
结合局部奖励机制的视频摘要技术研究
2021-06-11 10:17周娟平
计算机工程与应用 2021年11期
梅 锋,周娟平,陆 璐
1.广东省广播电视网络股份有限公司中山分公司,广东 中山528403 2.华南理工大学 计算机科学与工程学院,广州510006
随着大数据时代的到来,视频媒体应用程序以前所未有的速度堆积起来。因此,如何有效地浏览、检索和分析大量视频成为越来越需要解决的问题。视频摘要技术是解决以上问题的有效方法,它是从原始视频中提取关键帧或关键镜头,以更简洁的形式呈现视频重要内容的一种技术,这样可以加速用户浏览和节省存储空间。视频摘要技术是一个具有很强的现实意义但在研究和行业中都有待探索的课题。它主要包括以下三个步骤(如图1所示)。

图1 视频摘要生成的一般过程
首先,提取视频帧的特征作为输入序列,然后设计模型以预测视频镜头重要性分数,最后,将关键镜头合成生成视频摘要。
传统的视频摘要技术主要是通过无监督学习来实现的,包括聚类、图模型、稀疏编码等。尽管无监督方法长期以来一直主导着视频摘要领域,并且已经开发了许多方法,但仍有一些不足之处。由于视频摘要是一项主观任务[1],因此无监督学习难以实现面向用户的视频摘要。近年来,有监督学习的视频摘要方法引起了更多学者的关注[2-5]。有监督学习是为了明确学习和总结人类选择摘要的潜在标准。一般来说,有监督的方法比无监督的方法具有更好的性能[6]。
目前最先进的视频摘要技术是基于编码器-解码器框架,该框架将输入序列编码为固定长度的中间向量,然后将其解码为满足任务要求的输出序列。这是一个序列到序列的结构化预测问题。编码器和解码器通常使用递归神经网络(Recurrent Neural Network,RNN)技术,该技术已实现且被证明是建模远程依赖问题的有效方法。长短期记忆网络(Long Short-Term Memory,LSTM)作为一种特殊的RNN,解决了梯度消失的问题,被广泛用于视频摘要领域[3,6-7]。其中文献[3]中的研究是最有吸引力的,它利用行列式点过程(Determinant Point Process,DPP)选择包含不同内容的关键帧,从而提高视频摘要的多样性。此外,Ji等人[6]介绍了一种基于LSTM的注意力机制模型,为视频帧分配不同的权重。
以上所有编码器/解码器模型都已被证明是有效的,但是仍然存在很多缺陷。一方面,编码器解码器框架的计算复杂度很高,尤其是在使用双向LSTM网络的情况下[1]。另一方面,基于RNN的模型无法在训练示例中进行并行化,使得模型在更长的视频序列上的计算复杂度更高[8]。因此,Vaswani等人[8]通过使用注意力机制代替传统的RNN建立了解决seq2seq问题的整个模型框架,并取得了最好的结果。类似地,文献[1]使用自注意机制和两层全连接的神经网络来实现视频摘要框架。注意力机制的优点是能够赋予视频帧不同的权重一步捕获全局信息,并忽略不相关的信息。
Zhou等人[7]提出了使用强化学习实现视频摘要技术,同时还考虑了生成摘要的多样性和代表性。但由于模型是在整个视频上评估摘要的多样性和代表性奖励,忽略了视频序列中固有的时序关系,导致生成摘要缺乏故事情节的逻辑性。
为了提高训练速度,同时考虑到视频摘要的固有顺序性质,提出了一种具有编码器-解码器结构的注意力机制和局部奖励视频摘要网络(ALRSN)。为了训练ALRSN模型,采用卷积神经网络(Convolutional Neural Networks,CNN)对视频帧进行特征提取,而解码器则是通过自注意力机制实现的神经网络。该模型的体系结构使用简单的矢量运算来实现,取代了复杂的RNN模型。即使在序列长度可变的情况下,也可以在训练过程中通过单次向前或向后运行实现。模型的输出结果是视频帧被选择作为摘要的概率。考虑到不应该忽略顺序数据的固有时间结构,把摘要结果的片段映射回原视频中,并在局部范围内中评估摘要的性能,使摘要拥有原视频的时序关系。其中,评估摘要性能的函数称为局部奖励函数,该函数共同考虑了生成摘要的局部多样性和局部代表性。在有限范围内(图2),局部多样性奖励衡量被选视频帧与其最近的帧之间的不相似程度,而局部代表性奖励衡量视频帧在局部范围内的独特程度。这两个局部奖励相互作用,以促进模型生成更多样化和更具代表性的摘要。

图2 限制评估摘要性能的范围
综上所述,本文的主要贡献概括如下:
(1)提出了一种基于自注意力机制和局部奖励函数的视频摘要框架。它比最新的视频摘要算法结果更优,同时结构更简单,训练速度更快。
(2)设计了局部奖励函数,在局部范围内实现视频摘要的多样性和代表性。
1 相关工作
根据最新的研究,视频摘要有两种主要展现形式:基于关键帧的静态摘要和基于关键镜头的动态摘要。本文重点讨论后者,主要步骤包括视频内容分析和摘要生成。
1.1 有监督方法
根据视频摘要的生成过程中是否需要标记数据,视频摘要技术的研究可分为两类:无监督的和有监督方法。有监督方法可以直接从手动标记的视频摘要数据中学习选择关键镜头的准则,因此自动生成摘要的过程与人工摘要的决策过程相似,且更接近于人类的理解。Gygli等人[9]首先将视频分割成超帧,然后结合低、中、高三个层次的特征对线性回归模型进行训练,从而预测兴趣分数。最后,通过最大化超帧的兴趣分数来选择视频摘要。此外,他们在后期的工作[2]中设计了一个多目标函数,使生成的摘要满足兴趣,代表性和一致性的评估标准。Wei等人[10]关注视频摘要的语义信息,通过最小化所生成的摘要视频描述语句与人类注释文本之间的距离来选择视频镜头。Li等人[11]将视频摘要表述为元学习问题,将每个视频视为单一任务,以便更好地利用从处理其他视频的过程中学到的经验和知识来处理新的视频。Zhang等人[12]提出了一种扩展的时态关系生成对抗网络,使用生成对抗网络训练模型,并将LSTM与时态关系单元相结合,以捕获不同时间窗口的长期依赖关系。
1.2 注意力机制
当用户选择视频摘要时,存在视觉注意力,即越受关注的镜头或视频帧,越有可能被选中成为摘要。现有的一些工作试图将注意力机制建模为摘要选择的基础。
注意力机制关注于不同位置的编码向量,并赋予序列不同的注意权重,从而提高了翻译的准确性。在以前的深度学习方法中,模型提取的信息以同等的重要性向后流动。如果可以提前知道一些先验信息,则可以基于这些信息抑制某些无效信息的流动,从而可以保留重要信息。注意机制的作用是学习模型不同部分的重要性,然后将它们结合起来。
根据不同的计算方法,注意力机制可以分为硬注意力和软注意力。基于软注意力机制的框架在机器翻译、文本摘要和点击率等领域表现突出。根据注意力关注的范围不同,注意力机制又可以分为全局注意力和局部注意力。全局注意力类似于软注意力,而局部注意力是软注意力和硬注意力的组合,解决了硬注意力中不可分割模型的问题。对于具有注意力机制的视频摘要,大多数方法都基于全局注意力。本文模型将重点放在局部信息上。
在视频摘要领域,Ji等人[6]提出了一种基于注意力机制的编解码视频摘要方法。编码器是通过双向LSTM实现,而解码器是基于注意力机制的LSTM网络。基于注意力机制的LSTM网络可以自适应地调整当前状态的注意权重,捕捉视频序列的上下文信息,有助于提高模型选择视频摘要的准确性。Fajtl等人[1]提出了使用注意力替代循环神经网络,认为人工选择视频摘要时存在视觉注意力,根据注意力不同捕捉视频序列的相互依赖关系,并赋予视频片段不同的权重。由于注意力机制的有效性和高效性,本文采用注意力机制探索视频摘要问题。
1.3 奖励函数
当前,有些工作通过设计多目标函数,以优化视频摘要的通用标准实现。例如,Gygli等人[2]设计了多目标函数,以使生成的摘要满足评估标准,包括兴趣、代表性和统一性。具体来说,他们将视频摘要视为子集选择问题,并通过优化子模块函数来学习线性组合。类似地,Li等人[4]设计了四个评估标准,代表性、重要性、多样性和故事性。然后,他们建立了一个评分函数,将这四个标准与最大边际算法线性地结合在一起。值得关注的是他们提出的框架对于编辑视频摘要和原始视频摘要都是通用的。此外,Zhou等人[7]设计了一种新的奖励函数,利用概率分布生成视频摘要,然后计算生成摘要的多样性和代表性。同样,本文方法评估生成的摘要的多样性和代表性,并进一步考虑时间距离的程度,即评估范围。
2 模型
将监督视频摘要任务看作是序列到序列(Seq2Seq)的预测问题,并设计了一个基于注意力机制和局部奖励机制的视频摘要网络(ALRSN)。该网络通过自注意力机制预测视频帧的重要性得分,然后通过概率分布采样生成视频摘要,最后使用局部奖励函数评估生成的摘要的多样性和代表性。由于本文模型是实现动态视频摘要,是基于镜头的视频摘要,而模型的输出结果是帧级重要性分数,因此通过算术平均将帧级重要性分数转换为镜头级别的重要性分数。最后,选择重要性分数高的视频镜头以形成视频摘要。过去,序列到序列问题的常用方法是使用RNN网络,例如LSTM和GRU。与基于RNN的方法不同,本文方法使用注意力机制实现,训练速度更快,模型简单,更容易并行运算。模型结构如图3所示。
2.1 自注意力机制
假设一个视频有N个帧,并且每个帧都被预处理为特征向量(通过预训练的CNN)。将视频特征序列表示为X=x1,x2,…,xN。本文的目标是通过模型学习每个视频帧的重要性分数,并选择镜头的子集作为摘要。输出的序列表示为Y=y1,y2,…,yN,其中yt∈[0,1)表示视频中第t帧的重要性分数。
将视频摘要看作序列到序列的学习过程。序列编码是学习序列结构信息的有效方法。它可以使用递归神经网络(RNN)、卷积神经网络(CNN)和注意力机制来实现。注意力机制是最快的方法,只需一步即可获取全局信息,可以直接访问序列中所有位置的信息(图4(a))。计算方法是:

公式(1)是Vaswani等人[8]提出的注意力模型的通用公式,其中attt表示视频帧序列xt经过注意力机制处理后的结果。A和B是用于计算相关性得分的不同序列。

at和bi分别是A和B的项,得分函数score用于计算A和B之间的相关性。

图3 ALRSN的模型结构图

图4 (a) 注意力机制模型

图4 (b)自注意力机制模型
自注意力是一种特殊的注意力模型,当A=B=X时(如图4(b)所示),它可以捕捉序列的内部依赖关系。用于计算自注意力相关性得分的得分函数可以写成:

有两种方式来计算自注意力的相关性得分,加性注意(公式(4))和乘法注意(公式(5))。

其中,t,i∈[0,N),Ua和Va是网络权重矩阵,而ba是偏差。这些参数将在模型训练期间与其他参数一起调试。
由于加法注意力仅连接视频帧的序列,而没有充分探索视频帧之间的内部关系。乘法注意力的表现更好,它探索了自我注意力的内在联系,并且更容易并行运算[1,6],因此本文采用乘法注意力实现。
一旦通过以上方法计算了相关性得分,就可以将其归一化为注意力权重。

在每个时间步t计算注意力权重,它反映了输入视频中第i个时间特征的重要性程度。然后,将具有注意权重的输入特征进行加权平均,可以得到结果上下文向量attt,该向量将用于最终帧得分回归。

最后,视频帧得分回归是由两层神经网络构成的。第一层由上下文向量和原始视频序列的加权和实现,这样重要性分数结果具有全局上下文信息,并根据注意力机制有选择地聚合上下文。激活函数使用ReLU,然后将dropout设置为0.5以防止过拟合,最后进行层归一化。第二层具有相同的dropout和层归一化层,激活函数由Sigmod实现。
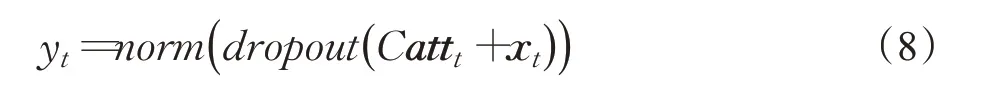
2.2 局部奖励函数
在训练期间,ALRSN模型将评估生成的视频摘要的性能。一方面,将模型训练结果直接与人工摘要重要性分数进行比较。另一方面,通过局部奖励函数来优化模型。在模型不断将期望与实际结果之间的损失最小化的同时,局部奖励LR函数也使期望的奖励回报最大化。一般而言,高质量的视频摘要应该既多样化,又能代表原始视频的主要内容。为此,受到Zhou等人[7]的启发,提出了一个局部奖励函数,用于评估所生成摘要的多样性和代表性。首先,使用概率分布对注意力机制结果yt进行采样生成视频摘要S。实现细节在公式(9)中定义。

视频帧之间的时间特征不应该被忽略,因为它们对于故事情节的构建至关重要。现有的大多数方法都是基于全局考虑,忽略了视频序列固有的时间特性。为了解决这个问题,设计了一个具有局部多样性和局部代表性的奖励函数。具体来说,当评估某个视频镜头的多样性和代表性时,仅选择其前后的λ个视频帧作为参考。λ控制时间距离的程度,即评估范围,它是一个超参数。其中,λ1控制多样性评估的范围,λ2控制代表性评估的范围。在本文的实验中,当λ1=20,λ2=10,获得最好的效果,实验部分将对此进行说明。
2.2.1 局部多样性奖励
对模型结果进行采样并衡量生成视频摘要的性能。局部多样性表示视频镜头在局部范围内与其他帧之间的不相似程度。越不相似,多样性就越高。具体地,引入了基于时间特征的局部奖励范围参数λ。当两个帧的距离超过λ时,将忽略它们的多样性,而仅考虑有限范围内的帧。这是因为本文认为距离遥远的片段复现对视频摘要的代表性是有重要意义的。最后,局部多样性LRdiv计算为局部范围内视频帧之间差异的平均值。具体实现如下所示:

其中,ddiv是由公式(11)计算的差异函数。

生成的视频摘要S通过公式(9)采样计算得出,ddiv表示选择帧与附近帧之间的不相似函数,这是局部多样性。
2.2.2 局部代表性奖励
代表性衡量生成的摘要能代表原始视频的程度。为此,将代表性表示为密度问题。选择一组中间点,使视频帧与最近的中间点之间的均方误差最小。也就是说,视频摘要中越多的帧到中间点的距离越小,则视频镜头在整个视频中所占的时间比例就越大,这样的视频摘要越具有代表性。考虑视频序列的时间特征,仅将中间点与附近的视频帧进行比较。对于其他超出范围的视频帧,将代表性得分设置为最大值inf,这样可以在公式(12)取最小值时忽略该帧。实验结果优于不考虑时间特征的方法。将LRrep定义为公式(12),将drep定义为公式(13)。

通过局部代表性奖励函数LRrep,可以不断鼓励模型在特征空间中选择聚类中心的视频帧。
2.3 函数合并
局部奖励函数LR由局部多样性奖励LRdiv和局部代表性奖励LRrep组成,LRdiv和LRrep相互作用,共同指导ALRSN模型学习。具体来说,通过简单的运算把两部分奖励分数融合形成最终的局部奖励分数,通过最大化该奖励分数,使模型选择更具有多样性和代表性的视频摘要。
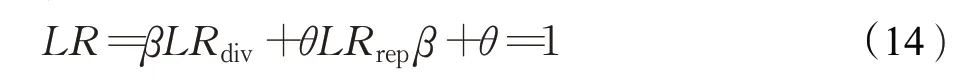
在训练过程中,给LRdiv和LRrep赋予不同的重要性权重,由于β+θ=1,设置θ=1-β,并调整β的大小,β是一个超参,实验部分对此进行了验证。
2.4 重要性分数转换成视频摘要
动态视频摘要的最终呈现是视频镜头的子集,并且模型输出结果是帧级别的重要性得分,因此需要将输出结果转换为镜头级的重要性分数。首先,使用核时态分割算法(KTS)[13]对视频执行感知变点检测并将其分段为视频镜头,然后将镜头内视频帧的重要性分数取平均值si作为镜头重要性分数。由于视频摘要是通过最大化镜头级别的重要性得分来生成的,因此使用0/1背包算法选择重要性得分高的镜头组成摘要。此外,如文献[1]中所示,将生成的摘要的总时长限制为原始视频的15%(如公式(16)所示)。

其中,yi,j代表在第i个镜头里第j帧的重要性得分,li是第i个镜头的长度。ui∈{0,1},ui=1代表第i个镜头被选入摘要,K表示镜头个数,L表示视频长总长度。
3 实验结果和分析
在上一章,已经详细介绍了模型的结构,接下来,首先介绍实验实现细节,包括数据集、评估指标和实验设置。然后,提供主要的实验结果和比较分析。接下来,提供模型生成的摘要结果以证明本文方法的优势。最后,进行参数分析。
3.1 实验设计
3.1.1 数据集
本文实验主要在TvSum[14]和SumMe[9]数据集上进行,这是当前仅有的适用于视频摘要的标记数据集。TvSum包含50个视频,每个视频都有20个用户标签。SumMe包含25个视频,每个视频由15~18个用户标记。以上两个数据集对于训练深度模型仍然很小。为了弥补这一缺陷,参考了Zhang等人[3]的论文,引入OVP[15]和YouTube[15]数据集作为增强训练数据集。表1提供了这四个数据集的详细说明。
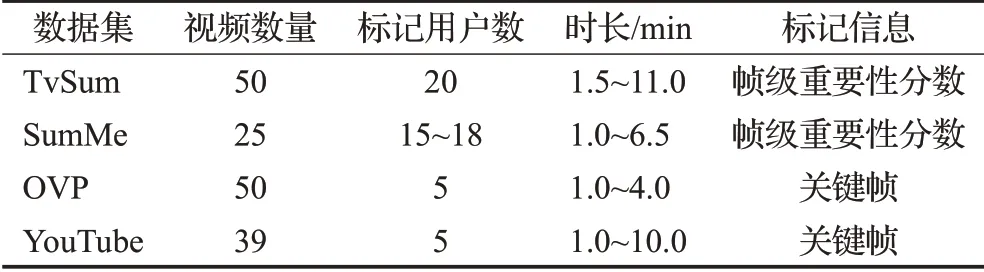
表1 四个基准数据集的详细说明
3.1.2 评价指标
为了直接与其他方法进行比较,遵循其他方法的评价指标,并使用F值来评估本文模型的性能。F值表示精度和召回率的调和平均。公式如下:
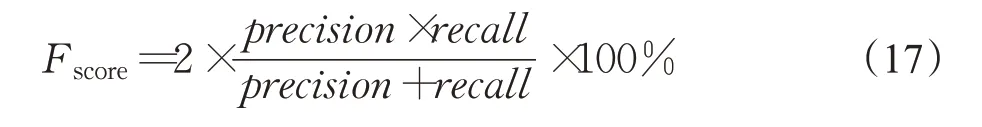
要获得F值,必须同时计算精度和召回率。假设机器生成的视频摘要为M,人工摘要为G,并且它们的重叠部分为O。精度和查全率的计算如下:

3.1.3 实验设置
根据Zhang等人[3]建议,对这两个数据集使用5倍交叉验证,分为规范设置和增强设置。在规范的设置中,将为TvSum和SumMe数据集随机生成五个训练组和测试组,其中80%的数据用于训练,剩余的20%用于测试。在增强设置中,80%仍用作训练集,其余用作测试集。以TvSum的增强设置为例,训练集包括SumMe、OVP和YouTube的所有样本,以及80%的TvSum样本,其余20%用作测试集。此外,如Fajtl等人[1]所建议,将视频摘要限制为原始视频长度的15%。根据Song等人[14]和Gygli等人[2]的研究,对TvSum数据集的每次训练取平均值,对SumMe数据集的训练取最大值。
3.2 比较和分析
3.2.1 对比实验
选择了七个最新的有监督视频摘要方法,与本文的ALRSN模型进行比较。所选基准算法的性能结果来自原始论文。(1)dppLSTM[3]使用LSTM建模视频序列远程依赖关系,并使用DPP作为补充以增强视频摘要的多样性。(2)DR-DSNsup[7]是一个基于深度强化学习的视频摘要网络,它同时考虑了生成摘要的多样性和代表性。(3)SASUMsup[10]将生成摘要转换成语义描述,并通过网络选择最具语义代表性的视频片段。(4)AVS[6]是一种基于注意力机制的编解码视频摘要方法。编码器是通过双向LSTM实现的,而解码器是引入注意力机制的LSTM网络。其中,A-AVS基于加性注意力,M-AVS基于乘性注意。(5)DTR-GAN[12]实现了一种扩展的时态关系生成对抗网络,将LSTM与时态关系单元相结合,以捕获不同时间窗口的长期依赖关系,而模型训练则依赖于生成对抗网络。(6)VASNet[1]实现了使用注意力机制来代替基于复杂RNN的视频摘要方法。
在表2中,无论是规范设置还是增强设置,本文方法都能在两个数据集上实现更高的性能。具体来说,在TvSum数据集上,规范和增强设置分别提高了0.44个百分点和0.69个百分点。在SumMe中,规范设置和增强设置分别增加1个百分点和1.5个百分点。本文方法在SumMe数据集上获得更高的性能可能是,相比于TvSum,本文的ALRSN模型可以从中提取更多的局部信息,而在TvSum中,大多数结果已经接近人工摘要的性能。增强设置的结果比规范设置更好,因为有更多可用数据共模型学习,说明本文模型更适合应用于大规模的数据集。值得一提的是,本文模型优于过去的基于注意力机制的最佳方法VASNet[1],本文模型侧重于具有局部多样性和局部代表性的更多局部信息。
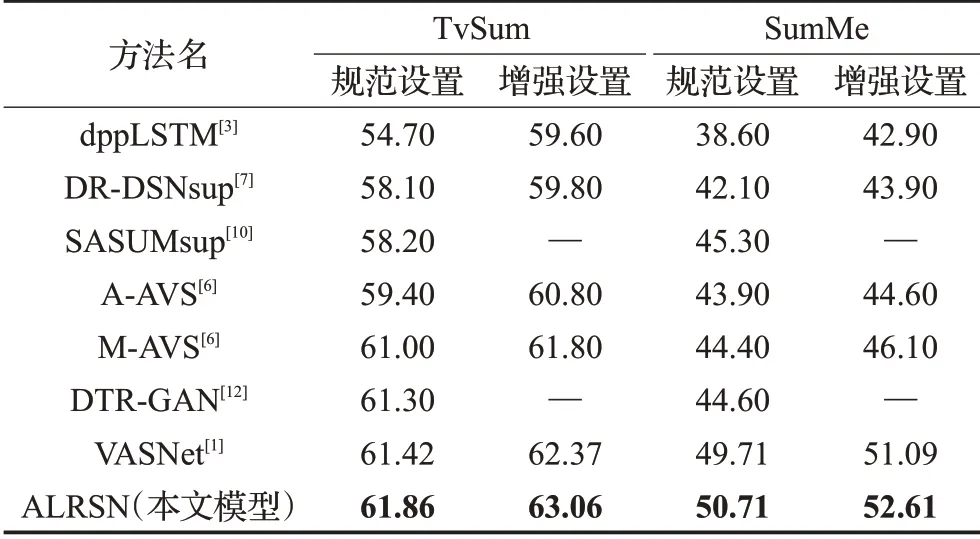
表2 实验结果对比%
3.2.2 摘要结果分析
为了更直观地比较重要性分数,在图5中绘制了TvSum数据集视频14的人工重要性分数(红色)和模型预测重要性分数(蓝色)。显然,通过局部奖励LR函数,本文方法获得更高的重要评分,而对于不重要的帧则更低。与人工重要性分数进行比较,可以看到它与机器摘要之间的明确关联,从而确认了本文方法的有效性。

图5 视频14的训练过程
将视频14最终的模型摘要结果与人工摘要进行比较。这是一部关于给狗狗美容的视频,从图6可以看到机器选择的视频片段与视频主题一致。此外,通过直方图展示摘要结果在人工摘要中的分布情况。如图7所示,用灰色显示了人工重要性分数,而机器选择的镜头用蓝色表示,对应的视频帧显示在下方,显然机器生成的视频摘要与真实摘要的峰值对齐,即模型选择了人工重要性分数较高的镜头,并覆盖了整个视频。
3.3 参数分析
在第2章中详细描述了本文模型,该模型主要基于自注意力深度模型,并引入了局部奖励函数。实际上,ALRSN的性能优于F值中的现有方法,这可以从实验结果中看出。本章重点介绍模型的参数敏感性,包括LRdiv和LRrep的奖励权重β和奖励范围λ。
3.3.1 奖励权重β
在本小节中,分别关注局部代表性和多样性的有效性,前者倾向于选择不重复的视频帧,而后者则试图保留在视频中出现时间长的视频帧。通过共同指导模型选择视频帧的过程,这两部分有助于鼓励模型选择高质量的视频帧,从而实现符合人类选择的视频摘要。

图6 视频摘要结果展示

图7 模型选择结果的分布情况
图8显示了局部奖励权重对模型结果的影响。观测参数β从0~1之间变化,从图中可以看出,权重分别设置为0.7和0.6可以在TvSum和SumMe数据集上获得最好结果,F值分别为61.86%和50.71%。由公式(14)可知,β权重越高,表示多样性越重要。从两个数据集的结果来看,局部多样性的重要程度高于代表性对测试数据的影响,这是由于被测视频大多是主题明确,而内容更丰富的摘要更符合人类选择的标准。对比于SumMe数据集,TvSum数据集在β值较大时获得最优的结果,即多样性的重要程度更高,这是因为TvSum的视频更长(如表1所示),可以获得更多内容更丰富的片段作为摘要。此外,SumMe数据集的视频大多是原始视频,即未经过编辑,存在大量冗余内容,因此选择代表性更高的片段更符合现实。

图8 奖励权重β对两个数据集性能的影响
当权重为0或1时,表示仅使用LRdiv或LRrep分别训练模型,作为本文模型对比的基线模型,分别用ALRSN_div和ALRSN_rep表示。表3显示了详细的训练结果。结果表明,将LRdiv和LRrep联合训练,比单独使用局部多样性奖励函数或局部代表性奖励函数训练模型结果更优,这表明联合训练可以更好地使ALRSN模型生成多样且有代表性的高质量视频摘要。值得注意的是,单独使用局部多样性函数的结果比单独使用局部代表性函数的结果更好,表明在这两个数据集上局部多样性的表现要好于局部代表性,模型更倾向于选择内容更丰富的片段作为摘要。
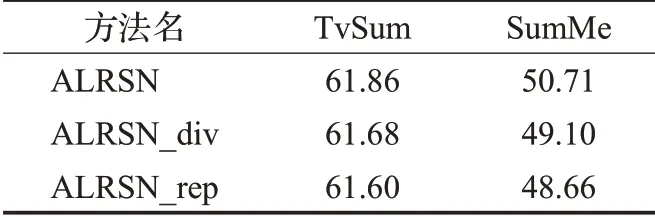
表3 基准模型训练结果对比%
3.3.2 局部范围λ
在本小节中,关注于视频摘要评估的范围大小对模型结果的影响,通过此方法可以有效地关注视频序列的时序关系。限制的多样性评估的范围为λ1,代表性的范围为λ2。在图9中可以清楚地看到,不同的局部奖励范围对模型结果的影响。图9(a)表示不同范围的局部多样性(λ1)和局部代表性范围(λ2=[10,20,30])对模型性能的影响,而图9(b)相反。结果表明,当局部多样性范围λ1设置为20且局部代表性范围λ2设置为10时,F值最高。这可能是因为使用KTS将视频分割成镜头时,每个镜头平均为10帧,则代表性评估范围在单个镜头内最高,这符合镜头分割的设想。而对于多样性评估范围,镜头内的变化比较平缓,至少在两个镜头内可以获得更高的多样性得分。考虑视频序列固有的时序关系,将整个视频限制在一定范围内以计算多样性和代表性,结果优于对应的全局奖励(范围设置为最大,λ为inf)。局部多样性是通过忽略两个时间相距遥远帧之间的相似性来保证故事情节。局部代表性可以确保在一定范围内所选择的视频帧与其他帧距离最小,相当于聚类的中心点,并且它代表视频的局部信息。考虑视频序列的局部信息,可以使模型注意到更多有用的信息。

图9 改变局部奖励函数的范围对模型结果的影响
4 结束语
在这项工作中,提出了一个基于自注意力机制和局部奖励机制视频摘要网络ALRSN。网络可以代替复杂的RNN的网络(例如具有LSTM的编码器-解码器模型),执行序列到序列的转换。实验结果表明,在有监督的视频摘要任务中,本文模型优于现有方法。此外,分析了数据增强、局部奖励权重和奖励范围对模型的影响。局部奖励函数包括局部多样性和局部代表性,它们共同引导模型选择更符合人类标签的视频摘要。鉴于本文的结果是可行的,提出了未来的研究方向。可以发展更复杂的注意力机制以探索视频中大量有用的信息。此外,情感分析是一个热门的方向,为视频摘要提供了更丰富的信息,这是未来将要考虑深入研究的方向。
猜你喜欢
河北科技大学学报(社会科学版)(2022年4期)2023-01-06
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
数学物理学报(2021年2期)2021-06-09
闽南风(2020年6期)2020-06-23
中国现代中药(2020年2期)2020-04-29
传媒评论(2017年3期)2017-06-13
——勉冲·罗布斯达
文化遗产(2017年2期)2017-04-22
第二课堂(课外活动版)(2016年2期)2016-10-21
发明与创新(2016年38期)2016-08-22
