
基于可见/近红外光谱和深度学习的早期鸭胚雌雄信息无损检测
2021-06-10 07:09李庆旭王巧华马美湖肖仕杰
光谱学与光谱分析 2021年6期
李庆旭, 王巧华, 2*, 马美湖, 肖仕杰, 施 行
1. 华中农业大学工学院, 湖北 武汉 430070 2. 农业部长江中下游农业装备重点实验室, 湖北 武汉 430070 3. 国家蛋品加工技术研发中心, 湖北 武汉 430070
引 言
我国是鸭蛋、 鸭肉消费大国, 而雏鸭孵化产业是鸭蛋、 鸭肉生产的重要保障。 在鸭蛋生产行业雌性的需求量更大; 而在肉鸭培育产业中, 雄性因其生长速度快, 养殖行业更倾向于养殖雄性。 若能在鸭蛋孵化早期根据需求控制雌雄比例, 不仅可以降低孵化成本, 也可以极大地提高养殖行业的经济效益。 因此, 开发一种高效、 无损的早期鸭胚胎性别检测方法, 对于提升整个鸭养殖行业的经济效益具有重要意义。
在国内外已有的文献记载中, 大都针对鸡蛋胚胎进行雌雄鉴别研究, 主要研究手段有机器视觉、 光谱和破损检测等。 唐剑林等[1]利用光照对孵化3 d的鸡胚胎进行性别鉴定, 发现雌性胚胎与雄性胚胎的血管分布有所区别。 祝志慧等[2]利用机器视觉技术根据孵化4 d鸡胚的血线特征鉴别雌雄。 潘磊庆等[3]利用高光谱成像技术实现了对孵化10 d的鸡胚性别的判别, 祝志慧等[4]利用紫外-可见光谱发现鸡胚在孵化7 d时可以进行雌雄判别。 以上为无损鉴别手段, Weiss-mann等[5]利用孵化9 d鸡胚的尿囊液中的硫酸雌酮含量的差异进行性别判定。 Turkyilmaz等[6]利用PCR 技术鉴别孵化5~7 d的鸡胚性别。 此外, 通过微创手段采集鸡胚的拉曼和荧光光谱也可以实现鸡胚雌雄的检测[7-8]。
鸡蛋与鸭蛋相比, 饲养方式和孵化周期均有所区别, 有关鸡胚性别研究对鸭种蛋具有一定借鉴意义。 纵观以上前人研究, 发现有损检测方式虽然检测精度较高, 但耗时长、 效率低下, 不适用于生产实际; 高光谱技术价格昂贵且效率低; 机器视觉技术虽然检测效率较高, 但检测精度低。 可见/近红外光谱技术是一种高效、 快速的无损检测方法, 目前广泛应用于农产品的无损检测, 光源能够透过鸭蛋的蛋壳被内部物质吸收, 可以将鸭蛋内部信息反映在光谱图上。 为此, 本文采用可见/近红外光谱技术对孵化早期鸭胚进行雌雄鉴别研究。
1 实验部分
1.1 材料与仪器
试验材料为新鲜生产的国绍一号麻鸭种蛋345枚, 产自江西上饶。 用酒精对种鸭蛋表面进行擦拭消毒, 待鸭蛋晾干后进行编号。
试验仪器包括可见/近红外透射光谱采集系统和智能孵化箱。 可见/近红外透射光谱采集系统如图1所示, 由Maya2000Pro光纤光谱仪、 150 W光源(输出波长范围为360~2 000 nm)、 暗箱、 聚焦透镜、 84UV准直透镜、 计算机和玻璃光纤等组成。 采集的光谱波长范围为200~1 100 nm, 采样间隔为0.5 nm。
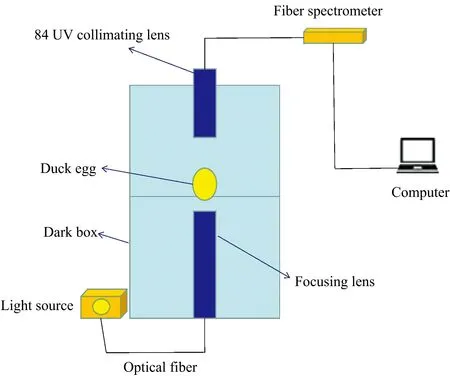
图1 光谱采集系统
1.2 方法
1.2.1 光谱采集
将清洗消毒后的种鸭蛋置入智能孵化箱中孵化, 分别在孵化前以及入孵之后每间隔24 h采集一次光谱信息, 采集0~8 d共9 d的光谱信息。 利用可见/近红外透射光谱信息采集系统对种鸭蛋进行透射光谱采集, 采集光谱时将种蛋竖直放置, 钝端向上。 由于孵化7d的种鸭蛋透射难度较大, 将光谱仪的采集积分时间设定为700 ms, 扫描次数设定为1。
1.2.2 雌雄胚胎人工判别
种鸭蛋在孵化过程中性腺开始转换为卵巢或睾丸, 在孵化后期可以通过睾丸和卵巢的形态进行性别鉴定, 雌性胚胎的卵巢两侧发育不对称, 而雄性胚胎的两侧睾丸则对称发育[9]。 为获得种鸭蛋的雌雄对比结果, 在种鸭蛋孵化20 d后将其破壳并对鸭胚胎进行解剖处理, 人眼观察其性别。 图2为孵化20 d后的鸭胚胎解剖图, 图2(a)为雄性胚胎, 图2(b)为雌性胚胎。

图2 鸭胚胎解剖图
2 结果与讨论
2.1 样本集划分
为了避免随机划分样本集带来的样本分布不均衡, 利用Kennard-Stone算法对样本集进行划分。 将变量空间中相对欧几里德距离相差较大的样本选入训练集, 其余样本选入开发集[10], 其中开发集和训练集的划分比例为3∶7。 为了进一步验证模型的性能, 从开发集中随机选出30%的样本作为测试集。 本试验共345个样本数据, 按照上述方法划分后, 训练集样本个数为242(雌性119, 雄性123)、 开发集为72(雌性36, 雄性36)、 测试集为31(雌性15, 雄性16)。
2.2 光谱预处理
获得的原始光谱数据如图3, 由于光源的波长范围是360~2 000 nm, 所以光谱仪采集的200~360 nm之间的光谱信息是噪声数据, 需要去除。 此外由于温度和操作环境等因素的影响, 导致360~500和900~1 100 nm波长范围内光谱信息波动较大, 含有大量的噪声数据, 若直接选用全光谱用于后续的分析与处理, 会导致模型不可靠, 泛化能力变差。 因此, 本文选用500~900 nm波长范围内的光谱信息进行相关分析。 截取后的谱区范围如图4所示。 考虑后续方便部署至生产实际, 不对光谱数据再进行其他预处理, 直接对截取后的光谱数据进行分析处理。
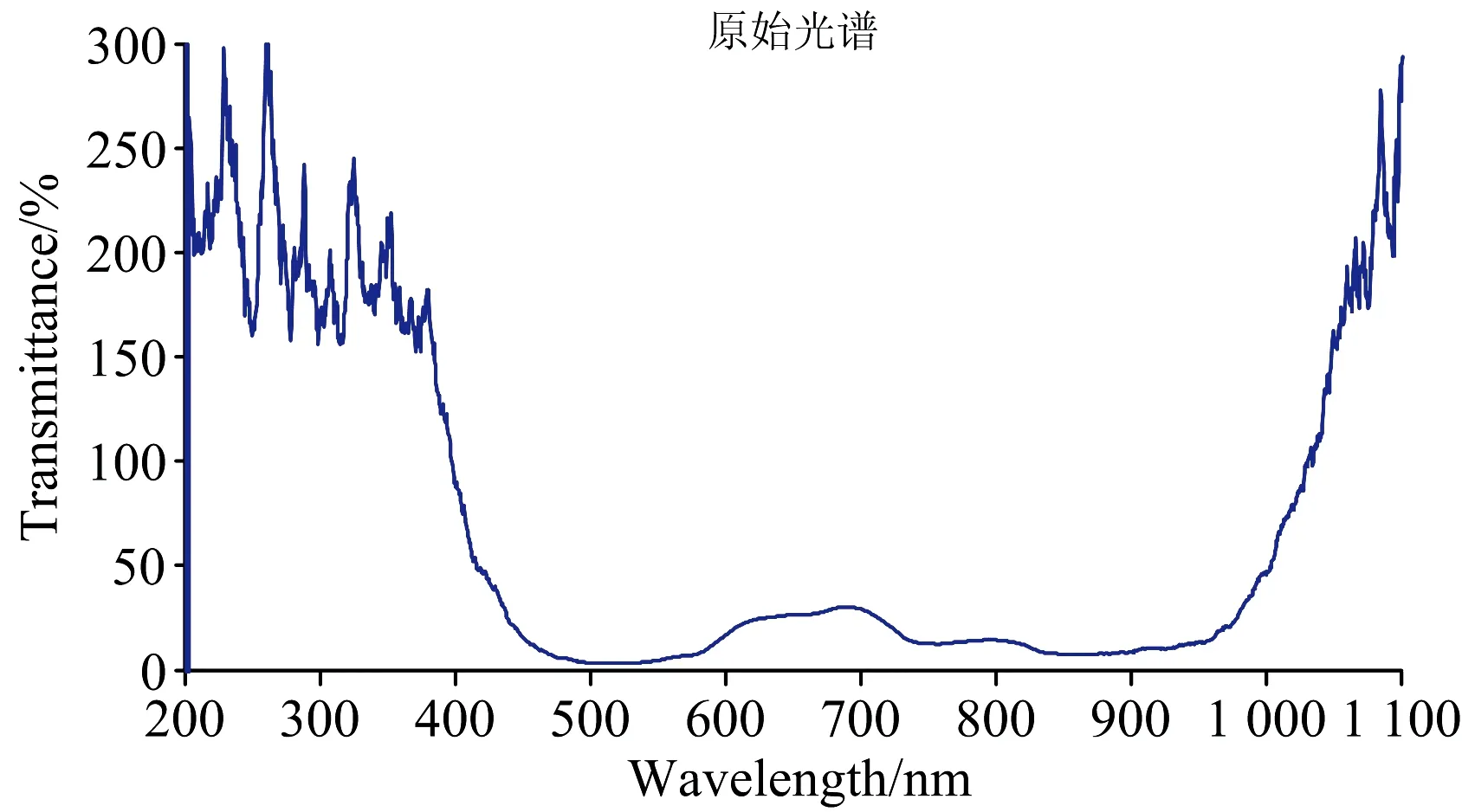
图3 原始光谱图

图4 500~900 nm光谱图
2.3 光谱特征波长选取
截取后的光谱数据高达908维, 一些波段之间依然存在着较强的相关性, 高维的光谱信息中包含了大量的冗余信息, 若直接使用高维光谱数据建立判别模型会导致模型出现过拟合现象。 此外在使用高维光谱数据建立机器学习或深度学习模型时, 由于输入信息过多会严重影响模型的训练速度, 而且训练得到的模型参数量过大, 不利于后续模型的部署。 为此, 本文使用CARS算法、 SPA算法和GA算法分别对截取后的光谱数据进行特征波长选择, 找出能够区分雌性鸭胚和雄性鸭胚的波长点集。
(1)竞争性自适应重加权(CARS)算法是一种利用自适应重加权采样方法筛选PLS模型中回归系数绝对值相对较大的波长点, 剔除权重比较小的波长点, 通过交叉验证方法选择出RMSECV值最低的子集, 可以有效地找出变量的最佳组合。 使用CARS对截取噪声后的训练集光谱数据进行特征波长选择, 选取孵化7d的鸭胚雌雄信息预测的最优波长点集过程如下: 经反复对比, 本研究把蒙特卡罗采样次数设置为100, 使用10折交叉验证。 由图5(a)可以看出, 随着取样操作次数的增加, 选取的特征波长点的数目逐步减少 。 从图5(b)可知, RMSECV值首先变化平缓, 然后递减, 最后再递增, 当RMSECV值减小时说明光谱数据中的一些无用的信息被剔除, 当RMSECV值递增时说明光谱数据中一些重要信息被剔除。 当RMSECV值达到最小时, 各变量的回归系数如图5(c)中的竖线处, 采样运行次数为75, CARS选取的最优波长点数为11个。
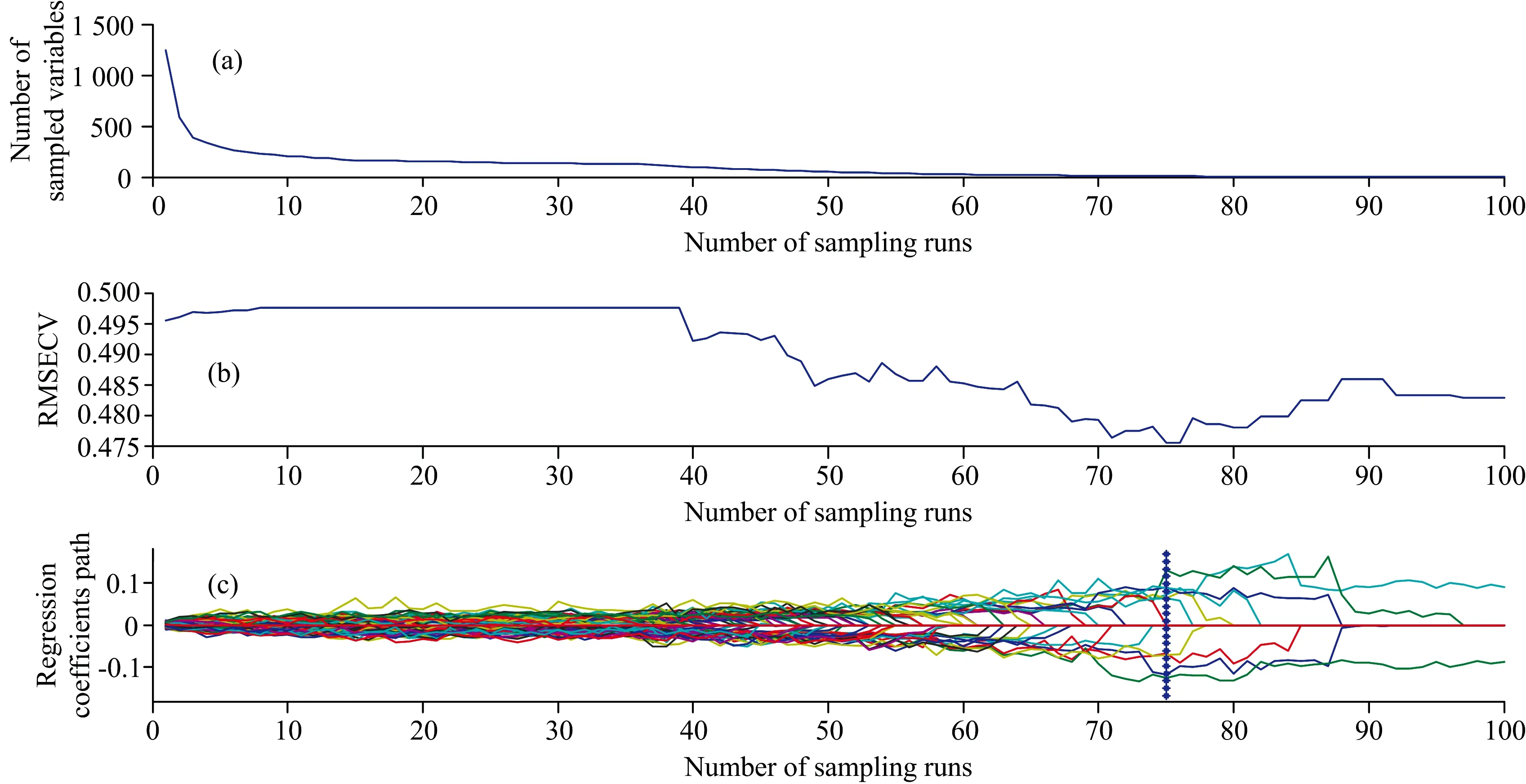
图5 (a)取样变量数; (b)RMSECV; (c)回归系数路径
(2)连续投影算法( SPA) 是使向量空间共线性最小化的前向变量选择算法, 可以消除高维光谱数据中的冗余信息, 可解决共线性问题。 SPA用于选取截取后的训练集光谱数据的特征波长点时, 根据SPA的原理可知, 利用均方根误差(RMSE)最小化原则选出均方根误差的导数变小的过渡点, 在过渡点之前冗余信息被剔除。 SPA选取孵化7 d的鸭胚雌雄信息预测最优波长点集如图6所示, SPA选取的特征波长个数为10, 均分布在可见光范围内。

图6 (a)RMSE; (b)选取的最优波长编号索引
(3)遗传算法(GA)模仿生物界进化遗传机制, 利用选择、 交叉与变异进行编码, 并通过不断地迭代去逼近全局最优解[11]。 本试验运用GA算法进行特征波长选取时, 设定初始群体数量为80、 交叉率为0.5、 变异率为 0.01、 迭代次数为100。 以最小的RMSECV值为标准, 挑选出在迭代过程中出现频率较多的波长点为特征波长点, 如图7所示, 最后选取了分布在可见光与近红外波段的30个特征波长点。

图7 (a)GA筛选图; (b)RMSECV变化图
2.4 卷积神经网络搭建
卷积神经网络被广泛应用于图像识别与检测, 处理分类问题时具有独特的优势。 高维光谱信息经过特征波长提取后, 均降到较低维度。 降维后的光谱信息为1×n的一维光谱矩阵(n表示特征波长点数), 为了方便将光谱数据传递给卷积神经网络, 本文将一维光谱信息转换为二维光谱信息矩阵[12], 转换公式如式(1)。 二维光谱信息矩阵不仅包含了一维光谱数据中的原有信息, 还体现了样本的方差和协方差, 同时能够适应卷积神经网络的结构。
S=XTX
(1)
式(1)中,X代表一维光谱数据,XT为一维光谱数据的转置。 以SPA提取特征波长后的光谱信息为例, 单个鸭胚样本的一维光谱数据为x=[x1,x2,…,x10], 二维光谱信息矩阵如式(2)
(2)
使用GA, CARS和SPA提取特征波长转换的二维光谱信息矩阵, 尺寸较小, GA为30×30、 SPA为10×10、 CARS为11×11。 若搭建的卷积神经网络层数过多会导致网络出现过拟合现象, 模型的泛化能力变差。 考虑到孵化7d鸭胚二维光谱信息矩阵的特点, 经反复尝试, 搭建了层数为6的卷积神经网络, 包括输入层(Inputs)、 3个卷积层(conv1, conv2, conv3)、 全连接层(FC)以及输出层(Output), 卷积神经网络的结构如图8所示, 具体实现过程如下(以GA提取的孵化7d鸭胚光谱信息特征波长为例, 其他的与之结构相同):
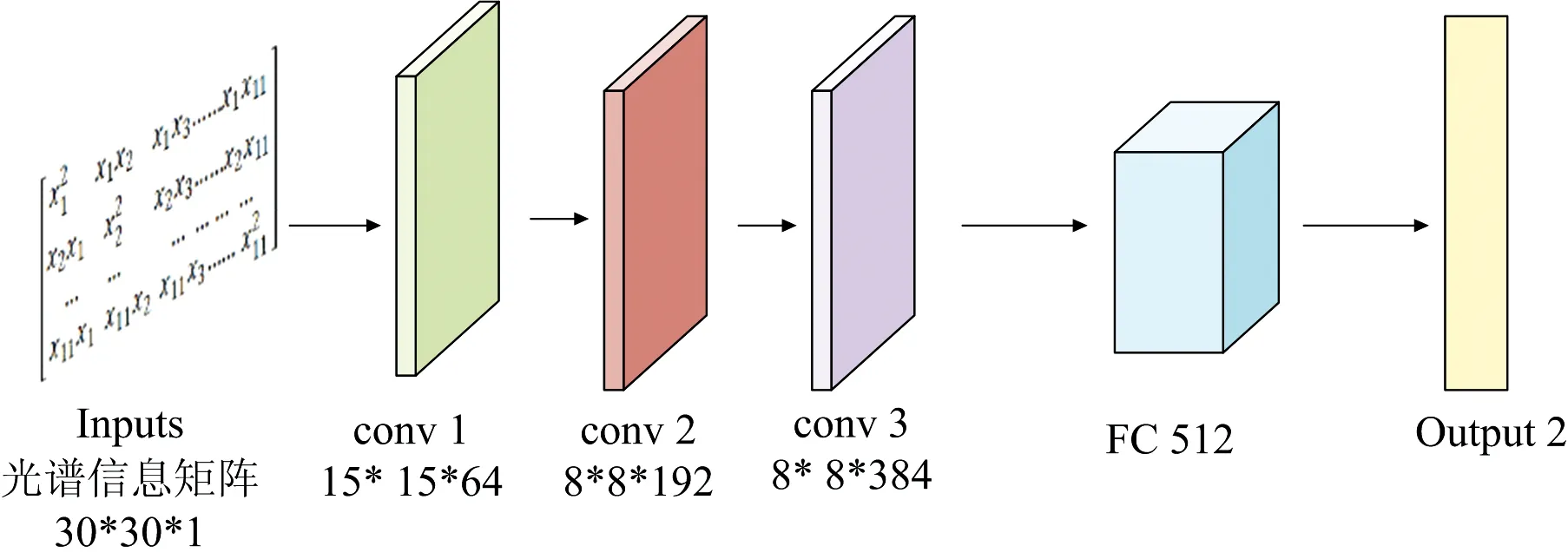
图8 卷积神经网络结构
(1)输入层(Inputs): 将GA提取的孵化7 d鸭胚光谱信息特征波长使用式(1)转为二维光谱信息矩阵作为卷积神经网络的输入, 输入层尺寸为30×30×1;
(2)卷积层1(conv1): 卷积核尺寸设置为3×3, 卷积核的个数设定为64, 步长设置成1。 输入层经过卷积操作后使用ReLU函数进行激活, 为了提高模型的性能, 在ReLU激活后的光谱特征矩阵进行局部响应归一化(LRN)操作, 经过卷积操作后的特征矩阵尺寸为30×30×64输出至pool1;
(3)池化层1(pool1): 将池化核的大小设置为2, 池化处理后的特征矩阵大小为15×15×64, 输出至conv2;
(4)卷积层2(conv2): 卷积核的尺寸为1×1, 卷积核的数量为192, 步长设置为1。 pool1的输出经过卷积操作后, 再进行LRN操作和ReLU激活, 特征矩阵大小为8×8×192, 输出至conv3;
(5)卷积层3(conv3): 卷积核尺寸为1×1, 卷积核个数为384, 步长为1。 conv2的输出经过卷积后, 加入ReLU和LRN操作后输出尺寸为8×8×384, 输出至FC;
(6)全连接层(FC): 全连接层中的神经元数目设置512个, 卷积层3输出的光谱特征矩阵被转化成1×24 576的数据, 输入给512个全连接的神经元, 然后输出512个权值, 为了防止模型出现过拟合现象, 在输出之前通过dropout层随机地失活一些神经元。
(7)输出层(Output): 将全连接层的512个权值经过softmax函数分别得到雌性胚胎和雄性胚胎的得分系数。
2.5 卷积神经网络训练与测试
本试验利用采集得到的345个孵化7 d的鸭胚光谱数据对搭建好的卷积神经网络进行训练。 卷积神经网络往往需要大量的训练数据才能取得较理想的训练结果, 本文利用光谱对孵化7 d的鸭胚进行雌雄二分类, 采集得到的分类样本数量已经足够。 在训练过程中, 利用Adam优化器寻找最优的梯度下降方向, 可以加快模型的收敛。 均值平方差被用作损失(loss)函数来计算预测值与实际值之间的差值。 初始学习率(LearningRate)设为10-4, 每次选取4个样本训练(BatchSize=4), dropout参数设置为0.5, 当迭代次数达到20 000后终止训练。 训练过程中的损失函数变化如图9, 可以发现SPA选取的特征波长分类损失loss在训练的前5 000次一直处于快速下降状态, 迭代到9 000次后loss一直维持在较低水平, 说明模型达到收敛。 CARS和GA选取的特征波长训练过程中loss值也为先快速下降后维持在较低水平, 但最终的损失值均比SPA选取的特征波长高。 从三者的loss曲线变化情况可以发现, 模型均未出现欠拟合现象。

图9 损失函数变化曲线
在模型训练20 000次后对其进行保存, 后将训练集, 开发集与测试集共345个鸭胚样本的二维光谱信息矩阵传递给训练好的模型对其性能进行验证。 测试结果如表1所示, 其中SPA提取的特征波长转换为二维信息矩阵后, 使用搭建的6层卷积神经网络建立的孵化早期种鸭蛋雌雄信息判别模型性能最佳, 在测试集中的性能与训练集的性能相当, 这表明模型并不存在过拟合或欠拟合。 GA提取的特征波长转换为二维信息矩阵后建立的卷积神经网络性能次之, CARS提取的特征波长建立的卷积神经网络在训练集上的表现明显高于测试集, 出现了轻微的过拟合现象。

表1 模型测试结果
3 结 论
以孵化7 d的种鸭蛋为研究对象, 利用可见/近红外透射光谱与卷积神经网络的技术手段探究了孵化早期鸭胚性别无损鉴别技术, 得到如下结论:
(1)通过对孵化7 d的鸭胚透射光谱信息的分析, 发现其有效信息集中在500~900 nm的波长范围内; 考虑后续将其应用于生产实际, 不再对其作其他预处理, 直接利用SPA, CARS与GA三种常用的特征波长选取算法, 将选定的特征波长点集转换成二维光谱信息矩阵, 利用卷积神经网络搭建判别模型, 不仅实现了光谱数据维数的降低, 避免了因为维度灾难而需要大量的实验样本, 同时适用于卷积神经网络的训练;
(2)利用SPA选择特征波长点集后并将其转换为二维光谱信息矩阵建立的卷积神经网络判别模型效果最好, 训练集、 开发集和测试集的准确率分为达到93.36%, 93.12%和93.83%; 说明用可见/近红外透射光谱结合卷积神经网络对孵化早期种鸭蛋性别信息的无损检测具有可行性, 能够满足实际生产的精度要求, 为相应检测装置的研发提供模型支撑;
(3)本文使用传统的光谱处理手段后, 将光谱信息转换为二维光谱信息矩阵, 为卷积神经网络和光谱信息找到了结合点。
猜你喜欢
特产研究(2022年6期)2023-01-17
小学生学习指导(中年级)(2022年6期)2022-11-23
江苏农业科学(2019年6期)2019-09-25
绿色科技(2017年20期)2017-11-10
实用口腔医学杂志(2017年6期)2017-09-19
中国管理信息化(2017年5期)2017-06-22
红领巾·萌芽(2017年3期)2017-05-03
科技知识动漫(2017年4期)2017-04-15
中国照明(2016年4期)2016-05-17
软件导刊(2015年1期)2015-03-02
