
全链路算法对云数据库中省市政务数据的优化
2021-06-02 23:46邱晓康
通信电源技术 2021年3期
邱晓康
(华信咨询设计研究院有限公司,浙江 杭州 310000)
0 引 言
目前,各地政务数据处理的数学方法较多,但均存在着信息冗余量多,关键信息难以识别的问题,而全链路可视化监控技术法因其路径优化性强和定位准确的优势被广泛应用。有学者认为,政务数据在处理过程中存在着共享性差、传输效率低以及硬件负荷强度弱的问题,造成严重的资源浪费[1]。省政府的云数据中心接收各市政府大量的数据,数据处理强度较大,另外各地区智能设备的应用,视频、图片以及声音等多媒体数据的采集,进一步增加了数据的处理强度。有调查结果显示,政务数据中约40~60%为有价值的行政数据,10~20%的数据为无价值数据[2]。政务数据存在的数据价值量低和数据传输频繁的问题,严重影响了市政工作正常进行。也有学者认为通过阈值和权重等方式,可以提高政务数据的价值判断准确性,减少云中心数据的处理压力[3]。此外,还有部分学者认为全程链路算法可以通过对政务数据的全程跟踪,实现各省市政府系统的综合管理,通过监测数据库、网络以及PC机进行相关的资源调用,以促进数据共享和数据优化,提高数据的传输效率[4]。为此,本文对全链路可视化监控技术法进行研究,通过优化关联规则来降低冗余信息的干扰,提高关键政务数据信息的识别率。同时,优化其关联规则,简化政务数据计算过程,提高政务数据处理的效率。
1 对政务数据进行数学描述
政务数据属于半结构化数据,如何实现对相关数据的综合性分析,提高数据的处理效率,是解决政务数据优化问题的关键。通过数学方法描述,将政务数据变为定性和定量的综合性数据,剔除数据中的相关属性,可以大幅提高数据的处理效率,下面对政务数据量进行数学描述。
1.1 政务数据量识别指标
省政府云数据中心接收或发送政务数据后,各地政府的处理终端会对数据进行识别。依据《2014年中国城市电子政务发展水平调查报告》和《联合国2014年电子政务调查报告》中的要求,将政务数据分为3类属性,即数据的来源、唯一标签属性以及历史日志,其数学内容如下。
假设U代表省政府云数据中心的数据集合,u1代表数据的来源,u2代表标签属性、u3代表历史日志,那么u1i代表各市的数据来源,u2i代表标签的各个属性,u3i代表不同系统的日志。各市与省政府云数据中心之间关系的数学描述为:
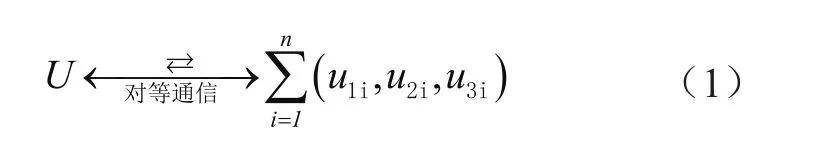
式中,i为自然数。
假设V代表各个市政务系统或数据库集合,vj为每个具体数据库的编号,即V=(v1,v2,…,vj)。其中,j为自然数[5]。
假设P(x, y, z|U, V)为各市政府与省政府之间政务数据处理的结果函数,x代表数据的共享性,y代表硬件的利用率,z为系统的负荷程度,其数学描述为:
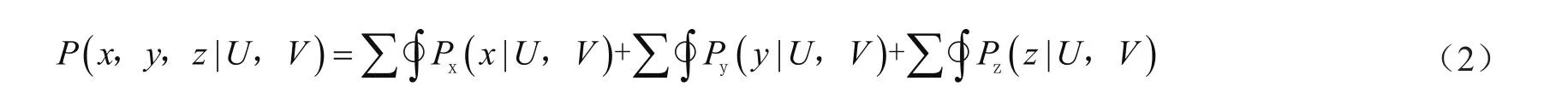
为了进一步提高P(x, y, z|U, V)的准确性,需要对各数据之间增加调节系数,式(2)可以表示为:
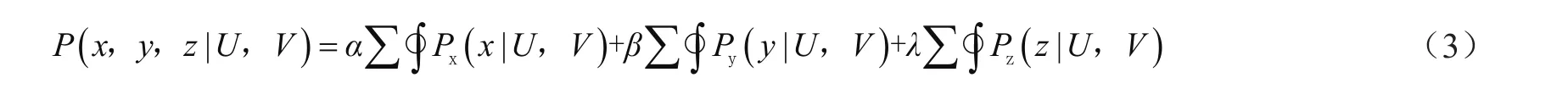
式中,α、β、λ分别代表共享性、利用率以及负荷程度的调节系数。系数的确定由日常工作统计得出,α=0.032,β=0.063,λ=0.017。
假设Q代表政务数据的重要程度,那么对收集到的信息进行剔除,其数学公式描述为:
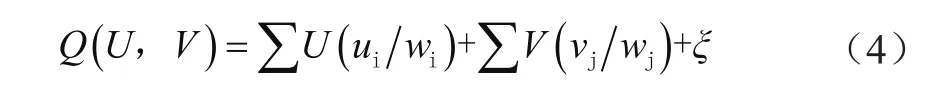
式中,wi是各市政务数据在云中心数据集合中的权重,wj为各市政务数据在市系统中的权重,ξ为各数据重要性的调节系数[7]。
1.2 全链路的处理过程
1.2.1 政务数据的处理
第一步,对各市政务数据进行识别,将其纳入到U中。确定数据中的数据来源u1i,属性u2i,系统的日志u3i,判断数据是否符合政务数据的要求,即数据是否合法[8]。
第二步,依据省政府云中心的数据,对各市数据进行确定,即确定数据库vj编号,并得到相应数据的确认。相关数据库发挥反馈信息以后,省政府云中心接受数据集合U。
第三步,省政府云中心依据数据库编号,对接收的数据和数据集合进行判断,判断相应数据库是否存在负荷程度低、共享性差以及软硬件利用程度不够的问题。如果出现此类问题则增加该数据库信息的调用,减少其他数据库中相同信息的调用,以保证政务数据的共享性与负荷满足要求,避免出现硬件资源浪费[9,10]。
第四步,剔除无关的数据。依据不同数据库和不同市政府数据的权重进行数据判断。如果数据不符合要求,则剔除数据,否则纳入数据。
第五步,用全链路方法对各个市和数据库结点进行遍历。如果数据库节点为最终节点,则终止遍历,否则进行下一个遍历。每遍历一个节点,则重复以上4个步骤。
1.2.2 建立关联规则
在政务数据传输、剔除以及反馈过程中,要遵循以下处理流程。首先要监测各市数据库V中的vj,判断其反馈信息是否符合要求,并监测各个数据库共享下的负荷程度等,同时依据α=0.032,β=0.063,λ=0.017进行相关的调节[11]。其次要对省云中心数据进行监测,判断各个数据u1、u2、u3以及u1i是否合法。最后要对省云中心数据进行冗余判断,剔除不符合要求的数据。
2 全链路算法对云数据库中省市政务数据的优化
2.1 相关数据的初始化
以A省市云计算中心为例,进行政务数据优化分析。A省涵盖5个市,16个数据库。其中包括22条光纤、129个WiFi点、10个ADSL、35个服务器以及168台PC机。网络传输速度平均为2M/s,系统为Windows10,云数据库为Amazon DynamoDB(无服务器数据库),省市访问云数据库的PC机为联想x395型,政府统一采购为i5CPU,内存为12G,硬盘为1T。
2.2 省市政务数据的优化效果
为了验证全链路算法对于省市政务数据的优化效果,从其数据的共享性、硬件的利用率、、数据传输的准确性以及传输时间的角度出发,进行分析和验证。
2.2.1 共享性和硬件利用率比较
共享性、平均负荷以及硬件利用率是政务数据处理中的关键性指标,也是减少云中心数据处理压力的重要内容。通过对各地市政府数据库共享性的分析,调整不同数据库的负荷,提高相关硬件的利用率,可以有效减少云中心政务数据的处理强度。下面对全面的算法进行分析,判断该算法对云数据库中省市政务数据处理的优化,具体结果如图1所示。
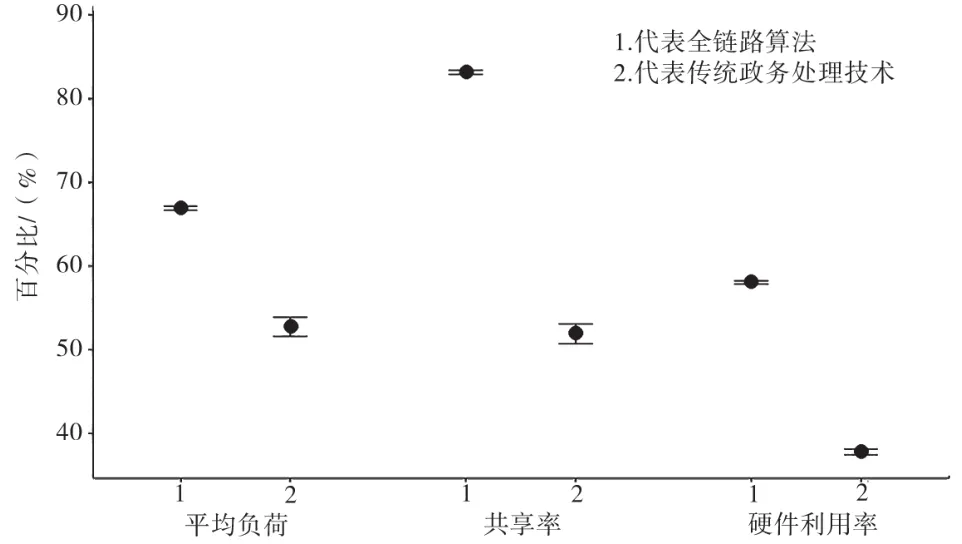
图1 传统算法与全链路算法的平均负荷、共享率、硬件利用率比较
由上图可知,1所代表的全链路算法,其平均负荷率为68.3%,共享率为85.7%,硬件利用率为54.5%。2代表的是多线程政务处理技术,其平均负荷率为56.4%,共享率为52.1%,硬件利用率为40.5%。说明全链路算法的平均负荷、共享率以及硬件利用率均高于多线程政务处理技术。与传统政务数据传输技术比较,发现全链路算法可以将各市服务器的负荷、共享性、硬件利用率提高到65%以上。同时,避免出现相关设备利用率的陡升、陡降现象,各个资源的利用率比较平稳。
2.2.2 算法计算时间
全链路算法的计算时间是其重要的标准,直接关系到云中心省市政务数据的优化效果,通过MATLAB仿真分析,得出结果如图2所示。
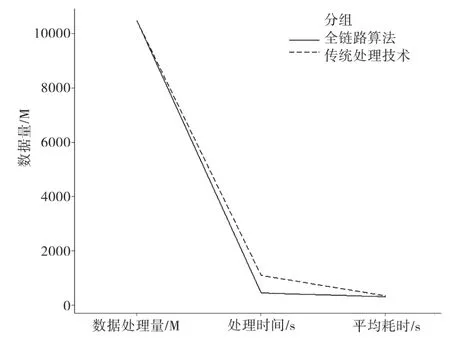
图2 传统算法与全链路算法的计算时间比较
通过上图分析可知,传统算法以前列入算法的数据处理量(注释:M代表兆字节)相同,但全链路算法的处理时间、平均耗时均小于传统算法。
由图2和表1可知,在处理数据总量为1 123 M不变时,全链路算法的计算时间和平均耗时均优于传统算法,说明全链路算法的处理的有效。

表1 传统算法与全链路算法的耗时对比
2.2.3 算法计算准确度
计算准确度是云数据库中省市政务数据处理的重要指标,直接关系到地方与省政府在数据传输时的准确性以及数据的丢失率。
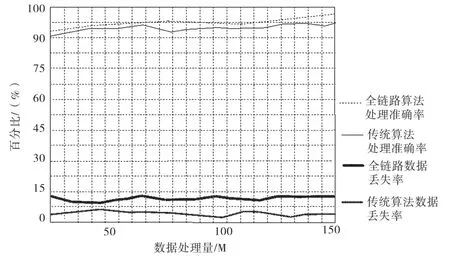
图3 传统算法与全链路算法的处理准确度、数据丢失率比较
由上图可知,全链路算法的平均准确率可以达到95%以上,传统算法处理平均准确率为92%以上。由此说明,全链路算法的准确率相对较高。数据丢失率也是准确率的一个评价指标,代表着省市政务数据传输过程中,数据是否受到干扰,数据是否完整。全链路数据平均丢失率为6%左右,传统算法数据平均丢失率在12%左右。由此可知,全链路数据丢失率相对较低,可能与其剔除无关数据有关。全列入算法中的冗余数据处理,可以减少网络通道的占有率,提高数据传输的准确率,进而减少无关数据的丢失。
3 结 论
政务数据是省市云数据中心处理的主要数据,其具有数据量大和数据价值量高等特点。同时,省政府与各地市政府分别建立了自己的数据库和网络中心,产生大量的政务数据,增加了云数据中心的处理压力。另外,各地数据库和网络中心的纷纷建立,致使数据库和网络的闲置率较高,造成相关资源的浪费。在云数据库处压力加大,各地网络闲置率高的双重背景下,增强数据共享性、降低云中心的负荷压力以及提高省政府云中心与各地市政府质监政务数据传输准确成为目前亟待解决的问题。在此背景下,本文提出一种全链路算法,对云中心数据处理步骤进行简化,剔除各地政府传输的冗余数据信息,提高数据传输的整体准确率,缩短数据传输的时间。以A云数据库中省市政务数据为研究对象,进行全链路算法的仿真分析,结果显示全链路算法的平均负荷率为68.3%,共享率为85.7%,硬件利用率为54.5%。多线程政务处理技术的平均负荷率为56.4%,共享率为52.1%,硬件利用率为40.5%。在处理数据总量为1 123M不变时,全链路算法的计算时间和平均耗时均优于传统算法,说明全链路算法的处理有效。全链路算法的平均准确率可以达到95%以上,平均丢失率为6%左右,传统算法处理平均准确率为92%以上,平均丢失率在12%左右。由此说明,全链路算法的平均负荷、共享率和硬件利用率均高于多线程政务处理技术,准确率和数据丢失率也优于多线程政务处理技术。
猜你喜欢
矿山安全信息(2022年11期)2022-11-26
火力与指挥控制(2022年8期)2022-09-16
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
矿山安全信息(2021年3期)2021-11-30
移动通信(2021年5期)2021-10-25
建材发展导向(2021年12期)2021-07-22
中学生数理化(高中版.高考理化)(2019年6期)2019-06-22
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
