
矿山人员行为视觉语义方法研究
2021-06-02 09:55戈琛闫雨寒刘晓文丁恩杰
工矿自动化 2021年5期
戈琛, 闫雨寒, 刘晓文 , 丁恩杰
(1.中国矿业大学 物联网(感知矿山)研究中心, 江苏 徐州 221008;2.中国矿业大学 信息与控制工程学院, 江苏 徐州 221116;3.中国矿业大学 电气与动力工程学院, 江苏 徐州 221116;4.中国矿业大学 江苏省煤矿电气与自动化工程实验室, 江苏 徐州 221116)
0 引言
煤矿井下人员行为检测是感知矿山建设关注的重点。评判矿山人员行为是否安全需要充分考虑时间、地点、行为、环境等多方面因素[1]。而现有的人员行为检测方法无法综合多方面因素评判矿山人员行为是否安全,如:基于电磁波的行为检测方法通过处理人员动作引起的收发端电磁波信号路径变化来识别人员行为,仅能识别人员特定动作,无法识别行为的交互对象;基于可穿戴设备的行为检测方法通过分析便携式人体穿戴设备捕获的运动数据进行行为识别,注重人的行为,忽略了行为与设备、环境间的交互;基于计算机视觉的行为检测方法通过从视频片段中提取人体运动信息进行行为识别,存在对环境状态估计不足的缺点。
视觉语义技术能在很大程度上解决上述问题。视觉语义通过分析输入图像或视频内容,自动生成1个或若干语句的文本语言,对视觉场景中的内容(地点、人物、行为、行为交互对象等)进行描述。该技术利用计算机模仿人眼“视觉功能”和大脑的“语言功能”,以自然语言形式自动描述视觉场景内容,有效连接了视觉信息和语言信息, 能够更加全面地评判矿山人员行为是否安全[2]。
本文提出一种矿山人员行为视觉语义方法。该方法采用具有自学习比例参数、并行双重注意力机制的InceptionV4网络提取视频静态特征,采用预训练的I3D网络提取视频动态特征,对动静态特征拼接后得到视频特征;针对视频内容与生成语义描述语句不一致问题,采用语义检测网络(Semantic Compositional Network,SCN)显式地将视觉语义特征、视频特征、嵌入特征共同作为解码器的输入,通过特征重构从解码器隐藏层状态中重构视频特征。实验结果表明,该方法具有良好的语义一致性,生成的语义描述语句能够准确反映视频内容。
1 视觉语义方法原理
矿山人员行为视觉语义方法包括特征提取、语义检测、特征重构、解码部分,如图1所示。在特征提取部分,采用在ImageNet ILSVRC2012数据集上预训练的InceptionV4网络提取视频图像静态特征,采用在Kinetics-400数据集上预训练的I3D网络提取动态特征,之后将动静态特征沿通道维度进行拼接融合。在InceptionV4网络引入双重注意力机制,以提升网络对视频特征的建模能力。语义检测通过语义标注建立视频特征与描述语句之间的关联性。特征重构通过提取解码器隐藏层状态重构视频特征,提高了视觉语义生成的准确性。
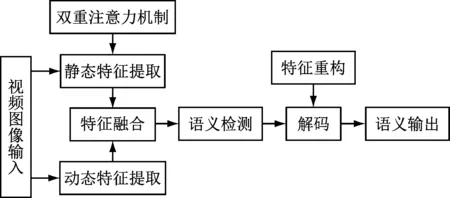
图1 矿山人员行为视觉语义方法Fig.1 Visual semantic method of mine personnel behavior
2 视频图像特征提取
由于矿井视频图像中主体、光线、参照物等因素会动态变化,从相同区域提取出的特征可能存在一定差异,导致特征表示不一致问题,影响矿山人员行为识别准确性。针对该问题,提出一种具有自学习比例参数的并行双重注意力机制:引入空间位置注意力模型,建立了不同空间位置特征之间的相关性,以聚合全局上下文信息;构建通道注意力模型,优化了多通道特征之间的相互依赖关系;通过自学习比例参数使特征提取网络在训练过程中学习到最优的注意力权重分配比例,以达到改善特征提取网络特征表示的目的。
2.1 空间位置注意力模型
获取特征的全局上下文表示对于视觉语义至关重要[3]。为了在局部特征空间建立丰富的特征上下文关系,引入具有自学习比例参数的空间位置注意力模型,将上下文信息聚合到局部特征中,以增强视频特征表示能力。空间位置注意力模型如图2所示。

图2 空间位置注意力模型Fig.2 Spatial location attention model
对于输入的原始图像A∈RC×H×W(C为图像通道数,H,W分别为图像高度、宽度),通过卷积操作生成3个相同的特征图B1,B2,B3。对特征图B1进行重塑和转置操作后,与经重塑的特征图B2进行矩阵相乘操作,再经softmax函数得到空间位置注意力特征权重,并与经重塑的特征图B3进行矩阵相乘操作,所得结果与原始特征图进行逐元素求和运算,得到空间位置注意力特征图E=[e1e2…eN](N为图像像素点总数)。
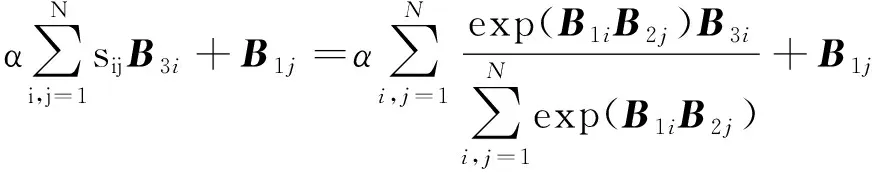
(1)
式中:ej为输出特征图E中第j个像素点特征;α为空间位置注意力自学习比例参数,初始值为0,并通过学习逐渐更新;sij为B1中第i个像素点与B2中第j个像素点的相似性;Bmi,Bmj为特征图Bm中第i,j个像素点特征,m=1,2,3。
由式(1)可知,空间位置注意力模型通过图像空间位置的相似性来衡量特征之间的相关性,二者呈正相关关系。利用重塑和转置建立原始图像不同位置像素点之间的相关性,得到空间位置注意力特征权重后,将其加权到原始特征图中,得到空间位置注意力特征图,因此空间位置注意力模型能够在捕获不同位置像素点之间相关性的同时,实现全局上下文信息聚合,并使处于不同位置的相似语义特征建立联系,增强了共同的特征表示能力,达到改善特征紧凑性和语义一致性的目的。
2.2 通道注意力模型
通常一组通道特征图可看作是对一组不同图像的响应,而不同的通道特征图之间具有一定的相互依赖关系[4]。本文充分利用该关系,构建了通道注意力模型,通过特征通道权重对原始特征图进行加权操作,从而改善特定语义的特征表示。通道注意力模型如图3所示。其采用挤压函数与激励函数生成注意力权重,进而实现特征重校准,构建通道特征之间的相关性,并通过学习特征的全局信息获取更高质量的特征表示。
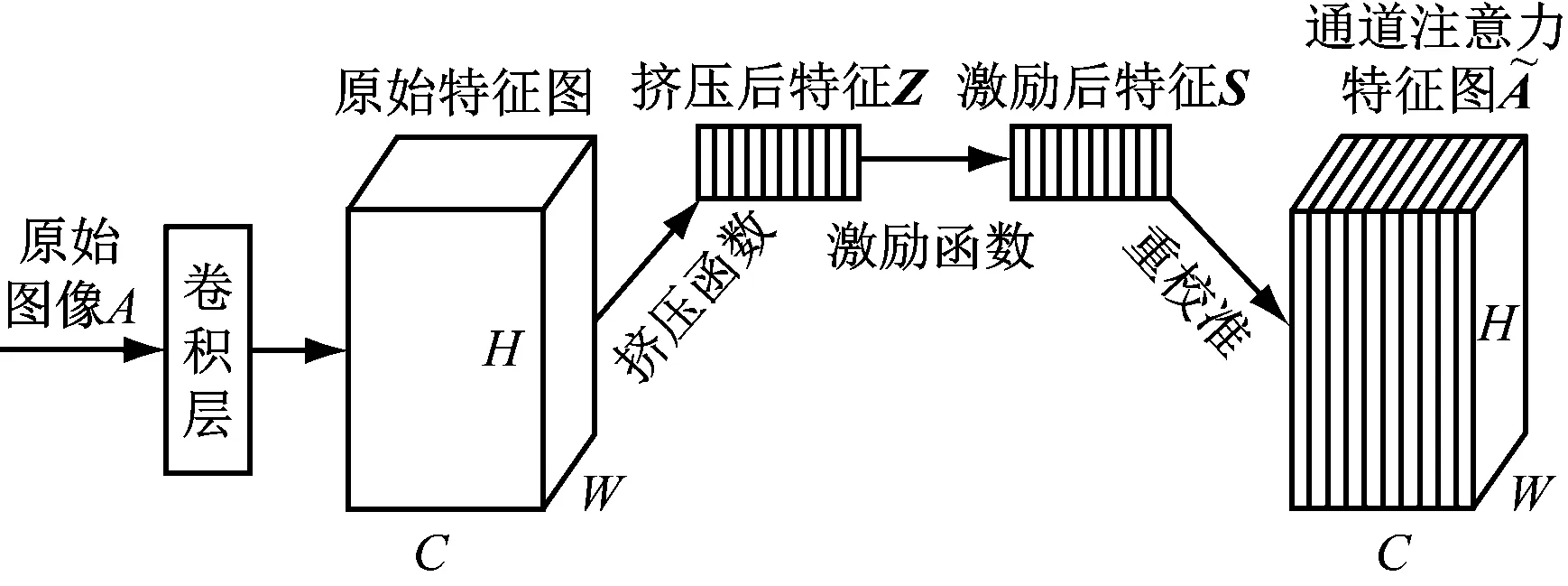
图3 通道注意力模型Fig.3 Chanel attention model
对于输入的原始图像A,利用全局平均池化对其进行降维和压缩操作,得到一组通道特征权重描述符Z。Z中第k(k=1,2,…,C)个特征权重为
(2)
式中:Fsq()为挤压函数;uik为降维后特征图中第i个像素点的第k个特征。
将通道特征权重描述符Z通过门控单元输入激励函数,得到激励后的特征S。
S=Fex(Z,D)=σ(g(Z,D))
(3)
式中:Fex()为激励函数;D为待训练参数;σ()为ReLU激活函数;g()为门控单元。
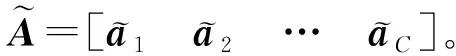
(4)

通过挤压、激励、重校准操作,将原始图像转换为通道注意力特征图,清晰显示了不同通道之间的权重分布关系和相互依赖性,增强了特征可分辨性。
2.3 双重注意力模型
在提取视频静态特征时,将空间位置注意力模型和通道注意力模型以并行方式构建双重注意力模型,通过自学习比例参数自适应调整注意力加权系数,再利用该模型提取视频图像特征。双重注意力模型如图4所示。

图4 双重注意力模型Fig.4 Dual-attention model
对于每段输入视频,以5帧的固定间隔提取视频帧,将其调整为299×299标准像素大小,作为特征提取网络的输入,平均每段视频提取32帧图像,对帧数不足的进行补零。将视频帧图像输入预训练的InceptionV4网络,每帧通道维度为1 536。通过在InceptionV4网络中引入双重注意力模型,优化网络对视频特征的提取能力。采用torch.cat()函数将InceptionV4网络提取的静态特征和I3D网络提取的动态特征进行拼接,得到视频特征。
3 语义检测
采用注意力机制执行视觉语义任务时,若直接采用解码器生成视频语义,会出现视频内容与描述语句不一致的情况,主要原因是视频特征与实际视频语义存在偏差[5-6]。针对该问题,设计了语义检测模块,通过为输入视频添加高级语义标签生成嵌入特征,将视频特征、语义特征、嵌入特征共同作为解码器输入,进一步改善了视觉语义准确性。
3.1 语义检测机制
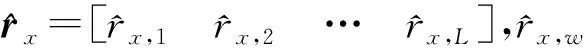
rx=σ(f(vx))
(5)
式中f()为基于多层感知机的非线性映射函数。
3.2 语义检测网络
本文采用LSTM(Long Short-Term Memory,长短期记忆)网络实现语义检测。LSTM通过门控单元来遗忘和更新单元状态,忽略了输入序列中的语义信息[7]。针对该问题,采用SCN对LSTM每个权重矩阵进行扩展,以增加语义标签权重。
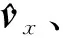
(6)
(7)
(8)
式中:Vb,Yb,Gb为待训练参数,b∈{c,d,l,o},c,d,l,o分别为LSTM细胞状态、输入门、遗忘门和输出门;⊙表示逐元素乘法。
4 特征重构
由于视频帧具有多样性和高维度特性,采用的LSTM解码器无法直接重构出输入视频。因此,设计了特征重构模块,通过获取LSTM隐藏层状态来重建视频特征,增强视频特征与描述语句之间的关联关系,提高视觉语义生成的准确性。
特征重构原理如图5所示。通过对LSTM隐藏层状态进行注意力加权生成上下文信息,再通过LSTM逐帧生成重构帧特征。

图5 特征重构原理Fig.5 Characteristic reconfiguration principle
第t帧视频的上下文信息为
(9)

(10)
(11)

为了优化特征重构模块,将损失函数定义为
(12)
式中:PI为第I个隐藏层输出语义和视频特征的概率;λ为比例系数。
采用重构特征损失函数优化整体模型,并通过比例系数λ平衡原始视频特征和重构特征的关系,在原始特征的基础上增加更多的特征信息。本文设置λ=0.1。
5 实验与结果分析
实验环境为Ubuntu18.0.4系统,采用GTX1080Ti 11G型GPU加速运算,基于Python语言编写代码,程序运行环境为Pytorch深度学习框架。
采用MSVD[8]和MSR-VTT[9]公共数据集作为实验数据来源。针对MSVD数据集,设置初始学习率为2×10-5和4×10-5;针对MSR-VTT数据集,设置初始学习率为4×10-5。训练时采用AMSGrad优化算法,并采用5轮训练后没有改善情况下,初始学习率衰减为初始值0.5倍的衰减策略。对于2种数据集,均采用提前终止策略在训练25个周期时终止,测试时采用集束宽度为5的集束搜索算法生成描述语句。采用Microsoft COCO公开评估服务器的BELU,METEOR,ROUGE-L,CIDEr指标评估各视觉语义方法性能。
不同视觉语义方法在2种数据集上的实验结果见表1、表2。可看出本文方法的4个指标均较优异,说明其在生成视觉语义时能够获取视频中的高级语义特征,并通过特征重构为解码器提供更多的特征信息,使得生成的描述语句更准确地反映视频的真实含义。
除针对不同方法进行定量分析外,在自制矿山视频数据集上进行实验。矿山视频与开源公共数据集不同,需要更加规范化的统一描述。对于公共数据集,一段视频样本有多样性描述,可丰富样本量,多角度地训练网络模型,提高模型的泛化能力。而对于矿山视频数据集,需要单一的规范化描述。本文对生成的语义采取固定格式:人(动作主体)+行为(动作)+目标(动作交互对象)+地点(环境位置)。采用本文方法对图6中的视频帧生成描述语句,并与文献[19]中MA方法生成的语句进行比较。图6(a)中视频帧显示一名矿工正在巷道内摘安全帽,正确视觉语义为“a miner is taking off the safety helmet at the mine passage”,主语对象为“a miner”,关键动词“take off”表明矿工动作,宾语“the safety helmet”表明矿工动作的交互对象是安全帽。MA方法生成描述语句为“a man is playing helmet”。其中主语为“a man”,说明MA方法在特征提取时未能准确捕获关键人物特征;由于缺少语义指导,在生成“take off”这一关键动作时出现偏差。本文方法生成描述语句为“a miner is taking off helmet at the mine passage”,准确获取了视频中“摘安全帽”这一关键动作语义,生成了更准确的描述语句。图6(b)中视频显示一名矿工正在巷道内吃食物,正确视觉语义为“a miner is eating food at the mine passage”。MA方法生成描述语句为“a man is eating”。本文方法生成描述语句为“a miner is eating food at the mine passage”,准确获取了视频中的关键语义。

表1 不同视觉语义方法在MSVD数据集上的实验结果对比Table 1 Comparison among experiment results of different visual semantic methods by use of MSVD data set %

表2 不同视觉语义方法在MSR-VTT数据集上的实验结果对比Table 2 Comparison among experiment results of different visual semantic methods by use of MSR-VTT data set %



(a) 摘安全帽行为



(b) 吃食物行为
6 结论
(1) 矿山人员行为视觉语义方法通过对输入视频进行特征提取、语义检测、解码等,生成描述人员行为的语句。该方法针对视频静态特征引入双重注意力机制,通过构建空间位置注意力模型和通道注意力模型,提高对视频特征的表征能力;针对输入视频与描述语句关联性不强的问题,引入语义检测和特征重构,提高了视频语义生成的准确性。
(2) 采用公共数据集MSVD,MSR-VTT及自制矿山视频数据集,对本文方法进行了实验,并与多种视觉语义方法进行对比,结果表明本文方法具有较好的语义一致性,能准确获取视频中关键语义,更好地反映视频真实含义。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
摄影世界(2022年1期)2022-01-21
新世纪智能(语文备考)(2020年4期)2020-07-25
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
