
基于卷积神经网络的图像分类及应用*
2021-06-09 09:00高嘉平司耸涛
电子与封装 2021年5期
王 彬,高嘉平,司耸涛
(中科芯集成电路有限公司,江苏无锡 214072)
1 引言
近年来,深度学习在图像检测方面被广泛应用,但现有的图像检测都是对特定识别目标的各种状态图像进行大量的深度学习模型训练,该模型通用性不强[1-2],若更换检测目标,需要进行新的模型训练,不仅费时费力,同时上述过程需要对深度学习有一定的了解,这也增加了模型的使用门槛[3-5]。因此本研究将深度学习在图像检测的过程进行简化,只需简单记录目标状态就能使模型微调成该目标的检测模型。首先利用深度学习对图像进行分类[6],使用网上图像分类的数据库对网络进行训练,再运用检测目标少量的各种状态目标的数据集去微调生成迁移学习模型,模型就可以对目标进行检测。迁移学习模型可以在原有模型的误差和精确度不变的情况下[7]实现对现有目标的检测,同时目标数据集微调生成学习迁移模型的过程可通过前期软件编程完成,简化采集数据集和训练模型的复杂程度。
本文运用该方法设计一个报警系统,该报警系统只需要通过相机采集目标各种状态的图像就能对目标进行检测,极大地简化了深度学习在目标检测中的应用,同时更换检测目标也较为方便。系统的硬件部分由相机、CNN加速芯片和嵌入式系统组成。为了满足系统在实际应用场景中的稳定性和准确率,本研究先在Imagenet数据集训练生成预训练模型,然后根据实际需求制作了新的数据集,即通过记录检测目标的不同应用场景中的各个状态生成数据集,然后用生成的数据集去微调已经训练过的图像分类模型,生成新的针对该目标的图像分类模型。
2 图像分类及检测算法基本原理
2.1 卷积神经网络模型选择
选择基于GoogLeNet模型来搭建本次研究的模型。深度学习GoogLeNet模型采用的是卷积神经网络框架Inception v1架构[8]。该架构的优势是当在计算复杂度不高和计算爆炸不受控制时,可以通过增加每个阶段的单元数目,增加网络的宽度和深度;同时Inception v1结构也和图像在进行多尺度处理之后,将图像处理结果汇总为下一个阶段能同时提取不同图像尺寸下的特征过程相类似,其框架结构如图1所示。它由一个1×1卷积层、一个中等大小的3×3卷积层、一个大型的5×5卷积层、一个最大池化层构成。1×1卷积层能够提取输入该层图像的每一个细节中的信息特征,同时5×5的卷积层也能够覆盖大部分前面图像的输入信息,进而能提取图像的信息特征。可以进行池化操作来减少输入图像映射维度的大小,降低过度拟合情况。此外在每一个卷积层后都添加了一个修正线性单元(ReLU),其作用是改善网络的非线性特征。

图1 Inception v1结构
2.2 网络模型结构
基于卷积神经网络GoogLeNet模型结构建立本次实验的图像分类模型并优化网络模型结构,如图2所示。

图2 卷积神经网络的整体结构
在训练模型之前先要确定如下几个参数。
分类器选择:Softmax分类器是归一化概率分类。Softmax分类器可以将模型的结果在(0,1)内反映出来,并且所有结果相加等于1,如式(1)所示。
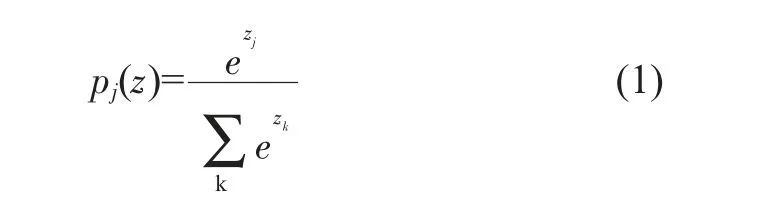
其中Zj为向量Z的第j个元素,Pj为向量Z的第j个元素的Softmax值。
损失函数:用来描述模型的理论值与实际值的差距程度,一般情况下,损失函数值越小说明模型的测试结果更能反映实际值。本文的损失函数选用Softmax loss函数,如式(2)所示。

其中,W为网络的权值矩阵,b为偏移量,y为实际测试结果,pj(z)为分类器输出结果。
Dropout正则化:主要用于权重衰减,这样可以解决Softmax分类器带来的参数冗余的数值问题,同时可以使模型泛化性更强,加入Dropout正则化的网络计算公式如式(3)~(6)所示。

从公式(3)~(6)中可以看出函数随机生成一个参数为0或1的概率向量,然后再乘入权重参数中,由于公式里的参数是随机的0或1,所以会有部分的权重失效,从而解决过拟合的问题。
优化算法:为了节省计算资源和计算时间,加入随机梯度下降法(SGD)[10],该方法用较少的数据即可实现对训练模型的更新,同时为了使学习速度提升,将引入动量参数,如式(7)、(8)所示。

公式(7)、(8)中,vt初始值为0,β一般取值0.9,α为网络学习率,J(θ)为损失函数。
3 训练模型设计及分析
根据设定的网络结构及选用的参数对网络进行训练,使用Caffe深度学习库的函数式模型完成整体网络结构的搭建,同时将α设置为0.01,选择SGD来减少计算资源和计算时间。对数据进行近10000次迭代训练后,通过对网络参数的不断调整建立了网络模型。模型训练后,得到train loss、test loss和accuracy 3个参数的随机迭代次数变化曲线,最终得到训练模型整体网络性能评估,如图3所示。
不难看出,迭代次数越多,模型的准确度accuracy越高,trainloss和test loss越低。在迭代5000次左右后准确度就趋近于1,train loss和test loss也不断趋近于0。该结果表明,模型的稳健性较好,并且其性能满足应用需求。
为了检验CNN模型对检测目标状态图像分类的迁移学习效果,将采用分类的准确率对模型进行评估,准确率(A)由分类准确目标状态次数和测试目标状态总次数之比得出,如式(9)所示。

图3 训练模型整体网络性能评估

其中,Nacc为分类准确目标状态的次数,Nall为测试目标状态的总次数。
将训练好的模型转换后放入CNN加速芯片中,然后对目标各种状态进行图像采集,经过裁剪旋转等方法后得到检测目标每个状态1000张图像。将图像大小统一处理成224×224×3分辨率的图像并进行状态标记得到数据集,将得到的数据集去更新生成新模型后,测试模型的准确率。实验测试是检测小灯亮灭的两个不同状态,经处理后得到两个状态各1000张标记好的图片。然后从两个不同状态的图片中随机抽取数量相同的图片作为数据集,最后在200、300、400、500、600、900张图片数量的数据集下测试检测目标状态的准确率。表1显示该模型在不同数量数据集下测试目标状态的准确率。
从表1数据可以看出,随着检测目标数据集的数量逐渐增大,该模型检测目标的准确率大大改善,同时数据集的数量达到900时,模型的准确率接近99.9%,表明该模型有着较高的准确度。在制作数据集时,本研究已经尽可能多地考虑到了使用场景的多样性和复杂性,所以只需根据具体的应用场景对模型进行微调即可。

表1 不同数量数据集的检测准确率
4 嵌入式报警系统设计
4.1 网络模型结构
我们设计了一个基于深度学习卷积神经网络的图像检测报警系统。系统整体框架如图4所示。其中CNN加速芯片采用的是Xilinx公司的XCKU115板卡,嵌入式系统以CKS32F103作为主控芯片。

图4 嵌入式报警系统框架
相机先采集目标各个状态的图像,进行标记分类后生成数据集储存到嵌入式系统的存储器中,在嵌入式系统中设置报警图像类型,然后将分类好的数据集去微调已经训练好的深度学习卷积神经网络图像分类模型,生成新的图像分类模型;完成系统的初步设置后就能进行检测目标的实时图像检测,相机实时检测目标状态,把实时影像传输到新生成的模型中,完成影像的分类,并把结果实时返回到嵌入式系统中;当嵌入式系统读取到目标图像类型后,对比设置报警图像类型,如果图像类型一致,嵌入式系统启动蜂鸣器程序开始报警。
由于卷积神经网络模型对输入图片的格式有严格要求,因此需要对相机输入的图片进行预处理,主要对图片的3个参数进行调整:IMAGE_DIM、IMAGE_STDDEV和IMAGE_MEAN。见表2。由于本次算法对预处理要求较高,故采用python工具包处理。

表2 输入图像参数
4.2 系统响应设计
嵌入式系统的主要工作是设置需要报警的图像类型,同时与网络模型反馈的图像类型分别进行对比,当二者一致时,它将驱动报警系统进行报警,驱动流程如图5所示。为了降低因图像类型误判引起错误报警的概率,系统做了如下处理:当返回的检测结果概率不低于0.7,并且处于报警图像类型连续大于20帧时才会启动警报程序,以减少错误警报的概率。

图5 嵌入式系统报警流程
4.3 系统测试分析
本文以LED灯为检测目标,检测LED灯的亮灭状态。LED灯亮表示报警状态图像类型1,LED灯熄灭表示正常状态图像类型2。搭建好测试平台后,相机对LED灯两个状态进行记录,记录完成后生成数据集,更新生成图像分类模型,然后再用相机去拍摄LED灯,可以看到如图6所示的画面,整个系统一直在实时检测LED灯状态。
从图6可知,系统实时地将每帧图像的LED灯是亮还是灭的概率呈现于显示器中,取出现概率最大的状态为当前LED灯所处状态,并在每帧图像上显示出图像类型。亮灯时显示的是1,灭灯时显示为2。然后将显示的类型及对应的概率发送到嵌入式系统中,连续20帧且概率不低于0.7后,若反馈的信号是类型1,蜂鸣器就开始鸣响。经多次试验测试,本系统能够实时、准确地完成对图像数据的获取、检测、分类和响应。
5 结论
本研究能快速且简单地完成对检测目标模型的生成和检测,同时所设计的报警系统只需较少的检测目标数据就能生成新的模型。最终结果表明,在简单场景下,该系统对图像检测的准确度可以达到99.9%。同时在更换检测目标时,只需要简单使用相机记录检测目标各个状态图片,自动形成新数据集然后生成新的模型,即可实现对检测目标的图像分类。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
铁道通信信号(2018年5期)2018-06-28
北京航空航天大学学报(2018年1期)2018-04-20
铁道通信信号(2018年2期)2018-04-18
电镀与环保(2016年3期)2017-01-20
汽车维护与修理(2016年10期)2016-07-10
小学生·多元智能大王(2015年3期)2015-05-25
汽车维护与修理(2015年6期)2015-02-28
电视技术(2014年19期)2014-03-11
