
浅析人群密度检测算法及其在机场的应用
2021-06-04 02:16好刘冬华
数字通信世界 2021年5期
关 华,万 好刘冬华
(广东机场白云信息科技有限公司,广东 广州 510470)
1 人群密度估计算法
人群密度估计算法的发展历程可归结为3个阶段:一是基于检测的方法。早期研究大部分集中在基于检测的方法,使用类似移动窗口的检测器来检测并统计人数。这些方法要求训练有素的分类器,从整个人体中提取低级特征,例如Haar 小波和HOG(方向梯度直方图)。然而,由于大多数目标对象被遮盖,它们在高度拥挤的场景上表现不佳。二是基于回归的方法。因基于检测的方法无法适用于高度拥挤的场景,学者们尝试研究基于回归的方法来学习提取自裁剪图像中特征之间的相互关系,以计算特定对象的数量,如图像的前景和纹理特征,被用于生成底层信息。Idrees 等人提出一种模型,利用傅里叶分析提取特征并实现基于SIFT(尺度不变特征变换)兴趣点的人群计数。三是基于密度估计的方法。由于卷积神经网络在分类和识别方面的成功,目前主流的方法是基于它来预测密度估计图。基于卷积神经网络生成密度估计图原理比较简单,但却能取得比基于检测的方法以及基于回归的方法更加优秀的性能。本文主要探讨基于卷积神经网络的机场人群密度估计算法设计及其在机场环境中的应用。
2 相关原理
基于卷积神经网络的人群密度估计算法,首先需要有训练图像和标签图像,然后训练一个非线性函数f,将人群图像x 映射到人群密度图像y,即

最后使用高斯核(已归一化为1)模糊每个头部标注即形成人群密度图,即
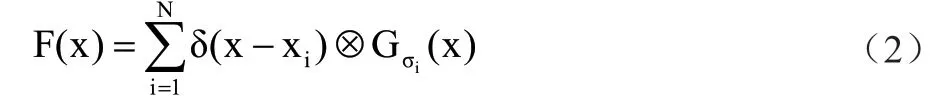
从图1、图2可以了解到输入图像中人群的分布情况,并且由标签生成的人群密度图是有具体数学意义的,从人群密度图获得人群总数只需要把密度图的所有像素值加起来即可。

图1 给定人群图像

图2 人群位置图
3 人群密度估计算法分析
3.1 多列卷积网络结构
3.1.1 MCNN
MCNN[1]是首次使用多列卷积神经网络进行人群密度估计的方法。针对人群密度检测中如何捕获大小、密度各异的人像特征的难题,设计了卷积核大小不同的3列卷积神经网络,从而使得每一列神经网络的感受野不同,以接收不同大小的人像,最后将这3列神经网络的输出进行concat(合并),从而使得网络可以捕获大、中、小三种尺寸的人像特征以生成密度估计图。如图3所示。

图3 MCNN结构
然而,作为早期应用卷积神经网络于人群密度估计的算法,MCNN 存在很大的局限性。首先MCNN 是多列卷积网络结构,较难以训练,其次MCNN 存在冗余组织,增添了计算量。
3.1.2 Switch-CNN
Switch-CNN[2]首先将输入图像分成9个子图像,然后设计专门的密度级别分类器SWITCH(3分类),依据9个子图像人群密度的不同,分别送入3列不同的神经网络预测它们的人群密度,最后把9个子图像输出结果合并,得到整张图像的人群密度估计图。但是SWITCHCNN 结构复杂,参数量大,将大量参数分配于密度级别分类,分配用于密度估计图生成的参数十分稀少,导致网络性能不佳,使得Switch-CNN 不适合用于机场人群密度估计。
3.2 新网络结构框架
3.2.1 CSRNet
CSRNet[3]针对存在的难训练、冗余结构的缺陷,系统分析了采用多列卷积神经网络进行人流密度估计的方案,提出摒弃多列结构,采用更深的卷积神经网络来进行训练,并且采用扩张卷积的方法,有效地捕获尺度、密度各异的人像特征,从而实现end-to-end 训练,并且采用更深层次地神经网络使得训练集性能与测试集均有大幅度的提升。
尽管CSRNet 比之前的人群密度估计网络在效果上有不小的提升,然而它是基于“扩张卷积”这种较新型的神经网络结构,可能难以被所有硬件设备支持,所以在机场环境下部署CSRNet 可能不是最佳选择。
3.2.2 SANet
SANet[4]先使用多列卷积网络结构提取特征,然后再使用反卷积结构生成与原输入图像相同分辨率的高质量分辨率图像,网络结构如图4所示。

图4 SANet网络结构
然而,这种结构显著的缺点是反卷积结构网络较难训练,且测试运行时间比一般卷积网络要长,而SANet追求的是生成与原图相同分辨率密度图,图上每个像素值代表的是在该像素值处存在行人的概率,这在机场实际应用中用处不大。
3.3 借助透视图辅助信息
PACNN[5]将透视图集成到人群密度估计网络中,以指导多尺度密度组合,获得更好的密度图以及人数估计。但是透视图的获取困难,且人工标注的透视图常常会有不小的误差,这给网络带来噪声干扰,导致了难以反映真实情况,限制了它的应用。
图5中,y 轴代表垂直距离,z 轴代表深度。高度为H 的行人被位于O 处的相机捕获,该行人的头部和脚部在Image 中分别为yh 和yf。相机光圈焦距为f,相机离地面高度为C。

图5 摄像机几何透视图
3.4 采用Attention 机制
3.4.1 ADCrowdNet
ADCrowdNet[6]使用不包含任何人像的图像与训练集图像构成负类和正类样本对,训练额外的卷积神经网络进行分类,依据中间图包含与类别区分相关的特征信息的特点,生成注意力图,然后将注意力图与原始图像进行点乘,再将得到的图像送入密度估计网络中,改善人群密度估计效果。但注意力图生成器AMG 的结构非常复杂,虽然AMG 的引入可以提高模型精度,但这在实际运用中势必增加额外的计算开销,对于人流视频监控模型而言弊大于利。
3.4.2 RANet
RANet[7]针对当前密度估计方法执行逐像素回归,没有考虑像素的相互依赖性,而独立的逐像素预测可能会带来噪声且预测不一致问题,采用一种具有自我注意机制的关系网络(RANet),以捕获像素的相互依赖性。RANet 通过考虑近距离和远距离像素间的相互依赖关系来分别实现局部自我注意力(LSA)和全局自我注意力机制(GSA),并引入一个关系模块,将LSA 和GSA 融合在一起,以实现更具信息量的聚合特征表示。然而,所构建的网络模型结构十分复杂,而且它要计算特征图每个像素点与其他所有像素点之间的相似度,导致大量冗余,不利于模型快速输出人群密度估计图。
3.5 使用新的代价函数
文献[8]针对传统卷积神经网络用于生成人群密度估计图采l2_loss 的不足之处,提出使用贝叶斯损失代替l2_loss,用于点监督下的人群计数估计。通过对每个注释点的计数期望值(而非注释点在密度图上的邻域内所有像素的计数值)进行监督,从而无需全图标注,提高了算法性能。模型实现简单,不需要复杂的网络结构,也不需要费力地制作人群透视图,且在多个公开人群密度数据集上均达到2019年SOTA 效果,因此适用于机场人群密度估计。
3.6 自适应人群密度标签图
静态密度图监督学习框架已广泛应用于现有方法中,该方法使用高斯核生成密度图作为学习目标,并利用欧氏距离对模型进行优化。但是,该方法对数据标记中的小偏差适应力差,并且可能无法正确反映大小变化的人像的真实分布情况。文献[9]提出了一种自适应扩张卷积和一种称为自校正(self-correction,SC)监督的新型监督学习框架,使用模型的输出来迭代校正注释,并使用SC 损失同时优化模型。但是实际实现比较繁琐,每一次迭代训练图像都要计算估计和存储每个人像的位置和高斯标准差,这样做需要耗费大量的计算开销和存储开销,也会使得训练时间加长。
4 结束语
本文分析了当前先进的人群密度估计算法,并结合机场监控视角分布的实际情况,对各方法在机场领域的适用性进行了论述,得出基于贝叶斯损失的人群密度估计算法更适用于机场环境,且该方法具有模型简单、优化性强的特点,使之在精度和速度上具有提升潜质,能为机场人群密度检测提供有效的支撑。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
科技视界(2021年4期)2021-04-13
现代信息科技(2021年17期)2021-04-05
农业机械学报(2021年1期)2021-02-01
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
