
拉曼光谱数据处理方式对大米产地鉴别模型的影响
2021-06-07 08:25:06李良翠黄家乐房雪婷
中国食品学报 2021年5期
沙 敏,李良翠,黄家乐,余 倩,刘 唱,房雪婷
(南京财经大学管理科学与工程学院 南京210023)
水稻是最重要的谷类作物之一[1],是一种复杂的食物基质,富含蛋白质、脂肪、淀粉和其它营养素[2],其质量受众多因素的影响,如遗传、生长条件和加工过程[3]。随着居民生活水平的提高,地理标志产品因其质量更优而颇受消费者喜爱。与此同时,市场上出现张冠李戴或掺假销售的现象,给欺诈者带来不公平的经济利益,破坏了消费者对生产者的信任度[4]。为消费者、生产者、零售商开发一个可确定大米地理来源的有效工具是非常必要的。
感官鉴别[5]、生物学鉴别[6-7]和化学鉴别(稳定同位素[8-9]、微量元素[10-11]、挥发性成分[12-14])等技术已被大量报道用于鉴别大米的地理起源。这些方法中,廉价、快速和非破坏性的光谱分析结合模式识别的方法越来越受欢迎,并普遍应用于固态和液态多组分复杂样品的分析。
以拉曼光谱技术为例,若干文献报道了其在大米产地鉴别中的应用[15-19]。这些研究所用的大米样品大多是去壳后的米粒,光谱采集仅涉及米粒外部的化学成分。众所周知,米粒中碳水化合物、蛋白质、脂肪和水的质量百分比分别在70%~80%,7%~8%,1%~2%和11%~12%范围,且各成分在米粒中分布不均匀[20],而大米的加工工艺如抛光等会导致大米表面的差异,因此,仅采集大米表面的拉曼光谱不足以反映大米的整体成分信息。为了准确分析,需对米粒进行粉碎、筛分,收集成分尽可能均匀的米粉样品,而现有大米及其它成分不均匀产品的产地、品种等的鉴别文献[21-24]均是基于2 次或3 次测量取平均值的方法获取样品的谱图信息,未考虑波动较大导致差异数据的可能性。多次测量取平均值仅可有效消除随机误差带来的影响,而样品成分不均一这一客观事实不属于随机误差。每个谱图的信息存在些许区别[25],而片面地取平均值后可能使一些关键信息消失,数据不一定准确。为使所得样品谱图数据库能够更加全面地反映样品的信息,需多次采集来获取足够多的谱图信息。
针对现有研究的不足,本文以中国东北6 个地区的地理标志大米为例,采用拉曼光谱检测技术获取大米的拉曼光谱信息,考察不同的数据处理方法对大米产地鉴别准确度的影响。首先对大米进行粉碎均匀处理,依次经精加工、粉碎、筛分获取较为均匀的米粉样品。其次,考虑到可能存在的数据差异,每个样品经拉曼光谱仪采集5 次,分析所得数据,剔除可能的差异数据。最后,筛选的数据分别考察取和不取平均值对大米产地鉴别模型的影响,以期寻求可使同种样品内差异减小、不同样品间差异扩大的数据处理方式,为后续建立产地鉴别模型提供依据。
1 材料与方法
1.1 材料
6 种地理标志大米分别为辽宁省盘锦市的盘锦大米,黑龙江省牡丹江市宁安市的响水大米,吉林省通化县西江镇的西江大米,黑龙江省农垦总局建三江分局的建三江大米,黑龙江省哈尔滨市五常市的五常大米,吉林省延边朝鲜族自治州的延边大米。大米为2017年间种植,为了保证样品的代表性,在地理标志大米种植区域内分散采样,分别在10,10,6,7,7 个和5 个采样点采集盘锦、响水、西江、建三江、五常和延边大米样品,每个采样点各采集了2 份大米,每份大米采集约2 kg 样品。
1.2 设备与仪器
NA12345 砻谷机、NA-JCB 碾米机,宁波科麦仪器有限公司;15B 型立式粉碎机(内置网孔直径为0.6 mm 的筛网),台州巴菱电器有限公司;Prott-ezRaman-d3 便携式激光拉曼光谱仪,美国Enwave Optronics 公司;拉曼测试样品池(石英材质,长4 cm,宽2 cm,厚3 mm,正中央圆形凹槽直径1.5 cm,深度2 mm),中国科学院上海有机化学研究所;JA1003 电子分析天平,上海力辰仪器科技有限公司;分级筛(100 目和140 目),上虞市华丰五金仪器有限公司。
1.3 方法
1.3.1 供试品制备 将水稻进行晾晒、脱粒、挑选、砻谷和碾米等处理,每份水稻砻谷2 次,碾米1 次。加工后的每份米分别称取20 g,在0.5 min 内缓慢加入到已预运行1 min 的粉碎机中,粉碎2 min,确保粉碎完全。所得米粉依次经100 目和140 目筛进行筛分,收集粒度为100~140 目的米粉,作为拉曼光谱测试的供试品,置于冰柜中冷藏储存,测试前将样品移至干燥器中平衡至室温。
1.3.2 光谱采集 经前期研究得最佳拉曼光谱采集参数如下[25]:激发波长785 nm,功率450 mW,CCD 检测器-85℃,扫描范围250~2 339 cm-1,分辨率1 cm-1,曝光时间4 s,扫描次数3 次,激光与样品表面的距离5 mm。米粉置于石英样品池中,考虑到样本的不均匀性,分别在5 个不同的位置各采集1 张拉曼光谱。
1.3.3 数据处理 为了从原始谱图数据中去除干扰的和无关的信息,在数据分析之前应对原始数据做一些预处理。本文中,拉曼光谱数据依次用wden 小波函数进行去噪处理,用多元散射校正(Multiplicative scatter correction,MSC)消除散射的影响,用mapminmax 函数进行归一化。然后,综合运用相对标准偏差(Relative standard deviation,RSD)分析和层次聚类分析(Hierarchical clustering analysis,HCA)剔除潜在的差异数据。最后,基于支持向量机(Support vector machine,SVM)对样本地理来源进行鉴别,考察剔除差异数据和取平均值的数据处理方式对模型的影响。所有数据预处理和模型构建均基于MATLAB 2016a进行。
2 结果与分析
2.1 数据预处理
以盘锦大米为例,样品信息和谱图编号信息如表1所示。以6 种大米第1 批次第1 份米的其中1 个拉曼光谱为例,经去噪、MSC、归一化处理后的谱图如图1所示。由于其它批次大米的拉曼光谱经上述预处理后的谱图与图1均类似,谱图峰较密集的区域位于250~1 500 cm-1之间,因此后续分析采用该区域数据。由图1可知,6 种大米高度相似,肉眼难以区分。

表1 盘锦大米样品和谱图信息Table 1 Information of Panjin rice samples and their spectra

图1 6 种大米第1 批次第1 份米的1 个拉曼光谱经去噪、MSC、归一化处理后的图谱Fig.1 Raman spectra of the first part of the first batch of the six kinds of rice after denoising,MSC and normalization
2.2 差异数据剔除
2.2.1 相对标准偏差分析 扫描范围在250~1 500 cm-1之间,盘锦大米每批次每份米的5 个拉曼光谱经数据预处理后的相对标准偏差值如表2所示。由于米粉的不均匀性、仪器的波动性、环境及人为因素等干扰拉曼光谱的采集,RSD 值普遍在11%~14%之间波动。其中,第5 批次第1 份米和第6 批次第2 份米的RSD 值较大,怀疑存在波动较大的差异数据。
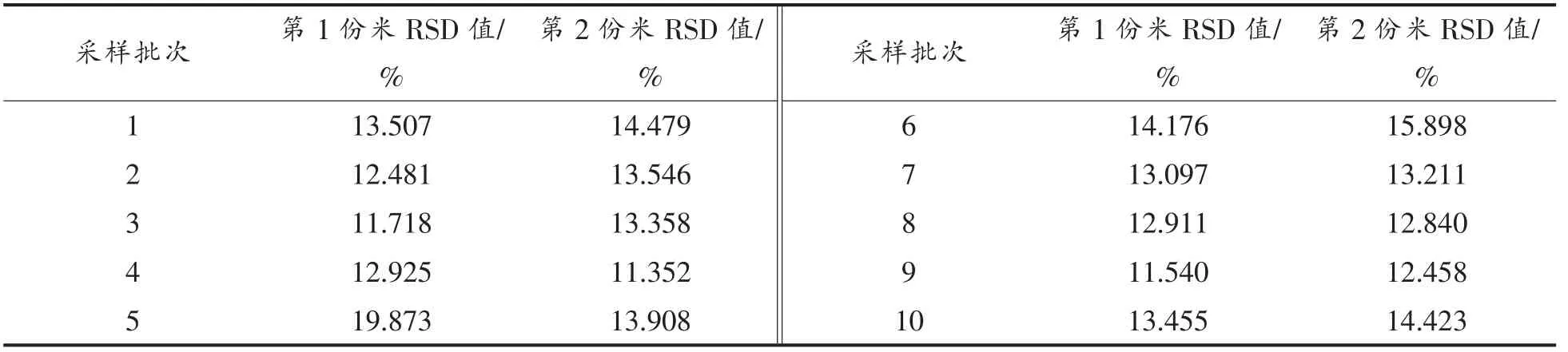
表2 每份大米的5 个拉曼光谱数据的相对标准偏差值Table 2 The values of relative standard deviation of five Raman spectral data for each rice
2.2.2 层次聚类分析 为了更直观的找出可能的差异数据,对每份米的5 个拉曼光谱进行层次聚类分析。分别使用欧氏距离(euclid)、标准欧氏距离(seuclid)、城市街区距离(cityblock)和余弦距离(cosine)作为距离度量方法,采用平均距离法(average)、最短距离法(single)和最长距离法(complete)创建系统聚类树[26]。以盘锦大米第5 批次第1 份米为例,不同创建聚类树方法对应的同表象型相关系数值如表3所示,以标准欧氏距离和平均距离法作为距离度量方法及创建聚类树方法对应的同表象型相关系数值最大,所创建的聚类树(图2)最佳。由图2可知,谱图2和3 最为相似,5和1 次之,谱图4与其它4 个谱图的差异显著,判断谱图4为可疑的差异数据。将剔除谱图4后剩余的4 个拉曼光谱数据进行RSD 分析,RSD 值为12.279%,在正常波动范围11%~14%之间,证实谱图4为差异数据,后续建模分析时应将其剔除。
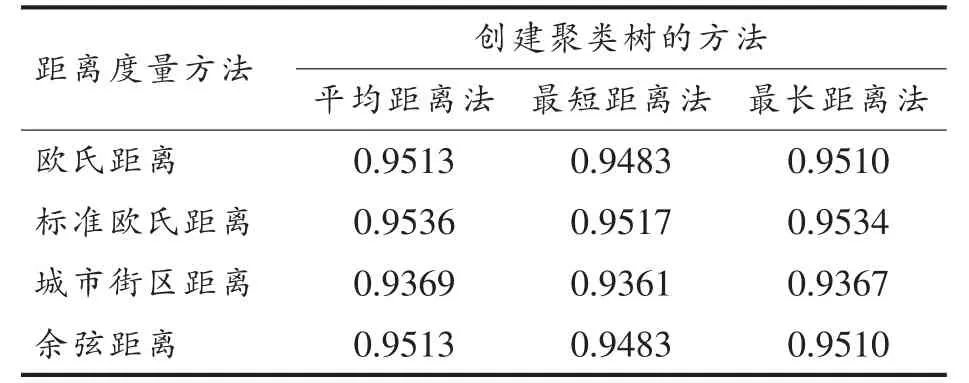
表3 不同创建聚类树方法下的同表象型相关系数值Table 3 The cophenetic correlation coefficients for the clustering trees using different methods

图2 盘锦大米第5 批次第1 份米的5 张拉曼光谱HCA 分析聚类树图Fig.2 The clustering tree of the five Raman spectra of the first part of the fifth batch of Panjing rice
对剔除差异数据后的盘锦大米的第5 批次2份米的拉曼光谱数据(9 个)进行HCA 分析(图3)。由图3可知,9 张谱图混在一起无明显聚成两类的趋势,说明2 份米之间的差异较小。上述研究结果表明,RSD 分析可以预判是否存在差异数据,HCA 分析可找出潜在的差异数据,最后再经RSD验证可明确差异数据,两者综合运用提供了精确、可靠的剔除差异数据的方法。

图3 盘锦大米第5 批次2 份米的9 张拉曼光谱HCA 分析聚类树图Fig.3 The clustering tree of the nine Raman spectra of the fifth batch of Panjing rice
重复上述步骤,对盘锦大米剩余的9 个批次样品做同样的分析,得差异数据如表4所示。研究发现,表2中RSD 值超过14%的均存在显著差异数据,剔除差异数据后的RSD 值均小于14%(表4),说明可通过RSD 值的波动范围初步判断是否存在差异数据,后续建模应剔除表4中的7 个数据。对响水、西江、建三江、五常和延边大米的拉曼光谱数据分析后,发现分别存在8,5,4,2 个和4个差异数据。

表4 剔除差异数据后的RSD 值Table 4 The values of RSD for each rice after eliminating the difference data
2.3 不同数据处理方式下的模型鉴别结果
以剔除差异数据前、后和取平均值前、后的4种拉曼光谱数据(A~D)分别建立大米产地鉴别模型,将每个批次第1 份米的数据作为训练集数据,第2 份米的数据作为测试集数据,SVM 建模使用径向基核函数(Radial basis function,RBF),通过网格搜索技术对gamma 和c 参数进行优化,最终通过测试集的识别率比较模型的优劣,结果如表5所示。未剔除差异数据和未取平均值处理的数据(A),其所建模型的识别率最低,小于80%,分类效果不理想;数据经剔除差异处理后(B),模型识别准确率小幅提升,提高了约2%;数据经取平均值处理后(C),模型的识别准确率有所提高,提升了约6%,相较剔除差异数据而言,取平均值的效果更佳;当数据经2 种方法处理后(D),所建立模型的分类鉴别能力大大提升,平均识别率提高了约13%,且每种大米的识别率均有所提高。

表5 不同数据下的模型鉴别结果Table 5 Results of discrimination model using different data
对采用数据C 和D 建模的结果进行分析,探究差异数据对模型鉴别能力的影响,结果如图4。采用数据C 时,共有7 个错误分类样本,其中,延边大米有1 个样本被错误地归为五常大米;建三江大米有1 个样本被错误地归为五常大米,1 个被错误地认为是盘锦大米。而采用数据D 时,错误分类样本数减少为4 个,延边大米可与其它大米完全区分开,建三江大米也可与盘锦大米和五常大米正确区分。结果表明,差异数据降低了鉴别模型的准确性,建模分析前应进行剔除处理。

图4 大米样本被错误分类的情况图Fig.4 Figure for rice samples misclassified
以响水、西江和盘锦大米为例,对数据B 和D进行主成分分析,探究数据取平均值对模型鉴别能力的影响,结果如图5所示。使用数据B 时,响水大米和盘锦大米可以明显区分,但西江大米与盘锦大米的大多数数据混杂在一起,西江大米与响水大米的少数数据混在一起,3 类大米无明显分界,较难区分。数据取平均值后(即数据D),响水大米与盘锦大米分散在很远的两端,可以容易区分;响水大米与西江大米有明显的分界,可以进行区分;西江大米有1 个数据落入盘锦大米的样品簇中,其余数据与盘锦大米不交融。由此可知,虽然样品成分不均一,但是数据取平均值后,可使同种大米样品内的差异减小、不同大米样品间差异扩大,有利于分类鉴别模型准确率的提升。

图5 3 种大米在前3 主成分上的分布图Fig.5 Distribution of the three kinds of rice samples on the first three principal components
3 结论
本文以盘锦大米、响水大米、西江大米、建三江大米、五常大米和延边大米6 种地理标志大米为例,探究拉曼光谱数据处理方式对大米产地鉴别模型的影响。稻谷样品分别经精米加工、粉碎和筛分操作,得粒度为100~140 目的米粉。其次,分别在5 个测量点采集每份米粉样品的拉曼光谱,所得拉曼光谱依次经去噪、多元散射校正和归一化预处理。然后,分别经相对标准偏差和层次聚类分析剔除每个米粉样品的差异数据。最后,将剔除差异后的所有数据和取平均值后的数据分别经支持向量机建立分类模型。结果表明,RSD 分析可以预判是否存在差异数据,HCA 分析可找出潜在的差异数据,再经RSD 分析,可最终明确差异数据,两者综合运用提供了精确、可靠的剔除差异数据的方法。此外,取平均值后的数据可使相同大米样品内的数据差异缩小、不同大米样品间的差异扩大,有效提高模型的识别准确率,所得模型对6 种地理标志大米的鉴别准确率达91.11%。本文所探究的数据处理方式为构建大米产地溯源模型提供了更为准确、有效的方法,所提出的数据处理方法、产地鉴别模型具有潜在推广应用价值。
猜你喜欢
新少年(2023年11期)2023-12-05 12:21:38
江淮法治(2022年8期)2022-05-18 02:42:40
中国化肥信息(2019年4期)2019-05-31 10:13:00
夜郎文学(2017年2期)2017-09-26 06:29:40
小学阅读指南·低年级版(2016年6期)2016-05-14 21:39:20
水利科技与经济(2016年10期)2016-04-26 08:40:10
防灾减灾学报(2015年3期)2015-12-16 16:15:33
天津经济(2015年10期)2015-02-28 16:46:51
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:38
化学分析计量(2013年1期)2013-03-11 16:37:15
