
基于FPGA的无刷直流电机控制系统探讨
2021-06-07 11:16朱劲涛
通信电源技术 2021年4期
朱劲涛
(南京信息工程大学,江苏 南京 210044)
0 引 言
无刷直流电机(Brushless DC Motor,BLDCM)由于具有起动和调速性好,控制简单以及堵转转矩大等特点,在航空航天、数控装置以及汽车电子等驱动和伺服系统中得到了广泛应用[1,2]。在BLDCM控制系统中,常采用二二导通单管调制方式,需要检测转子磁场相对于定子绕组的位置以控制逆变电路的导通与关断。为了获得转子位置信息,传统的方式是直接使用如霍尔传感器的位置传感器检测,但其使得电机体积增大,难以在高低温环境下工作,并且使用传感器会增加接线,引入干扰,因此需要发展无位置传感器控制方式。
本文探讨一种基于现场可编程门阵列(Field-Programmable Gate Array,FPGA)加速神经网络的BLDCM控制系统,利用深度学习技术改善对控制信号的分析,提高控制精度,实现无BLDCM的自适应控制。
1 现场可编程门阵列
FPGA是常用的神经网络加速器,其逻辑部分主要由可配置逻辑块和用于接口的输入/输出块组成,开发的一般流程如图1所示,主要包括电路功能设计、设计输入、综合、实现与布线、器件编程、功能仿真、综合后仿真、时序检查、板级仿真以及电路验证等[3]。
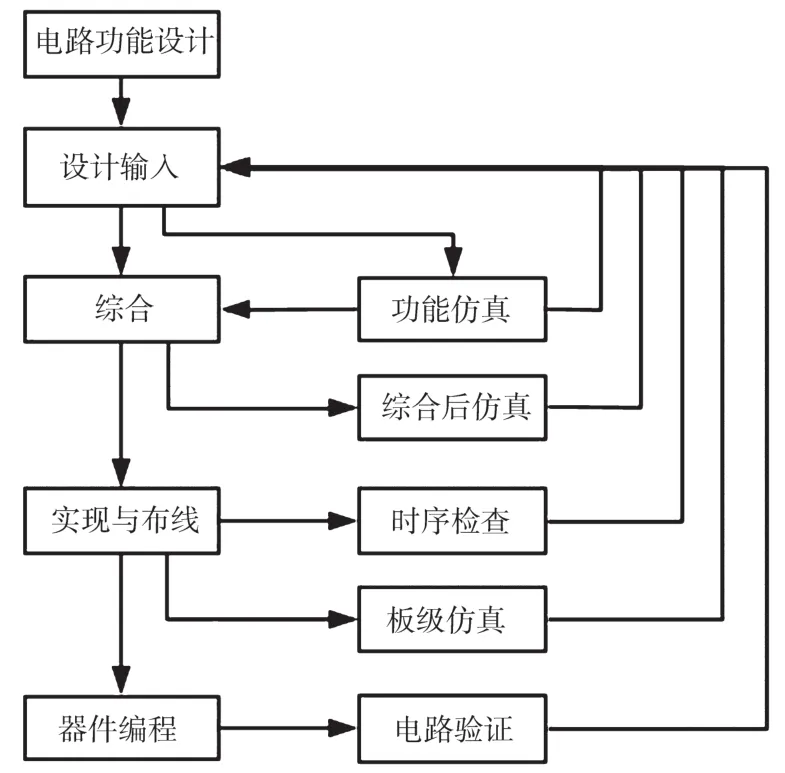
图1 FPGA开发的一般流程
1.1 FPGA加速目标
深度学习是一种以人工神经网络为框架,利用简单但非线性的模型对数据进行表征学习并提取数据特征的方法。其中卷积神经网络(Convolutional Neural Network,CCN)是一种被广泛使用的深度学习的基础模型,它是一个多层神经网络,主要的层包括卷积层、池化层以及全连接层[4,5]。CNN一般分为训练过程和推理过程,训练过程主要为处理数据和反向调整模型的参数,推理过程则是利用额外的数据测试模型对数据进行处理与分类。本文以CNN作为FPGA加速器的加速目标,其基本框架大致可以分为片外存储、片上缓存以及寄存器3个部分。
1.2 FPGA加速特点
FPGA主要具有可编程性和可重构性特点,可以根据算法来设计硬件结构,即开发者可以根据自己的需求,通过配置FPGA内部逻辑块的连接以实现逻辑操作与设计目标,从而更快更灵活地升级其算法。FPGA还能够实现并行计算,相比于图形处理器(Graphic Processing Units,GPU)有较好的能效比,即在相同功耗下获得更高的性能。此外,FPGA相比于专用集成电路(Application Specific Integrated Circuit,ASIC)有更短的开发周期,编程效率更高。
2 转子位置检测
图2为逆变器控制的BLDCM等效电路图,其中电机采用三相星型连接方式。由于电机中没有位置传感器,无法直接检测转子位置,因此需要通过检测电路测量定子绕组的电压、电流等变量间接确定转子的位置。目前较为成熟的方法有反电动势过零检测法、人工智能法以及状态观测法等[7]。其中,反电动势过零检测法线路设计简单,模块参数易于计算,性能可靠性高,应用广泛,技术成熟。此外,由于大部分BLDCM中没有中心点的引出线,需要使用其中的端电压法,端电压指相电压与中心点对地电压的和[8]。

图2 逆变器控制的无刷直流电机等效电路图
假定BLDCM的气隙磁通密度分布为方波,反电动势为梯形波,在三相绕组完全对称,忽略涡流损耗及磁路不饱和条件下,得到电机动态模型为:
式中,UAg、UBg、UCg为每相绕组端电压,L为绕组自感,M为绕组之间的互感,ea、eb、ec为每相的反电动势,Ung为中心点对地电压。
由于电机采用二二导通单管调制方式,在任意时刻仅有两相导通且这两相电流大小相等,方向相反。假定B、C相导通,A相悬空,电流为0。由式(1)可得A相的反电动势过零点方程为:

其余两相同理可得。通过检测反电动势的过零点便可以确定B、C相的过零点时刻,得到转子信号位置,依此调整逆变器的导通与关断,在此基础上再延迟30°电角度即是电机的换相时刻。
由于BLDCM的反电动势取决于每极磁通和转速的乘积,假定每极磁通保持不变,则反电动势与电机的转速成正比关系,电机的换相频率也因此取决于电机的转速。在BLDCM的闭环调速系统中,以速度控制作为外环,电流控制作为内环,两者组成双闭环结构。外环中,通过计算相邻信号的时间差换算成反馈转速n,再将反馈转速n与设定转速n0的差值经PID计算得到设定电流I0。内环中,检测定子绕组得到反馈电流I。设定电流I0与反馈电流I经电流调节器输出PWM波,功率驱动器放大PWM信号后调节逆变电路的导通关断,实现电机的运行与调速。
3 控制系统设计
在运用以CCN为基础的FPGA加速器模型时,基本的设计流程是首先确定设计目的及针对目标,然后选择合适的CCN算法。常用的算法包括非快速算法中的空间卷积算法和通用矩阵乘法算法(General Matrix Multiplication,GEMM)以及快速算法中的快速傅里叶变换算法(Fast Fourier Transform,FFT)和Winograd算法[3]。接着在约束条件下建立数学模型并将其转换为求最值问题,利用穷举法、动态规划法以及分治法等寻找最优解方案。最后根据方案中求得的参数,拓扑结构等生成FPGA系统结构。
3.1 设计流程
本文设计目的主要针对无位置传感器的BLDCM利用基于FPGA的深度学习实现自适应控制的可行性,针对目标则包括两个方面。一方面是提高FPGA的提高数字信号处理(Digital Signal Processing,DSP)资源和内存宽带等利用率,二是提高FPGA的计算吞吐率和执行时间等计算性能。
在CCN算法方面,其训练过程首先进行网络权值的初始化。根据之前分析,将测量的定子绕组的电压和电流等数据作为训练的输入数据,经过卷积层与池化层提取特征向量,再经过全连接层分类识别结果得到输出值,即向前传播阶段。接着求输出值与目标值的偏量,判断其是否在设定范围内,若在范围内则训练结束,固定权值与阀值,若超出范围,则将误差返回并重新计算每一层的误差,即反向传播阶段,以此更新网络权值并重复前传播阶段。训练结束后,神经网络通过大量学习得到输出与输入的映射关系,不再依赖两者之间准确的数学表达式。
在数学建模方面,依据以上得到的输出,在FPGA片上资源的约束条件下建立模型。能否充分利用FPGA片上有限的资源影响着硬件加速器的性能,一般设计时会对其片上资源进行建模以衡量资源的利用率,并作为约束条件。资源利用主要关注计算资源与内存资源。其中计算资源方面主要考虑提高DSP资源的利用,其主要在CCN中进行卷积操作,通常实际DSP的使用数量与可用DSP数量的比率决定了最大计算速率。对于内存资源,主要考虑双极型随机存储器(Bipolar Random Access Memory,BRAM)与内存宽带的利用。BRAM用作输入和输出数据的缓存区,设计时要确定FPGA片上数据所能存储的最大值。内存宽带影响数据的传输速率,即CCN单层计算时数据的交换速率是否与计算吞吐率相匹配。计算性能方面,判断单个FPGA能否满足电机传递的电压电流数据对计算吞吐率的需求,若利用多个FPGA来加速CCN,则还需衡量它们之间通信对计算吞吐的影响。
建立完数学模型后根据实际需求选择合适的方法求得加速性能的最优解。穷举法方法简单,但花费大量时间,适合取值组合较少的情况。动态规划法与分治法都是将原问题分解成若干子问题的求解,最后合并成原问题的最优解。其中动态规划法分解后的子问题之间相互联系,使用迭代法求解,而分治法的子问题之间则相互独立,使用递归法求解。
3.2 优化策略
数学建模中关键参数的选择同样影响公式最终的结果,其主要依据优化策略的选取。计算优化方面,一是针对CCN中的计算并行以提高FPGA的加速性能,包括网络间层与层之间的并行,不同输出特征图之间的并行,特征图中像素点间以及像素点内计算的并行。在优化需要注意FPGA片上存储资源能否存储并传输计算时所有的操作数以及计算资源能否支持设定的特征图及像素的同时计算。二是针对循环分块与展开,循环分块将循环分成多个子循环以减少访问内存的次数,循环展开则提高计算并行的计算量,但循环分块大小会影响计算并行,所以分块大小会作为模型中的关键参数。
内存优化方面,由于FPGA片上存储资源无法存储计算中生成的所有数据,需要与片下存储频繁进行数据交互,更加消耗资源。一是使用单层内的数据复用,而非全部将卷积神经网络层与层之间的中间计算结果存储在片外存储中,再进行访问。二是在不牺牲准确度的情况下用位数相对较少的定点数代替32位或64位浮点数的形式,从而降低操作数的位数,减少片下资源访问次数,增加存储数据量与计算吞吐量。三是CNN中计算单元间的数据通信充分使用FPGA片上存储资源,减少对片外资源的访问,提高其执行效率。
4 结 论
BLDCM中采用神经网络和模糊控制等人工智能算法的无位置传感器控制方法,因具有强大的自学能力而前景广阔。本文探讨了基于FPGA加速器的BLDCM控制系统的可行性,在说明以CCN为模型的FPGA加速特点和转子位置检测方法的基础上阐述了控制系统基本的设计流程与优化策略。
猜你喜欢
防爆电机(2022年1期)2022-02-16
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
电子制作(2019年11期)2019-07-04
电脑爱好者(2015年21期)2015-09-10
农机使用与维修(2014年1期)2014-09-23
电脑爱好者(2009年13期)2009-07-07
