
基于机器学习的“携号转网”微博评论情感分析
2021-06-01 09:47
中国科技纵横 2021年3期
(中国电信北京分公司,北京 100010)
0.引言
本文基于机器学习的方法,围绕“携号转网”话题的微博评论进行情感分析,考虑到各类媒体围绕“携号转网”主题发布的微博文字稿件会影响到情感分析结果,并且媒体账号数量很多,不易全部剔除,故仅选取微博评论作为分析文本,不包括微博原文。
1.研究概述
1.1 研究思路
本文分为两个实验步骤,第一部分是寻找可靠的开源语料库,将带有情感标注的语料库按照7:3的比例分成训练集和测试集,经分词、去停词处理并转化为词向量后,使用训练集构建情感分类模型,使用测试集对模型进行情感分析测试。本文选用github上公开发布的开源语料库对情感分类的模型进行训练[1],该语料库是对一定数量的微博评论文本进行正负面情感分类的数据集,经过人工核验,过滤掉了广告、过短或过长、表意不明等语料,可靠性较强,语料库内容如表1所示,其中0为负面情绪,1为正面情绪。

表1 开源语料库节选
第二部分首先要爬取微博评论数据,将2019年11月至2021年3月19日(剔除3月21日“大量肖战粉丝携号转网事件”对实验结果的影响)期间微博平台关于“携号转网”相关评论进行爬取,对获取到的数据进行筛选,去除运营商客服标准化回复以及类似的无效评论,利用筛选后的文本数据,进行文本处理、词语向量化,然后运用第一步得到的分类模型进行情感分析。
1.2 理论概述
1.2.1 词语向量化
本文使用的Word2vec是一种无监督式方式学习语义知识的方法,通过将文本转换为词向量的方式来表示词语信息,即将词语嵌入数据空间,使得语义上相似的单词在该空间内距离很近。Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从原理上说,Skip-Gram是给定输入词语来预测上下文。而CBOW是通过上下文,反过来推测要输入的词语,在本文中是使用CBOW方法来生成词向量的[2]。
1.2.2 情感分析理论
当前机器学习的主流算法有支持向量机算法、随机森林算法、K近临算法、朴素贝叶斯等,本文使用支持向量机(SVM)以及随机森林(RF)算法开展对比实验[3]。
(1)支持向量机算法。支持向量机是一种基于统计学习理论的机器学习方法,其最大的特点就是可以在不同类别的样本点之中找到最优的分界线或者分界面。在二维空间中,两种类型的数据点分别位于决策分界线的两侧,该分界线使两类数据之间的分类间隔最大。在现实情况中,数据往往是非线性的,实践中可将二维数据空间拓展至多维,进而找到一个最优决策面,将不同类型的数据点进行分割。
(2) 随机森林算法。随机森林算法是通过组合多个弱分类器进行投票或求均值的方法,来提高最终结果的准确性。该方法首先在该数据集上随机有放回地抽样重新选出K个新数据集来训练分类器。它将使用训练出来的分类器对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别定位最终类别[4]。
2.用户评论情感分析
2.1 文本数据预处理
本文采用python进行微博评论数据爬取,观察收集到的数据,可以看出数据中存在较大数量的运营商客服回复,比如“您好,您反映的问题我们已经详细记录并反馈至相关部门……”,对情感分析的结果产生干扰,故予以剔除,最终得出了本次的实验数据集。
2.2 模型的建立与测试
对于用来训练模型的开源数据集,共有10000余条微博评论文本,开源作者已为所有文本逐条标记了情感倾向,0为负面情感,1为正面情感。取其中7000个作为训练集,3000个作为测试集。
2.3 对采集到的文本数据进行分词以及停用词处理
本文利用jieba词库进行分词,将句子拆解成词语,并把获得的词语数据集与哈工大停用词表进行比对,剔除掉重复的词语,从而达到去除停用词的目的。
2.4 利用Word2vec生成词向量
本文使用Word2vec模型生成词向量时,采用了gensim包中的CBOW算法。为保证词向量的准确度,在生成过程中选择了窗口值为5,并将词向量维度调整为300,如表2所示。
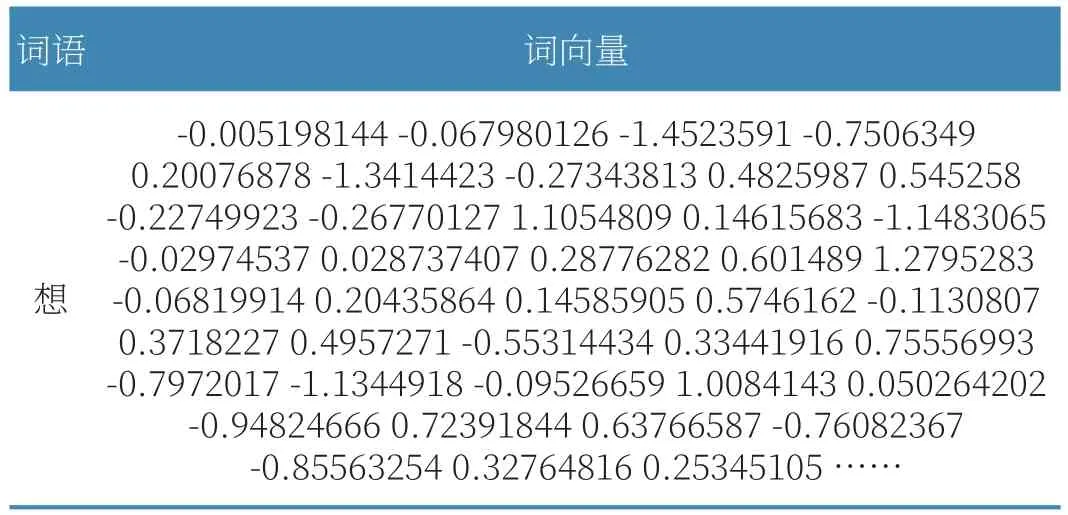
表2 “想“词向量节选
2.5 情感分析的各项指标
(1)混淆矩阵(Confusion Matrix),也称误差矩阵。以二分类模型为例,最终需要判断样本的结果是0还是1,或者说是正向还是负向。
通过样本的采集,在真实结果已知的前提下,通过比对真实结果和分类模型的结果,可以一定程度上判断模型的可靠性,如表3所示。
表3 混淆矩阵(0代表负向,1代表正向)
真实值为正向,模型输出的预测结果是正向的数量(True Positive=TP)。
真实值为正向,模型输出的预测结果为负向的数量(False Negative=FN)。
真实值为负向,模型输出的预测结果为正向的数量(False Positive=FP)。
真实值为负向,模型输出的预测结果为负向的数量(True Negative=TN)。
(2)准确率(Accuracy),代表分类模型中所有判断正确的结果占总观测值的比重,是对于整个模型的评估项[5]。
Accuracy= (TP+TN)/(TP+TN+FP+FN)
(3)精确率(Precision),代表分类模型预测结果为正向的所有结果中,预测正确的数量。
Precision= TP/(TP+FP)
(4)灵敏度(Sensitivity),又称召回率(Recall),代表在真实值为正向的所有结果中,模型预测结果正确的数量。
Sensitivity=Recall= TP/(TP+FN)
(5)F1-Score,F1-Score指标是对分类模型的整体精度进行衡量的评价指标,该指标综合了Precision与Recall的产出的结果,取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
F1 Score= 2PR/(P+R)
2.6 模型测试
实验中对于测试集的测试结果下:
(1)支持向量机方法下,真实为1预测为1的是729个,真实为0预测为1的是673个,真实为1预测为0的是320个,真实为0预测为0的是1276个,如表4、表5所示。
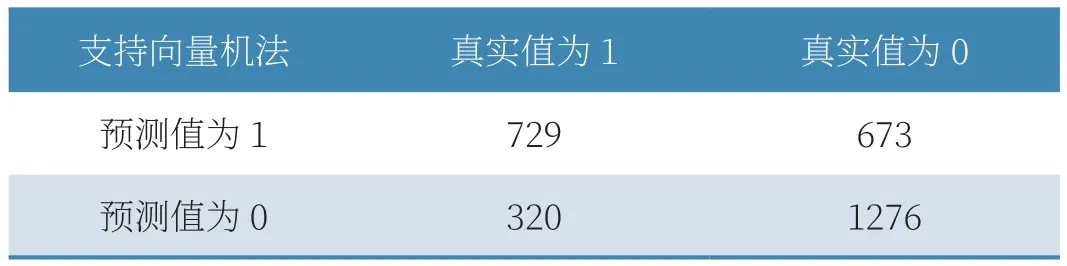
表4 支持向量机混淆矩阵

表5 支持向量机指标
(2)随机森林方法下,真实为1预测为1的是898个,真实为0预测为1的是504个,真实为1预测为0的是426个,真实为0预测为0的是1170个,如表6、表7所示。
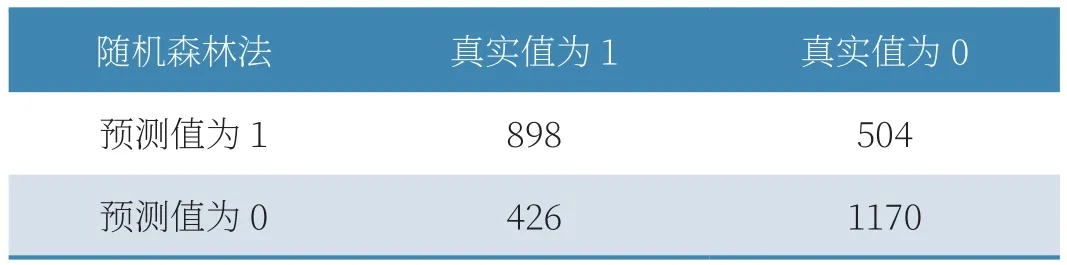
表6 随机森林法混淆矩阵

表7 随机森林法指标
从数值上看,综合各项指标,随机森林方法进行测试的结果更贴近真实值,故使用随机森林方法对“携号转网”相关微博评论文本进行情感分析。
2.7 模型应用
实验中,共爬取到30184条与“携号转网”关键词相关的微博评论,经筛选客服留言、去重后,共15273条有效样本数据,表8所示。

表8 有效数据情感分析列表节选
3.结语
使用训练好的随机森林模型来对该数据集进行情感分析,得到以下结果:
正面情感6461条,占比42.31%;
负面情感8812条,占比57.69%。
从实验结果上看,微博用户对于携号转网的正负面情感认知较为均衡,约42.31%的微博评论对于“携号转网”话题持正面情绪,57.69%持有负面情绪。
负面情绪的原因主体可以归结如下三方面:
第一,部分微博网友并非对于携号转网业务本身带有负面情绪,而是觉得某个运营商的服务欠佳,在微博中抱怨遇到了不开心的事情,想要去转到其他运营商,本次实验的学习模型无法对此类微博评论进行剔除,故而这一类的评论会被判断带有负面情感。经后续人工核查,此类微博评论以及其他无效负面情感评论占所有负面情感评论的21.4%。
第二,部分微博网友反映,办理携号转网业务后,会出现无法收到第三方App的验证码等问题,这也使得想要携转的用户们望而却步。虽然目前相关技术已经成熟,但是面对成千上万的第三方App,携转的衔接完善过程极为繁重,并非短时间内可以完成[6]。
第三,携号转网的过程较为复杂,需要携入携出两家运营商合作完成,在任何步骤中遇到问题都可能导致转网困难。建议运营商间积极协调配合,不断优化携号转网业务流程,保证用户携号转网顺利、畅通。
猜你喜欢
电脑报(2020年49期)2020-12-31
通信产业报(2020年24期)2020-07-31
计算机与网络(2020年24期)2020-04-01
天津外国语大学学报(2020年1期)2020-03-25
知识经济·中国直销(2018年6期)2018-06-29
知识窗(2017年12期)2018-01-02
语言与翻译(2015年4期)2015-07-18
基础教育(2014年3期)2014-04-16
当代外语研究(2010年3期)2010-03-20
