
一种自主设计的面向E级高性能计算的异构融合加速器
2021-06-17 14:03陈海燕雷元武孙海燕杨乾明陈小文陈胜刚刘必慰鲁建壮
计算机研究与发展 2021年6期
刘 胜 卢 凯 郭 阳 刘 仲 陈海燕 雷元武 孙海燕 杨乾明 陈小文 陈胜刚 刘必慰 鲁建壮
(国防科技大学计算机学院 长沙 410073)
(liusheng83@nudt.edu.cn)
高性能计算(high performance computing,HPC)是推动科学技术发展的基础性领域之一,被称为超级计算机的“下一个明珠”的E级高性能计算时代已经悄然来临.面向E级高性能计算的加速器领域逐渐发展成为全球最高端芯片的竞技场.由AMD公司于2020年11月推出的INSTINCTTMMI100加速器的双精度峰值计算能力已经突破10TFLOPS量级,达到11.5TFLOPS,典型功耗为300 W[1].由英伟达公司于2020年5月推出的A100 GPU[2],其可编程部分的双精度浮点峰值计算能力为9.7TFLOPS,张量核(tensor core)部分的双精度浮点峰值计算能力高达19.5TFLOPS,典型功耗为400 W.根据报导,英特尔公司也将于2021年末甚至更早推出代号为Ponte Vecchio的XeHPC系列GPU,预计性能也将高达数十TFLOPS[3].
作为国内最早开始自主处理器设计的优势单位之一,国防科技大学一直以来都是高性能加速器领域强有力的竞争者.本文主要对国防科技大学自主设计的一款面向E级高性能计算的加速器进行介绍.该芯片采用了CPU+GPDSP的异构融合架构,兼顾高性能、高效能和高可编程性的特点,双精度浮点峰值性能可达10TFLOPS以上,典型应用情况下效能在50GFLOPS/W左右,有望成为新一代E级超算系统的核心计算芯片.
1 体系结构
该芯片采用了异构融合架构,如图1所示.由多核CPU和4个GPDSP_Cluster五部分组成.多核CPU包含32个FT-C662 CPU内核(兼容ARM指令集),每个GPDSP_Cluster包含24个自定义指令集的FT-M64DSP核.作为芯片的主控部分,多核CPU可以访问和调用所有的资源,4个GPDSP_Cluster相互独立.该芯片将主控部分和运算部分的互连在片内解决,从而为两者间的通信提供高数据带宽.
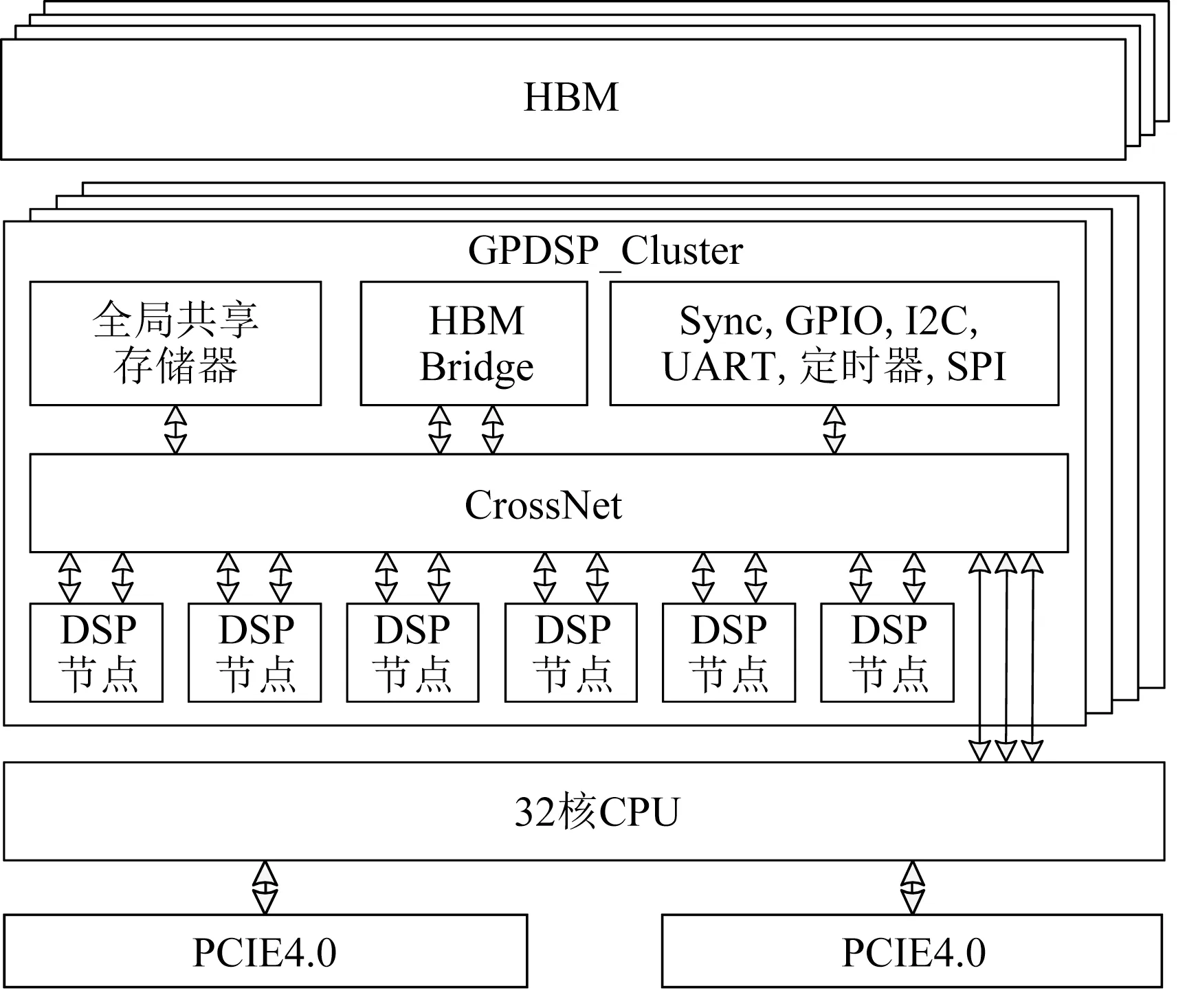
Fig.1 Architecture of the chip图1 芯片体系结构
GPDSP_Cluster从标、向量并行的64 b单核结构、可扩展多核结构等方面实施了全方位、多层次并行优化,充分开发应用的指令级、数据级、任务级并行,并针对应用进行了指令集级别的定制,提高了典型应用的峰值运算能力和效能.每个GPDSP_Cluster包含6个DSP节点(每个DSP节点包含4个DSP核).GPDSP_Cluster内包含一个全局共享存储器,提供了片上高带宽的数据传输.还包含一个HBM2转接桥和控制器,以支持片外高带宽数据传输.采用了具备高带宽、支持优先权仲裁和QoS等多个特点的多级CrossBar(CrossNet)片上网络结构,保证了数据带宽的稳定发挥.
1.1 GPDSP内核结构
DSP内核基于自主知识产权的指令集设计.如图2所示,采用了超长指令字(very long instruction word,VLIW)技术和标向量协同融合的结构.向量部件由16个同构的VPE阵列组成,每个VPE内部包含3个乘加单元.指控单元(L1P/Fetch/Dispatch)同时向标量单元(scalar unit)和向量单元(vector unit)派发指令,16个VPE采用SIMD的方式同时执行相同的向量指令.标量部件和向量部件各自有对应本地的局部存储器:标量存储器和阵列存储器.DSP内核拥有一个的DMA,支持灵活高效的数据传输方式(如点对点、广播、分段、Super Gather等)以充分适应不同的应用需求.
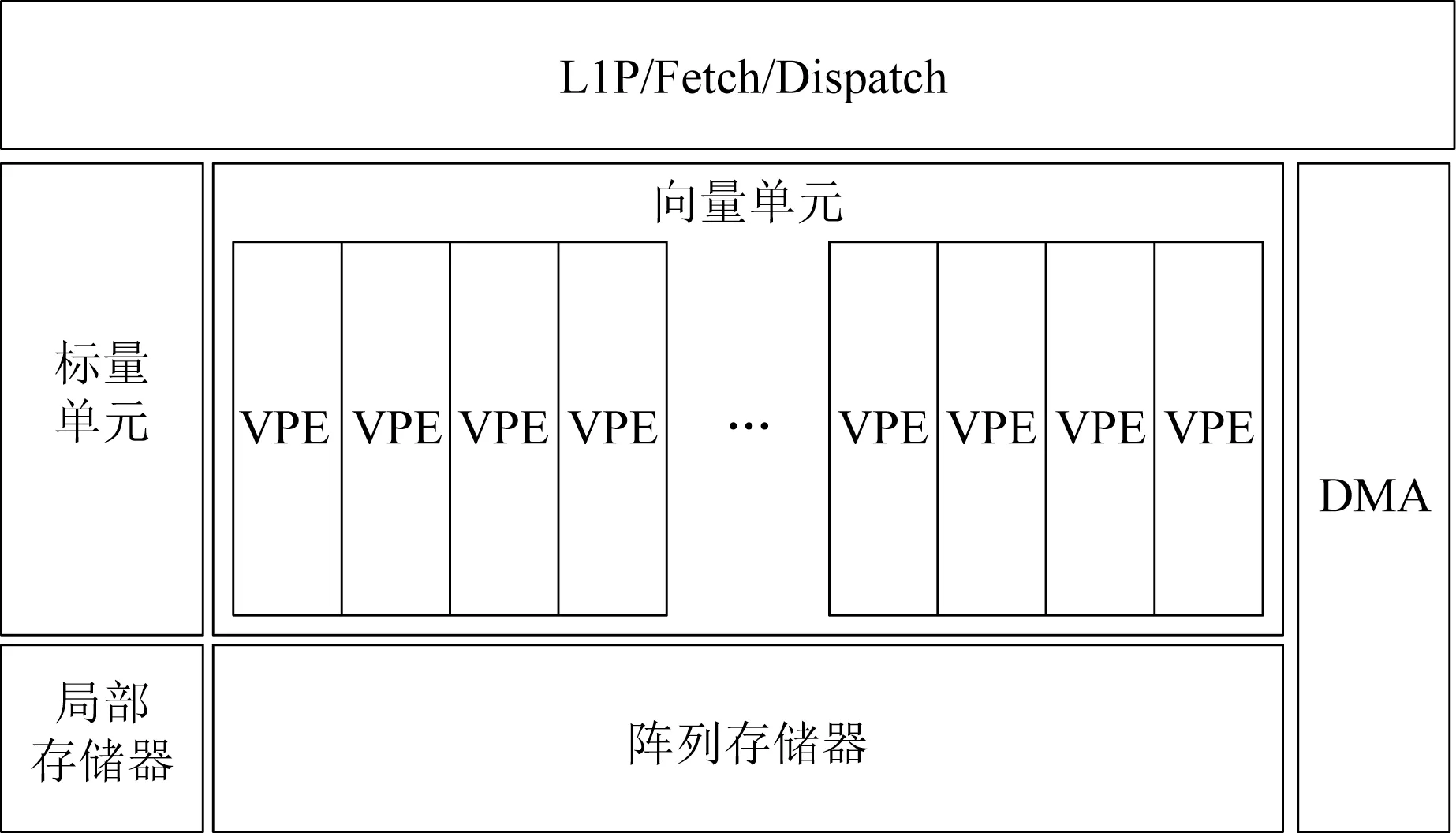
Fig.2 Structure of DSP Core图2 DSP内核结构图
1.2 存储层次
为了简化存储管理硬件逻辑设计,多核CPU内部支持硬件Cache一致性(包含16 MB的L2Cache),GPDSP_Cluster支持软件管理的垂直存储一致性.面向高性能计算以及AI等应用需求,提出了一种多层次协同共享存储结构,将加速器GPDSP核内的私有存储(近80 MB,峰值带宽98TB/s)、全局共享存储(共24 MB,峰值带宽1.2 TB/s)、HBM存储(4个HBM2,峰值带宽1.2 TB/s,容量32 GB)三级存储架构,通过高速DMA和片上网络连接,提供了高带宽的数据传输和核间数据交互能力.
1.3 先进、灵活的PCIE4.0接口
本加速器集成了2个PCIE4.0接口.每个PCIE接口除了支持4.0规范外,还兼容3.0,2.0规范.每个接口为X16设计,支持EP和RC模式.
2 软件开发环境
针对异构融合架构设计并实现了一套支持异构多核的类CUDA开发调试运行环境.支持用户在同一个界面中进行多核CPU和GPDSP异构程序的调试,支持用户在同一个工程甚至在一个文件中编写CPU和GPDSP异构程序.
如图3所示,该芯片软件工具链包含了异构编译器、资源管理库、异构运行时库、异构设备库等,方便用户快速开发面向典型领域的高性能应用.GPDSP编译器针对多核、超长指令字、向量等特点进行了一系列优化,具体包括标量和向量指令级并行优化、SIMD优化、循环展开和软流水优化、跳转延迟槽调度优化、寄存器分配优化、谓词优化等.
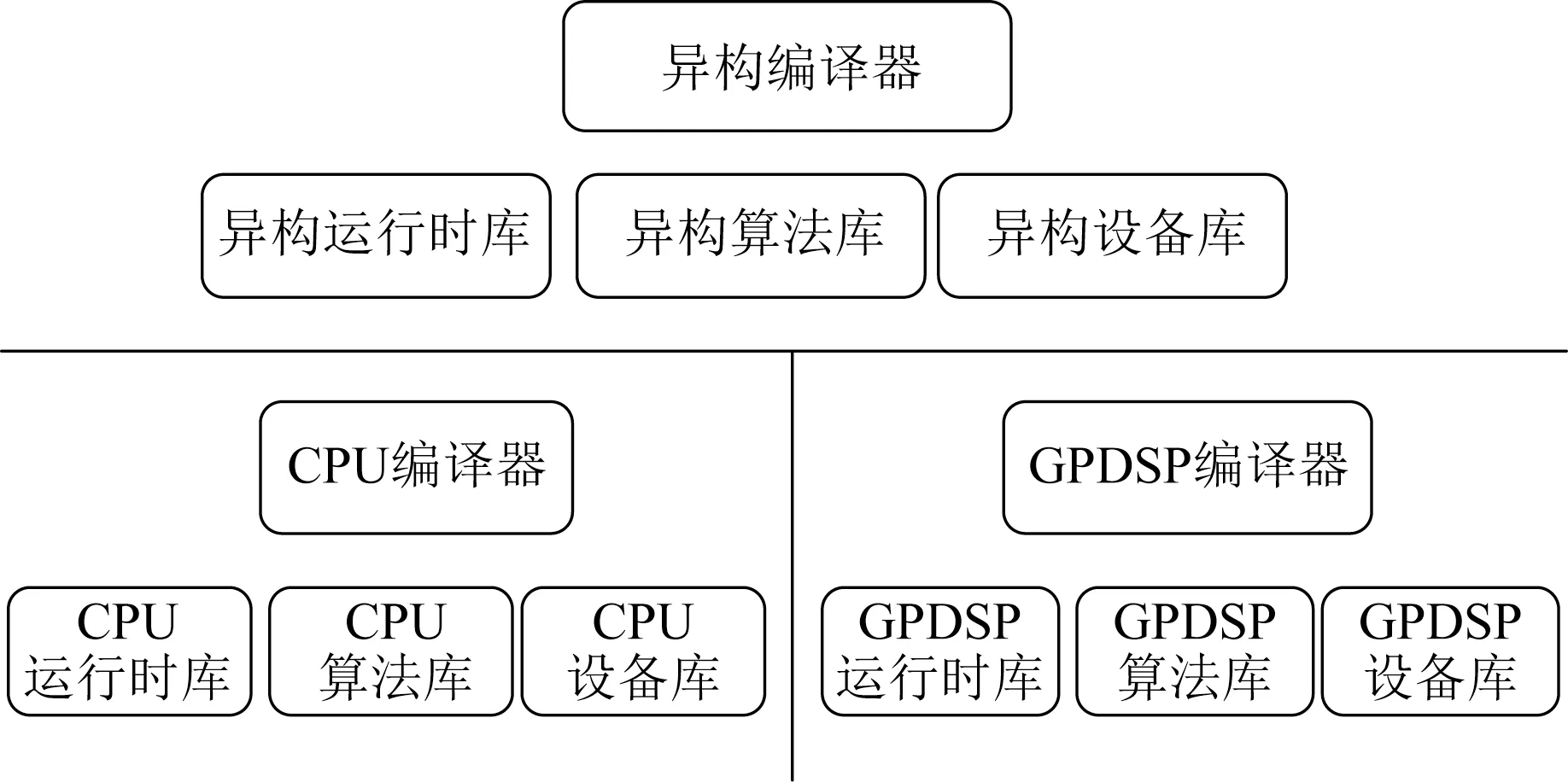
Fig.3 Structure of the software chain图3 软件工具链结构图
为了发挥加速器的计算能力和易用性,提供了面向用户核心级代码的线性汇编开发工具,能够在大幅提高核心代码效率的同时 降低程序优化难度.此外还提供与结构相匹配的手工汇编优化算法库,手工汇编优化后的算法库比普通C语言实现的库函数效率能够提高一个数量级以上.目前已经完成了Linpack,HPCG,CNN等算法核心算法库的开发.
3 算法效率评估
1)双精度通用矩阵乘法(double general matrixmatrix multiplication,DGEMM)算法.采用DGEMM算法(执行C′=A×B+C)对系统的计算效率进行评测,其中矩阵A的规模为24576×512,矩阵B的规模为512×(1152×n),矩阵C的规模为24576×(1 152×n),n为矩阵规模的系数.如图4所示,DGEMM算法在系统的实测计算效率方面平均为94%.

Fig.4 Efficiency of DGEMM图4 DGEMM算法的效率
2)卷积神经网络模型算法.在加速器上实现了深度卷积神经网络模型Alex Net.表1对比了本加速器与其他5种高性能GPU[4]实现Alex Net推理的计算性能.本加速器在深度卷积神经网络推理计算方面能够达到15 108帧/秒,具有较高的计算性能.

Table 1 Comparison of Our Accelerator and Other GPUs表1 本加速器与其它GPU的性能对比
4 小 结
本文主要介绍了国防科技大学自主设计的面向E级高性能计算的加速器芯片.目前该芯片已经顺利流片和量产,下一步将围绕该芯片进行工具链和应用开发进行更深入的工作.
作者贡献声明:卢凯(芯片架构设计)、郭阳(芯片结构设计)、刘仲(芯片算法评估)三人对本文具有同等贡献,均为通信作者.
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
现代仪器与医疗(2022年3期)2022-08-12
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
今日农业(2021年9期)2021-07-28
现代装饰(2021年1期)2021-03-29
中国计算机报(2019年12期)2019-06-21
福建基础教育研究(2019年11期)2019-05-28
