
结合AdaBERT的TextCNN垃圾弹幕识别和过滤算法
2021-06-05 06:27:52孙瑞安张云华
智能计算机与应用 2021年4期
孙瑞安,张云华
(浙江理工大学 信息学院,杭州310018)
0 引 言
随着现代互联网的发展,越来越多的人在网络上寻找消磨时间的娱乐方式,其中就包括了带有趣味的弹幕视频——有弹幕飘过的视频。弹幕最初出现在日本niconcio视频网的视频里。之所以叫弹幕,是因为其就像子弹一样密集地在视频上飘过,网友借此发明视频弹幕这一网络词汇。人们可以使用弹幕发表对某一情节的看法和评论,也可以借用弹幕对一些电影进行背景介绍,让新来的观众对电影有一定的了解,方便决定自己是否要继续看下去。而有些视频的语音是外语的,而且没有提供字幕,这时候就有热心网友使用底部弹幕的形式制作中文字幕方便别人的观看。可以看出,弹幕作为一种新型网络文化有一定的趣味性和实用性。但是,当有人利用弹幕发布与视频无关的信息,比如广告、贬低别人的话语,又或者发布遮挡字幕的底部弹幕,就会影响他人的观看,甚至形成不好的社会风气,造成恶劣的后果。所以,对垃圾弹幕进行过滤是一件急需落实的措施。目前的弹幕过滤方法一般是使用关键词进行识别过滤。该方法将弹幕评论与关键词进行对比,如果匹配成功,则屏蔽该弹幕;否则不屏蔽[1]。在使用关键词进行垃圾弹幕过滤时,需要与时俱进更新新的屏蔽词,无形中又增加了时间及人力成本。所以,只使用关键词进行过滤,不仅效率较低,其准确率也不高。为了提高垃圾弹幕的识别和过滤效率,本文提出了一种结合AdaBERT自适应结构的TextCNN垃圾弹幕识别和过滤算法。与原始的BERT模型相比,使用AdaBERT压缩后的模型的参数规模大大下降,其推理速度也提升了十多倍,提升了垃圾弹幕识别模型的性能和效率。
1 相关研究
自然语言处理是机器学习的一个重要研究领域,而文本分类和文本生成是其两个研究重点。本文研究的弹幕就是一种特殊的网络文本。现在机器学习和深度学习在文本分类领域的研究发展迅速,并取得了一定的进展。
机器学习的方法主要有4种:
(1)逻辑回归方法。这种方法经常用来预测一个样例属于某个类别的概率,适用于二分类问题和多分类问题;
(2)朴素贝叶斯方法[2]。其原理依赖于数理统计的贝叶斯定理;
(3)随机森林方法。这种方法是将多个决策树的结果综合起来[3];
(4)支持向量机(Support Vector Machine,SVM)方法。其可以用于线性分类、非线性分类、回归等任务,主要思想是使用间隔进行分类[4]。
随着深度学习的发展,越来越多的深度学习模型被应用于短文本分类任务中。如,文献[5]中提出基于自编码网络的短文本流形表示方法,实现文本特征的非线性降维,可以更好地以非稀疏形式、更准确地描述短文本特征信息,提高分类效率;文献[6]提出一种基于语义理解的多元特征融合中文文本分类模型,通过嵌入层的各个通路,提取不同层次的文本特征,比神经网络模型(Convolutional Neural Network,CNN)与长短期记忆网络模型(Long Short-Term Memory,LSTM)的文本分类精度提升了8%;文献[7]使用CNN模型,将句中的词向量合成为句子向量,并作为特征训练多标签分类器完成分类任务,取得了较好的分类效果;文献[8]提出DCNN模型,在不依赖句法解析树的条件下,利用动态k-max pooling提取全局特征,取得了良好的分类效果;文献[9]采用多通道卷积神经网络模型进行监督学习,将词矢量作为输入特征,可以在不同大小的窗口内进行语义合成操作,完成文本分类任务;文献[10]结合CNN和LSTM模型的特点,提出了卷积记忆神经网络模型(Convolutional Memory Neural Network,CMNN),相比传统方法,该模型避免了具体任务的特征工程设计;文献[11]将CNN与循环神经网络(Recurrent Neural Network,RNN)有机结合,从语义层面对句子进行分类,取得良好的分类效果;文献[12]提出一种基于注意力机制的卷积神经网络,并将该网络用在句子对建模任务中,证明了注意力机制和CNN结合的有效性;文献[13]提出了一种基于弹幕内容和发送弹幕的用户标识的混合垃圾弹幕识别过滤算法,其主要考虑弹幕本身的特点来研究。
目前,迁移学习在自然语言处理的应用,主要针对第一层的微调预训练的词嵌入,而且对于不同的语言任务都要有针对性地单独训练一个模型,比较浪费时间和资源。为此,一些学者提出,通过一个大数据集下训练过的NLP模型,然后针对不同的小任务只需要细微的调些参数即可完成不同的语言处理任务。在这其中就包括BERT预训练模型[14]。BERT模型是谷歌在2018年提出的,其在11个NLP任务中打败其它所有选手,成为最受瞩目的明日之星。BERT使用Transformer进行特征提取,Transformer可以学习到语句的双向关系。BERT主要使用MLM(Mask Language Model)和NSP(Next Sentence Predication)作为训练任务。使用BERT预训练的模型只需进行微调参数就能适应各种下游任务,但BERT所需调整的参数量十分巨大,需要更好的硬件条件来运行。如何压缩BERT模型就成为某些研究者新的研究课题。Chen[15]等通过可微神经架构搜索(Differentiable Neural Architecture Search,DNAS)将BERT压缩成适应相应任务的微小模型,加快了推理速度,减少了大量参数。
2 结合AdaBERT的TextCNN垃圾弹幕识别及过滤算法模型构建
2.1 AdaBERT词向量模型
在使用BERT预训练模型时,其参数达到110M之多,给训练此模型带来一定难度。要想训练这样规模的模型需要更好的机器和更多的资费,这对于一般人是无法承担的。为在模型结构不变的情况下减少参数的规模,文献[16]提出向量参数分解的方法,将词语的大向量分解为小向量,并且将层之间的参数共享,实现了模型压缩。由于这些研究都是在不改变原始模型结构的情况下减少参数数量,而BERT在海量数据中学到了不同领域的知识。对于不同的任务,知识面是不同的。因此,需要寻找适合每种任务本身的、小的结构和知识。而AdaBERT就实现了这一目标。
AdaBERT的损失函数包含两个方面:一个是针对任务进行知识蒸馏,引导模型的搜索;二是模型效率反馈的损失,对模型的搜索过程进行剪枝。只有同时考虑这两方面的损失,才不会导致最终的模型只有效率高而有效性低,或者只有有效性高而速度却很慢。而应该找到一个效率和有效性权衡的模型。具体流程如图1所示。
图中,目标弹幕文本数据集为D t,经过调整参数后的BERT模型记为BERTt,所探索的模型空间记为S,而最终搜索到的最适合本文文本类型的模型记为s∈S。其损失函数为:

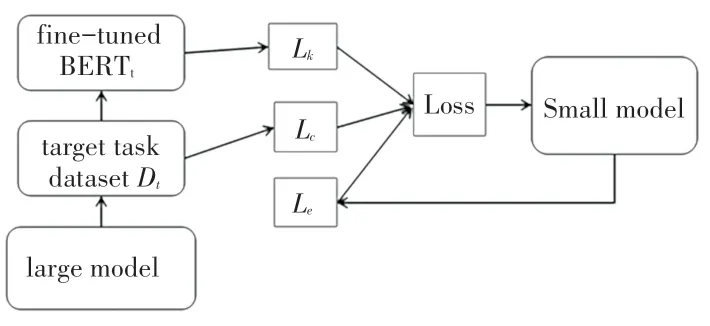
图1 AdaBERT流程Fig.1 AdaBERT process
式中,ωs是搜索到的结构s对应的训练权重;L c是和目标数据集D t相关的交叉熵损失;而L k、L e分别是面向任务的知识蒸馏损失和模型的效率损失;λ和α是平衡所有损失的超参数。
为了将搜索目标表示为分布变量,最直接的方式是建模为one-hot变量。但这样带来的问题是,离散的采样过程会使得梯度无法回传。因此,AdaBERT引入了Gumbel Softmax[17]技术,将onehot的模型结构变量松弛为连续分布y K和y o。 对于堆叠层数K相对应的第i维(表示模型结构最后堆叠i层的概率),以及候选Opearation的第i维(表示DAG中某条边最后导出第i种operation的概率):

这里,g i是Gumbel分布中采样得到的随机噪声,τ代表此分布与one-hot分布的接近程度。此后,变量都是可微的,可以直接使用相应的优化器进行损失优化。
2.2 TextCNN模型
使用TextCNN可以实现对文本的分类任务,其模型结构如图2所示。其中包括:一个用于生成词向量的嵌入层;一个包含几个卷积核的卷积层,一个卷积核可以得到len(seq)-filter_size+1个卷积结果;进入激活函数进行非线性化操作;再进行最大化池化操作;最后经过全连接传入softmax进行分类。
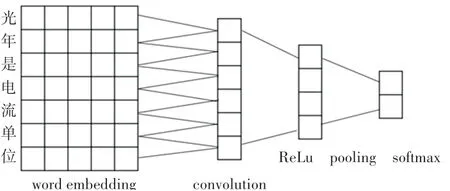
图2 TextCNN模型Fig.2 TextCNN model
2.3 结合AdaBERT的TextCNN模型
在TextCNN中一般使用word2vec或者GloVe作为词向量的选择,而AdaBERT使用Transformer可以真正识别上下文的信息。所以,本文使用AdaBERT的词向量代替TextCNN本身的词向量。BERT模型本身学习了大量百科知识,拥有很好的学习能力来学习弹幕中的上下文关系。而AdaBERT可以训练出适合本文弹幕语料集的相应结构的模型,使用AdaBERT词向量,对提高最终的模型效率和有效性有一定作用。
结合AdaBERT的TextCNN模型,在输入层对文本使用AdaBERT转换成相应的词向量,然后将所有词向量拼接成一个向量矩阵B,公式如下:
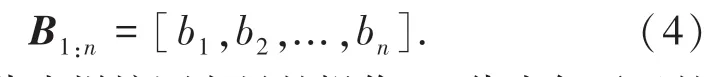
其中,[]代表拼接词向量的操作;b i代表句子里的每一个词向量;Bi:j代表将第i个词向量到第j个词向量拼接。然后使用不同的卷积核W,大小(h)分别为3、4、5。从而获得3个字符、4个字符、5个字符之间的关系。进行卷积操作得到特征Fi,如式(5)所示:
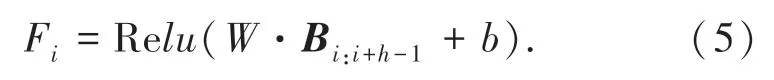
式中,b为偏差,通过R e L U激活函数生成特征F=[F1,F2,...,F n-m+h],然后进行批量归一化(BN)操作,防止维度爆炸或者弥散。再进行最大池化,最后全连接到softmax层,输出样本在不同分类上的概率,取最大值为分类结果。
本文结合AdaBERT的TextCNN模型架构如图3所示:

图3 结合AdaBERT的TextCNN模型Fig.3 TextCNN based on AdaBERT model
3 实验及结果分析
3.1 数据集和实验环境
实验主要进行模型正确性的验证。本文采集了哔哩哔哩弹幕网的《秒速五厘米》的弹幕数据作为实验的数据集。使用爬虫技术共爬取5 384 000条弹幕,经过去重、去除只有标点符号、去除表情等清理数据的手段后,剩余154 268条弹幕。对弹幕数据进行敏感词标注,再进行人工标注查漏补缺。由于垃圾弹幕属于少量异常数据,所以本文将取出与垃圾弹幕相等数量的正常弹幕,生成平衡数据集。
最终电影《秒速五厘米》的弹幕数据集一共包含6 000条带有标签的弹幕数据,其中含有3 000条正常弹幕和3 000条垃圾弹幕。弹幕数据集的标注结果见表1。

表1 弹幕数据集的标签Tab.1 Label of barrage dataset
3.2 实验结果评价标准
评判分类问题性能优劣,一般可以用正确率和错误率来评估。而在本文的数据集中,少数异常是主要的关注对象,其分类精度也就显得很重要。数据集中正常弹幕和垃圾弹幕的数量差距大,是一种不平衡的文本分类数据集,那么正误率不太适合作为这种数据集的分类算法评判指标。本文将采用精确率(Pr eci s i on)、召回率(Recal l)、F1分数(F1-s cor e)这3个指标对算法进行评估。表2所示的混淆矩阵更能直观地说明这3个概念。

表2 混淆矩阵Tab.2 Confusion matrix
精确率P表示的是预测结果为正例的数据中预测正确的比例;召回率R是指实际为正例中预测为正例的百分比。精确率和召回率之间存在一定的数量关系,即当精确率上升时,召回率会下降,反之亦然。综合考虑精确率和召回率时可以使用F1分数。以下是精确率、召回率和F1分数的计算公式:
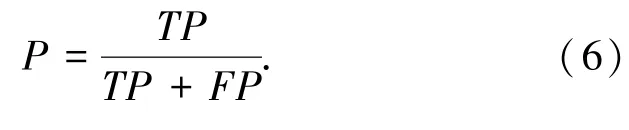

3.3 实验过程与结果分析
本次实验使用Windows10操作系统、jupyter lab平台,使用TensorFlow深度学习框架进行模型训练,主要开发语言为Python。实验数据集包含相等数量的正常弹幕和垃圾弹幕,从中随机将数据集按8:2的比例分成训练集和测试集。为说明本文提出的结合AdaBERT的TextCNN算法的优势,通过与TextCNN算法、朴素贝叶斯算法和BiLSTM算法进行对比结果,说明本文算法的有效性。实验结果见表3。
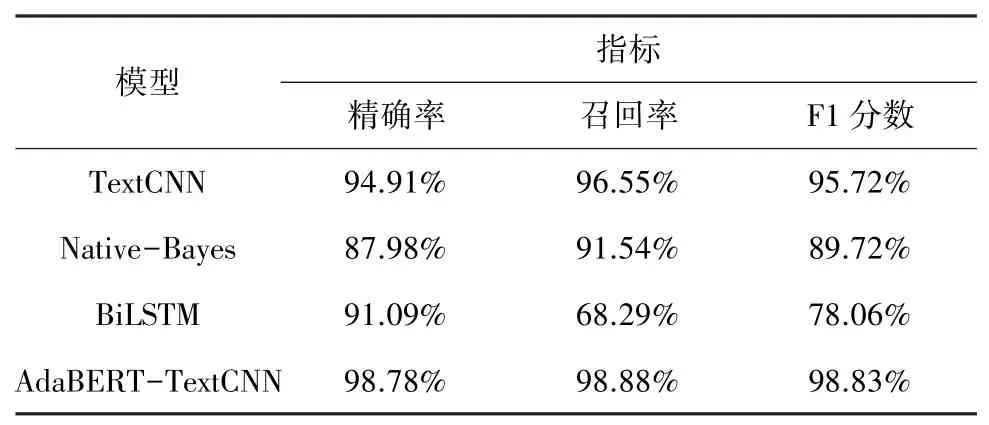
表3 实验结果Tab.3 Experimental result
从测试结果可见,本文算法的3个指标都是最高的。与使用word2vec的其它算法相比,采用AdaBERT词向量模型的TextCNN模型相关指标均更高。说明使用AdaBERT进行模型预训练得到的词向量比word2vec词向量更好。使用统计学知识计算分类概率的朴素贝叶斯模型,没有考虑词之间的上下文关系,而只是把每个词单独转换成相应的数值,并计算其属于某个类型的概率。其取得的结果必定是不准确的。TextCNN、AdaBERT-TextCNN模型都属于CNN类别的模型,而BiLSTM则属于RNN模型。CNN类型的模型比使用RNN的BiLSTM的精确率和召回率更高,这说明弹幕这种短文本类型的分类更适合使用CNN进行。在垃圾弹幕识别中上下文关系比较少,关键词的信息更多。
为了说明AdaBERT对BERT的参数优化,本文还包含了这两种方法的实验对比,结果见表4。
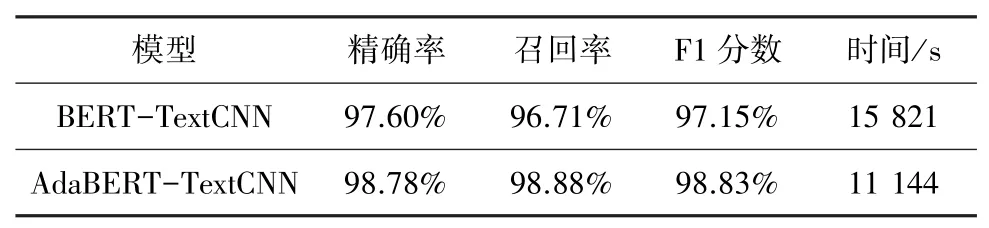
表4 时间对比Tab.4 Time comparison
从表中结果来看,使用自适应的BERT模型的确减少了训练时间,提高了模型的效率。
总体来看,本文提出的结合AdaBERT的TextCNN模型,在实验中取得较好的成果,与普通分类算法相比优势较大。使用AdaBERT相比一般BERT算法的参数更少,可以加快模型的预训练,更好的提取词向量特征,结合TextCNN后可以获得更好的模型泛化能力。可以预见,本文算法对垃圾弹幕过滤这一应用场景有较大作用,可以投入到实际的弹幕过滤系统中使用。
4 结束语
本文提出的结合AdaBERT的TextCNN垃圾弹幕识别与过滤算法模型,与以前的基于统计学的分类算法相比,有更高的准确率;与CNN类型和RNN类型的模型相比,拥有更好的泛化能力。采用AdaBERT也减少了模型的复杂程度,使得总体训练时间降低。实现了对垃圾弹幕文本更好的语义理解,获取了更准确的弹幕特征,提高垃圾弹幕识别的准确率。目前,本文只研究基于弹幕文本内容的筛选,后续将考虑加入弹幕的位置和视频内容等维度加以综合评估,进一步提高识别精确率。
猜你喜欢
中学生天地(B版)(2023年2期)2023-04-01 01:20:14
新高考·高一数学(2022年3期)2022-04-28 07:02:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
汉语世界(2021年2期)2021-04-13 02:36:18
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小学科学(学生版)(2020年10期)2020-10-28 07:52:18
电子制作(2019年11期)2019-07-04 00:34:38
小哥白尼(野生动物)(2019年3期)2019-07-01 08:27:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
