
基于生成对抗网络的超低分辨率视频中动作识别算法
2021-06-16 09:35刘松
电子技术与软件工程 2021年7期
刘松
(四川大学电子信息学院 四川省成都市 610065)
本文的主要贡献可以概括如下:
(1)提出了一个基于超分辨率重建生成对抗网络的超低分辨率动作识别算法。据我们所知,这是超分辨率重建方法第一次应用于低分辨率动作识别领域。
(2)我们在网络训练中使用了我们称之为长范围时域卷积的新的训练策略,该训练策略取得了很好的效果。
(3)大量的实验表明我们的方法的有效性和优越性。在只采用RGB 图像的情况下,与其他使用了光流图像作为输出的算法相比也毫不逊色。
1 算法描述
1.1 超分辨率模块
如之前的研究工作所假设那样,我们在训练阶段也使用了高分辨率视频。但和半耦合和全耦合网络相比,我们并不如他们那样简单地采用高分辨率图像作为网络输入以辅助训练,我们为了在动作识别模块获得更易识别的特征,我们通过一个生成对抗网络通过学习高低分辨率数据之间的映射以恢复低分辨率图像。图1 展示了我们的超分辨率生成对抗网络的大致架构。
1.1.1 生成对抗网络
自生成对抗网络[2-3]提出以来,其在生成逼真图像方面的优异表现一直令人印象深刻。生成对抗网络通过一个对抗过程轮回优化生成器和判别器,使得生成器达到最优状态。生成对抗网络的损失函数可以表示如下:

其中,x 代表真实数据,z 表示随机噪声,Dθ和Gw分别代表判别器和生成器。
我们本文的目标是自低分辨率图像恢复出高质量图像,同时获得易于识别的特征,因此我们的输入应该是低分辨率图像而不是随机噪声。受之前在超分辨率重建领域应对大下采样因子(x8)工作的启发,我们采用了在SDSR 中的生成结构和在ESRGAN 中的判别损失函数。
1.1.2 网络结构
在本小节中,我们将分别介绍生成器和判别器的网络结构。如图2 所示,我们的生成器由特征提取器和上采样模块两部分组成。
1.1.3 生成器损失函数
接下来,我们将依次介绍像素级的MSE 损失、基于VGG 的感知损失和对抗损失以及判别器的损失函数。
MSE 损失。像素级的MSE 损失计算如下:
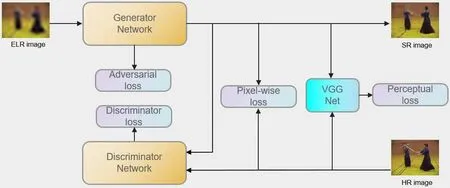
图1:超分辨率模块的大致结构图,其中ELR 表示超低分辨率(extreme low resolution),SR 和HR 分别代表超分辨率和高分辨率
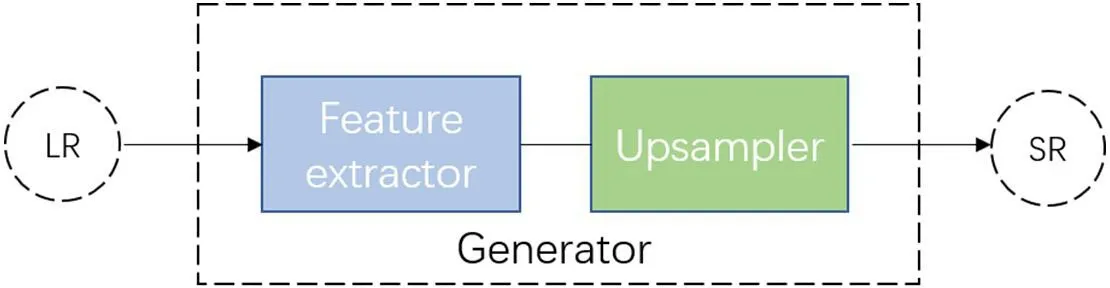
图2:生成器网络结构示意图
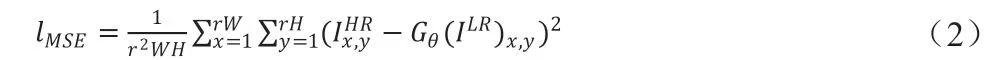
这种形式的MSE 损失函数被目前超分辨率领域许多先进方法所采用。
感知损失。感知损失一般是基于一个预训练的VGG-19 网络的最后一层提取的特征,用以衡量生成的超分辨率图像在高级语义信息层面和高分辨率图像是否接近。我们使用∅i,j来表示VGG 网络获取特征的过程,其中j 表示第j 层卷积之后,i 表示第i 层最大池化之前。我们可以定义感知损失如下:

其中,Wi,j和Hi,j表示各自VGG 网络特征图的维度。
对抗损失。除了以上基于图像内容的损失函数,我们还添加了对抗的部分。对抗损失可以表示如下:

最后,我们可以将生成器的损失函数总结如下:

1.2 动作识别模块
我们假设我们要对一个共计有L 帧的低分辨率视频进行动作识别,我们将随机选取一帧设为L1作为起点,我们以起点开始往后再连续选取帧得到一个视频片段{L1,L2,L3......Lk}。我们得目标是对这个低分辨率视频中得动作进行识别并且我们的算法过程可以用公式表示成如下形式:
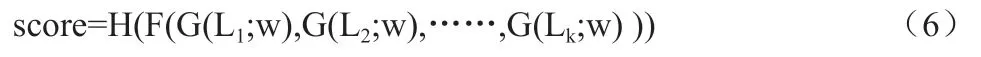
其中G 表示我们的超分辨率模块而w 则为其参数;F 则表示任意端到端的动作识别模型。有之前那些采用光流作为输入且应用双流网络的低分辨率动作识别算法不同,本文我们采用3D 残差卷积神经网络作为上式中的F 以对超分辨率重建后的图像序列进行时空建模。3D 残差卷积神经网络既有强大的时空建模能力,又避免了使用光流图像作为输入节约了算力。最后,基于F 模型的输出,每个动作类别的预测概率将会通过预测函数H 算出,本文选用softmax 函数作为H。
1.3 训练策略
1.3.1 数据增强
具体而言,我们先分别根据官方的划分文件将两个数据集划分成训练测试集。然后我们将训练集和训练集进行合并,测试集和测试集进行合并。合并后的训练集我们再用来对生成对抗网络进行训练。
1.3.2 长范围时域卷积
为了学得更好的视频表征,我们将采用长范围时域卷积以对长距离的时空信息进行建模,以此来弥补空间信息的不足。具体而言,对于每个视频片段我们通常采用16 帧作为输入,现在我们则将输入扩张至64 帧,这将覆盖更多时域上的内容进行卷积操作。
2 实验设计与结果
2.1 数据集介绍
我们选择了HMDB51 数据集以和其他先进的方法做直接的对比。并且我们放弃了Dogcentric 而选择了UCF101 数据集以继续充分验证我们方法的有效性。原因有以下几点:一方面来说,本文的目的在于对远处的人类动作进行有效识别或为隐私保护起见而识别低分辨率视频中的人类行为。然而,Dogcentric 是一个以狗的视角拍摄并记录了一些狗的动作的数据集。另一方面来说,UCF101 数据集包含了各式各样从人类于室内运动到野外活动的人类行为动作,这非常契合本文的初心:识别远离摄像头的人类动作和隐私保护条件下的动作识别。以上这些理由使得UCF101 数据集更加合理且更具挑战性以作为低分辨率动作识别数据集。
2.2 应用细节
我们的训练过程包括两个阶段:
(1)训练超分辨率模块并使用该模块自低分辨率视频中恢复超分辨率图像;
(2)使用恢复好的超分辨率图像作为识别模型的输入进行训练。
对于超分辨率模块,我们使用HMDB51 和UCF101 数据集对我们设计的生成对抗网络进行从头训练。如之前讨论的那样,我们采用仿真的低分辨率数据作为网络输入而采用对应的高分辨率数据作为标签进行训练。我们采用了Adam[31]作为我们网络的优化器并将初始学习率设置为10-3,权值衰减我们设置为10-5,并且如果验证损失持续10 个epoch 没有下降,我们将对学习率进行衰减。在批尺寸(batch size)设置为60 的情况下,整个超分辨率模块的训练持续了299 个epochs。
对于动作识别模块,我们按照[]中的设置进行训练。并且我们使用了他们预训练好的模型对我们在低分辨率情况下UCF101 和HMDB51 两个数据集进行微调。我们分别对输入16 帧和64 帧做了消融实验。我们使用SGD[32]对我们的网络参数进行优化并将学习率设置为10-3,权值衰减我们设置为10-5。本小节全部实验都是在ubuntu 环境下,使用两张Nvidia GTX 1080Ti 显卡,应用Pytorch框架完成。
2.3 与先进方法对比
我们将我们所提方法与其他低分辨率动作识别算法在12x16 HMDB51 这一极具挑战的数据集上进行了比较。表1 不仅列出了各方法的准确率而且展示了各种方法使用的输入模态和输入帧数,从表1 我们不难看出我们的方法比起其他先进算法表现都更加优异。更重要的是,仅仅采用16 帧RGB 帧作为模型输入,我们的方法都比第二好的算法领先1.5%识别率。并且如果我们按照之前其他工作的取帧方式,在取64 帧的情况下,我们的方法更是比其他算法有了大幅领先。这清楚地表明了我们算法在低分辨率动作识别领域的有效性和优异性。
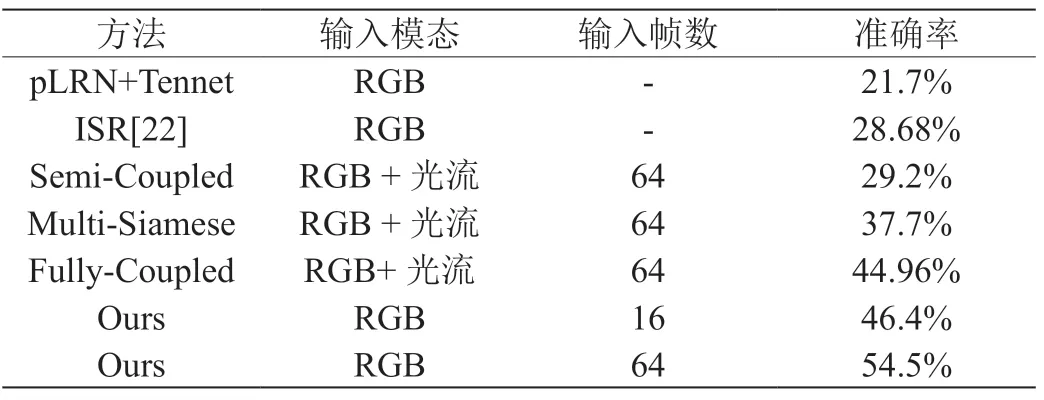
表1:在HMDB51 数据集上我们所提算法与其他先进方法的比较
3 总结
在本文中,我们提出了一种基于超分辨率生成网络的方法来识别极低分辨率视频中的动作。我们的方法包括两个模块,即超分辨率模块和动作识别模块。我们的超分辨率模块可以从低分辨率帧中恢复丢失的信息以获取超分辨率帧,以更好地进行识别。识别模块采用恢复的超分辨率帧作为输入,预测低分辨率视频中的动作类别。在HMDB51 和UCF101 数据集上的大量实验表明,我们的方法总体上达到了目前最先进的精度性能。
猜你喜欢
西北大学学报(自然科学版)(2023年2期)2023-05-08
红外技术(2022年11期)2022-11-25
数学小灵通·3-4年级(2021年5期)2021-07-16
数学物理学报(2019年3期)2019-07-23
今日农业(2019年15期)2019-01-03
家庭影院技术(2018年9期)2018-11-02
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
