
基于词嵌入和自注意力机制的方面提取算法
2021-06-05 06:28:52吴杭鑫张云华
智能计算机与应用 2021年4期
吴杭鑫,张云华
(浙江理工大学 信息学院,杭州310018)
0 引 言
方面信息提取[1]是从给定原始文本中提取出表征实体、实体属性或反映实体某一侧面的信息。方面信息是方面情感的直接受体,一般为一个词语或者短语。例如,在句子“今天的晚餐既美味又实惠”中,“美味”和“实惠”分别评价了晚餐的两个不同侧面,且赋予了正向的情感极性,所以可作为方面信息提取出来。
方面提取任务是方面级别情感分类任务的前提和基础。近年来随着互联网的发展,越来越受到业界的关注。早期的研究人员主要采用基于语义特征的方法来训练模型[2-4]。但此类模型的性能受人为定义特征的影响较大,相对费时、费力,且对于研究人员的操作能力与资源质量有着较强的依赖性。近期,性能表现较好的方面提取算法,主要以基于词共现网络和基于图的方法为主[5-7]。
受上述方法的启发,本文提出基于词嵌入和自注意力机制的方面提取算法(World Embedding and Self-attention Model for Aspect Extraction,简 称WESM),主要工作如下:
(1)利用基于词汇共现网络的来进行方面提取,相较于传统的主题模型,能够有效克服短文本存在稀疏性等特点,可以发现一些不常见的主题。
(2)引入自注意力机制,解决由于长距离依赖问题而造成的上下文信息忽略问题,能够充分捕捉词的上下文语义信息。
(3)应用细粒度的汽车评论数据集及来自购物网站的抓取数据集,与当前主流相关算法进行了比较。实验结果表明,所提出的WESM模型的性能优于相关工作,适合于方面提取任务。
1 相关工作
方面提取是观点挖掘领域中的细分任务,在过去的数十年中,大量学者在方面提取上做了大量研究工作。如,在文献[8-9]中提出了一个词汇HMM模型来提取文本的显示方面;文献[10]提出基于监督的条件随机场模型来提取显示方面。但是监督学习需要大量的标签数据,耗费大量的人力。
无监督的学习方法可以省去大量的数据标注工作。以pLAS(probabilistic latent semantic analysis)[11]和LDA(Latent Dirichlet allocation)[12]模型为主的方法,通过在文档与单词间搭建“主题”这一桥梁,来进行方面提取,已经被许多研究者应用于方面提取的任务中。然而,这类主题模型基本都是针对长文本方面提取,对于短文本任务无法取得良好效果。针对短文本特性,文献[13]提出了BTM(Biterm Topic Model,简称BTM)模型,它与LDA模型不同的是使用了biterm进行建模,能够更好的发掘文章的隐藏主题;文献[14]提出了词汇网络共现主题模型(Word NetWork Topic Model,简称WNTM),通过词汇共现网络中语义紧凑的潜在词群,发现不常见的主题,取得了良好效果。上述方法在针对短文本这一特定方向时,综合表现较好,其共性在于挖掘上下文隐含的语义关系解决短文本存在的稀疏性等特点。
综上所述,短文本数据相对于长文本主要存在的问题是文本稀疏性大、语义信息不足以及主题不平衡等。针对这些问题,本文提出了WESM模型,通过词汇共现网络,解决了难以发现罕见主题的问题;通过引入针对中文的词嵌入模型,能够更好的发掘出丰富中文词汇的语义信息;通过引入自注意力机制,缓解上下文语义缺失的问题,提高了算法的性能。
2 模型描述
本文提出了一种基于词嵌入和自注意机制的方面提取算法(WESM)。该模型基于词汇共现网络,在整个语料库上构建伪文档,相较于传统的LDA模型,词汇共现网络有着明显的优势,能够充分利用整个语料库的语义信息。其次,其节点之间的边权值表示两个词汇在上下文中共现的次数。通过针对中文的词嵌入模型cw2vec来训练词汇,丰富词汇的潜在语义信息,得到词汇的向量表示。然后输入到自注意力机制模块中,其特点在于可以无视词汇之间距离,捕获长距离的依赖关系。算法模型架构如图1所示。
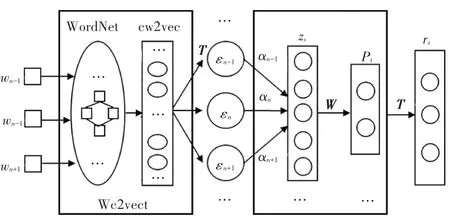
图1 WESM模型图Fig.1 Model of WESM
其中,WordNet是词汇共现网络,w n-1、w n、w n+1是输入量,分别表示语料库中的词汇、网络中节点是词汇、节点之间的边权重表示两个节点词汇共现的次数。cw2vec是中文单词向量模型,经过该模型的训练可以得到词汇的向量表示,即εn-1、εn、εn+1。经过词嵌入模型后,进入自注意力机制模块,该模块主要是为了得到词汇的上下语义信息,Z s表示相应句子的嵌入表示,W为过滤矩阵,T代表高维空间向量矩阵。
WordNet是词汇共现网络(WNTM)模型,从关键词之间的共现关系角度来建立网络。考虑到语义的联系是相互的,所以该网络是一个无向有权图。其中节点表示关键词,权值表示两个词汇共同出现的次数。显然,若节点之间的边权值越大,则它们之间的关系越紧密。
WNTM模型由网络图、邻近表、伪文档三部分组成,如图2所示。其中,伪文档是和邻近表由词汇与相邻节点生成的,描述了节点之间可能存在的关系。词汇贡献网络生成相应的伪文档,步骤如下:
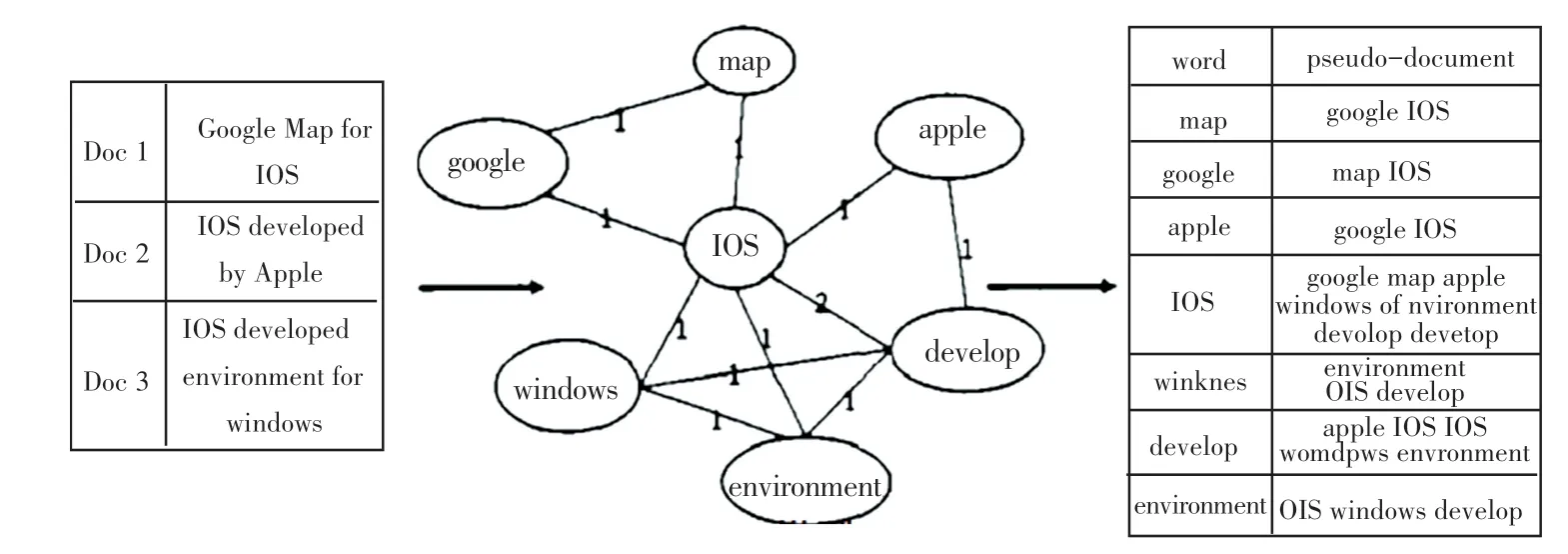
图2 WNTM模型图Fig.2 Model of WNTM
(1)根据词汇w i的邻近词汇表L i,与潜在词群z i,进行“主题-单词”概率分布采样,得出相应关系表达式:Θi~Di r(α);
(2)对潜在词群z,进行“伪文档-主题”概率分布采样,得到表达式:φz~Di r(β);
(3)对于邻近词汇表L i中的每个词汇w j:
①根据“伪文档-主题”概率分布,采样主题z j
②根据“主题-单词”概率分布,采样单词w j~
其中,Θ、φ分别表示邻近表中潜在词群出现的概率分布、词汇属于潜在词群的概率分布。
由于WNTM模型包含了词汇的上下文语义信息,因此将词汇w i的邻近词表Θi的主题比例作为词汇w i的主题比例,其计算公式如下:

其中,Θi可以表示为可以看成词汇的经验分布,计算公式如下:
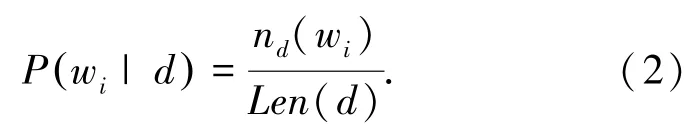
式中,n d(w i)表示词汇w i在文档d中的词频,Len(d)表示文档d的长度。由于短文本数据的特点,使得长文本主题相关方法对其处理效果欠佳。而基于WNTM模型构建的伪文档中包含了所有的主题信息,学习伪文档上的主题分布,能够解决短文本数据稀疏性问题。
TC2vec的另一个部分是cw2vec模型,该模型以中文笔画信息作为特征,捕捉汉字词语的语义和结构层面信息,获得分布式向量词并以负采样进行计算。
cw2vec模型使用一种基于n元笔画的损失函数,公式如下:

其中,w和D分别表示词语和词语归属的训练语料;c和T(w)是词语的上下文和词语上下文窗口内的所有词语集合;λ是负采样的数量,由总数乘以负采样比例得到;E w'~P[~]是期望,并且选择的负采样w'服从部分P。因此,语料中出现次数越多的词语越容易被采样,公式如下:

在词嵌入层后增加自注意力层,通过自注意力机制获取文本的上下文语义信息,重构句子嵌入表示,转化为r s的形式。
通过加权和的方式将方面信息纳入到重现后的句子中,计算公式如下:

式中,e wi表示第i个词汇的向量,词汇的嵌入表示和上下文环境将共同决定注意力机制的权值,即a i的数值。计算公式如下:
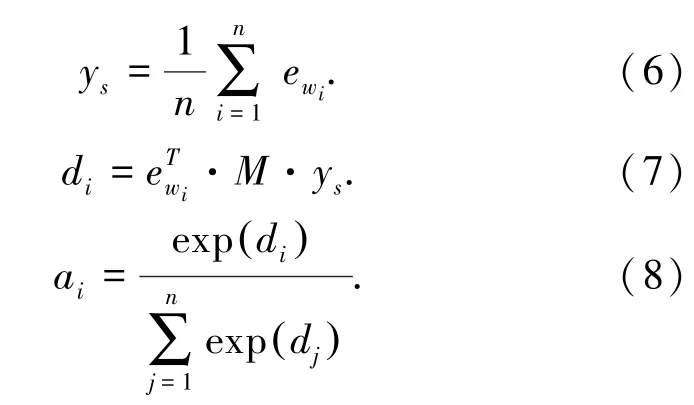
其中,y s由组成句子词汇的向量和求均值得到,是句子向量的嵌入。通过模型训练获得矩阵M(M∈R d×d),并在句子向量和词汇向量之间进行映射,以获得词汇和方面相关信息。a i表示注意机制的权重,公式如下:

其中,p t表示方面嵌入权重,将z s从d维降到k维,然后通过softmax函数标准化得到。W和b从训练模型中获得的。
若直接进行后续训练,将会产生较大的重构误差。因此,本文采用最大边界相关函数(Contrastive Max-margin Objective Function),其公式如下:

其中,D代表语料库,n i代表负样本。训练使得r s与z s大体相似,并且与n i最大限度不同。{E、T、M、W、b}为训练得到的模型参数。
3 实验及分析
3.1 数据集和评价指标
为验证模型的有效性,采用公开数据集(细粒度汽车评论标注语料数据集)通过网络爬取相关评论信息(某购物网站关于手机的相关数据)进行测试,并且都详细标注了用户评论中的评价对象和评价特征。数据集详细信息见表1。
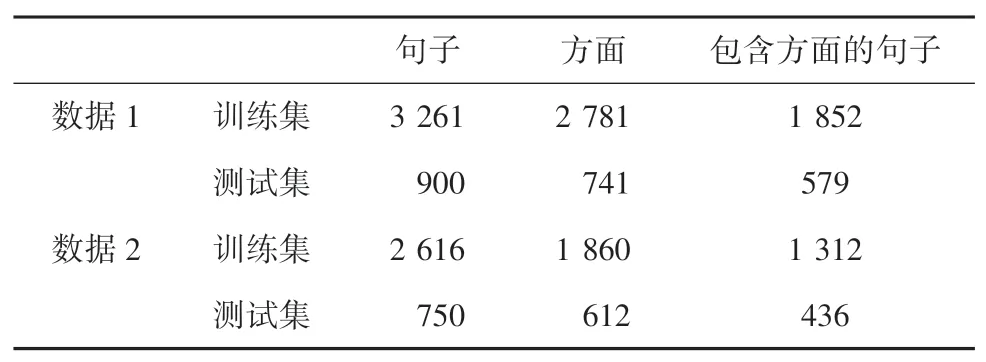
表1 数据集和训练集Tab.1 Data sets and training sets
本文选取精确率(Preci s i on)、召回率(R ecal l)和F-s cor e值来评估模型的整体性能。精确率计算公式如下:
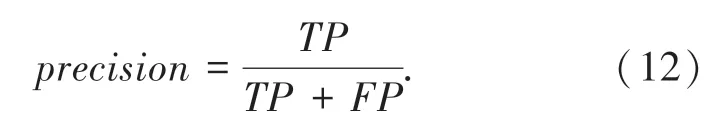
召回率也称为查全率(R ecal l),计算公式如下:
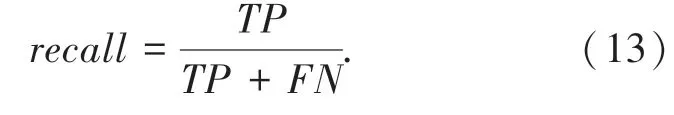
实验引入了F-s cor e值,用来调节查准率和查全率,公式如下:
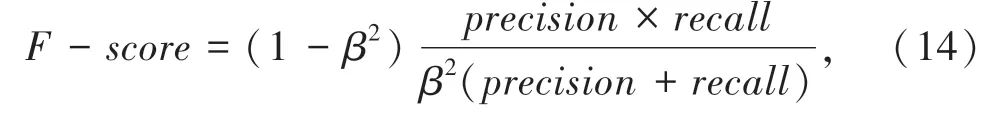
其中,β为F-s cor e中权重参数。
3.2 实验结果及分析
本文使用主题聚合度(Topic Coherence)来评价得到的方面聚类之间的相似性,它与方面词相似度之间呈正相关,其计算公式如下:
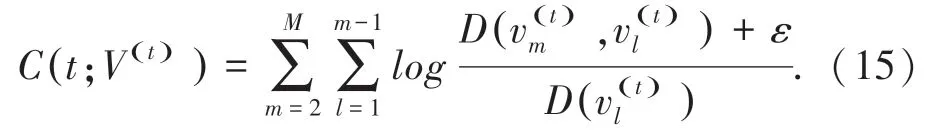
其中,t代表某个方面;M表示在方面集合选取词汇数量代表方面t中n个方面词汇;和分别表示方面t中的两个方面词汇;D(~)表示参数(方面词汇)的共现次数。当只有一个参数时,表示该词汇的出现次数。为了防止l o g函数的值为0造成计算错误,本文设置ε为1。公式如下:

本文选取LDA、BTM、WNTM、WESM算法在数据集上进行对比实验,模型表现如图3、图4所示。其中主题数统一选10,先验参数学习率设置为0.025。
从图3和图4中可以看出,WNTM模型在主题句聚合度上的实验结果优于LDA和BTM模型,而WESM算法又优于WNTM模型。由于数据都是短文本数据,用于长文本的LDA模型在实验结果上略逊色于WNTM模型和BTM模型,而WESM算法是在WNTM的基础上增加了词向量模型和自注意力机制,能够更细粒度的利用词汇语义信息。主题聚合度得分越高,则模型所得到的主题质量更好,证明了引入自注意机制能够有效丰富语境语义,提高主题质量。

图3 数据集D1主题聚合度Fig.3 Data set D1 topic aggregation degree

图4 数据集D2主题聚合度Fig.4 Data set D2 topic aggregation degree
图3 和图4通过各主题聚合度得分表现,说明了WESM模型主题聚合效果上表现更出色。下面将通过查准率、召回率以及F1值对模型的其它方面做进一步验证。其中本文选取前n(其中n=10,20,30,40)个词汇计算各项指标,结果如图5、图6所示。
从图5和图6可以看出,WESM模型的平均查准率比其它三个模型更好。对图表进一步观察对比发现,针对短文本提出的WNTM和BTM模型在查准率上的表现优于LDA模型;通过WNTM和WESM的对比发现,引入词嵌入和自注意力机制确实有利于查询率的提高,验证了其对于方面提取性能的提升是有效果的。
通过图7和图8可以看出,随着词汇数量的增加,各模型的F1值都呈现下降的趋势。但WESM模型在实验中的表现还是优于其他模型。验证了词向量和自注意力机制能够丰富词汇的上下文语义特征,从而提高方面提取的性能。
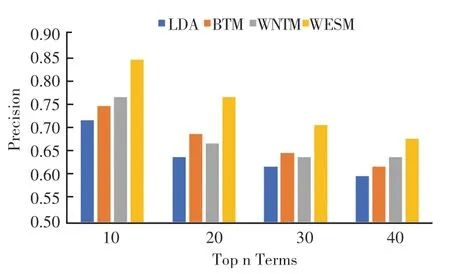
图5 数据集D1平均查准率Fig.5 Average precision of data set D1

图6 数据集D2平均查准率Fig.6 Average precision of data set D2
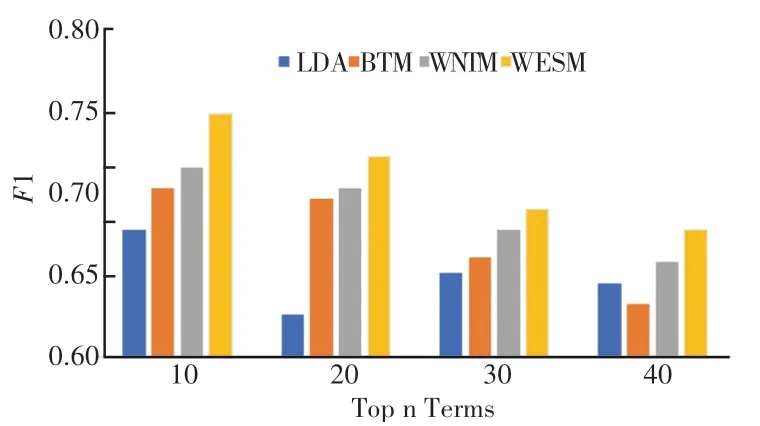
图7 数据集D1平均F1值Fig.7 Average F1 value of data set D1

图8 数据集D1平均F1值Fig.8 Average F1 value of data set D2
4 结束语
本文在词汇共现网络基础上引入了词向量模型和自注意力机制,提出了方面提取算法WESM。实验结果表明,基于本文提出的方面提取算法及自注意力机制的引入,能够丰富词汇的语义信息,得到文本的上下文语义信息。通过应用两个数据集实验,对比了相关的方面提取方法,证明了本文算法的优势所在。但是,模型仍旧存在一些不足。如,方面词汇聚类簇数要人为进行设置、参数的设定直接影响模型的性能等问题。因此,在后续研究中可以考虑是否能够将这些步骤都通过算法训练得到,减少人为对算法的影响。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
开放教育研究(2020年2期)2020-03-31 01:54:14
时代英语·高二(2018年7期)2018-12-03 09:23:06
时代英语·高二(2018年3期)2018-06-06 05:24:36
现代语文(2016年21期)2016-05-25 13:13:44
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
