
基于改进多元非线性回归模型的云计算负载预测
2021-06-16 05:29:18邢运智
电子制作 2021年4期
邢运智
(西安市第一中学,陕西西安,710000)
0 引言
近年来,随着信息和通信技术的快速发展,计算模式已经发生了重大变革[1]。“数据为王”的时代,谁掌握了数据,谁就掌握着消费者的动向,掌握着行业发展的脉络。很多企业在发展的过程中,对于数据的处理要求越来越高,仅仅依靠自己企业的服务器已经很难满足需求。在此情况下,云计算这一平台脱颖而出,其已成为继互联网、计算机之后的又一个关键技术,甚至将引领未来的信息技术产业变革。云计算发展至今已有10多年的时间,在此期间取得了飞速的发展,带来了商业模式和工作模式的巨变;同时也暴露出一些不足,如在提供资源利用率的情况下如何保证服务质量,对于用户的请求能否及时做出响应等问题[2],这些都将影响云计算的未来发展。针对此类问题,很多学者结合工作负载预测进行研究,形成一系列研究成果,其中赵莉提出基于支持向量机的负载预测模型,采用混合遗传算法和粒子群算法来选择参数[3]。谭乾提出了使用遗传算法来代替传统的BP算法训练网络参数建立模型[4]。郭正红等人提出一种基于权重调整的预测模型,其增加了多个非线性项,用于体现模型之间的联系对预测结果的影响。
本文在云计算的背景下,针对用户负载预测问题进行了研究。以国内最大的云计算提供商—阿里云的用户负载数据为研究对象,针对一年来的用户请求数据进行分析预测,建立了从线性到非线性的回归模型,逐步优化模型、优化预测结果,最终探究出了云计算用户请求负载的一般规律。
后续章节的内容安排为:第二章介绍了数据的来源和预处理方式;第三章建立了三组不同的回归模型,实现了对于数据越来越好的拟合和预测;第四章对全文内容进行了总结,并对未来的研究方向进行了展望。
1 数据收集和预处理
本文研究的数据来自于国内最大的云计算资源供应商—阿里云(www.aliyun.com)。数据基本情况描述如下:
(1)数据时间段:2018年某城市计算集群接收到的用户请求负载量。
(2)采样时间间隔:每两个小时采样一次,采样的数值为两个小时内用户负载的平均值。
(3)数据总量:共1578个数据点。
在对数据进行一致性分析和可靠性检测之后,发现在采样数据中,存在10月-11月数据部分遗失的问题。因此,将10月份以后的数据舍弃,只保留1月至9月的用户请求负载记录,共1336个数据点。
另外,由于阿里云作为国内最大的云计算供应商,用户请求负载量非常大。因此,在数据处理时,以1000次请求为单位,等比例缩小用户请求的数字,便于后续的建模和预测工作。
将预处理后的负载数据画图,可以看出,整体的走势如图1所示,而描述数据的变化趋势并进行未来数据的预测,就是本文的主要工作内容。

图1 用户对于虚拟机的需求量整体走势图
2 构建基于回归分析的时序预测模型
本章针对预处理后的数据,逐步深入构建了预测模型,从一元线性回归模型开始,之后增加了30天和7天周期的波动,逐步优化了模型的预测效果。
■2.1 模型基本假设
(1)用户对于虚拟机的需求整体稳定,符合一定的增长规律,没有出现突变情况。
(2)在一定时间范围内,包含线性增长和周期性波动两种走势。
(3)服务商的计算资源是无限的,可以满足所有的用户请求。
(4)假设服务商的市场占有率是一定的,不考虑服务商之间的市场竞争行为对用户请求负载带来的影响。
■2.2 模型一:一元线性回归模型
首先,本文基于以2小时为间隔的抽样数据,建立了基于一元线性回归的时间序列模型,来刻画负载请求的线性变化趋势。若假设 t 为时间参数,r 为用户对负载请求(单位为1000)则模型的表达式如下:

其中a和b 是该模型的回归系数。
本文利用Excel软件的数据分析工具进行拟合,我们将1335个数据点划分为训练集和测试集两个部分:
(1)训练集:前1000个数据点,时间跨度为2000个小时
(2)测试集:后335个数据点,时间跨度为670小时
在Excel中进行你和运算,得到的拟合结果如表1所示。

表1 一元线性回归模型的拟合结果
因此,得到模型公式:

经过计算得到R Square=0.3517,由结果所知拟合性能非常差。随后对该模型的预测性能进行测试,并且计算均方误差参数来衡量预测性能,RMSE = 681.9318。由图2可以看出,简单的线性模型没有足够好的预测性能,该模型存在较大的问题。需要进一步完善。

图2 模型预测走势
■2.3 模型二:加入30天周期波动
通过上述研究可知,训练集上的残差具有很强的周期性,因此我将加入三角函数特征表达式,进行模型优化。
在模型中加入正弦和余弦两个周期函数,它们的表达式分别是 sin(ωπ+φ)、cos(ωπ+φ),经过观察可得该函数的波动周期约为82,根据公式ω=2π/T,得知ω=1/41。优化后的模型表达式如下:

图3 训练集残差走势
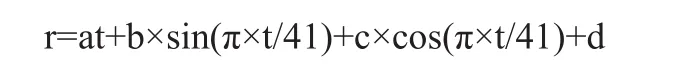
随后通过Excel软件进行拟合分析得到如表2数据。
因此,得到模型表达式为:

其中拟合优度为R Square=0.4980,说明该模型的拟合性能一般。在测试集上对该模型的预测性能进行测试,并且计算均方误差参数来衡量预测性能,RMSE = 745.7023。通过对图4的研究发现以82为周期存在一定的问题,82并非本模型的最佳周期。

图4 以82为周期波动的回归模型及预测走势
通过分析得出周期波动模型的周期应略大于82,因此,设定波动周期为84,优化的模型表达式如下:

同理,保持训练集、测试集不变情况下,通过拟合之后得到结果如表3所示。
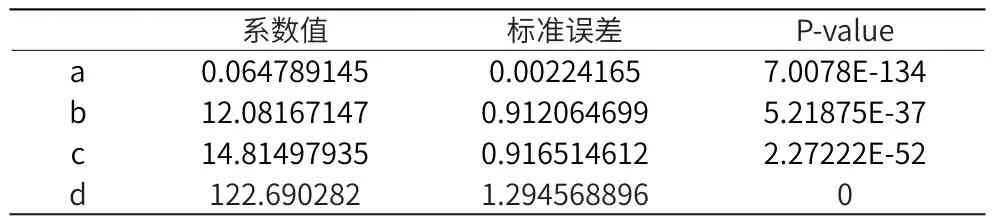
表3 优化周期为84后的拟合结果
因此,得到模型表达式为:

最终拟合得到的拟合优度为R Square=0.5497,较82周期的模型性能有所提升,说明原始数据84为周期更能刻画其波动性。同时,拟合结果也反映出该模型的拟合性能一般。在测试集上进行测试,并且计算均方误差参数来衡量预测性能,RMSE = 198.3479。研究发现均方误差较小但是拟合优度仍然较差。通过对局部数据变化情况的研究,如图5所示,可以发现数据仍存在一个的小周期。

图5 以84为周期波动的回归模型及预测走势
■2.4 模型三:84-12周期波动预测模型
研究84周期过程中,发现负载请求变化时存在双重周期性(以84为周期的大周期、以12为周期的小周期),遂添加两组周期为12的正弦、余弦函数。表达式如下:
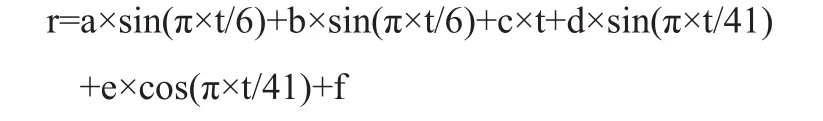
同理,训练集与测试集保持不变,利用 Excel表格进行拟合分析,得到拟合结果如表4所示。
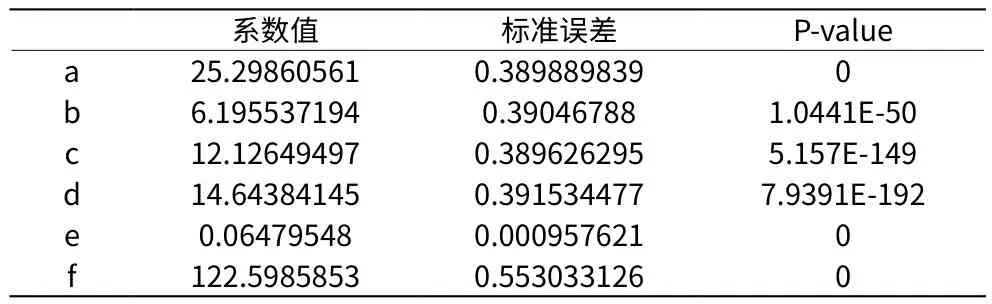
表4 8-12周期波动的回归模型拟合结果
因此,得到模型表达式为:

最终拟合得到的拟合优度为R Square=0.9179,较84周期的模型性能有所提升,说明原始数据存在以84为周期的大波动以及12为周期的小波动。同时,拟合结果也反映出该模型的拟合性能较好。之后对该模型的预测性能进行测试,并且计算均方误差参数来衡量预测性能,RMSE =198.2078。如图6所示,通过研究发现拟合优度较高。
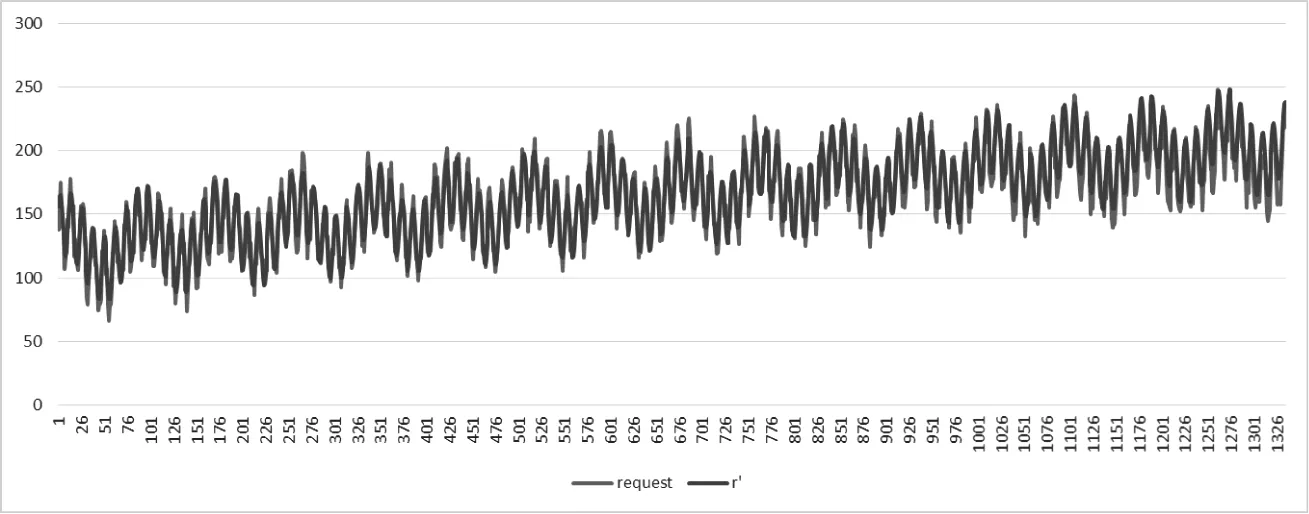
图6 以84—12双重周期波动的回归模型及预测走势
因此,从实验结果可以看出,用户请求的负载具有明显的线性增长的特征和周期性波动的特征。线性增长的部分体现在请求量随时间整体上扬、在模型表达使用以线性的部分进行刻画;周期性波动的特征体现在以84和12为周期的三角函数上,反应用户存在以1天和7天为周期的请求波动性。
3 总结展望
云计算是目前信息技术领域炙手可热的资源共享技术,极大地方便了目前的资源使用。在云计算领域,用户负载预测一直是一个重要的研究课题。本文基于数据挖掘的理论和方法,针对阿里云的用户负载数据进行研究,经过数据收集、预处理和建模分析三个部分,探索了一元线性回归、带周期性的非线性回归等多组模型,通过不断优化模型,预测性能也得到了不断的提升。最终结果显示,用户请求数量具有整体上涨、按7天周期模型和按1天周期波动的特征,为后续的用户请求负载预测提供了指导性的帮助。
在未来的研究中,还可以进行以下几个方面的深入拓展:
(1)使用更加复杂的模型,例如人工神经网络模型、深度学习模型、随机森林模型进行预测,争取能够实现更加精准的预测性能;
(2)获取更多的数据,对其他几个云计算生供应商的用户数据进行分析,研究是否存在一些同质化的规律;
(3)对于预测的结果进行进一步的分析利用,根据用户负载的预测来研究云计算中虚拟资源部署的问题。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
今日农业(2019年12期)2019-08-13 00:50:14
文学少年(原创儿童文学)(2019年1期)2019-05-23 09:37:26
中国化肥信息(2019年3期)2019-04-25 01:56:16
现代计算机(2019年6期)2019-04-08 00:46:50
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
环境保护与循环经济(2017年2期)2017-09-26 11:52:16
