
基于联合神经网络学习的中文电力计量命名实体识别
2021-06-03 07:09肖勇郑楷洪王鑫钱斌孙凌云
浙江大学学报(理学版) 2021年3期
肖勇,郑楷洪,王鑫,钱斌,孙凌云
(1.南方电网科学研究院有限责任公司,广东广州 510663;2.浙江大学计算机学院,浙江杭州 310058)
0 引言
随着新一代人工智能技术的发展,从自然语言中提取实体、属性、关系等高层次结构化语义信息以解决各行业的实际问题是当下的研究热点[1-2]。智能电网对电力大数据所蕴含有效信息的关联分析与处理的要求也不断提高。其中,电力企业计量信息的离散化问题随数据的暴增愈加显著。电力计量信息孤立存在于各个层级单位的子系统内,互不联通,使得决策人员难以从这些离散信息中获取有效的支持[3]。如何将庞大而零散的电力计量大数据化零为整,为电力企业的决策和发展提供更为全面有效的指导,构建知识图谱是一种很好的方法。
电力知识图谱是将电力业务对象不同种类的业务信息按照此业务对象的业务架构关联组合而成的巨大信息网络[4]。使用者可通过电力知识图谱获取电力业务对象的相关业务信息、技术知识、行业标准、内在联系等综合信息,能有效提升检索信息的效率,以获得更具深度和广度的搜索结果,并将其作为全面的决策依据。
命名实体识别(named entity recognition,NER)是知识图谱构建中的一个关键性基础步骤,其经历了基于词典与规则的方法、基于统计模型的方法和基于深度学习的方法3 个阶段[5]。通用领域的主流方法是基于深度学习的方法,通过神经网络实现端到端的NER[6],不再依赖于人工定义的特征。然而,一方面,考虑中文电力计量文本的特点:(1)中文NER 比英文NER 更复杂,比如中文的词与词之间没有空格做分隔符,无类似于英文的实体单词首字母大写的指示信息,中文实体字词的随意性更强;(2)存在大量电力计量领域的专业术语和中英文缩写;另一方面,受联合学习思想的启发[7],本文设计了一种基于联合神经网络学习的中文电力计量NER 技术。联合学习认为,相比以往将NER 单独作为一项计算任务而言,联合多个计算任务(实体消歧,中文分词)可更加充分地共享信息,提高性能。
本文的贡献主要体现在以下两个方面:
(1)将CNN-BLSTM-CRF 模型与整合电力计量词典知识的中文分词模型进行联合学习,基于多任务学习技术,构建了统一NER 模型;
(2)结合电力计量领域专家的业务知识,建立了电力计量领域命名实体分类规则,并构建了基于百科数据等多数据来源的电力计量领域语料集。
实验结果表明,在不需要人工构建特征的情况下,本文方法在正确率、召回率、F值等方面均显著优于以往方法。
1 相关工作
基于词典与规划的命名实体识别方法虽然在实际工业应用中使用较多,并显现出不错的效果,但由于存在无法识别未记录在词典内词语的问题,而且构建和维护词典需要付出不小的代价,因此无法作为实体识别的核心方法,通常用于补充和对照。
基于统计模型的方法大多利用线性统计模型对完全标注或部分标注的语料进行模型训练。典型的有隐马尔可夫模型(hidden Markov model,HMM)[8]和条件随机场(conditional random field,CRF)[9],均严重依赖手工设计的特征和特定任务的训练数据,这种特定任务的统计方法开发成本高昂,使得实体识别模型难以适应新任务或新领域。
近年来,出现了各类将深度神经网络结构成功应用于NER 的新方法。其中代表性工作主要有:LAMPLE 等[10]提出利用双向长短期记忆神经网络(bidirectional long short-term memory neural network,Bi-LSTM NN)与CRF 相结合,利 用BLSTM-CRF 结构进行标签预测。该模型在英文测试数据集上获得的结果与统计方法最好结果相近,且不需要人工定义特征。CHIU 等[11]将卷积神经网络(convolutional neural network,CNN)用于抽取字符级特征,并有效提升了实体识别性能。MA等[12]将CNN 训练的字符级Embedding 加入BLSTM-CRF 模型中。该模型是一个端到端模型,不依赖特定任务的资源、功能工程或数据预处理。在CoNLL2003 语料集上,命名实体识别的F值达91.21%。
上述研究主要针对通用领域,并且测试数据集主要为英文文本。国内学者基于类似的多神经网络协作思想,提出了一些针对中文或特定领域的NER方法。其中包括面向中文语言特点[13-16]中文社交媒体领域[17-19]、医学生物领域[20-22]、国防军事领域[23-24]等。在电力领域,代表性工作主要有:樊华等[4]通过分句、分词、词性标注等语义标注信息作为预处理手段实现电网全业务域命名实体识别;ZHAO 等[25]用BLSTM-CRF 模型对2 类电力实体类别数据开展了实验分析。
上述国内学者的各项工作在各自领域均取得了不错的实验结果,但均将NER 任务作为单独步骤进行计算。联合学习的思想认为,不应该将命名实体识别任务与分词任务、命名实体消歧任务、关系提取任务等分开计算,而应统一进行联合计算,因为人脑在理解文本信息时就是如此[7]。联合学习或许是未来NER 等自然语言处理技术的发展方向,受联合学习技术等研究工作[26-28]的启发,本文提出了基于联合神经网络学习的中文电力计量命名实体识别技术,具有一定的创新性。
2 电力计量语料集构建
2.1 电力计量数据来源
通用领域的实体类别一般为人物、地点、组织机构等名称,命名格式相对规范统一,而且网上有大量的公开语料集可供模型训练。但在电力计量领域,目前并未有公开的数据集可直接用于训练,各类电力计量知识语料零散分布于网络的各个信息资源点。为解决此问题,本文自主构建了面向电力计量领域的文本语料库。
文本语料库的数据来源包含中国电力百科网(https://www.ceppedu.com/)上各类电力计量领域的期刊文献、百度百科(https://baike.baidu.com/)中半结构化的相关电力计量知识、百度文库(https://wenku.baidu.com/)中文档类和表格类的相关电力计量知识。其中,百度百科和百度文库中的电力计量知识大多为非结构化文本形式,包含各类基本概念的说明及相关原理、技术、应用的介绍等。另外,南方电网相关合作企业提供了一部分与计量相关的业务报告、计量统计数据等语料信息。
本文对获取的数据进行了清洗操作,剔除了无关信息,并以各类标点符号为标志划分语料集的句子结构,然后对语料进行实体划分。
2.2 电力计量实体分类与标注
电力计量领域的实体分类较通用领域更为复杂,且常存在命名实体边界模糊、难以界定的问题。如“电流失流”可以认为是电力现象实体,也可以认为“电流”是电力对象实体,“失流”是电力现象实体;“电量差动异常”可以认为是电力现象实体,也可以认为“电量”是电力指标实体,“差动异常”是电力现象实体。
针对这种边界模糊的情况,结合电力领域专家知识和相关书籍资料,除通用的人名、地名、时间等实体外,本文还定义了电力指标(index,I)、电力对象(object,O)、电力现象(phenomenon,P)、计量行为(meter,M)4 种类别的实体术语分类。具体如下:将与统计相关的电力数据标注为电力指标实体,如“用电量”“抄表率”等;将与电力计量相关的物体、人员、地区、机构单位等标注为电力对象实体,如“电能表”“广州供电局”等;将具体主语在电力计量过程中产生的现象标注为电力现象实体,如“电能表停走”“电流不平衡”等;将指代具体行动的某项电力计量操作标注为计量行为实体,如“抄表”“异常修复”等。此外,还注意到,不同的分类具有一定的语言学特征,尤其在词性特征上区别明确。如电力指标、电力对象等大多为名词,电力现象大多为名词+动词的组合词组,计量行为大多为动词,词性特征的不同有助于标注和训练。
结合明确的实体分类机制,在电网领域专家的指导下,本文对包含电力指标、电力对象、电力现象、计量行为等4 大类别的语料数据集采用BIO 方式进行标注,在标注过程中使用了中文实体标注工具YEDDA,利用可视化界面,通过选取待识别实体部分的文字和快捷标注按键,对大量语料进行高效标注,其内置的实体推荐功能可显著降低人工误差。对标注完的整段语料利用编写好的程序进行格式重构、字符切分和单句空行,使之符合基本语料集格式。同时,考虑批次切分是以句子为单位进行划分的,因此需对其中过长的句子进行拆分,如对整段成句或以分号间隔的大段表述等内容进行拆分。最终总计构建16 454 个句子,包含21 627 个4 种类别的电力计量实体术语,并将这些语料数据集按照8∶1的比例划分为训练集和测试集。各类实体术语的数量见表1。

表1 语料库实体数量统计Table 1 Statistics of corpus entity count
3 电力计量领域实体识别模型
3.1 模型概述
针对上述电网数据的特征,构建了基于联合学习的中文电力计量命名实体识别模型框架。结合CNN-BLSTM-CRF 模型和整合词典知识的分词模型构建联合学习NER 模型,具体结构如图1 所示。该模型利用CNN、Bi-LSTM 等神经网络和条件随机场CRF,能有效识别此类包含复杂关系的海量数据,且无须进行大量人工处理和依赖专家经验就可以自主学习。
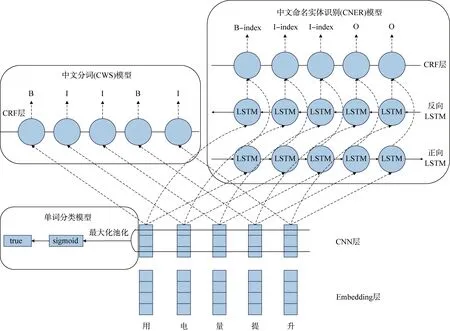
图1 神经网络的主要架构Fig.1 Main structure of neural network
该模型自底向上分别为Embedding 层、CNN层、Bi-LSTM 层和CRF 层。下面详细介绍各层模型的架构与原理。
3.2 Embedding 层
Embedding 层用于生成字符向量。字符向量模型通过将电力计量词语信息转化为低维度的稠密向量,使孤立的字、词在数值层面产生联系,便于进行深度学习计算。本文使用谷歌发布的word2vec 工具,对已整理的电力计量知识语料进行训练,为句子中的每个字生成字符Embedding。word2vec 模型可将每个词语转化为对应的向量,其中包含CBOW 和Skip-Gram 2 类模型,本文主要利用Skip-Gram 模型。该模型的算法思想见图2,通过学习各层间的权重矩阵,获取字、词表中各个位置字符的概率分布。可将输入的句子表示为s=[w1,w2,…,wn],其中,n表示句子中字符的数量,wi为第i个字符的one-hot 向量;Embedding 层的字符向量序列[x1,x2,…,xn],其中,xi为句子中第i个字符对应的字符向量。
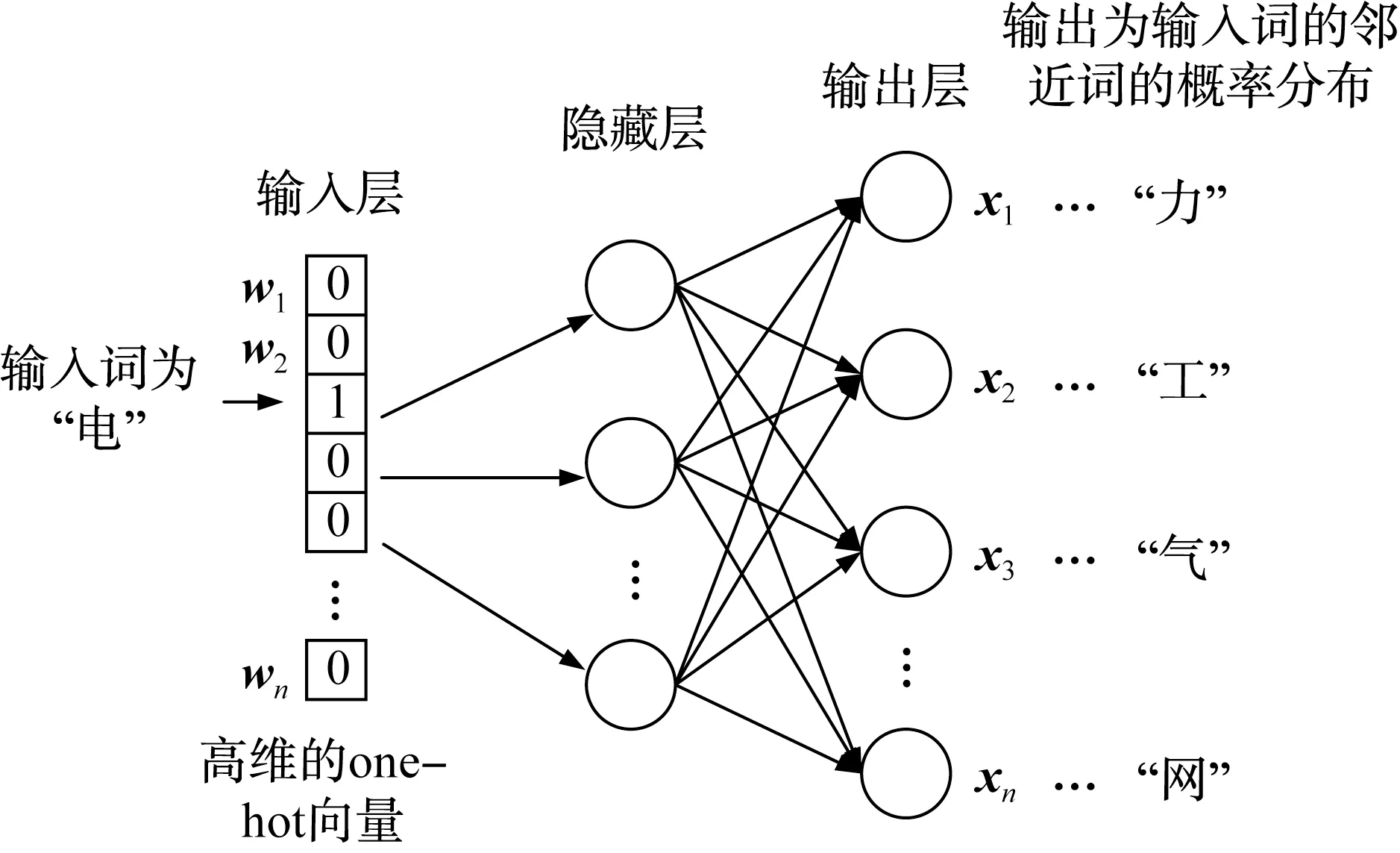
图2 Skip-Gram 模型Fig.2 Skip-Gram model
3.3 CNN 层
CNN 层常用于计算机图像处理,可有效提取局部信息。在本文模型中,则可用于提取句子的局部语境信息,这在中文命名实体识别中起十分重要的作用。如电力计量领域中的“换表”一词,其在“换表处理”中表示业务变更,而在“分库换表”中则表示计量大数据分布式架构的一种策略。考虑电力计量领域此类情况较多,因此,利用CNN 捕获局部上下文信息。
在CNN 中,W∈RKD表示滤波器,其中,K为窗口大小,D为预训练的词向量维度。由此,滤波器学习的第i个字符的上下文表示为
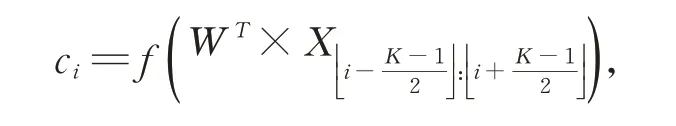
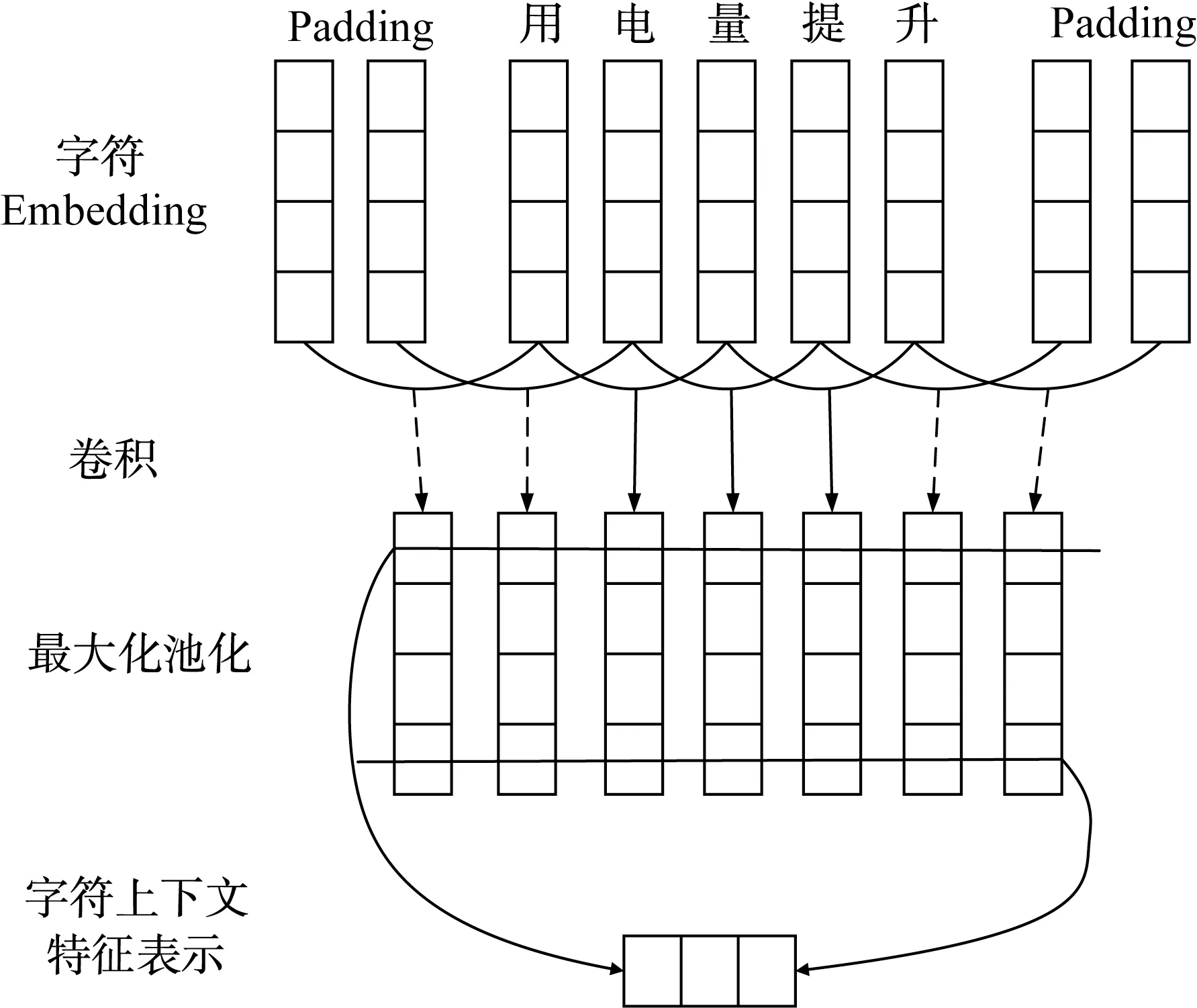
图3 提取字符上下文特征的CNN 架构Fig.3 CNN architecture of extracting character context features
3.4 Bi-LSTM 层
循环神经网络(recurrent neural network,RNN)具有一种重复神经网络模块的链式形式,可通过周期计算捕获时间动态。但传统的RNN 无法有效解决序列数据的“长距离依赖”问题,因此,在实际应用中会出现梯度消失或梯度爆炸现象[29]。
LSTM 是一种特殊的RNN,弥补了传统RNN的不足,可捕获长距离序列信息,因此很适用于电力计量命名实体识别。通常,一个LSTM 单元包含遗忘门、输入门和输出门,这些门控制信息遗忘和传递给下一时间步骤的信息比例。图4 给出了LSTM 单元的基本结构。
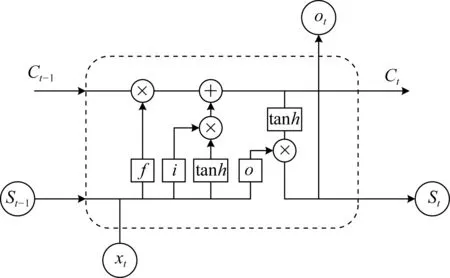
图4 LSTM 网络结构单元Fig.4 LSTM network structure unit
RNN 和LSTM 的输出预测是单向的,但在电力计量实体识别中需要同时根据之前与之后的状态信息进行判断,只有这样才能同时兼顾上下文信息。Bi-LSTM 层通过正向LSTM 和反向LSTM 分别计算考虑左侧词和右侧词时每个词对应的向量,然后连接2 个向量,形成词的向量输出。也就是说由这2 个LSTM 的状态共同决定最终输出。
3.5 CRF 层
实体识别作为一种序列标注问题,考虑相邻标签之间的相关性,CRF 联合建模标签序列是一种很有效的方法。
给定训练数据集,CRF 模型通过极大似然估计得到条件概率模型。假设X={x1,x2,…,xn}为输入序列向量的完全展开式,xn为经过前一模块处理后序列中第n个汉字的向量表示。Y={y1,y2,…,yn}为对应的标签序列,yn为第n个汉字xn对应的标签。那么,在给定变量x的情况下,可将CRF 概率模型看作通过对应的标签y计算概率P,即

其中,x为隐藏表示,y为句子的标注序列,通过极大似然估计可得到式(2)的最优解。最后,通过解码得到与最优解相对应的标签序列y*。
3.6 整合词典知识的分词联合训练
NER 任务可看作2 个子任务的组合:从文本中提取实体名称与根据其类型进行分类。由于中文文本无明确的词分隔符,因此识别中文实体名称的边界十分具有挑战性。
在中文自然语言处理领域,中文分词(Chinese word segmentation,CWS)的目的是划分中文语句的单词边界,因此通常将CWS 作为中文命名实体识别(Chinese named entity recognition,CNER)的前序步骤,以提升CNER 预测实体边界的准确性。而CWS 本质上也属于一类字符级序列标注问题,与CNER 的计算过程类似,经常用CRF 方法处理。为此,提出通过联合训练CNER 和CWS 模型提高CNER 模型识别实体边界的能力。
但是面向通用领域的CWS 模型在处理电力计量语料时存在一定问题,如语句“临江公寓部分用户存在电量波动异常情况”,若“电量波动异常”这一电力现象实体词汇没有出现在标注的数据中或仅出现了几次,则很有可能将此句子分割为“临江公寓/部分/用户/存在/电量/波动/异常/情况”,因为“电量”“波动”“异常”3 个均为常用词,可能经常出现在标签中。这就给领域分词带来了较大的困难。为解决此问题,考虑电力领域的专业词典中包含了许多电力计量的专业术语,若将上述CNER 模型与专业词典中的知识结合,使CNER 模型能够像行业专家一样全面学习电力计量专业术语,则可更好地为此类句子分词,并进行命名实体识别。
为此,本文设计了多任务学习,并在联合训练模型中增添了单词分类这一额外任务。可根据其是否属于电力计量实体词汇对一串汉字序列进行分类。例如,字符序列“电量波动异常”将被分类为true,而字符序列“电置工动异常”将被分类为false。true 样本从专业词典中选取词汇,而false 样本则从词典中随机抽取1 个词汇,然后将该词汇中的每个字以概率p随机替换为另一个随机选择的字。重复此步骤直至获得预定义的样本数。
本文将神经网络应用于单词分类任务,其结构与CWS 的CNN-CRF 体系结构类似,不同之处在于CRF 层被最大池化层和sigmoid 函数层替代,从而进行了二分分类。单词分类任务的损失函数为
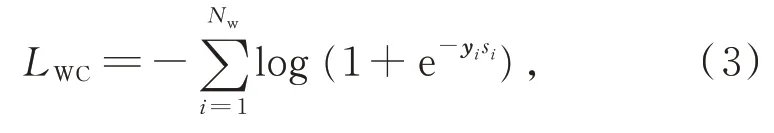
其中,Nw为用于单词分类的训练样本数量,si为第i个样本的预测分数,而yi为1 或0 的单词分类标签(1表示true,0 代表false)。
基于多任务学习思想,本文设计的联合模型可用于共同训练电力计量领域的单词分类模型、CWS模型和CNER 模型。如图1 所示,框架中的单词分类模型、CWS 模型和CNER 模型共享相同的字符嵌入和CNN 网络。其中,CNER 模型中,B,I,O 为BIO 标注方式;CWS 模型中,B,I 为2-tag 标注方式,B 表示词首,I 表示词的其他位置。通过此方式,可对分词中的有用信息进行编码,以学习有助于单词边界区分的上下文字符表示形式,这对预测实体边界具有很好的效果。CWS 模型的损失函数为
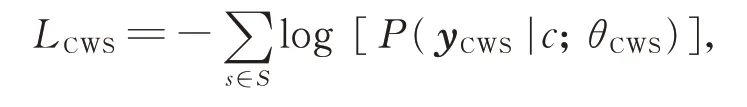
其中,yCWS为用于句子分词的标注序列,θCWS为模型中的参数集,c为从CNN 层中输出的句子隐藏字符表示。
联合模型的最终目标函数为CNER 损失、CWS损失和WC 损失的组合,即
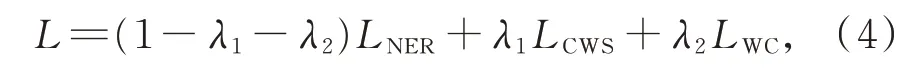
其中,λ1为控制CWS 损失在总损失中相对重要性的系数,λ2为控制单词分类损失在CWS 损失中相对重要性的系数。
4 实 验
4.1 实验设置
所构建的语料库包含了328 篇电力计量相关的文本文献,共计16 454 个句子,包含21 627 个4 种实体类别的电力计量技术术语。将语料数据集按8∶1的比例选择292 篇作为训练集,36 篇作为测试集。在实验中采用正确率、召回率、F值3 个通用指标衡量电力计量命名实体识别的性能。
本实验框架基于PyTorch,运行环境为python3.6.4,CRF 运行版本为CRF++0.58,操作系统为Windows10,CPU 为第4 代酷睿i5-4210H@2.90 GHz,内存为16 GB。
字符嵌入的预训练工具为word2vec,字符嵌入维度为100。CNN 网络中的滤波器数量设置为300,LSTM 的隐藏状态层数量为200,使用随机梯度下降算法训练模型。此外,在多任务学习的整合词典知识部分选用由中国电力出版社出版的《新英汉·汉英电力工程技术词典》[30],从中选取1 200 多条与电力计量领域相关的专业术语作为true 样本。
4.2 实验结果与对比
设计3 组实验,分别用于检验模型的实验效果、找到模型最优状态下的相关参数、检验系数λ1和λ2的影响。
实验1检验并对比基于CRF,基于BLSTMCRF、基于 CNN-BLSTM-CRF、基于 CNNBLSTM-CRF 与CWS 联合、基于CNN-BLSTMCRF 与整合词典知识的CWS 联合5 种模型的电力计量实体识别效果,每组实验进行5 次,取平均值,实验结果见表2,其中加粗值为最优结果。
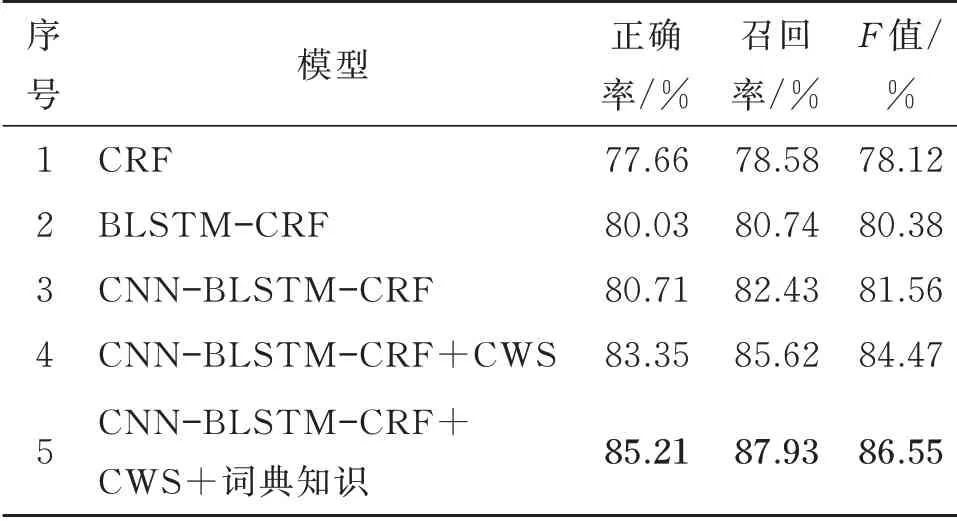
表2 各模型的实验结果Table 2 Experimental results of each model
由表2 可知,本文提出的基于CNN-BLSTM-CRF 与整合词典知识的CWS 联合模型在正确率、召回率和F值3 个指标上均较其他4 种模型有明显提高。另外,还可发现:
(1)相较于CRF 模型,CNN-BLSTM-CRF 与整合词典知识的CWS 联合模型的F值提升了8.43%,表现出深度学习神经网络应用在电力计量实体识别中有很好的效果,显著优于传统机器学习方法。
(2)CNN-BLSTM-CRF 模型较 BLSTMCRF 模型的F值提升了1.18%,显示CNN 有助于学习局部上下文特征。
(3)相较于CNN-BLSTM-CRF 模型,CNNBLSTM-CRF 与CWS 联合模型的F值提升了2.91%,表明CWS 识别单词边界的能力有助于CNER 模型识别实体边界。统一框架发挥了两者内在联系的作用,使得CNER 的识别效果得以提升。
(4)相较于CNN-BLSTM-CRF+CWS 模型,CNN-BLSTM-CRF 整合词典知识的CWS 联合模型的F值提升了2.08%。说明结合词典知识有助于提升通用领域的分词模型识别电力计量术语词汇的准确性,能使模型单独分割专业术语,辅助NER 模型更好地识别相关实体。
表3 列出了本文模型在各实体类别上的识别性能。通过比较4 类实体识别数据,可发现电力指标和电力对象2 类实体的识别效果相对较好,电力现象和计量行为2 类实体的识别效果欠理想。究其原因,一方面,电力现象和计量行为的实体数量在训练集中占比较少,使得训练效果较其他两类差。另一方面,电力指标和电力对象的实体名称格式相对统一,重复出现率较高,而电力现象和计量行为在实体词汇的结构上更为复杂,词语的平均长度更长,导致分词更困难,稀有度太高影响训练效果。
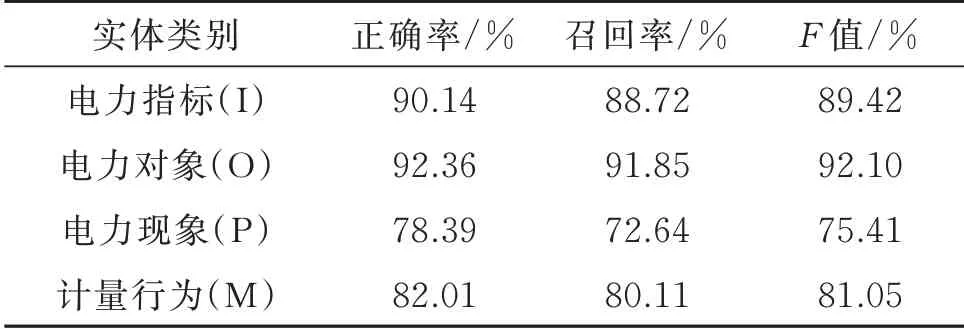
表3 各实体类别识别性能Table 3 Identification performance of each entity type
实验2调整神经网络模型参数获得最佳识别效果。利用预训练得到100 维字符向量。实验过程中改变神经网络训练中的各项参数。
如表4 所示,设定几组batch-size 和学习率,在每个训练阶段将学习率更新为ϑt=ϑ0/(1+ρt),衰减率ρ=0.05,t为完成的迭代周期。整体模型训练用GTX1060 进行加速。由于dropout 是缓解过拟合的有效方法,因此,模型在CNN 的输入、BLSTM 的输入和输出向量上应用dropout,以提升模型的泛化能力。通过所有的实验,最后设定所有dropout 层的dropout 率为0.5,在该数值下模型性能得到显著提升。
对初始嵌入进行微调,在神经网络模型的梯度更新过程中,通过反向传播梯度对其进行修改(此方法的有效性已在序列和结构化预测问题中得到验证[31])。通过改变学习率和batch-size 2 类参数寻找最优参数状态。
由表4 可知,当batch-size 为32 时,F值最高,继续增加batch-size,识别效果有所降低。
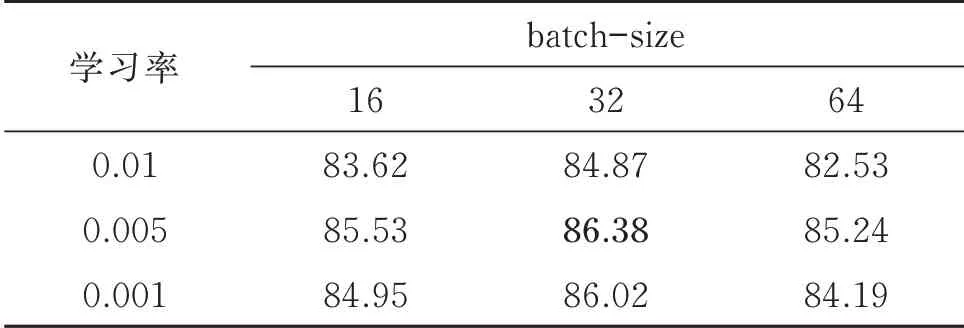
表4 深度学习调整参数对应的F 值Table 4 F value corresponding to deep learning adjustment parameter 单位:%
实验3检验系数λ1、λ2的影响。控制最终损失的有2 个重要参数:λ1控制中文分词任务的相对重要性,λ2控制词典知识分类的相对重要性。λ1和λ2对本文方法的性能影响分别见图5 和图6。
本文采取控制变量法,固定其中一个λ值为0.2,通过另一个λ值的变化获得变化趋势。从图5和图6 中可以看出,随着λ1,λ2逐渐增大,F值均不断增大,当λ1和λ2的值大于0.5 后,F值均呈下降趋势。当λ1,λ2的值过小时,因中文分词与词典知识所起的作用受到限制,无法充分发挥其中有用信息的作用,初始识别效果不佳;而当λ1,λ2的值过大时,中文分词与词典知识部分被过分强调,本末倒置,使性能下降。总体上说,当λ1,λ2为0.3~0.5 时,性能相对较优。
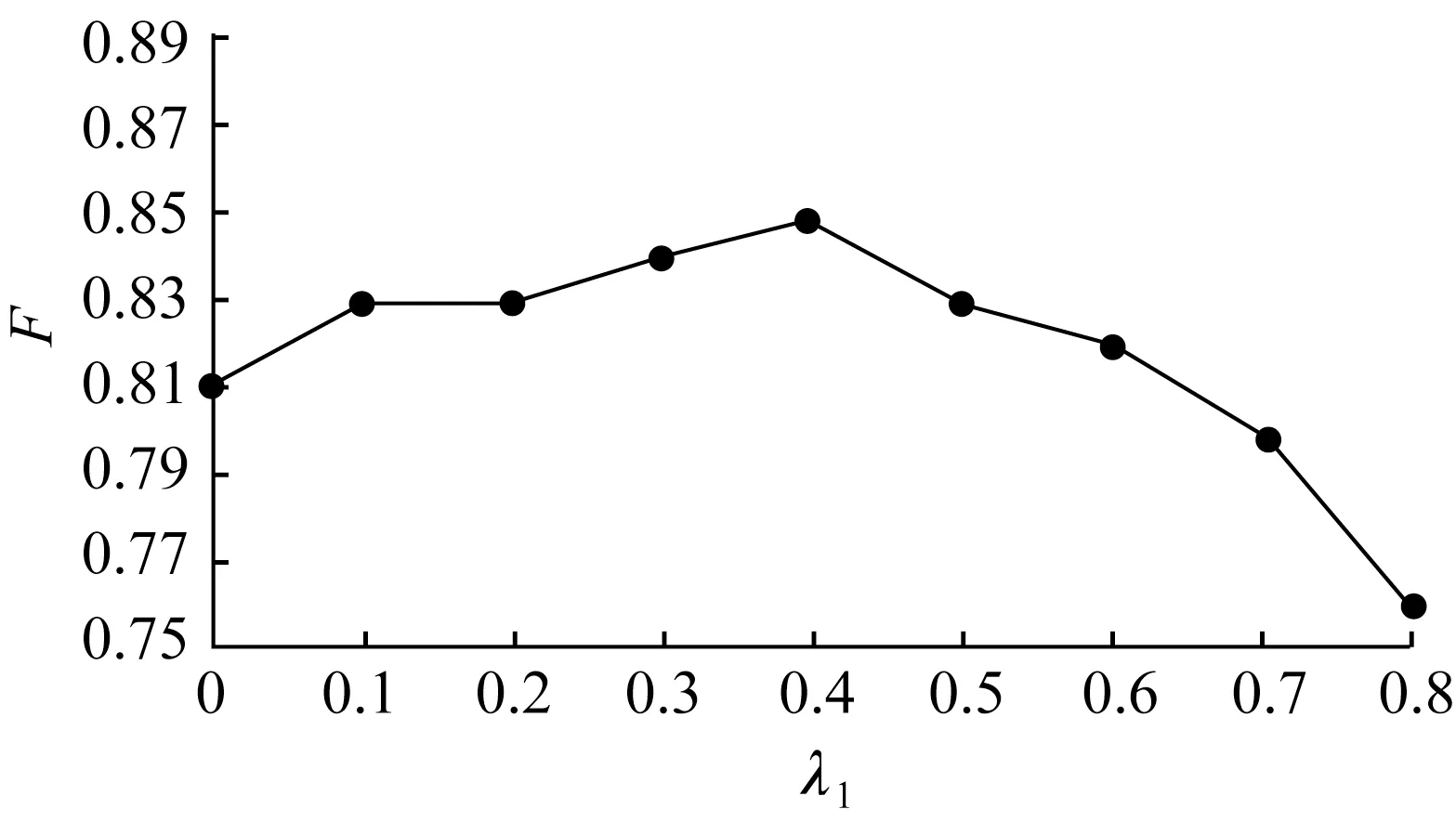
图5 λ1 的影响Fig.5 The influence of λ1
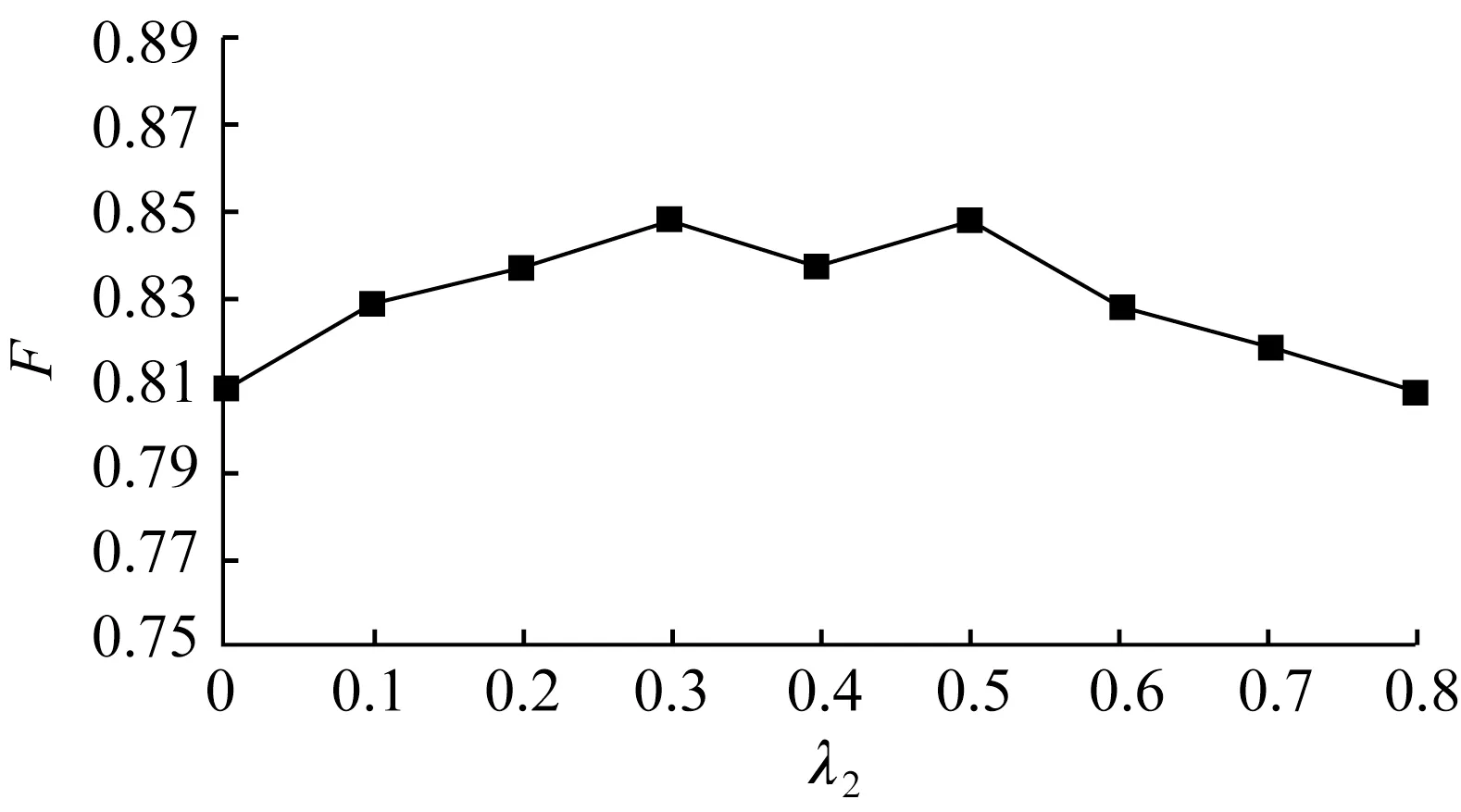
图6 λ2 的影响Fig.6 The influence of λ2
本文构建了一个实体识别系统,可以对输入文本进行识别测试,图7 显示的为从测试集中摘取部分文字的测试结果。经分词处理后,词与词之间用空格隔开,同时对电力计量领域的专业技术词汇对应的实体标签(如meter,index)和彩色背景进行了标示,对应关系见图7 左侧方框。

图7 实体识别结果展示Fig.7 Entity recognition results
5 结论
为充分挖掘电力计量领域中海量数据的价值,更为全面准确地构建电力知识图谱,将基于深度学习的神经网络算法模型应用于电力计量领域,以提升命名实体识别效果。本文创新性地提出基于联合神经网络学习的中文电力计量命名实体识别方法。该方法联合了CWS 模型,使用电力计量词典知识,对大规模电力百科知识文本与电力计量数据进行中文分词并生成字符向量,将该向量序列经过CNN 训练获得的字符进行上下文特征表示,通过Bi-LSTM 层和CRF 层的训练获得NER 结果。将本文模型与以往主流模型在电力计量实体识别实验中进行了对比分析。此外,本文还创新性地提出了电力计量实体分类方法,并将其用于实验分析。
实验结果表明,本文方法有效结合了CNER、CWS 与领域专业术语知识,对含有中英文缩写、各类长短词组的电力信息及稀有的电力专业术语的识别更为有效,实际应用价值较高。
本文模型仍存在待提升之处。如(1)如何在模型中加入具有中文特点的特征(中文偏旁部首级别的特征等),中文词性分析、中文句法分析等;(2)如何将更多的自然语言处理任务引入本模型;(3)当某种类型训练数据输入偏少时,会影响该类型的识别精确度,如何解决此问题,进一步提升模型的泛化能力。这些均为未来的研究方向。
猜你喜欢
厦门大学学报(自然科学版)(2021年4期)2021-06-22
校园英语·月末(2021年13期)2021-03-15
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
计算机应用与软件(2018年9期)2018-09-26
外语教学理论与实践(2014年2期)2014-06-21
