
高速公路突发事件实体识别及事件分类联合模型研究
2021-06-08 12:30范晓武葛嘉恒
计算机时代 2021年1期
范晓武 葛嘉恒

摘 要: 针对高速公路突发事件实体识别和事件分类任务中文本表征时存在的一词多义问题,提出使用层次多头注意力网络HMAN来学习文本字向量的高层次特征表示,结合经典的BiLSTM-CRF模型,构建一个称为HMAN-BiLSTM-CRF的多任务联合学习模型。模型共享文本特征表示模块,使用CRF对共享表征进行解码获得最优实体标注序列,而全连接层则根据输入的文本特征预测事件类别。在FEIC数据集上的实验结果显示,本文所提出的HMAN-BiLSTM-CRF在突发事件实体识别和分类两项任务中都优于其他对比模型。
关键词: 实体识别; 事件分类; 层次多头注意力网络; HMAN-BiLSTM-CRF模型
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2021)01-11-05
Research on the joint model of entity recognition and event
classification of freeway emergency
Fan Xiaowu, Ge Jiaheng
(Zhejiang Comprehensive Transportation Big Data Center Co., Ltd., Hangzhou, Zhejiang 310018, China)
Abstract: Aiming at the polysemy problem in text representation in freeway emergency entity recognition and event classification tasks, this paper proposes to use a hierarchical multi-head self-attention network to learn high-level feature representations of text word vectors, and combines with the classic BiLSTM-CRF Model to construct a multi-task joint learning model called HMAN-BiLSTM-CRF. The model shares the text feature representation module, and uses CRF to decode the shared representation to obtain the optimal entity annotation sequence. Meanwhile, the fully connected layer predicts the event category according to the input text feature. The experimental results on the FEIC data set show that the HMAN-BiLSTM-CRF proposed in this paper is superior to other comparison models in the two tasks of emergency entity recognition and classification.
Key words: entity recognition; event classification; hierarchical multi-head self-attention network; HMAN-BiLSTM-CRF model
0 引言
隨着我国高速公路建设规模的不断增长与道路交通量的快速增加,交通事故、恶劣天气、道路拥堵,以及危化品泄露等高速公路突发事件日益增长,严重影响高速公路的通行能力和运营效率。当高速公路突发事件发生后,交通应急指挥部门应根据报警信息快速定位事故点,调配应急救援物资并制定最佳救援路径,使高速公路能够迅速恢复平稳通行。在整个应急救援实施的过程中,精确确定事发点并分析出事件类别是应急救援能够正确、顺利开展的关键。然而,突发事件报警信息大多以语义来表述事发地理位置和事件情况,如何识别出突发事件位置等实体信息并对事件进行分类是亟待解决的问题,两者本质上是自然语言处理领域的经典任务:命名实体识别和文本分类。
目前,国内外对特定领域实体识别的研究已有很多,研究方法主要包括基于规则的方法[1]、基于统计机器学习的方法[2]以及基于深度神经网络的方法。将深度神经网络与条件随机场(Conditional Random Field,CRF)相结合的模型取得了比较有竞争力的结果,此类模型先利用神经网络自动提取文本特征,再通过CRF进行实体标签预测。比如,Xu等人[3]提出将双向长短时记忆网络(Bi-directional Long Short-Term Memory neural network,BiLSTM)与CRF结合起来构建基于BiLSTM-CRF的模型,在NCBI疾病语料库上取得了80.22% 的F1值;李等人[4]在BiLSTM-CRF模型的基础上融入了卷积神经网络(Convolutional Neural Network,CNN)训练字符级向量,提出了CNN-BLSTM-CRF模型进行生物医学命名实体识别,在Biocreative II GM和JNLPBA 2004数据集上的F1值分别达到了89.09%和74.40%。张等人[5]将生成式对抗网络(Generative Adversarial Network, GAN)与基于注意力机制的BiLSTM-CRF模型相结合,构建了一种新的实体识别模型BiLSTM-Attention-CRF-Crowd,在信息安全领域的众包标注数据集上取得了较高的F1值87.2%。
高速突发事件分类是指根据事件的起因、影响等因素将其归类到某个类别中,属于文本分类任务中的单标签多分类问题。文本分类的核心是文本特征表示,基于深度神经网络的方法在此方面表现出很好的性能成为了研究的主流模型。先前的研究大多使用基于CNN[6]或基于循环神经网路(Recurrent Neural Network,RNN)[7-8]的单一神经网络模型处理文本分类问题,但受限于网络结构,这两类模型在提取文本特征时具有一定的局限性。最近研究者尝试将不同的神经网络结合起来以利用他们的优点,取得了非常显著的研究进展。Zhang等人[9]提出了一个结合CNN和LSTM的情感分类模型CNN-LSTM的,模型首先使用CNN提取文本序列的局部N-Gram特征,然后通过LSTM学习文本的语义表示并输出分类结果。Li等人[10]提出的BLSTM-C模型利用BiLSTM从正向和逆向同时处理输入序列,获取能够捕捉双向语义依赖的文本表示,并输入到CNN进行特征提取和分类。
实体识别和文本分类通常被视为两个不同的任务独立进行,但实际上这两个任务是相关的,两者可以共享底层的文本特征表示,进行联合训练。目前,多任务联合学习模型已被广泛应用。Wu等人[11]提出使用CNN-LSTM-CRF模型来进行命名实体识别任务和分词任务的联合学习,提高了识别实体边界的准确率。Zhang等人[12]提出了CNN-BiLSTM-CRF模型来识别实体及其关系,使两个任务的效果都得到了提升,达到了联合处理的目的。这两个模型都使用CNN来训练高层次字符向量,但CNN只能提取文本序列的局部特征,无法捕捉长距离依赖关系。
受Vaswani等人[13]在机器翻译中提出的Transformer网络结构的启发,本文提出使用层次多头自注意力网络HMAN(Hierarchical Multi-head Self-attention Network)来训练字符特征向量,自注意力网络能够直接建立文本序列中不同位置之间的关系,所以使用层次多头自注意力网络训练出的字符特征向量具有全局语义信息,从而解决了突发事件文本特征表示时存在的一字多义问题。
本文提出了一个多任务联合模型同时完成高速突发事件实体识别和事件分类任务,该模型将层次多头自注意力网络HMAN和BiLSTM相结合来学习输入文本的共享表征,并输入到CRF和全连接网络分别进行实体识别和事件分类,从而构建出一个称为HMAN-BiLSTM-CRF的联合学习模型。在高速突发事件语料库上的实验结果表明,与其他对比基线模型相比,HMAN-BiLSTM-CRF模型在各评价指标上都有显著提升。
1 数据预处理与数据标注
本文实验所使用的数据由杭州市高速公路管理相关部门提供,我们对其进行了预处理和实体分类标注,从而建立了一个基于实体识别和事件分类的高速突发事件语料库FEIC。这个数据集中包含15937个用于训练的突发事件示例、2601个用于验证的突发事件示例以及3985个用于测试的突发事件示例。
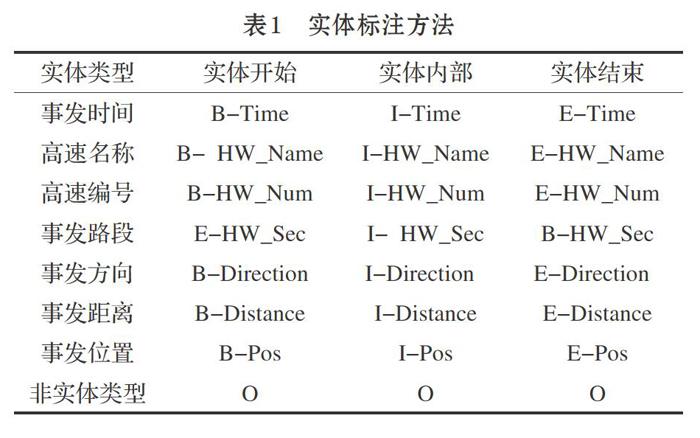
本文采用人工标注方式对高速突发事件实体进行标注。为了更加清晰地划分实体边界,在对高速突发事件语料进行实体标注时采用BIEO(Begin,Inside,End,Outside)标签方案。B表示高速突发事件实体的第一个字符,I表示实体的内部字符,E表示实体的结尾字符,O表示非实体字符。表1展示了实体类型及其具体标注方法。给定一个含有n个字符的高速突发事件文本句子[S={w1,w2,…,wn}],
采用上述标注方法标记句子[S]的每个字符[wi]。同时,本文将高速公路突发事件进行了分类标注,每个类别的数据分布情况如表2所示。
2 HMAN-BiLSTM-CRF模型
2.1 模型概述
HMAN-BiLSTM-CRF模型的结构如图1所示,包括字符编码层、HMAN层、BiLSTM层、CRF层以及FNN层。模型首先将输入的文本序列随机初始化为高维度数值向量矩阵,然后使用HMAN训练字符向量的高层次特征表示,并输入到BiLSTM提取文本的上下文特征,最后,CRF层对BiLSTM层输出的共享表征进行解码获得实体标记序列,全连接层的作用是对事件进行分类。
2.2 字符编码层
模型的第一层是字符嵌入层,目的是将输入的文本句子映射为高维度数值向量序列。假设输入的突发事件文本句子为[S={w1,w2,…,wn}],本文使用随机初始化的嵌入矩阵将每个字符[wi ]表示为字符向量[xi∈Rd],[d]为字符向量的维度,那么整个输入文本句子可被表示为[ X0=[x1,x2,…,xn]∈Rd×n]。
2.3 HMAN层
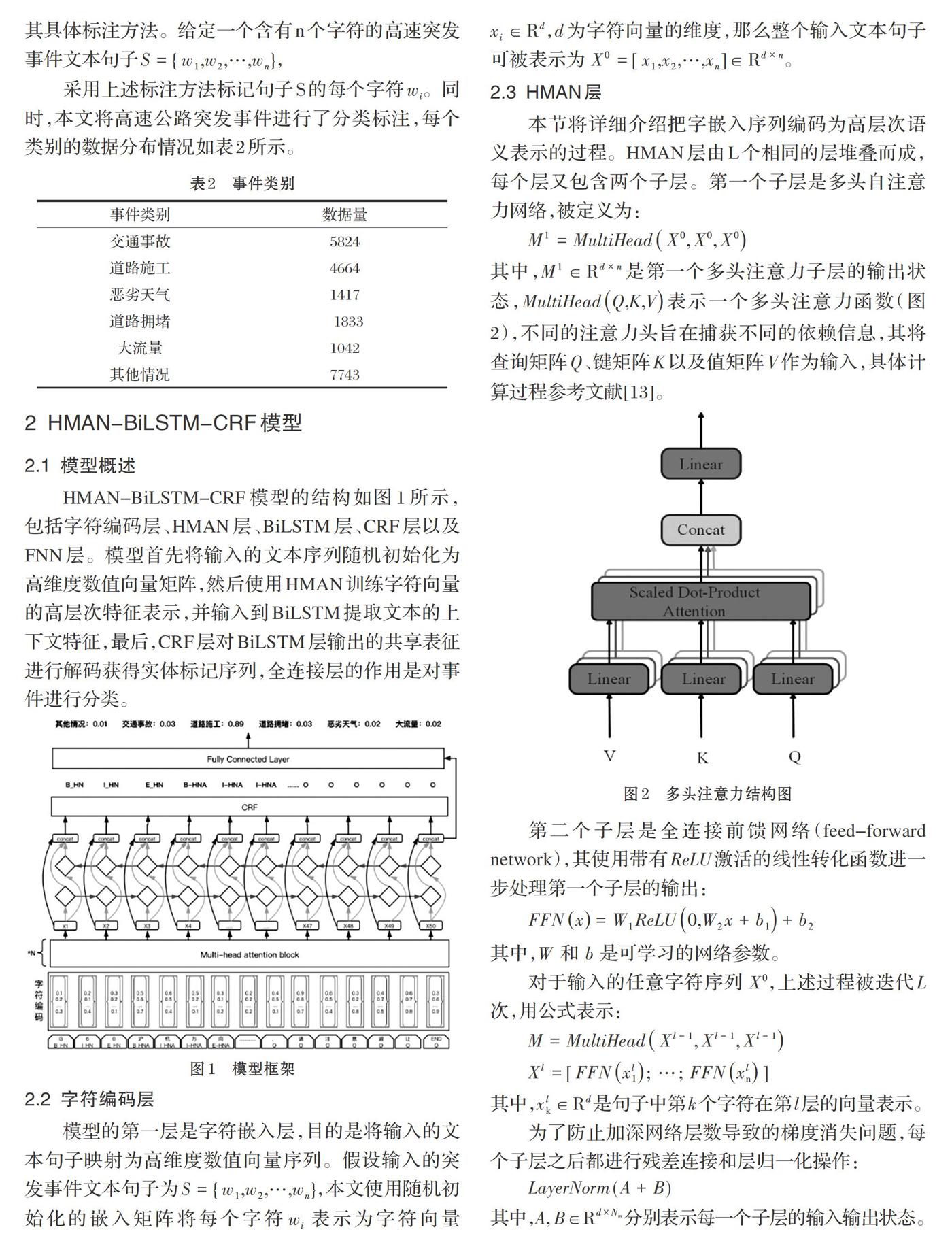
本节将详细介绍把字嵌入序列编码为高层次语义表示的过程。HMAN层由[L]个相同的层堆叠而成,每个层又包含两个子层。第一个子层是多头自注意力网络,被定义为:
[M1=MultiHead X0, X0, X0]
其中,[M1∈Rd×n]是第一个多头注意力子层的输出状态,[MultiHeadQ,K,V]表示一个多头注意力函数(图2),不同的注意力头旨在捕获不同的依赖信息,其将查询矩阵[Q]、键矩阵[K]以及值矩阵[V]作为输入,具体计算过程参考文献[13]。
第二个子层是全连接前馈网络(feed-forward network),其使用带有[ReLU]激活的线性转化函数进一步处理第一个子層的输出:
[FFNx=W1ReLU0,W2x+b1+b2]
其中,[W ]和[ b ]是可学习的网络参数。
对于输入的任意字符序列[ X0],上述过程被迭代[L]次,用公式表示:
[M=MultiHead Xl-1, Xl-1, Xl-1]
[Xl=[FFNxl1;…;FFNxln]]
其中,[xlk∈Rd]是句子中第[k]个字符在第[l]层的向量表示。
为了防止加深网络层数导致的梯度消失问题,每个子层之后都进行残差连接和层归一化操作:
[LayerNorm(A+B)]
其中,[A, B∈Rd×Nm]分别表示每一个子层的输入输出状态。
2.4 BiLSTM层
由于LSTM模型在处理文本序列时,只能保留过去时刻的文本信息,无法同时对上下文信息进行建模,所以本文采用BiLSTM提取文本特征。BiLSTM由一个正向LSTM和一个反向LSTM组成,正向LSTM用来学习上文的特征信息,反向 LSTM 用来学习下文的特征信息。
LSTM模型通过3个控制门结构来决定信息的保留和丢弃,具体计算过程如下:
[it=σ(Wixt+Uiht-1+ViCt-1+bi)]
[ft=σ(Wfxt+Ufht-1+VfCt-1+bf)]
[ct=tanh(Wcxt+Ucht-1+bc)]
[ct=ftct-1+itct]
[ot=σ(Woxt+Uoht-1+VoCt-1+bo)]
[ht=ottanh (ct)]
其中, [σ]为激活函数, [W]为权重矩阵, [b]为偏置向量;[it],[ft] 和 [ot]分别为输入门,遗忘门和输出门的输出;[ct]是输入信息后的中间状态,[ct]是更新之后的cell状态, [ht]是[ t]时刻的最终输出。
BiLSTM模型的在[t]时刻的隐状态由前向LSTM的隐状态[ht]和反向LSTM的隐状态[ht]共同决定,可以表示为:
[ht=[ht,ht]]
之后,使用tanh激活函数来计算每个字符可能的实体标签的概率得分,其公式表示如下:
[P=W1tanhW1ht+b1+b2]
其中,[W]和[b ]为可训练的网络参数。
2.5 CRF层
BiLSTM模型是独立预测实体标签的,会出现[{B-Time、I-Pos}]等序列标注错误的情况。因此,本文添加 CRF 层来保证预测标签的合法性,其能够建立相邻标签之间的依赖关系。BiLSTM输出的概率矩阵[ P ∈Rn×k ],其中[ n ]为输入序列的字符个数, [k]为标签种类数。输入序列[ X=(x1,…,xn)]对应的输出序列[Y=(y1,…,yn)]的得分为:
[scoreX,Y=i=0nAyi,yi+1+i=1nPi,yi]
其中,[Pi,j]表示第[i]个字符对于第[j]个标签的分数,[Ai,j]表示标签[i]转移为标签[j]的概率。
最后,使用一个softmax函数来计算标签序列[ Y ]的概率:
[pY|X=escoreX,YY∈YXescore(X,Y)]
其中,[YX]表示所有可能的标签序列。
2.6 全连接层
全连接层的主要任务是将BiLSTM层输出的文本特征向量作为输入,经过线性变换后,使用softmax函数计算高速突发事件属于某一类别的概率,即:
[P=softmax(W1tanhW2X+b1+b2)]
其中,[W]为权重矩阵,[b]为偏置向量,两者都是可学习的网络参数。
3 实验与结果分析
3.1 模型参数设置
在模型训练过程中, 使用Adam算法对模型进行优化。字嵌入大小设置为200,隐藏向量大小也设置为200,层次多头注意力的层数为3,头数为5,以批次量为64的小批量进行训练,学习率选取为0.0001。同时,模型使用Dropout来防止过拟合问题,参数取值为0.3。
3.2 评价指标
本文使用准确率(Precision)、召回率(Recall)和F1值(F1-score)作为评价指标对突发事件实体识别与事件分类的效果进行评估,计算公式如下:
[Precision=TPTP+FP×100%]
[Recall=TPTP+FN×100%]
[F1=2×Precision×RecallPrecision+Recall×100%]
其中,TP(True Positives)表示测试集中被正确识别的实体或事件的个数,FP(False Positives)表示测试集中被错误识别的实体或事件个数,FN(False Negatives)表示测试集中没有被识别出的实体或者事件个数。
3.3 实验结果
本文使用高速突发事件数据集的测试集来对训练后的HMAN-BiLSTM-CRF模型进行评价。表3展示了高速突发事件中不同类型的实体识别结果。从表3可以看出,事发时间、高速名称、高速编号和事发方向实体类型取得了相对较高的结果,这是因为它们的表达形式相对较为固定且实体语义简单。事发路段、事发位置、实体的各项指标相对较低,主要是因为这几类实体的字符数相对较长且其实体语义比较复杂。通过查看实例发现,在高速突发事件数据集中事发位置的实体分布低于其他实体,这也是造成其识别准确率等指标较低的原因。
表3 高速突发事件实体识别实验结果
[实体类型 准确率 召回率 F1 值 事发时间 0.955 0.954 0.955 高速名称 0.967 0.97 0.968 高速编号 0.986 0.988 0.987 事发路段 0.769 0.805 0.787 事发方向 0.927 0.948 0.938 事发距离 0.822 0.846 0.834 事发位置 0.629 0.586 0.607 總体指标 0.865 0.871 0.868 ]
高速突发事件的分类结果如表4所示。从表中可以看出,道路施工类和其他情况类的准确率最高,分别达到了85%和86%,而大流量类的准确率仅为59%,这在一定程度上证明了数据量的规模对模型的训练结果有较大影响,大规模训练数据有利于提升模型的性能。值得注意的是,虽然交通事故类的训练数据较大,但其性能指标的提升相对不是太高,这可能是因为造成交通事故的原因有很多,交通事故情况也较为复杂,从而增大了语义识别的难度。
4 结束语
针对高速公路突发事件实体识别和事件分类任务, 本文提出了HMAN -BiLSTM-CRF多任务联合学习模型,该模型使用多头自注意力网络学习字向量的高层次特征表示,解决了文本表征时的一词多义问题。本文提出的HMAN -BiLSTM-CRF模型在突发事件实体识别任务和事件分类任务中均取得了最佳结果,证明了模型的有效性。
参考文献(References):
[1] EftimovT, Seljak B K, Koroec P. A rule-based namedentity recognition method for knowledge extraction of evidence-based dietary recommendations[J].Plos One,2017.12(6).
[2] The role of fine-grained annotations in supervised recognition of risk factors for heart disease from EHRs[J]. Journal of Biomedical Informatics,2015.58:S111-S119
[3] Xu K, Zhou Z, Hao T, et al. A Bidirectional LSTM and Conditional Random Fields Approach to Medical Named Entity Recognition[J].2017.
[4] 李丽双,郭元凯.基于CNN-BLSTM-CRF 模型的生物医学命名实体识别[J].中文信息学报,2018.32(1):116-122
[5] 张晗,郭渊博,李涛.结合GAN与BiLSTM-Attention-CRF的领域命名实体识别[J].计算机研究与发展,2019.9.
[6] Kim Y. Convolutional neural networks for sentence
classification[C].Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP),2014:1746-1751
[7] BansalT,BelangerD,Mccallum A. Ask the GRU: multi-task
learning for deep text recommendations[C]. The 10th ACM Conference on Recommender Systems (RecSys), 2016:107-114
[8] Zhou P, Shi W, et al. Attention-Based Bidirectional Long
Short-Term Memory Networks for Relation Classification[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2:Short Papers),2016.
[9] Zhang Y,YuanH,WangJ,et al. YNU-HPCC at EmoInt-
2017:Using a CNN-LSTM model for sentiment intensity prediction[C]. Proceedings of the 8th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis,2017:200-204
[10] Li Y,WangX,XuP,et al. Chinese text classification model
based on deep learning[J]. Future Internet,2018.10(11):113
[11] Wu F, Liu J, Wu C, et al. Neural Chinese Named Entity
Recognition via CNN-LSTM-CRF and Joint Training with Word Segmentation[J]. 2019.
[12] Zhang Z, Zhan S, Zhang H, et al. Joint model of entity
recognition and relation extraction based on artificial neural network[J]. Journal of Ambient Intelligence and Humanized Computing,2020:1-9
[13] Vaswani A, Shazeer N, Parmar N, et al. Attention is all
you need[C].Advances in neural information processing systems,2017:5998-6008
收稿日期:2020-08-31
基金項目:浙江省交通运输厅科研计划项目(ZJXL-JTT-2019061)
作者简介:范晓武(1972-),男,浙江绍兴人,硕士,高级工程师,主要研究方向:交通大数据应用和智慧高速车路协同。
