物理意义,采用灵敏度(Sensitivity)和特异度(Specificity)作为模型评估的指标。其计算公式如下:

(14)

(15)
式中:TP为真阳性(true positive,TP);FP为假阳性(false positive,FP);TN为真阴性(true monegative,TN);FN为假阴性(false negative,FN)。
TP代表在测试集中真实标签为1(异常胎儿),模型预测结果也为1的样本个数。FP代表在测试集中真实标签是为0(正常胎儿),模型预测结果却为1(异常胎儿)的样本个数。TN代表在测试集中真实标签为0(正常胎儿),模型预测结果也为0的样本个数。FN代表在测试集中真实标签为1(异常胎儿),模型预测结果却为0(正常胎儿)的样本个数。模型的灵敏度越大,表示模型对异常样本的识别能力越强,即模型的漏诊率越低;模型的特异度越大,表示模型对正常样本的识别能力越强,即模型的误诊率越低。
为了综合考虑上述两个指标,本文也采用接受者操作特性(receiver operation characteristre,ROC)曲线下面积(area under the roc curve,AUC)的大小对模型性能进行评估。模型分类性能越好,则AUC值越大。最大AUC值为1,最小为0。另外,为了比较各个算法模型在胎儿窘迫数据集上的时间复杂度,本文将调用Python的第三方库函数time计算各模型运行所需消耗的时间。
3.2 试验结果与分析
经过对试验数据预处理、数据集划分、数据均衡处理和基于网格搜索法调参的GBDT-LR模型训练后,利用训练好的最优参数GBDT-LR模型对测试集进行分类。另外,本次试验也分别比较了逻辑回归(logistic regression,LR)、支持向量机(support vector machine,SVM)、反向传播(back propagation,BP)神经网络梯度提升决策树(gradient bossting decision tree,GBDT)和XGBoost等单模型在测试集上的分类效果。以上所有单模型都经过网格搜索法调参达到最优。同时,为了保证各模型分类效果的稳定性,所有指标数据均为十折交叉验证后取平均值的结果。不同模型性能对比结果如表2所示。

表2 不同模型性能对比结果
图3为处于最优参数时,训练集和测试集上的GBDT-LR模型的ROC曲线。

图3 GBDT-LR模型的ROC曲线
从表2可以看出,GBDT-LR融合模型在测试集上的灵敏度为0.896,特异度为0.842,AUC值为0.942,优于其他5种单模型算法的这3个指标,但耗时方面仅优于BP神经网络。另外,从图3可以观察到,GBDT-LR模型在测试集上的ROC曲线被训练集的ROC曲线包裹,测试集上的AUC值为0.942,训练集上的AUC值为0.968,表明GBDT-LR模型在胎儿窘迫样本数据上存在轻微的过拟合学习问题。
4 结论
本文利用GBDT和LR融合的方法构建了胎儿窘迫预诊模型。该方法通过GBDT算法从原始数据中获得组合特征,并将组合特征与原始数据特征合并后再提供给LR模型训练,从而得到最终的GBDT-LR模型。试验结果表明,相较于已有的单个算法模型,GBDT-LR融合模型有效降低了胎儿窘迫的误诊率和漏诊率,能够辅助产科医生对宫内胎儿窘迫程度作出更有效的评估。同时,本文所提方法也存在不足的地方,如GBDT-LR融合模型会因数据量过少而产生轻微的过拟合现象。因此,笔者未来将继续保持与医院间的合作,以期在更大的数据集上进一步提升胎儿窘迫的诊断效果。
猜你喜欢
中国典型病例大全(2022年10期)2022-05-10
中国生殖健康(2020年2期)2021-01-18
成都信息工程大学学报(2019年3期)2019-09-25
中国临床医学影像杂志(2019年1期)2019-04-25
小学生导刊(2018年34期)2018-12-18
中国生殖健康(2018年1期)2018-11-06
电子制作(2018年16期)2018-09-26
小学生优秀作文(趣味阅读)(2018年6期)2018-09-19
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
海峡姐妹(2016年1期)2016-02-27
