
嵌入知识图谱信息的命名实体识别方法
2021-06-01 08:10阎志刚李成城
内蒙古师范大学学报(自然科学汉文版) 2021年3期
阎志刚, 李成城, 林 民
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
命名实体识别(named entity recognition,NER)是将文本中的命名实体定位并分类为预定义实体类别的过程[1]。近年来,基于深度学习的NER模型成为主导,深度学习是机器学习的一个领域,它由多个处理层组成,可以学习具有多个抽象级别的数据表示[2]。神经网络模型RNN[3](recurrent neural network,RNN)有长期记忆的性能并能解决可变长度输入,在各个领域都表现出良好的性能,但会伴有梯度消失的问题。于是在RNN神经网络模型的基础之上提出了长短时记忆(long-short term memory,LSTM)模型[4]。Gregoric等[5]在同一输入表示中使用了多个独立的双向LSTM单元,该模型通过加入模型间正则化项增强了LSTM单元之间的多样性,并在多个较小的LSTM之间分配计算,很大程度上降低了模型的参数量。Peters等[6]提出了ELMO(embeddings from language models,ELMO)模型,该模型在具有字符卷积的双层双向语言模型上计算,这种新的深度上下文本词项表示能够模拟词项使用的复杂特征(例如语义和语法)和跨语言上下文的用法差异(例如一词多义)。Liu 等[7]提出字符任务感知型神经语言模型,将字符进行向量化表示,可以很好地识别新实体。Radford等[8]提出了GPT(generative pre-trained transformer,GPT)用于自然语言理解任务。Devlin等[9]提出了基于Transformer的BERT模型。该模型采用先预训练,再微调的方法可以捕获到更加丰富的语义信息。Zhang等[10]提出了C-GCN(contextualized graph convolutional Network,C-GCN)模型,通过图卷积运算建模依赖树用于命名实体识别。杨飘等[11]通过嵌入BERT预训练语言模型,构建BERT-BiGRU-CRF模型用于表征语句特征。针对BERT模型参数量大,训练时间长,实际应用场景受限等问题,邓博研等[12]提出了一种基于ALBERT(alite BERT,ALBERT)的中文命名实体识别模型ALBERT-BiLSTM-CRF。在结构上,先通过ALBERT预训练语言模型在大规模文本上训练字符级别的词嵌入,然后将其输入BiLSTM模型以获取更多的字符间依赖,最后通过CRF(conditional random field,CRF)进行解码并提取出相应实体。
鉴于中文命名实体存在结构复杂、形式多样、一词多义等问题,本文提出了一种融合知识图谱的中文命名体识别方法,通过知识图谱中的信息实体增强语言的外部知识表示能力,从而提升中文命名体的识别效果。
1 相关工作
1.1 知识图谱
知识图谱是由图和知识组成[13],将数据结构化并与已有的结构化数据相关联,就构成了知识图谱。2012年谷歌正式提出知识图谱(knowledge graph)的概念,旨在实现更智能的搜索引擎。知识图谱本身是一个网状知识库,由实体通过关系链接而形成。它以结构化的形式描述客观世界中的概念、实体及其之间的关系,将互联网的信息表达成更接近人类认知世界的形式。知识图谱的表示形式为G=(E,R,S),其中E={e1,e2,…,e|E|}表示知识库中的实体集合,R={r1,r2,…,r|E|}表示知识图谱中的关系集合,S⊆E×R×E表示知识图谱中三元组的集合。
1.2 BERT模型
1.2.1 Transformer体系结构 BERT的模型体系结构是基于Vaswani等[14]描述的原始实现,是一个多层的Transformer。具体Transformer模型的编码器共四层: 第一层是多头注意力机制(multi-head attention); 第二层是求和与归一化层,用于解决深度神经网络中的梯度消失问题; 第三层是前馈神经网络层; 第四层也为求和与归一化层,用于生成中间语义编码向量并传送给解码器。
解码器和编码器结构类似,共包含六层。区别在于第一层是带MASK操作的多头注意力机制层,在输出时,当前时刻无法获取未来的信息,因此解码器的输出需要右移,并遮挡后续的词项进行预测。最后解码器再经过一个线性回归和Softmax层输出解码器最终的概率结果。Transformer模型架构如图1所示。

图1 Transformer模型架构Fig.1 Transformer model architecture
1.2.2 BERT模型的输入表示 BERT模型将词向量、句向量和位置向量叠加起来一同作为输入,且在开头和结尾分别加入 [CLS]和[SEP]两个特殊字符,两个句子之间使用 [SEP]进行分割。BERT模型的输入具体包括三个方面。
(1) 使用学习的位置向量,支持的序列长度最多为512个词项。每个序列的第一个词项始终是特殊分类嵌入([CLS]),对应于该词项的最终隐藏状态(即Transformer的输出),常被用作分类任务的聚合序列表示。对于非分类任务,将忽略此向量。
(2) 句子对作为一个序列进行输入,以两种方式区分句子。首先,用特殊标记([SEP])将它们分开。其次,添加一个学到的句子 A嵌入第一个句子的每个词项中,一个句子B嵌入第二个句子的每个词项中。
(3) 对于单个句子输入,只使用句子A嵌入。
2 融合知识图谱信息的命名实体识别方法
传统的BERT可以较好地挖掘出文本数据中的语义信息,但几乎没有考虑结合知识图谱对命名实体进行识别。针对语言理解,知识图谱能够为其提供更丰富的结构化信息。基于传统的BERT模型,该方法加入了知识图谱信息,使词嵌入以及知识嵌入联合嵌入,这样可以更有效的学习到语义知识单元的完整语义表示,提升命名实体识别的性能。
2.1 标记策略
设定词项序列标记设定为{w1,w2,…,wn},其中n是词项序列的长度。同时将与词项序列对齐的实体序列标记设定为{e1,e2,…,em},其中m表示实体序列的长度。此外,将包含所有标记的整个词汇表记为V,包含知识图谱中所有实体的实体序列表的集合记为E。如果一个词项w∈V,并且有与其对齐的实体e∈E,则定义这种对齐方式为f(w)=e。
2.2 模型结构
模型主要包含抽取知识信息与训练语言模型两大步骤。
(1) 对于抽取并编码的知识信息,首先识别文本中的命名实体,然后将识别出的实体与知识图谱中的实体进行匹配。该模型并不直接使用知识图谱中基于图的事实,而是通过知识嵌入算法对图结构进行编码,并将多信息实体嵌入作为相关输入,基于文本和知识图谱的对齐,将知识模块的实体表示整合到语义模块的隐藏层中。
(2) 借鉴BERT模型的思想,该模型采用带Mask的语言模型,同时预测下一句文本作为预训练目标。此外,为了更好地融合文本和知识特征,设计了一种新型的预训练目标,即随机掩盖掉部分对齐输入文本的命名实体,并要求模型从知识图谱中选择合适的实体以完成对齐。本模型要求同时聚合上下文和知识事实的信息,并预测词项和实体,从而构建出一种知识化的语言表示模型。
本模型一方面利用T-Encoder从文本中捕获基本的词法和语法信息; 另一方面利用K-Encoder将知识图谱集成到底层的文本信息中,最终将词汇信息和实体的异构信息表示为统一的特征空间。
在T-Encoder编码器中,首先对词嵌入、句子嵌入及位置嵌入进行合并,作为T-Encoder的输入,如图2的词项输入。而后通过(1)式计算词法和语义特征,即

图2 K-Encoder编码器中的聚合器Fig.2 Aggregators in the K-Encoder
{w1,…,wn}=T-Encoder({w1,…,wn}) 。
(1)
在K-Encoder编码器中,首先抽取文本中对应的实体,通过知识图谱嵌入法将实体转为对应向量表示{e1,…,em},如图2所示。然后将{w1,…,wn}及{e1,…,em}作为K-Encoder的输入,即
(2)

(3)
(4)
聚合器采用信息融合层用于词项和实体序列的融合,并计算每个词项和实体的输出嵌入。对于词项wj及其对齐实体ek=f(wj),信息融合过程为
(5)
其中:hj表示集成词项和实体信息的内部隐藏状态;σ表示GELU激活函数。通过这样的方式,将实体的知识信息融入对文本语义的增强表示中。对于没有相应实体的词项,信息融合层会计算输出嵌入而无需集成,即
(6)
此外,为简单起见,第i层聚合器(Agg)操作由(7)式表示。顶层聚合器计算的词项和实体的输出嵌入将用作K-Encoder的最终输出嵌入。
(7)
2.3 知识增强
为了将知识融入信息性实体的语言表示中,提出了一项新的预训练任务,该任务随机掩盖了一些已经对齐的词项和实体,而后要求系统根据对齐的词项来预测所有相应的实体。给定词项序列{w1,…,wn}和与它对齐的实体序列{e1,…,em},关于词项wi,对齐的实体分布定义如式(8),式中Li表示线性层,该式也将用于计算预训练任务的交叉熵损失函数。
(8)
鉴于词项实体对齐方式存在一些问题,制定以下操作。
(1) 在5%的时间内,对于给定的词项实体对齐方式,将实体替换为另一个随机实体,目的是训练相关的实体模型,解决词项与错误实体对齐的问题;
(2) 在15%的时间内,掩盖掉词项实体对齐方式,目的是训练相关模型,解决实体对齐方式未提取全部现有对齐方式的问题;
(3) 在剩余时间内,保持词项实体对齐不变,使得模型将实体信息集成到词项表中,以更好地理解语言。
与BERT模型相似,该模型还采用掩码语言模型(MLM)以及下一个句子预测作为预训练任务,使模型能够从文本标记中捕获词汇和句法信息。
3 实验设计
3.1 数据集与评价指标
实验数据集采用MSRA以及搜狐新闻网数据集,其中MSRA数据集在16 MB左右,共计50 000余条信息,标注质量较高,是传统NER的首选数据集。搜狐新闻网数据集为手工标注数据集,大小6 MB左右,共计20 000余条信息。实验中将上述数据集随机划分为三部分,即训练集占比70%、验证集占比20%、测试集占比10%。在中文命名体识别研究领域,MSRA以及搜狐新闻网数据集被广泛应用在科学研究中。
基于准确率P、召回率R以及F1值对模型性能进行全面评估,即
(9)
其中:TP表示正确识别出的命名实体数量;FP表示识别错误的命名实体数量;Fn表示未识别出的命名实体数量。
3.2 实验参数设置
相关实验的软硬件环境见表1。

表1 相关实验的软硬件环境Tab.1 Hardware and software environment of relevant experiments
在对模型进行训练时,基于随机梯度法优化模型,通过Dropout层减少过拟合情况的发生。训练迭代次数默认为8 500次,初始学习率为5×10-5,权重惩罚项为权重衰减,预设值为0.05。具体设置见表2。

表2 模型相关参数设置Tab.2 Model parameters setting
3.3 实验结果分析
3.3.1 相关对比模型 为验证提出模型的有效性以及鲁棒性,选取近年来6种较经典的命名体识别模型,包含HMM、BiLSTM-CRF、BERT、OpenAI GPT、ALBERT-BiLSTM-CRF以及C-GCN。通过对比相关模型的准确率、召回率以及F1值评价改进模型的性能。
(1) HMM: 隐马尔可夫模型是关于时序的概率模型,随机生成状态序列,每个状态生成一个观测,由此产生的随机序列称为观测序列。
(2) BiLSTM-CRF: 该模型是序列标注任务中的经典神经网络模型,采用预训练好 Word2Vec 向量作为 BiLSTM 网络的输入进行特征提取,然后将其特征矩阵输入CRF中完成序列标注。
(3) BERT: 该模型将文本中的每个字转换为一维向量,作为模型输入; 模型输出则是融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分。文本向量: 该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合。位置向量: 由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分。最后,BERT模型将字向量、文本向量和位置向量的加和作为模型输入。
(4) OpenAI GPT: 基于transformer,该模型共包含两阶段的训练任务。首先使用语言建模目标,在未标记的数据上使用transformer来学习初始参数,然后运用监督目标使相关参数适应目标任务,从而使预先训练的模型发生较小变化。
(5) ALBERT-BiLSTM-CRF: 该模型先通过ALBERT预训练语言模型在大规模文本上训练字符级别的词嵌入,然后将其输入BiLSTM模型以获取更多的字符间依赖,最后通过CRF进行解码并提取出相应实体。
(6) C-GCN: 该模型采用图卷积运算对依赖树建模,进行关系分类。此外,为了对单词顺序进行编码,并减少依赖解析中的错误副作用,使用BiLSTM模型生成语文字化表示作为GCN模型的输入。
3.3.2 改进方法的单一性能评估 为验证本文方法对特定种类实体的识别效果,基于手工标注的搜狐新闻数据集,实验选取了人名、地名、组织名三类特定实体,与现有方法进行对比,实验结果见表3。由表3可知,与现有的模型相比,改进方法的准确率、召回率以及F1值均有一定程度的提升,说明融合知识图谱信息对中文命名实体检测的方法是有效的。此外,由于组织类实体容易出现地名以及人名的嵌套,对其识别造成了一定干扰,识别难度与地名、组织名相比有所提升。观察实验结果可知,组织名的识别效果相较于地名、人名有所下降,符合实验预期结论。
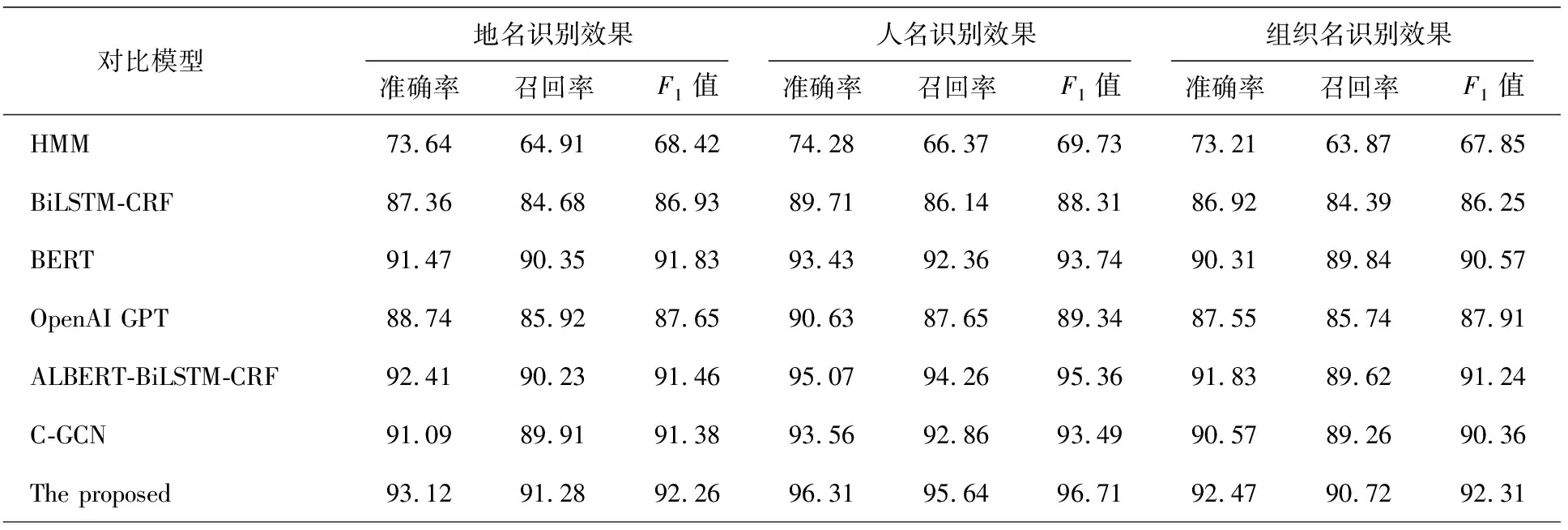
表3 地名、人名和组织名识别效果对比Tab.3 Comparison of place name, name and organizational name recognition effect %
3.3.3 改进方法的综合性能评估 借助混淆矩阵,在两个数据集上分别进行训练,对模型的综合性能进行评估,相关结果见表4。

表4 实验结果对比Tab.4 Comparison of experimental results %
由表4可知,本文提出的模型更具有竞争力,明显优于其它方法。在MSRA与搜狐新闻网标注数据集的实验对比中取得了最佳结果,F1值分别达到了95.4%与93.4%,验证了该模型在中文命名实体识别中的有效性。
3.4 消融实验
在3.3节中,通过一系列的对比实验探究了本文所提方法的有效性。本节重点探究模型编码器以及知识增强机制对识别准确度的影响。主要包含以下探究。
(1) 实验首先探究了模型编码器对识别准确度的影响,模型丢弃了知识增强机制,分别探究了T-Encoder 和K-Encoder对分类识别准确度的影响。针对T-Encoder编码器,模型将词嵌入、句子嵌入、位置嵌入进行合并,通过前馈网络输出相关词项和实体。
(2) 基于(1)中的实验结果,对K-Encoder中的知识图谱嵌入机制展开探究。利用K-Encoder编码器抽取文本中对应的实体,通过知识图谱嵌入法将实体转为相应的向量,由一系列堆叠的聚合器对词项和实体编码,采用信息融合层将实体的知识信息融入对文本语义的增强中。
(3) 基于(1)、(2)的实验探究结果,重点探究知识增强机制对于命名实体识别精度的影响。
表5记录了上述三种探究方案的消融研究结果,发现相关方案的性能均比本文提出的方法差。在命名实体的识别任务中,依赖于句子的语义信息,通过嵌入知识图谱信息以及知识增强机制有助于提高准确性。

表5 消融实验结果对比Tab.5 Comparison of ablation experimental results %
4 结语
本文将知识图谱信息融入命名体识别模型中,为更好地融合文本和知识图谱中的异构信息,使用K-Encoder 知识聚合器和知识增强策略。实验结果表明,与传统命名体识别模型相比,如BERT、OpenAI GPT、ALBERT-BiLSTM-CRF等方法,融合知识图谱信息的命名实体识别方法具有更好的识别效果。未来的研究主要从两方面进行,一方面,将多种结构的知识引入命名体识别模型,从而增强模型的鲁棒性。另一方面,启发式地标注更多真实语料库,以进行更大规模的预训练。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
少先队活动(2020年12期)2021-01-14
新城乡(2018年6期)2018-07-09
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
领导科学论坛(2016年9期)2016-06-05
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
