
改进K-means聚类算法对学生成绩的分析与评价
2021-05-28 20:11王锦严德菊
牡丹江师范学院学报(自然科学版) 2021年2期
王锦 严德菊

摘 要:提出一种改进K-means聚类算法——cnnK-means算法,优化学生成绩分析.分析结果表明,语文和数学成绩联系最大,数学和英语成绩联系最小,英语成绩对学生成绩的分类影响最直接和也最明显.如果想要提高学生的整体成绩,教育者需要在英语方面做出更大的努力.
关键词:自动编码器 ; K-means聚类算法; 学生成绩分析
[中图分类号]TP391 [文献标志码]A
Student Achievement Evaluation Based on K-meansClustering Algorithm
WANG Jin,YAN DeJu
(China West Normal University,Computer Science,Nanchong 637000,China)
Abstract:An improved K-means clustering algorithm is proposed for better performance analysis.The results show that the relationship between Chinese and mathematics is the largest,the relationship between mathematics and English is the smallest,and the classification effect of English is the most direct and obvious.If you want to improve the overall performance of students,educators need to make greater efforts in English.
Key words:automatic encoder;K-means clustering algorithm;student performance analysis
自動编码器[1]是神经网络[2]的一种,是一种常用于机器学习的具有自学习功能的一个训练模型.K-means算法可以对成绩数据进行聚类分析.[3]笔者用改进后的自编码器K-means算法分析学生的成绩,明确学科之间的关系,并根据不同的分类情况采取个性化的教学方法,达到提高学生整体素质的目的,为教育者的教学提供教学改革指导.
1 改进的K-means算法——cnnK-means算法
笔者提出一种与卷积神经网络[4]相结合的K-means算法[5]——cnnK-means算法.该算法能克服人的主观偏向,从科目数据本身出发,探寻数据的隐藏规律,以此分类.这种算法能更公正地判断学生的考试结果,并直观地展示出各科成绩及对分类的影响.研究将卷积神经网络(cnn)加入到自编码器中去,将自编码器中的encoder部分换成cnn,对输入数据进行升维以获取更多的信息,然后再用decoder还原信息.
cnnK-means算法流程如下:
输入:数据集合,k的值.
输出:k个簇.
步骤:(1)设置k的值;
(2)计算距离,并按最近原则把其他所有数据对象分到各个簇;
(3)计算簇内所有数据对象的平均值,把数据点放到最近的类里;
(4)重复2,3,步,当簇心固定不变时,算法结束,将聚类的结果输出.
2 实验结果与分析
本文选择南充市某小学学生期末成绩数据作为分析对象,选取学生的语文、数学、英语成绩作为实验数据,通过实验结果对比来验证cnnK-means的有效性.
实验包含两个部分:利用原始的自编码器处理学生成绩,用K-means算法进行聚类;利用改进后的自编码器对学生成绩进行处理,使用K-means算法聚类.
cnnK-means算法的参数设置:
·n_hidden_1设置为3,n_hidden_2为512,n_hidden_3为1024,n_hidden_4为512,out_put_dim为200;
·聚类数num_of_clusters设置为2;
·卷积层为6,卷积核大小是2,卷积核数量为64;
·激活函数选择“relu”函数,strides为1,pooling为2,池化步数ps为2.
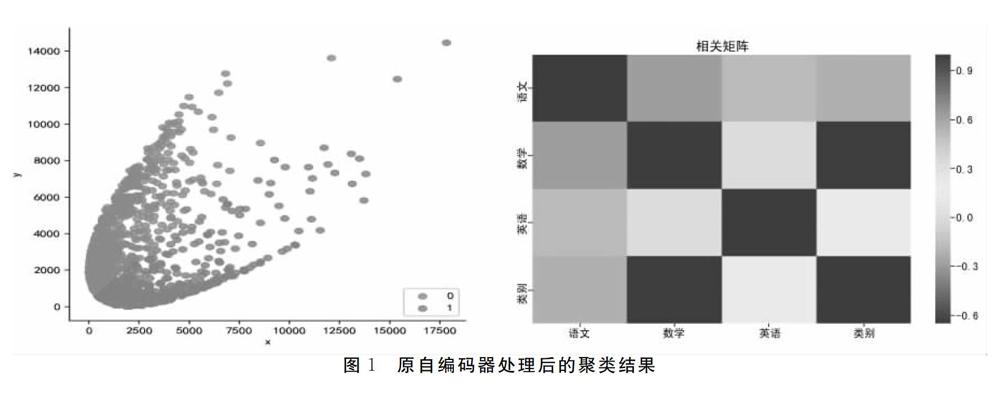
成绩数据包含语文、数学、英语3科,所以将n_hidden_1设置为3,out_put_dim为200.也就是将三门成绩升维为200维,聚类数num_of_clusters设置为2.聚类结果见图2.将图2与原自编码器处理后的聚类结果图1对比.可以看出,加入CNN改进后的自编码器聚类效果更好,特别是对于0类学生成绩,聚类结果的分布相当靠拢.虽然1类学生成绩数据相对来说聚类效果对比不是特别明显,但是总的效果还是要好一些.
图2与图1的矩阵图对比表明,改进前后的矩阵图总体上相差不大,说明语文和数学成绩联系最大,数学和英语成绩联系最小,可能是由于学生理解能力对语文的影响.理解能力是学习的基础,对问题解决的前提是要理解问题,然后才能分析解决问题.因此,教育者不要单纯为了提高学生的成绩而仅依靠增加练习来完成,要注意多科之间的关系;不要单纯地只提高学生的分数,要注意学生能力的提高,比如理解力、记忆力、表达力等,当学生的各方面的能力提高了,各学科成绩自然会提高.
语文、数学、英语3科考试成绩[6]分析表明,英语成绩对学生成绩的分类影响最直接,也最明显.除了英语之外,明显影响学生成绩的是语文,最不明显的是数学成绩.卷积神经网络做的相关矩阵图说明,除去英语,数学对学生成绩分类影响要大于语文,但是相差不是特别大.由于英语成绩几乎在很大程度上决定了学生成绩的分类,根据木桶效应,如果想要提高学生的整体成绩,教育者需要在英语方面做出更大的努力.
3 结语
本文提出cnnK-means算法,对研究对象的期末成绩做了分析.研究结果表明,影响学生成绩的因素主要有学校、家庭和学生自己三方面.教育者可根据不同的分类情况,采取个性化的教学方法教学.建议学校方面要把培养学生的能力放在首位,学生家长要关注孩子记忆力、表达力、理解力和观察力的提高.
参考文献
[1]张常华,周雄图,张永爱,等.深度自编码器在数据异常检测中的应用研究[J].计算机工程与应用,2019(2):12-16.
[2]肖思宇,吴丁娟.基于神经网络与模糊理论的模糊自编码器[J].信息技术,2020(4):5.
[3]田宏,于晓秋.因子分析与聚类分析在学生成绩综合评价中的应用[J].牡丹江师范学院学报:自然科学版,2009(3):09.
[4]孙昭颖.基于卷积神经网络的文本聚类算法优化研究[D].上海:上海交通大学,2018.
[5]Xindong Wu,Vipin Kumar,J.Ross Quinlan,Joydeep Ghosh,Qiang Yang,HiroshiMotoda,Geoffrey J.McLachlan,Angus Ng,Bing Liu,Philip S.Yu,Zhi-Hua Zhou,Michael Steinbach,David J.Hand,Dan Steinberg.Top 10 algorithms in data mining[J].Knowl Info Syst,2008,14:1-37.
[6]殷倩,柳雪雪.基于因子分析和聚类分析的学生成绩评价模型[J].牡丹江师范学院学报:自然科学版,2015(3):68.
[7]FLETCHER S.POTTS J.BALLINGER R.The pedagogy of integrated coastal management[J].The geographical journal,2008,174(4):374-386.
[8]陈庄,罗告成.一种改进的 K-means 算法在异常检测中的应用[J].重庆理工大学学报,2015,29(5):66-70.
[9]马永梅,龙兵,胡传双.基于灰色聚类的大学生课程学习效果评价模型[J].牡丹江师范学院学报:自然科学版,2020(3):62-66.
[10]Tatjana Vasileva-Stojanovska.Impact of satisfaction,personality and learning style on educational outcomes in a blended learning environment[J].Learning and Individual Differences,2015,38:127-135.
[11]李芳芝,慕丽蓉.高校线上教学评价指标体系建构[J].牡丹江师范学院学报:自然科学版)2020(4):19-22.
编辑:吴楠
收稿日期:2020-12-09
基金项目:四川省教育厅重点项目 (13ZA0015)
作者簡介:王锦 (1963-),男,四川成都人.教授,硕士生导师,主要从事数据库技术研究;严德菊(1988-)女,重庆开县人.研究生在读,主要从事数据库技术研究.
