
基于ATT&CK的APT攻击语义规则构建
2021-06-02 08:35潘亚峰周天阳朱俊虎曾子懿
信息安全学报 2021年3期
潘亚峰, 周天阳,2, 朱俊虎,2, 曾子懿,2
1信息工程大学 数学工程与先进计算国家重点实验室 郑州 中国 450001
2国家数字交换系统工程技术研究中心 郑州 中国 450001
1 引言
随着高级持续威胁(Advanced and Persistent Threat, APT)不断出现, 网络安全面临严峻挑战, 在此背景下, 以威胁情报驱动的新型网络安全防御机制应运而生。Gartner公司将威胁情报定义为一种基于证据的知识, 为威胁响应提供包括相关场景、威胁指标、含义和可行建议等决策依据[1]。Bianco提出金字塔模型[2], 将威胁情报数据划分为6个层次, 自下而上依次为哈希、IP地址、域名、网络或主机特征、攻击工具、TTPs, 在模型中, 威胁情报收集难度逐层增加, 网络防御能力逐层增强。
威胁情报发展迅速, 但是对威胁情报数据的利用却严重不足。SANS发布的2020年威胁情报调查报告[3]显示, 在对威胁情报的利用中, IOC(Indicators of Compromise)威胁情报底层数据始终占据主导地位, 而对价值更高的TTPs威胁情报信息利用较少。IOC是描述特定攻击活动中主机或网络行为特征的基本指示数据[4], 可用于识别某种攻击, 但是由于缺乏对攻击技术等行为规律的关注, 攻击者很容易通过文件混淆、更换IP地址、域名等简单方式规避检测。TTPs是直接反映APT攻击者行为的高层语义信息, 描述了攻击战术、技术和过程等行为规律本质。防御者可利用TTPs检测和描述APT攻击, 识别攻击者。攻击者对抗检测, 需要开发新技术、新工具、重新部署IP、域名等基础攻击资源, 极大增加了攻击成本和难度。基于人工的TTPs信息分析与利用效率低、难以适应攻击快速发展, 因此急需加强对TTPs威胁情报的自动化分析与利用研究。但是, 当前TTPs主要以自然语言文本形式描述, 在文本的自动化处理分析中存在攻击语义鸿沟问题[5]。
语义规则可以消除上层TTPs和底层数据之间的语义鸿沟, 可用于从审计数据中自动化分析网络威胁。开展基于ATT&CK攻击技术的语义规则提取研究, 可以促进对TTPs威胁情报的自动化利用。本文首先介绍了研究背景, 其次, 构建语义规则模型, 描述攻击行为规律, 最后借鉴自然语言处理领域的知识抽取方法, 将ATT&CK的技术定义文本中的语义知识转化为可用于数据匹配的语义规则。实验证明, 构建的语义规则可从审计数据中检测网络攻击并还原网络环境、攻击目标、攻击过程等攻击上下文信息。
2 研究背景
2.1 威胁情报数据利用
学术界对威胁情报的研究主要关注IOC的提取和利用。文献[6]和文献[7]专注于自动化生成IOC威胁情报, 用于威胁检测分析。但是, 文献[8]和文献[9]研究发现, IOC生命周期较短, 绝大部分的IOC只出现一次, 用IOC检测威胁效率较低。另外, IOC缺乏攻击战术、技术等高层语义信息, 无法分析还原网络攻击上下文信息。文献[10]尝试利用IOC分析开源威胁情报对攻击演变的影响, 但是此分析只能还原出攻击者IP、域名、攻击漏洞的变化, 依旧停留在较低的语义层次, 缺乏对攻击技术和行为规律的分析。文献[11]将IOC威胁情报构建成查询图(Query Graph), 通过消除攻击过程中的签名特征, 刻画特定攻击行为模式来检测攻击, 但是该方法只适用于特定的攻击活动, 未深入攻击技术行为规律本质, 当攻击者改变攻击工具、漏洞就会导致攻击行为和查询图产生较大差异, 由此产生漏报。
TTPs威胁情报中包含详细的攻击上下文信息, 由于TTPs威胁情报一般都是报告形式的自然语言文本, 虽然包含丰富的攻击语义, 但是很难用于自动化威胁分析。要将威胁情报用于自动化威胁分析, 建立威胁情报标准是重要前提[9]。以ATT&CK[12]为代表的攻击战术(Tactics)、技术(Techniques)知识框架, 是对高层攻击语义知识的标准化描述, 为实现自动化威胁分析提供基础。在Mitre公司构建ATT&CK的同时, 也提出了一套规范的威胁分析流程方法[13], 但是主要依靠人工分析。人工分析虽然可以消除TTPs威胁情报和底层数据间的语义鸿沟, 但是分析效率是主要制约因素。除ATT&CK外, 互联网中还广泛存在着其他TTPs威胁情报, 网络中不断发生新的攻击事件也会产生新的TTPs威胁情报, 如果单纯依靠人工分析, 很难及时跟踪掌握最新攻击技术, 导致安全防御严重滞后网络攻击技术演进。因此急需加强TTPs威胁情报自动化利用研究。
将TTPs用于自动化威胁分析已经有若干工作。文献[14]根据ATT&CK技术语义信息, 针对收集恶意代码相关技术在实施过程中的指纹特征(例如特定的系统函数调用), 以此作为语义规则, 可自动化分析恶意代码行为的攻击技术语义; 文献[5]则对同一个攻击阶段下的攻击技术进一步总结归纳, 以函数形式描述IP、文件、进程等在攻击实施中的特征, 以此来构建语义规则, 用来消除底层数据到上层攻击过程之间的语义差异。上述方法都是采用攻击指纹特征来构建特征规则, 未对攻击行为进行建模, 实质上仍然是传统的指纹特征匹配, 缺乏结合上下文信息的高层语义规则提取。从威胁情报的角度, 此类规则将金字塔模型上层TTPs威胁情报映射到了中低层次的威胁情报, 降低了威胁情报的价值。
2.2 ATT&CK框架
ATT&CK是在大量已知APT攻击事件基础上构建出来的, 从战术和技术两个维度对APT攻击进行总结归纳。战术是攻击的目的, 技术是实现战术所采取的具体方法, 在对技术的定义中, 包含了丰富的攻击上下文语义信息。例如, 图1展示了“Exploit Public-Facing Application”技术[15]的部分定义文本, 其中就完整地介绍了该技术的实施过程, 即使用软件、数据或命令, 利用系统或程序的脆弱点, 对目标系统实施攻击, 从而引发一些恶意行为, 随后对其中涉及的漏洞、目标应用服务等又进行了解释说明。由此可见, 技术的定义文本中包含了该技术在实施过程的普遍规律, 既包含抽象的攻击流程, 又包含了实施过程中涉及的网络环境(例如Internet-facing)、关键工具(例如weakness)和目标服务(例如SQL)实例。但是, 此类以自然语言文本描述的语义知识只能通过分析人员学习理解后, 才能以知识经验的形式应用于威胁分析, 效率较低。因此, 需要对技术定义文本中的语义知识的形式化描述, 促进语义知识在威胁分析中的自动化应用。

图1 ATT&CK Exploit Public-Facing Application技术部分定义文本[15] Figure 1 Part definition text of ATT&CK Exploit Public-Facing Application technique[15]
3 语义规则模型
3.1 模型定义
定义1.语义规则模型. 是一张带标签的有向图G=(V, E, L, Λ)。其中V是图中的顶点, 表示攻击过程中的网络实体集合, E是图中边的集合, 描述网络实体之间的关系, L是网络实体数据类型标签集合, Λ是网络实体和标签的映射集合。
定义2.网络实体. 网络中存在的客观事物, 包括概念和对象。概念是对具有相同特点或属性事物的抽象, 用符号Ψ表示, 对象是概念的具体实例, 用符号Θ表示。
定义3.网络实体关系. 表示网络实体之间的相互作用和联系, 用符号R表示。包括操作关系、从属关系、并列关系三种类型。
· 操作关系。表示网络实体对另一个实体的操作行为, 例如software对weakness的execute (take advantage of)关系。操作关系表示攻击过程中的动作, 结合动作主体、客体就可以刻画攻击步骤。
· 从属关系。表示对网络实体划分, 是对实体的进一步具化, 用isa表示。例如bug是weakness的一种具体类别, 可以用isa关系表示, 其中weakness被称为bug的父实体; SQL是database的对象也可以用isa表示, 其中, database是SQL的父实体。
· 并列关系。表示对等的两个网络实体, 例如SMB和SSH的or关系, 并列关系的网络实体具有相同的父实体。并列关系不显性表示, 而是通过同一个父实体的isa关系表示。

表1 语义规则模型关键元素 Table 1 Key elements of semantic rule model
在模型中, 为了清晰地描述网络实体之间的依赖关系, 利用起源图[16-17]的数据表示方法, 对网络实体标签以及操作关系进一步规范, 如表2所示。将网络实体分为进程、文件、套接字三类, 分别对应Process、File、Socket三个标签, 用不同形状表示。在网络和主机中, 进程是关键的行为主体, 网络数据收发、文件读写执行、进程的启动和停止都是由进程发起。本文定义了以进程为主体, 进程、文件、套接字为客体的网络实体操作关系, 操作关系的边用蓝色线条表示, 用黑色边表示网络实体的从属关系。

表2 网络实体标签及其关系[17] Table 2 Network entity labels and relation[17]
语义规则图模型将自然语言描述的技术语义信息表示成有向图, 是对攻击技术的知识化表示。图2是“Exploit Public-Facing Application”技术根据模型生成的语义规则图, 在图中P1→F1→S1→P2→F2描述了技术的实施过程, 网络实体通过操作关系连接起来。在实际远程漏洞利用过程中, 常用的方法是利用漏洞攻击工具, 加载特定漏洞的攻击脚本, 通过网络向目标发送攻击载荷并在目标系统中执行恶意代码。F1→S1边表示漏洞利用程序通过网络向目标发送攻击载荷, 在F1和S1之间隐含了一个进程实体, 由于该进程并不影响整个攻击过程的完整性, 如果增加它反而会提升规则匹配的复杂度, 所以在此将该进程实体省略。当前数据仅限于ATT&CK攻击定义文本, 对抽取的网络实体的子实体无法做到完全列举, 因此, 如果进一步扩充文本数据(例如APT分析报告), 对网络实体的划分会更加具体, 对攻击技术的语义描述更加精确。
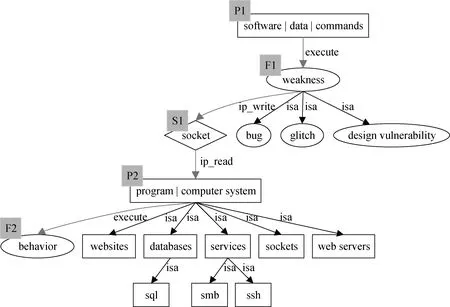
图2 Exploit Public-Facing Application语义规则图 Figure 2 Semantic rule graph of ATT&CK Exploit Public-Facing Application technique
3.2 规则定义
定义4.语义规则. 是描述攻击行为模式规律的法则, 针对网络中可能出现的威胁, 从设备审计日志数据中还原攻击技术语义和上下文信息, 为威胁分析、评估、响应提供支撑。表示为R=H∪Z, 其中H表示实体匹配规则集合, Z表示关系匹配规则集合。
定义5.网络实体属性. 是网络实体用于相互区分的性质、特征、类型, 包括通用属性和特有属性。
语义规则是一个规则集合, 包括实体匹配规则和关系匹配规则两类。两类规则都是对网络实体属性的逻辑运算, 用于对数据中的网络实体及其关系的进行匹配, 还原攻击技术语义。在数据中, 实体之间通过属性进行区分, 通用属性是所有网络实体都具备的属性, 包括label和children。label属性实现了标签和网络实体的映射, 属性值可以继承; children属性是网络实体的子实体的列表, 对象类型网络实体的children属性为空。例如, 图2中网络实体P2的children属性为{[websites, databases, services, sockets, web servers], [sql, smb, ssh]}。进程、文件、套接字三类网络实体都有各自的属性, 如表3所示。

表3 网络实体属性列表 Table 3 Attributes of network entities
属性之间比较运算包括大于(>)、小于(<)、等于(==)、不等(≠)四种, 比较对象可以是两个实体属性, 也可以是单个实体属性和特定数值。例如, 两个进程实体px、py, 通过对两个进程属性进行比较运算, 即px.pid==py.ppid, 可以判断两进程之间是否是父子关系, 通过对单个进程属性和特定数值进行比较运算, 即px.local_addr.port>10000, 可以判断进程是否绑定了非通用端口。属性之间的比较运算关系, 一方面可用于表示关系匹配规则, 另一方面, 可以增强语义规则的扩展性, 便于安全人员根据实际网络环境以及安全经验知识对语义规则进行定制, 使得语义规则更加适用于不同网络环境。
语义规则是面向受害端的, 由于攻击发起端的行为无法通过审计捕获, 所以在将语义规则图转化生成语义规则后, 会再经过人工确认, 将攻击发起端的行为特征转化到防御侧。表4是一个技术语义规则示例, 实体匹配规则是验证单个网络实体属性值是否满足一定规则条件, 关系匹配规则是对主客实体的操作关系进行匹配。如果数据既满足实体匹配规则又满足关系匹配规则, 则匹配成功。通过对数据进行匹配, 语义规则不仅可以自动发现数据中的攻击威胁, 还能还原攻击上下文信息, 辅助分析人员进行威胁分析。
4 语义规则构建
4.1 技术框架
ATT&CK中技术是以文本形式描述的, 因此需要从文本中抽取语义知识, 以此构建语义规则。从文本中抽取语义知识是自然语言处理领域的一项重要内容, 一般采用命名实体识别、关系抽取、属性抽取等方法[18]。由于本文的目的是构建语义规则, 只需描述网络实体属性之间的逻辑运算关系, 而不是描述某一个网络实体的具体特性, 因此在进行知识抽取时, 不涉及属性抽取, 这是和自然语言处理领域的最主要区别。由于本文专注于ATT&CK的攻击技术定义文本, 文本数量较少, 描述比较规范, 再加上网络实体仅限定在进程、文件、套接字三类, 因此采用基于规则的知识抽取方法, 避免基于机器学习的知识抽取方法对构建语料库的要求。
语义规则构建技术框架如图3所示, 框架输入是ATT&CK技术定义中的自然语言文本, 输出是语义规则。在方法上, 主要包括文本数据预处理、知识抽取、语义规则构建三个阶段。预处理阶段是识别文本中的关键词组, 再对文本经过语法解析, 得到标注有词性和语法依赖关系的词汇集合; 知识抽取阶段是从预处理后的词汇集合中, 识别关键网络实体以及关系; 规则构建阶段是对网络实体进行标注, 建立网络实体和标签的映射, 构建语义规则图, 生成语义规则。
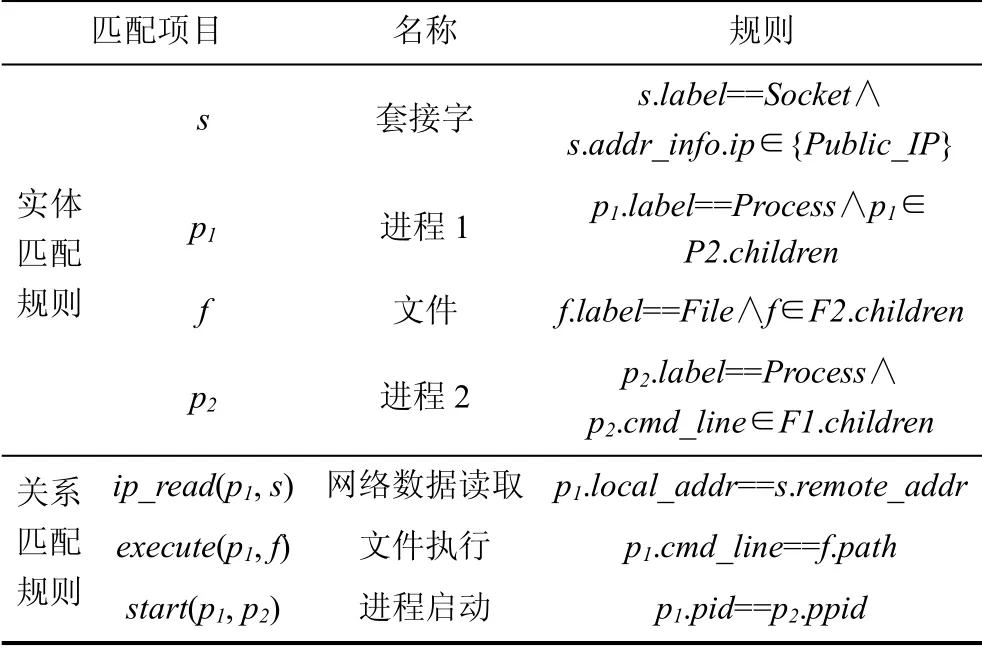
表4 Exploit Public-Facing Application技术语义规则 Table 4 Semantic rule of ATT&CK Exploit Public- Facing Application technique

图3 语义规则构建技术框架 Figure 3 Technology framework of semantic rules construction
4.2 数据预处理
数据预处理包括关键词组识别和语法解析。关键词组识别是根据领域词汇特点, 利用词汇之间的相关性, 识别文本中的词组, 避免分词导致的网络实体识别错误。本文采用逐点互信息(Pointwise Mutual Information, PMI)[19]表示词汇之间的相关性。文本可表示为{w1, w2, …, wi, …, wn}, 其中wi表示文本中的单词, PMI定义如下:

其中, (wi, wi+1)是两个连续单词组成的词组, p(wi, wi+1)是词组出现的概率, p(wi)是单词wi出现的概率。当单词之间的相关性超过一定阈值σ, 则接受该词组。表示为:

筛选出词组后, 对表示操作行为的动词词组进行词典替换, 简化文本的语法结构。例如, 动词词组“take advantage of”, 其语义和单词use相同, 因此, 可以使用use进行替换, 生成新的文本。
语法解析是对文本进行分词, 标注单词词性以及单词之间的依赖关系。本文采用NLTK[20]和spaCy[21]工具进行语法解析, 生成带词性标签和依赖关系的词汇集合。表示为:

其中, tag是单词的词性标签, pos表示单词wx和单词wy之间的语法依赖关系[22]。
4.3 知识抽取
知识抽取包括网络实体识别和关系抽取。通过分析网络实体词汇在文本中的语法特点, 本文构建了一套网络实体词汇语法规则, 用来抽取网络实体, 如表5所示。语法规则是根据英文文本的语法表达规范, 利用词汇词性和语法依赖关系构建的, 输入是预处理阶段生成的带词性标签和依赖关系的词汇集合, 输出是网络实体集合。
在网络实体识别过程中, 为了尽可能多的覆盖文本语义信息, 对文本语法规则定义较为宽泛, 但是这也造成了一定程度上的信息冗余。例如adversary就不属于语义规则模型定义的三类网络实体, 因此仍需对抽取的网络实体进行进一步筛选。筛选过程在规则构建阶段进行。

表5 知识抽取语法规则 Table 5 Grammar rules for knowledge extraction
文本语法规则中也包含了网络实体关系。例如主谓宾句子就表示主语对谓语的动作, 如果主语、宾语都是网络实体, 那么谓语就可以用来表示实体之间的动作关系。类似的也可以从主系表结构、从属关系、并列依赖的句子中抽取实体之间的从属、并列关系。并列关系的网络实体相互继承父实体。因此, 可通过语法规则抽取网络实体关系。
算法1. 基于路径搜索的关系抽取算法.
输入: voc词汇集合, entityList网络实体集合, maxNop最大跳数


由于自然语言语法灵活多样, 语法规则不能保证抽取出文本中所有的网络实体关系。例如图1文本中的“the use of software”介词短语后跟不定式结构, 表示software和weakness之间的use关系, 该结构就不在表5文本语法规则中。为了解决这一问题, 本文利用路径搜索思想, 从某一实体出发, 搜索多次语法依赖关系后可达的网络实体, 实体之间关系用距离实体最近的动词(VERB)或介词(ADP)表示, 具体如算法1所示。设置maxNop=2, 从上述介词短语加不定式的文本结构可以抽取出
4.4 语义规则构建
规则构建包括标签化和规则生成。标签化是根据语义规则定义对网络实体标签及其关系的定义, 对知识抽取的网络实体指定数据类型标签。本文采用基于语义相似度的实体标注方法, 将网络实体通过word2vec[23]转化为向量矩阵, 计算待标注实体和已标注实体的向量cos相似度, 对网络实体进行标注。
语义规则构建就是将标记好的网络实体、关系进行组织, 生成一张语义规则图, 再将规则图转化为语义规则。在构建语义规则时, 首先去除不属于进程、文件、套接字类型的网络实体及其连接关系, 然后将网络实体、关系三元组进行合并, 生成语义规则图。在这个过程中, 用不同形状节点表示不同的实体标签, 蓝色线条表示操作类关系, 黑色线条表示从属、并列类关系。由于语义规则模型描述的是完整的攻击过程, 未区分攻击发起端和受害端, 再加上防御者数据采集方法的限制, 因此需要对自动化生成的语义规则进一步人工确认。人工确认遵循以下原则:
· 最大化保留攻击发起端行为语义信息。攻击发起端的数据虽然无法直接采集, 但是其行为最终会在受害主机中体现, 因此, 最大化的将攻击发起端的行为转化到防御主机侧, 可增强语义规则对攻击行为的还原能力。例如表4.1将漏洞利用代码文件实体转化到受害主机的进程实体中。
· 最大化保证语义规则有效性。语义规则最终是用于对审计日志进行匹配, 从中发现威胁并还原上下文信息, 因此要使得语义规则描述的行为不能超出防御者数据采集能力范围。例如去除代码签名、自定义指控协议、多跳代理等超出审计日志数据范围的语义规则。
5 实验评估
5.1 语义规则匹配算法实现
从255条ATT&CK技术文本中, 构建123个APT攻击语义规则, 涵盖ATT&CK的115项技术和12种战术。表6的每一行列举了每一个战术对应的规则数量、规则所涵盖的技术数量(规则技术)以及战术对应的技术总数, 最后计算了规则涵盖的技术占技术总数的比例。由于ATT&CK战术和技术不是一一对应的, 因此在统计总数时, 对重复项目只统计一次。
从表 6中可以看出, 语义规则并未覆盖ATT&CK的所有技术, 每个战术对应的规则技术占该战术技术总数比例也存在差异。这是由于在语义规则构建过程中, 依据最大化保证语义规则有效性原则, 对超出审计数据采集范围的规则进行人工筛选导致的。因为攻击执行战术中的技术大多在受害主机上实施, 通过审计即可记录攻击过程, 而命令控制战术对应的攻击技术特征一般表现在网络流量中, 通过主机审计已经无法记录。因此, 在规则涵盖的技术占技术总数的比例中, 攻击执行战术比例最高, 而命令控制战术对应的比例最少。
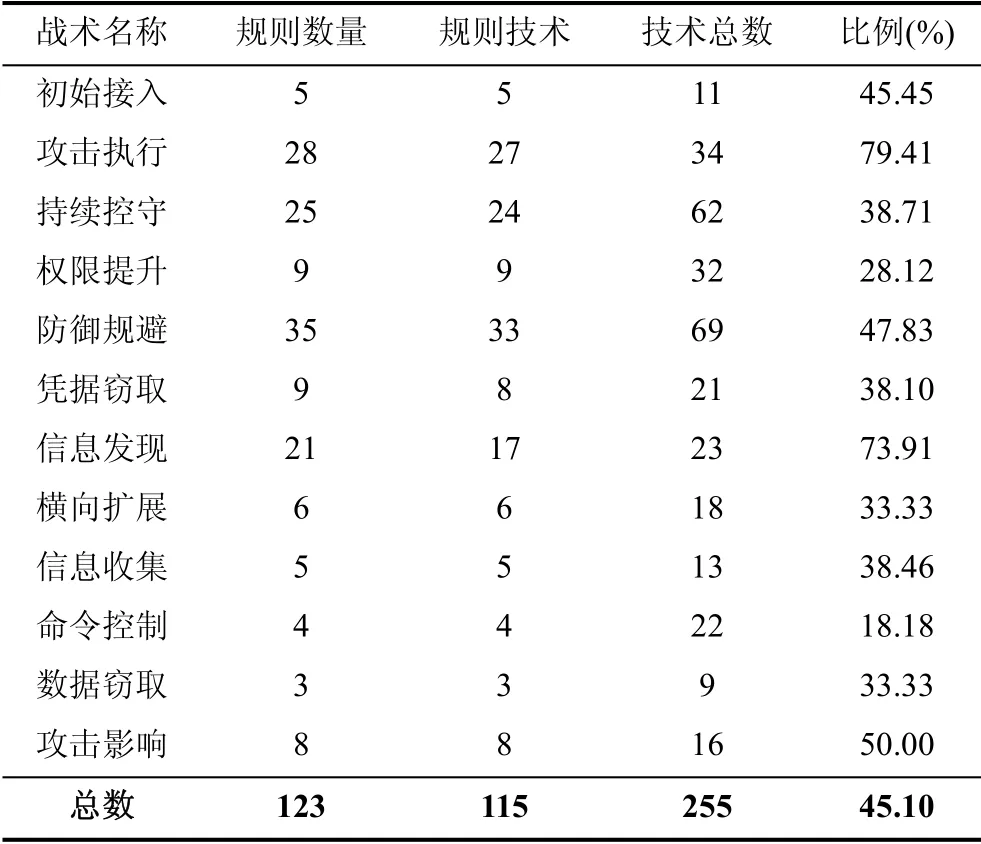
表6 语义规则统计表 Table 6 Statistics of semantic rules
语义规则匹配算法是用语义规则对审计日志进行匹配, 发现威胁并还原上下文信息, 具体如算法2所示。输入为语义规则和日志数据起源图, 通过输入路径最小和最大长度, 控制路径搜索范围, 通过匹配阈值控制和语义规则的匹配程度。语义规则包括实体匹配规则集合H和关系匹配规则集合Z。规则匹配分值是匹配到的关系和规则中关系总数的比值, 用来衡量规则和数据的匹配程度, 计算如下:

其中, matchedRelation是与语义规则成功匹配的关系集合, R.Z是语义规则的关系规则集合, count表示计数运算。算法使用python语言实现。
算法2. 语义规则匹配算法.
输入: R语义规则, GP日志数据起源图, min路径最小长度, max路径最大长度, threshold匹配阈值
输出: result匹配成功的路径


语义规则处理对象是起源图, 而非采集的审计日志数据, 一方面可避免不同日志数据格式对语义规则的影响, 另一方面也提升了语义规则对不同网络场景的适应能力。此外, 研究发现, ATT&CK单个攻击技术实施过程一般只发生在单个受害主机, 很少有跨多主机的操作。因此可以针对网络场景中的不同设备分别构建起源图, 不仅可以缩小起源图中的路径搜索范围, 提升检测效率, 还可以降低网络节点规模的影响。综上可见, 对于语义规则而言, 即使被应用于不同网络环境, 仍然只是对单个主机构建的起源图进行规则匹配, 检测攻击行为并还原攻击技术语义。因此, 在具备一定审计数据采集能力条件下, 只要攻击者技术手法不超出ATT&CK定义的技术范围, 网络环境和攻击技术手法对语义规则检测能力不会产生明显影响。另外, 由于语义规则也具备一定的可扩展性, 通过语义规则属性比较运算, 安全人员可根据实际网络环境和安全经验知识对语义规则进行定制, 进一步提升语义规则对不同网络场景和攻击技术手法的适应能力。
5.2 实验环境和数据
由于语义规则涵盖的攻击技术较多, 难以在现网中收集到所有技术对应的攻击日志数据。本文通过模拟构建实验场景, 依据APT生命周期模型[24]模拟实施攻击过程, 利用Audit[25]审计工具采集场景中的日志数据并作为实验数据。
实验场景由三台VMWare Workstation虚拟机组成: (1)Ubuntu 16.04.6 LTS 64-bit虚拟机作为内网网关, 运行OpenVPN服务, 将内外网隔离; (2)Fedora 29 64-bit虚拟机作为内网主机, 开启SSH服务; (3)Kali Linux 64-bit虚拟机作为攻击机, 从外网对内网发起攻击。场景中的虚拟机器均使用Intel® Core™ i3-7100 CPU @ 3.90GHz × 2 CPU, 4GB内存。
在采集数据时, 利用Audit工具对内网网关和内网主机进行审计, 通过监控系统调用、关键文件、目录的方式, 重点记录进程、文件、套接字三种实体的日志数据。实验共分三个阶段模拟APT攻击过程。在第一阶段, 利用CVE-2014-6271漏洞[26]对内网网关实施攻击, 建立立足点, 搜集主机、服务等信息, 提升权限; 在第二阶段, 通过VPN接入内网, 向内网网关主机植入木马后门, 实现对内网网关的持续控守; 在第三阶段, 以内网网关为跳板, 对内网其他主机进行探测, 通过口令猜解接入内网主机, 实现横向扩展和情报收集, 最终完成攻击任务, 消除攻击痕迹。整个攻击过程共使用了ATT&CK中的29项攻击技术。
利用SPADE[27]工具对实验数据进行预处理, 将审计日志转化为起源图, 图中节点是监控的进程、文件、套接字信息, 边是实体之间的关系。实验数据信息如表7所示。

表7 实验数据信息 Table 7 Experimental data
5.3 语义规则有效性测试
通过对实际数据进行匹配测试, 验证语义规则的有效性。主要依据检出率(Recall)和虚警率(False Alarm)两个指标来衡量。检出率是成功识别攻击技术占数据中真实攻击技术总数的比例, 虚警率是将正常行为判断为攻击行为的数量占算法检测出攻击行为总数的比例。从两个角度衡量语义规则的攻击行为检测能力。
在实验中, 设置匹配算法的路径最小长度为5, 路径最大长度为12, 匹配阈值为0.7。实验结果显示, 算法从29项攻击技术中匹配出27项攻击技术, 在该场景中检出率达93.1%, 具有较强的检测能力, 匹配结果如表8所示。其中, 列举了匹配成功的技术和匹配到的行为数量, 并且每一项匹配成功的技术列举了一个行为示例, 该示例是根据语义规则简化后的行为路径。在检测结果中, T1018技术是攻击者通过脚本连续发送大量的ping数据包, 探测内网存活主机, 因此匹配到的行为数量最多; T1219技术是由于植入的木马在运行时由于绑定端口失败, 从而不断尝试, 因此产生大量的异常行为; T1210技术是在对内网进行扫描时, 产生了大量扫描探测行为。对于漏检的两项技术, T1169由于审计工具没有捕获相应日志数据, 导致规则匹配失败; T1043是由于语义规则和实际数据不一致导致匹配失败。
语义规则虚警率难量化衡量, 这是由于ATT&CK中定义的很多攻击技术都是操作系统提供的正常功能, 之所以将其定义为攻击, 是因为这些功能在一定条件下会被攻击者的滥用, 从而达到攻击目的。例如, 远程服务(T1021)、进程发现(T1057)、文件删除(T1107)等技术, 如果从技术本身来看, 都是正常的用户操作, 但是在APT攻击的上下文语境 中, 这些技术可作为攻击者服务探测、信息收集、痕迹消除的手段。所以要判断检测结果是否属于攻击, 要结合上下文信息进行具体分析。语义规则匹配的目的是自动化从审计数据中发现潜在攻击行为, 并为分析人员提供相关上下文信息, 辅助威胁分析研判。下面通过具体案例, 测试语义规则的上下文语义还原能力。
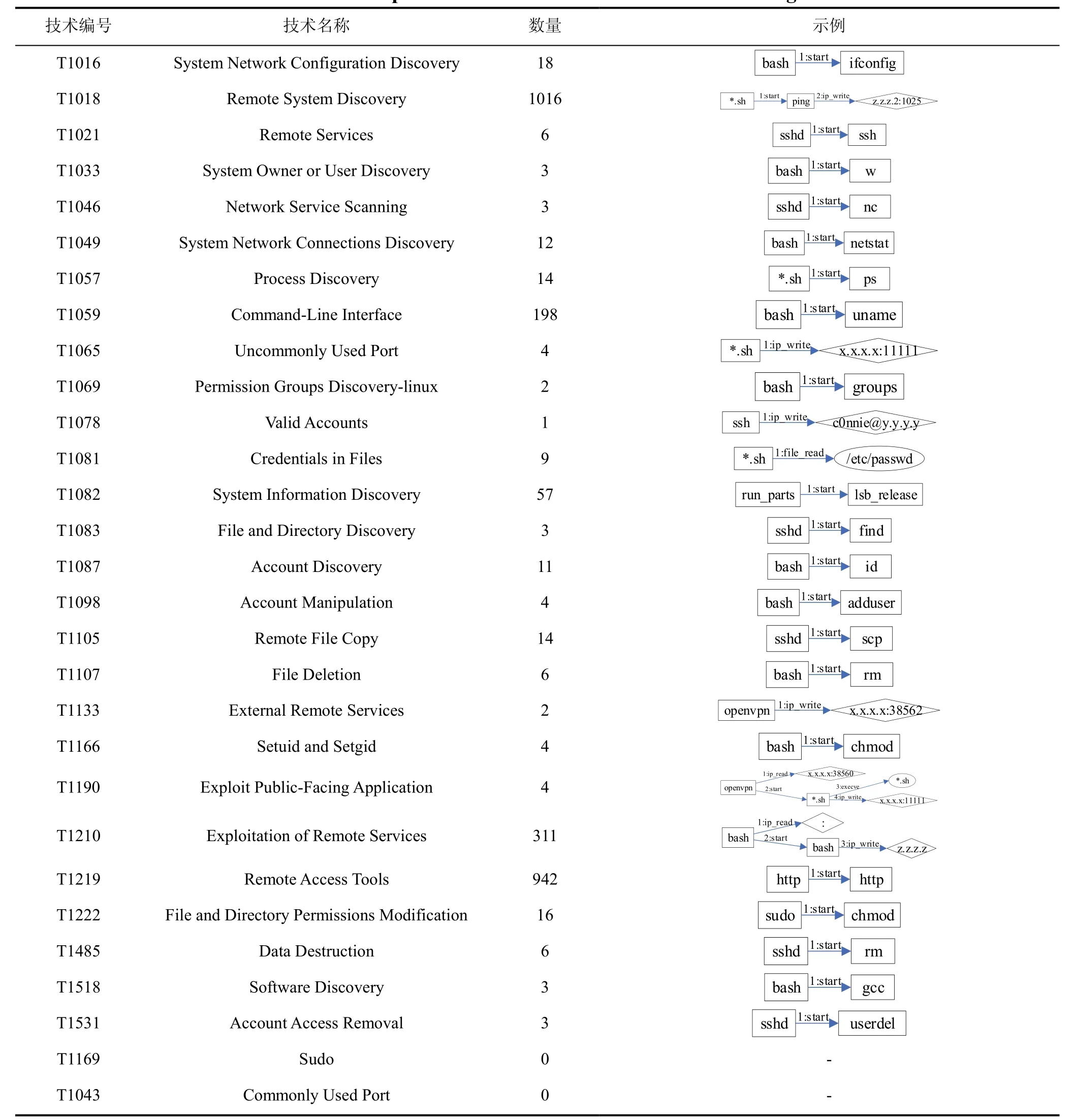
表8 语义规则匹配结果 Table 8 Experimental results of semantic rule matching
案例1: 远程漏洞攻击
语义规则从数据中匹配发现攻击者远程漏洞攻击行为, 并还原其上下文语义信息, 如图4所示, 其中G1是语义规则匹配结果, 即攻击者利用远程漏洞突破内网网关。除此之外, 语义规则还还原了漏洞利用成功后, 攻击者建立立足点、搜集信息、建立帐户实现持续控制等行为, 具体包括获取内网网关远程shell终端, 搜集获取内网网关设备、系统、用户、文件、网络信息, 并添加新用户实现持续化控制等。这些信息比较完整地刻画了攻击者在漏洞利用成功后地后续行为, 可为攻击过程分析、评估提供重要信息支撑。
案例2: 内网扫描攻击
语义规则从数据中发现了两次内网扫描攻击, 都是采用远程系统发现技术, 如图5所示。其中, G2是规则匹配结果, 即脚本通过ping对远程主机进行探测, 如果单纯从匹配结果看, 很难判断该行为是否异常。但是经还原其完整上下文信息, 发现该脚本是对一个网段254个IP地址进行探测, 是个典型的内网扫描行为, 而且扫描脚本是通过远程shell终端启动的, 进一步确定规则匹配结果属于攻击。

图4 远程漏洞利用攻击上下文信息 Figure 4 Context information of remote exploit attack
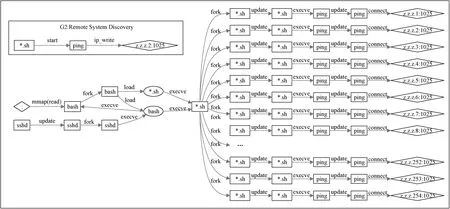
图5 内网扫描攻击上下文信息 Figure 5 Context information of intranet scan
通过以上案例证明, 语义规则可通过上下文信息还原, 有效发现攻击行为, 降低虚警率。语义规则检测对象是日志数据起源图中的路径, 该路径反映了攻击实施过程在受该主机中所表现的行为序列, 不仅包含行为主体、客体, 还包含主客体之间的操作关系。而语义规则就是分别针对此行为主体、客体及其操作关系进行检测, 一旦匹配成功, 可以还原整个行为序列, 即攻击上下文信息。因此, 路径长度可决定行为序列包含信息量的多少, 直接影响语义规则对攻击上下文的还原能力。
5.4 语义规则匹配对比测试
本实验将语义规则和IOC规则进行对比, 通过检出率指标比较两种规则对攻击行为的检测能力。通过IOC Editor[4]工具创建IOC规则, 对实验场景中的审计数据进行匹配, 发现攻击行为。IOC规则关键信息如表9所示。其中, 主要包括攻击者使用的木马、扫描脚本、指控IP地址、URL以及木马和攻击工具文件哈希等。由于IOC规则只能判断主机是否遭受攻击, 无法还原攻击对应的TTPs信息, 因此需通过人工分析, 按照ATT&CK攻击技术分类标准, 将IOC匹配结果和攻击技术进行映射, 从而计算检出率。实验结果表明, IOC规则共检测出13项技术, 检出率为44.8%。具体如表10所示。

表9 IOC检测规则信息 Table 9 Major information of IOC rules
从对比结果可以看出, 对攻击的检测上, 语义规则明显优于IOC规则。IOC规则主要基于攻击指纹特征, 用于直接从数据中识别攻击, 对检测准确性要求较高, 所以检测结果都是包含攻击指纹特征的行为, 但是对攻击者滥用系统正常功能而执行操作无法识别。而语义规则旨在为分析人员提供潜在攻击线索, 只要符合规则描述的行为规律, 都会被成功匹配, 因此匹配结果既包含远程漏洞利用等攻击行为, 又包含攻击者调用系统正常功能而执行的恶意操作, 对攻击行为检测更加全面。
实验中, IOC规则检测攻击并还原语义耗时近1 h, 而语义规则平均耗时约205 s。在效率上, 语义规则也优于IOC规则。IOC规则只能检测攻 击, 却无法自动还原攻击语义, 因此基于IOC的攻击语义还原需要人工参与, 这种半自动化的方式制约了分析效率; 而语义规则可自动化从审计数据中发现攻击并还原语义信息, 避免了工参与, 分析效率更高。

表10 IOC检测规则和语义规则匹配结果对比 Table 10 Comparison of experimental results between IOC rules and semantic rules
5.5 语义规则匹配性能测试
通过测试语义规则匹配效率, 研究影响效率的主要参数。实验在一台工作站上进行, 操作系统为Microsoft Windows 10 64位专业版, CPU为Intel® Core™ i3-7100 CPU @ 3.90GHz, 内存为16GB DDR4。在正常运行时, 设置路径最小长度为4, 路径最大长度为12, 匹配阈值为0.7, 算法10次运行平均时间约为205.05 s, 从54252条路径中匹配到2662个攻击行为, 还原生成27个攻击上下文信息。
本实验采用控制变量法, 分别测试路径最小长度(min)、路径最大长度(max)、匹配阈值(threshold)三个参数对语义规则匹配效率的影响。每个参数都经过10轮测试, 取平均测试结果, 如图6所示。从图中可以看出, 路径最小长度和路径最大长度对算法运行时间效率有明显影响, 匹配阈值对性能影响变化不大。随着路径最小长度的增大, 算法运行时间开始下降, 当路径最小长度大于15时, 运行时间逐渐趋于稳定, 如图6.1所示; 随着路径最大长度的增加, 算法运行时间开始急剧增加, 当路径最大长度大于20时, 运行时间趋于稳定, 如图6.2所示; 当算法匹配阈值不断增加时, 算法运行时间在小范围内略微变化, 但是总体趋于稳定, 如图6.3所示。

图6 性能测试结果 Figure 6 Experimental results of performance test
在测试算法运行时间同时, 对算法从输入数据中搜索的路径总数以及成功匹配到的结果总数进行了统计, 如图6所示(为了更好体现变化, 在图中对匹配结果数量放大了10倍)。在图中可以看出, 路径总数、匹配结果数量都和运行时间成正相关, 并且受到路径最小长度和路径最大长度两个参数影响较大, 受到匹配阈值影响很小。这是由于在给定的输入日志数据不变的情况下, 路径最小长度和路径最大长度两个参数直接控制算法搜索的路径数量, 算法会对每一条路径进行语义规则匹配, 路径越多, 算法匹配耗时越长, 因此路径总数和运行时间呈正相关。但是随着路径长度的变化, 路径总数不是无限增大(或减小)的, 而是逐渐趋于稳定, 这是由输入日志数据起源图本身最大路径长度决定的。在路径最小长度和路径最大长度不变的情况下, 匹配阈值决定算法接受匹配结果的严格程度, 但是路径总数不会变化, 所以算法匹配时间总体不变, 只会影响匹配结果数量, 因此匹配阈值对算法运行效率影响较小。路径长度决定路径中包含的上下文信息量, 在保证一定检出率和语义还原能力的情况下, 选择适当的路径最小长度和路径最大长度, 可以有效优化算法运行效率。
6 结论
自然语言语义鸿沟是制约TTPs威胁情报自动化利用的重要因素, 本文设计并实现了一种基于ATT&CK的APT攻击语义规则, 将攻击技术文本中的语义知识抽取成可用对数据检测的规则, 从而实现底层数据到上层攻击技术语义知识的映射, 以此加强TTPs威胁情报在威胁分析中的自动化应用。实验结果表明, 语义规则检出率达到93.1%, 具备一定的自动化攻击检测和上下文信息还原能力, 能够辅助分析人员较为快速全面地发现数据中的潜在攻击行为, 提升威胁分析效率。语义规则匹配结果是攻击行为以及攻击上下文信息, 只是APT生命周期不同阶段所表现的局部行为, 但是对完整生命周期的还原还需对各阶段行为进行综合关联分析, 因此, 将语义规则用于APT攻击生命周期还原将是下一步的研究重点。
猜你喜欢
红领巾·探索(2020年5期)2020-05-19
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
小学科学(学生版)(2018年9期)2018-09-21
家教世界(2017年11期)2018-01-03
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
