
如何避免“失街亭”:论公共管理中的信任建立机制
2021-05-27 05:37:46文建东
四川大学学报(哲学社会科学版) 2021年3期
文建东
一、公共管理博弈中的一般性信任与合作问题
(一)问题的提起:为何失街亭和如何不失街亭
组织与社会的良好运行,都依赖于公共机构和公众之间是否存在信任和基于信任的合作。企业有着严格单一的组织架构和章程,管理层与员工之间不存在信任问题。但是与企业管理不同,公共管理中信任却总是存在问题,合作也就无法实现。在公共管理中,管理机构和服务对象是通过各种政策进行互动的,前者主要通过发布各种政策进行社会和公共管理。政策是否有连续性,是否可以预测,以及是否遵守以前的承诺,这些影响着服务对象是否信任从而是否愿意配合,进而也影响着公共管理效率。
以法规执行为例,有不少涉及轻微刑事的法规,例如医闹、械斗、老人或残疾人碰瓷、网络上诬陷他人、侵犯他人隐私等各种寻衅滋事,依法是应该治罪的。但是法规不彰,违法了而被和稀泥了事。随后人们会无视法规,继续违法,而此时如果要重新维持法规严肃性,就不得不付出更大的代价,比如需要动用更多的警力才能将嫌疑人约束住。
再以城市的经济发展规划为例,有些地方的党政主官更倾向于开启一个新的发展计划,而不愿意完成上一任开启的计划。更严重的是部分地区招商时言之凿凿、信誓旦旦,而一旦成功引入资本,就轻忽怠慢。这对招商而言就带来巨大不确定性,无论地方上如何宣传鼓动,投资者都只会将信将疑。结果地方上和投资方都只考虑短期行为,经济发展被大大耽误。
不过现实中也有与以上情形相反的事例。比如在东部沿海地区,相对而言注重规则,注重保持政策的连续性,注重增强未来的可预期性,从而更能吸引资本。
这一类问题在公共管理中非常常见,而且以各种表现形式层出不穷。形象一点,可以用失街亭时诸葛亮挥泪斩马谡为例来描述:在驻守街亭之前,诸葛亮让马谡立下军令状,失之当斩。而当失街亭成既成事实后,斩杀马谡已经于事无补,但是保证了今后的军纪严明,无人抗令也就无需斩杀了。这个例子中,诸葛亮选择了诛马谡。而在其他同样的例子中,有人选择了让“马谡”将功补过。不同的做法,带来的结果是不一样的。
失街亭的故事包含了公共管理中的两个关联机制:奖励是否可信,惩罚是否严明。两者都是指事先宣布的政策能否得到执行,从而信任(和基于信任的合作)是否建立的问题。这类问题太普遍,有很多讨论,但是也正因为太常见,反而在讨论时未能深究其背后的逻辑,缺乏理论上的深入系统分析。例如,很多讨论文章停留在表面,没有解释为什么有些“失街亭”是以“挥泪斩马谡”的方式解决,有些“失街亭”则以“下不为例”草草收场;也没有深入解释不同解决方式带来的结果是什么。再比如,有些观点认为任何时候都应该坚持规则,不能随意朝令夕改;而有些观点则认为不应该墨守成规,应该审时度势、因地制宜。这两个观点明显是矛盾的,孰对孰错仍然没有定论。
(二)相关文献述评
关于“失街亭”这类普遍现象,虽然在国内学术界中没有系统深入的论述,但是在国际学术界已经进行了理论研究,并形成了广为接受的一般性理论。其中最重要的是基德兰德和普雷斯科特的动态不一致性理论和卢卡斯的政策无效理论。
普雷斯科特和基德兰德将“失街亭”这类的现象加以归纳提炼,指出了其中存在长期最优计划和短期最优计划,两者之间存在冲突;他们将这个冲突称为时间不一致性。政策实施方为未来指定长期最优计划,但是这个计划在落实时环境已经变化了,不再是最优的。此时会存在着与当时形势相关的短期最优计划。于是就出现了长期最优计划与短期最优计划不一致的问题,这被称为时间不一致性,后来又被为动态不一致性。在博弈论的理论体系中,是否存在时间一致性或动态一致性是指纳什均衡是否也是子博弈精炼的,即时间一致性或动态一致性就是指子博弈精炼纳什均衡。因为存在着不一致性,政策方就有强烈的动机偏离长期最优计划,转而采取短期最优计划。但是这种动机带来信任与合作丧失的负面后果。基于此,基德兰德与普雷斯科特用数学模型分析了时间一致性和不一致性的一般原理。(1)Finn Kydland and Edward Prescott,“Rules Rather than Discretion: The Inconsistency of Optimal Plans,” Journal of Political Economy, Vol.85, No.3,1977,pp.473-491.
卢卡斯指出,如果政策方想利用不一致性获得好处,则由于理性预期的存在,政策方的企图不仅徒劳无功,即政策无效,反而会丧失公众信任,还会被公众在识破政策方动机的基础上进行反制,束缚了政策方手脚,反而导致政策不仅无效反而愈加糟糕的后果。(2)Robert E. Lucas,“Econometric Policy Evaluation: A Critique,” Carnegie-Rochester Conference Series on Public Policy 1, 1976,pp.19-46.
关于当局与公众之间的信任建立问题,经济学家在货币政策和通货膨胀问题上做出了很多研究,这些研究也都多多少少建立在动态不一致性和理性预期原理的基础上。巴罗具体分析了货币当局与公众之间信任博弈对解决通货膨胀的影响。为此他建立了动态模型,广泛利用了博弈论的方法,分析了声誉机制在信任与合作建立中起到的作用。(3)Robert J. Barro,“Reputation in a Model of Monetary Policy with Incomplete Information,” Journal of Monetary Economy, Vol.17,No.1,1986,pp.3-20.巴库斯和德里菲尔也建立了类似的模型。(4)David Backus and John Driffill,“Inflation and Reputation,” American Economic Review, Vol.75,June 1985, pp.530-538.此外,巴罗和戈登还分析了公众对政策当局的惩罚机制在维持信任与合作关系中起到的作用(Barro and Gordon, 1983)。(5)Robert J. Barro and David B.Gordon, “Rules, Discretion and Reputation in a Model of Monetary Policy,” Journal of Monetary Economics, Vol.12,July 1983,pp.123-125.罗格夫分析了解决信任问题的一个机制,就是让公众选择一个与自己偏好完全一致的代理人主掌政策制定与实施。(6)Kenneth Rogoff,“Reputational Constraints on Monetary Policy,” Carnegie-Rochester Conference Series on Public Policy 26,1987, pp.141-181.
但上述理论并没有完全解释公共管理中的信任与合作建立机制问题。动态不一致性原理触及了信任缺乏的根本原因,提出了基础性理论,但是并没有对信任建立或丧失的一般博弈过程进行理论分析。巴罗等人的理论分析了博弈过程,但是他们的理论一是针对通货膨胀问题中的货币当局和公众之间的博弈,二是他们的模型在分析博弈动态过程时不具有一般性,至少是不能分析中国的情况。因此,我们仍然有必要对公共管理中的信任和合作机制展开理论分析。
(三)研究思路
本文对我国公共管理中信任机制的建立进行理论分析,所用到的原理是动态不一致性理论和理性预期,并通过扩展这两个原理,分析信任机制建立的内在规律,以弥补现有研究在这个问题上的空白。这里的公共管理,主要是指行政机构在管理社会时如何采取政策和调整政策。
具体而言,本文要研究政策方和公众之间的互动具有什么样的必然逻辑,从而影响着信任是否能够建立,合作是否能够形成。在此基础上分析,为什么有些公共管理建立了信任,而在有些公共管理中,信任无法建立,并进一步就如何建立信任机制给出政策建议。
在利用动态不一致性和理性预期进行研究时,在方法上要用到动态博弈的基本思路和机制设计理论。信任建立是一个动态博弈过程,需要用到博弈论的相关理论。阿布鲁分析了如何通过纠错机制对失信行为加以校正以重建信任的机制,分析信任机制的建立是一个解释世界的工作,在此基础上需要改变世界,因此也要利用博弈论中的机制设计理论提出政策建议。
据此,本文接下来的第二部分提出一个静态的博弈模型,第三部分提出动态的博弈模型,从而完成理论分析,第四部分对模型的一般性结论进行总结并提出政策建议。
二、公共管理与信任建立机制的静态基准模型:囚徒困局的出现
(一)公共管理的基本结构与问题
公共管理主要体现为公共机构针对公众的制度和政策推行所进行的管理。管理是否有效,取决于公众是否信任和合作,体现为公共机构和公众之间的互动,这种互动会重复进行。显然,这是一个公共机构和公众之间阶段博弈不断重复的动态博弈过程。为了建立模型,我们将动态博弈的关键要素归纳如下:
在阶段博弈中,公共机构出台规章制度或政策,承诺要严格执行,这包括兑现奖励或者实施处罚;民众选择是否相信,这构成信任或者敬畏,从而决定自己如何行动,是否合作;然后公共机构要决定是否遵守承诺坚持既定的制度或严格执行宣布了的政策。
在阶段博弈的重复过程中,公共机构要考虑每一次博弈中如何施政对下一次博弈时公众信任与合作带来的影响,而公众会根据上一次或更早前博弈中公共机构的表现来选择是否信任和合作。换言之,这是一个策略问题。公共机构的策略包含两个方面。一方面,他今天要决定今后各个时期的政策是什么。另一方面,当今后的时间段到来后,他要决定是按照原来制定的政策做,还是根据变化了的形势,相机抉择地采取对当时情形最合适的新的政策。公众的策略很简单,就是在每个时期做出自己的最优选择,选择是否相信公共机构。
从公共机构的目标来看,一方面,它希望在各个时期的政策效果加总起来达到最优状态,但是这意味着可能要牺牲某一个特定时期,从而换来今后长时期的政令通畅。比如,当民众卷入各种高风险的金融活动而遭遇巨额亏损时,政府要不要出面救济,要不要动用财政资金给予一定的弥补呢?如果政府只打击违规行为,但是不弥补个人损失,会招致民众不满,引发上访。但是从长期而言是有好处的,会大大降低民众再次卷入同样风险的动机,从而带来金融市场秩序的稳定。
但另一方面,公共机构也往往被当前问题所困扰,有着强大的不顾后果而解决当前问题动机。在上述金融违规案例中,如果受害者众多,政府也可能在惩处违规金融机构的同时,为了社会稳定而对受害者的损失给予一定的弥补。这在现实中也是经常出现的。问题是,如此一来,民众从此就不再畏惧风险,因为有政府兜底。
(二)具体数学模型
下面我们用一个具体的数学模型说明管理过程中公共机构和公众之间的互动问题。假设公共机构的目标用下面的效用函数表示:
(1)
其中各个符号的含义是:U表示公共机构的效用函数,可以看成是公共机构希望实现的最高境界;X表示公共机构的业绩表现,公共机构最好的业绩是X*;Y表示公共机构的政策措施,公共机构最偏爱的政策措施是Y*。式子(1)表明,公共机构从业绩X和政策Y中获得效用。
公共机构在推行政策取得业绩时,受到现实的约束;我们可以用如下函数描述这个约束:
(2)
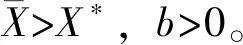
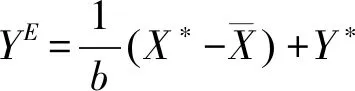
由此我们可以确定这个模型中信任的定义:
定义1:当YE=Y*时,群众对公共机构是信任的。
结合公共机构的目标函数和现实的约束条件,我们可以看到公共机构和群众之间的互动存在如下情形:
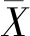
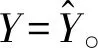
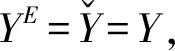
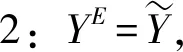
(三)阶段博弈中信任与合作的静态均衡:囚徒困局的形成
首先分析公共机构和群众之间的一次性静态博弈。公共机构会根据群众是否信任来决定采取何种政策Y,以便达到何种业绩X。这就是在式子(2)的约束下,选择X和Y,寻求式子(1)的最大化。计算结果是一个反应函数Y=R(YE):
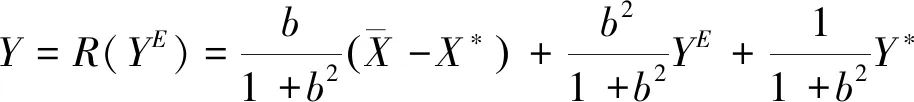
(3)
图1绘制了反应函数(3)的曲线。
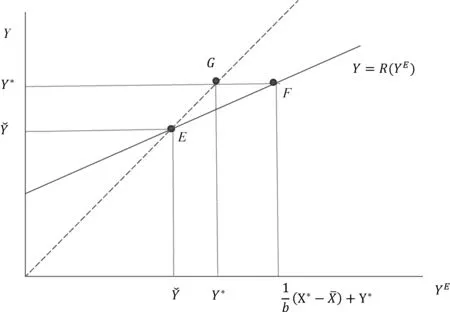
图1
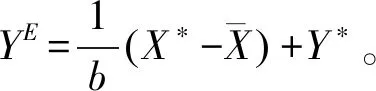
在现实中,通过和公共机构之间的长期博弈,群众会形成理性预期,即群众掌握了公共机构的行为逻辑,了解公共机构是按照式子(3)来采取政策的,其承诺是不可信的。因此,群众就会根据式子(3)来形成对政策Y的认识,即:
(4)
(5)
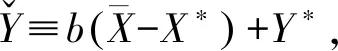
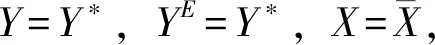
(6)
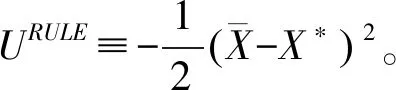
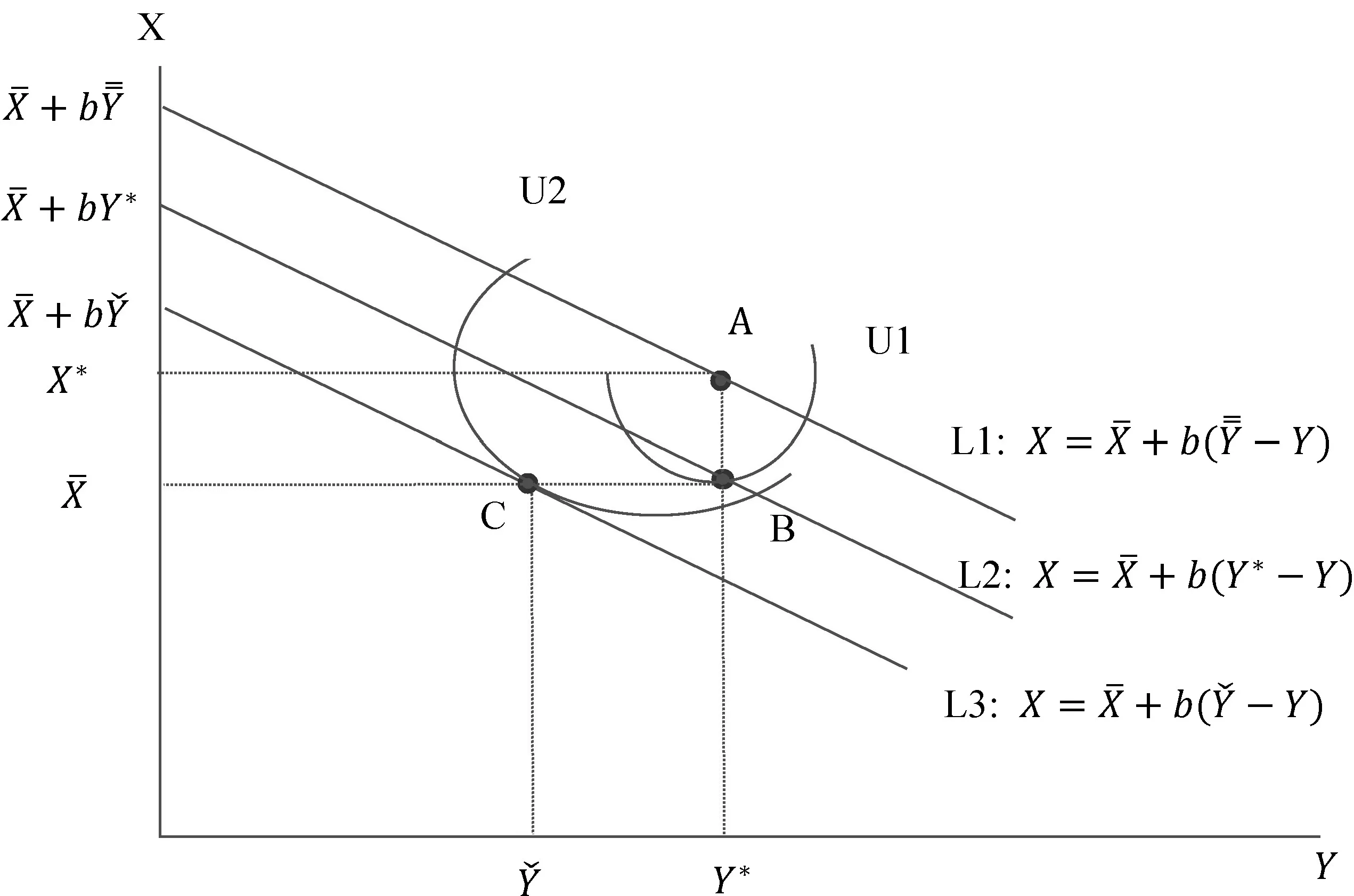
比较可以看到:UPD 表1 阶段博弈的不同情形 但是,在一次博弈中,囚徒困局是唯一的纳什均衡:在前面提到的各种情形中,唯有情形Ⅲ是静态博弈中的均衡。其存在原因在于理性预期和动态不一致性的相互作用。为了说明这个机制,我们需要定义长期最优计划和短期最优计划。 定义2:长期最优计划。公共机构在YE=Y和式子(2)的约束下寻求式子(1)最大化,由此所确定的Y的最优值即为长期最优计划。与Y=YE代表坚持规则略有不同,YE=Y代表预期的形成机制即群众信任公共机构宣布的政策。 定义3:短期最优计划。公共机构式子(2)的约束下寻求式子(1)最大化,由此所确定的Y的最优值即为短期最优计划。此时已经进入到YE已经确定的阶段,所以不再有YE=Y的约束。短期最优计划也就是即期最优计划。 定义4:动态不一致性。如果长期最优计划与短期最优计划不同,我们就称这种情况为动态不一致性。 在管理博弈的初期,公共机构希望群众给予信任和合作,相信公共机构必然实施已经宣称的政策,这在模型里表现为公共机构对Y承诺一个数值并努力让YE与之相等,此时承诺的Y值就是长期最优计划。但是,一旦进入到管理博弈的中期,YE已经确定而不再有更改的机会,与此对应存在一个不同的最优计划,这就是即期的短期最优计划。于是,轮到公共机构实施政策时会发现,基于群众已经给予的充分信任,实施一个不同的即期政策会带来更好的结果,这在模型里表现为重新选择的Y与事先宣布的Y不一致,从而也与民众笃信不疑的YE相背离。这样就出现了动态不一致性:事先宣布的最优计划到了执行时不再是最优的,长期最优计划与短期最优计划存在不一致性。这种不一致性诱致公共机构用短期最优计划(相机抉择)取代长期最优计划(坚持既定规则)。 图2 归纳起来可以看出,长期最优计划是B点,但是公共机构的短期计划与之不同;最好的短期计划是A点,于是出现动态不一致性。动态不一致性终究被公众认识到,从而将结局引向C点。公共机构为了实现A点,结果得不偿失,连B点都牺牲了。C点是动态一致的。 在现实中,公共机构和群众之间的博弈是重复进行的。如果是有限次数重复,那结果仍然回到一次博弈的结局中。但是,可以通过制度设计将博弈改造成无限次数重复博弈。在无限次数重复博弈条件下,存在着多重均衡:子博弈纳什均衡有多个,其中有的均衡是有效率的,有的均衡是无效率的。本文不求解所有的均衡,而是只分析在现实中存在过或有可能存在的均衡,借此说明现实的管理博弈中信任建立和缺失的机制是什么,如何确保信任与合作。 在无限次数重复博弈中,存在着奖励与惩罚机制,形成促使公共机构兑现承诺的制约,从而实现信任和合作。具有均衡性质的奖励与惩罚机制有多种形式,其中有两种是现实中经常出现的:对犯错者永远惩罚和给予改过机会。 首先我们分析对犯错者永远惩罚的制约机制,这在博弈论模型中叫做以牙还牙策略,即一旦有任何一方违背了互信合作,那么从此各方便永远不再合作。具体到我们的模型中: 公共机构采取的“以牙还牙”的策略: (7) 群众采取的“以牙还牙”的策略: (8) 当贴现因子足够大时,上述“以牙还牙”策略构成子博弈精炼纳什均衡,即给定对方采取这个策略,自己采取这个策略得到的各期效用现值是最大的。下面计算这个贴现因子的临界值。为简单起见,假设公共机构和群众的贴现因子相同,用δ代表。 (9) (10) 要让支持互信和合作的“以牙还牙”策略构成纳什均衡,公共机构必须满足VRULE>VDR的条件。要满足这个条件,贴现因子必须足够大;设贴现因子最小临界值为δ*,则通过求解VRULE>VDR可以得到: (11) 就群众而言,如果公共机构采取式子(7)那样的“以牙还牙”策略,则自己采取式子(8)那样的“以牙还牙”策略是最最优的。这个道理很简单而无需证明,因为只有这样,才能确保自己的预期是对的。 需要说明的是,就本文的具体模型而言,上述计算结果是“以牙还牙”策略的唯一解。而在更为一般的模型中,“以牙还牙”策略会有多种。 “以牙还牙”策略是一个终极策略,一旦犯错就永不信任。这在现实中是大量存在的,比如刑事犯罪。一旦某人有了刑事案底,就会永远被排除在主流社会之外。在演艺圈也是一样,即使是大红大紫的明星,一旦出了状况,就不再有翻身的机会。 在现实世界,与“以牙还牙”策略同时大量存在的策略还有给机会“改过自新”的策略,这在博弈论里被称为“胡萝卜加大棒”策略:如果一方犯错,另外一方就会予以惩罚,但是不会是终身惩罚。如果犯错的一方能够表现出改正的诚意,对方就会再次接纳他。 在我们的模型中,这种“胡萝卜加大棒”的策略是: 公共机构采取的策略: (12) 群众采取的策略: (13) 要保证上述策略构成纳什均衡,必须满足两个条件。 第一个条件是确保选择Y*是最优的。这个条件已经在前面推导出来,就是δ>δ*,δ*由式子(11)给出。 (14) (15) 求解的结果是: (16) 此时有: (17) 假设公共机构采取式子(16)的策略所获得的当期效用为UDC,则有: 因此,要想让改过自行策略构成子博弈中的纳什均衡,则应该满足条件VCORRE>VDC,即选择改过自新获得的好处大于继续犯错,因为一旦改过自新,则今后回到互信合作的状态。这个条件意味着: VCORRE>UDC+δVCORRE (18) 即: (19) 在现实中,这种均衡也大量存在,例如在西方国家的两党政治中,大选落败的政党都有机会重新赢得大选;在夫妻关系和朋友关系中,也存在着出现分歧和解决分歧恢复关系的情形。 公共管理中的动态不一致性现象一直困扰着管理者,也一直被管理学者讨论,但是这些讨论都流于表面。我们在前面给出了一个具体的模型,对公共管理中存在的动态不一致性的机理做出了细致的刻画,给出了更为深刻的答案。 首先,最根本的结论是,模型证明了公共管理的动态博弈存在着多重均衡,其中有有效率的均衡,也有无效率的均衡,后者以囚徒困局为代表。这解释了为什么我们在现实中既看到很多公共管理存在缺陷、效率低下,也看到有的地方公共管理卓有成效、井然有序,这些都是有其内在原因的。这说明,要改善公共管理并不是一个简单的事情。 其次,奖惩机制可以促使动态博弈实现有效率的均衡。奖惩机制有多重形式,前面的模型列举了永远惩罚和允许纠错两种机制。这两种机制在现实中广泛存在,例如前面提到的刑事犯罪、明星犯错和两党政治、夫妻朋友关系等等。此外,还有更多形式的其他奖惩机制。奖惩机制设计中,贴现因子和惩罚奖励的程度是两个重要的因素。如果贴现因子不够大,也就是说如果公共机构只关注当前政绩,不在乎今后的损失的话,那么加大奖惩力度或者设计奖惩方式就极为必要了。公共机构只关注当前政绩,主要原因是其代理人的任期是有限次数的,任期届满就会另赴他处。 再次,模型还解释了卓有成效的公共管理并不是始终处于有效率状态,中间会不断出现偏离效率的情形,不过一旦偏离,总能够重新回到正轨。正如模型所揭示的,动态博弈中的均衡是由若干子博弈精炼纳什均衡支持的,这个子博弈精炼是动态一致的。在催生信任与合作的公共管理博弈中,构成精炼纳什均衡的子博弈有两类,分别导向两个方向:要么走向重新合作,要么继续承担代价。这表明,要维持信任与合作,是要付出成本的。一旦离开了长期最优方案,错失其所能实现的长期最优目标,要想再回来,就需要经过若干个短期的高成本努力,重获信任并善待信任,从而重新形成互信。可以用法律维护秩序的博弈例子来说明:犯法后追究法律责任是子博弈,是为了确保所有人不以身试法。在违法追责的子博弈中,还需要选择惩罚强度,是严厉惩罚还是适当惩罚。 另外一个例子是美国历史上的反通货膨胀做法。美国在20世纪70年代时经历了严重的通货膨胀,1979年沃尔克就任美联储主席,声称要紧缩货币以反通货膨胀,但是一开始人们并不信任他。因此,当通货膨胀率从1980年的13%降低到1982年的6%以下时,失业率则从7%飙升至接近10%。但是,因为美联储坚守规则,没有因为失业率上升而改变货币政策,到1983年,通货膨胀再降至3%以下时,失业率反而开始减少;而到1986年,通货膨胀率再降低到2%以下时,失业率反而减少到7%。1980—1982年间,在失业率不断攀升时,本来美联储转向相机抉择,放松货币紧缩政策的力度甚至寻求货币扩张,也许能阻止失业率上升过快,但是这会带来长期隐患,如同此前20世纪70年代发生的:失业率高时采取扩张性货币政策降低失业率,但是带来通货膨胀率的提高;而看到通货膨胀率提高时又紧缩银根,但是已经降低的失业率开始反弹。 最后,模型还告诉我们,在改善公共管理表现时,应该重视被管理者的理性程度。在前面的模型中,假设公众是完全理性的,因此可以实现理性预期。这样在短期就会必然出现囚徒困局,而在动态博弈中也容易走出囚徒困局。但是在现实中,人们并非是完全理性的,而且不同人理性程度参差不齐。这就意味着不一定有囚徒困局,也意味着实现有效率的公共管理更为困难。 本文理论分析表明,在公共管理中要制定并执行长期最优计划,不能在短期内偏离它。但是要实现这个政策却极为困难,因为存在着动态不一致性。因此,更重要的是要找到一个机制,破解动态不一致性,限制行政部门以短期化的方式执行长期政策的权力。我们可以利用既定制度来形成这个机制: 第一,强化人民代表大会的决策权和监督权,由人民代表大会审批各种长期规划,监督其执行情况。同时,应该在人大和政府部门之间形成一个明确的防火墙。 第二,强化法律问责机制,确保行政部门信息公开和依法行政,并能够对偏离长期最优计划的举措进行问责。事实上,这一点在现阶段已经有了很好的基础,例如官员任免和各种利益分配的公示制度。 第三,与信息公布有关的事项交由专业部门独立完成,地方政府最高领导机构依法不能干预。例如,经济统计数字应该由统计局独立发布,无需获得地方领导机构授权;与公共卫生有关的疫情信息有疾控中心独立发布,不能够把信息公告政治化。 第四,在对公共机构进行监督时,应该依赖独立的专业机构。专业机构相对普通民众而言更为理性,有更多的专业知识,从而能通过囚徒困局形成威慑,也能在陷入囚徒困局后顺利走出。
三、信任与合作的动态均衡
(一)采取“以牙还牙”策略走出囚徒困局
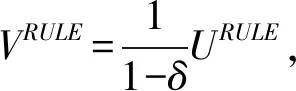
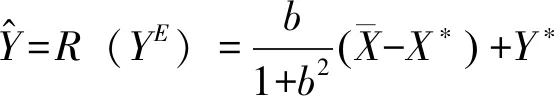
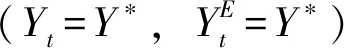
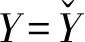
(二) 引入改过自新策略走出囚徒困局
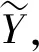
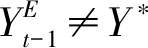
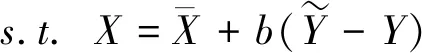
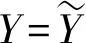
四、如何解决公共管理中的动态不一致性问题
(一) 信任与合作模型对现实动态不一致性的解释
(二)基于信任合作模型的政策建议
猜你喜欢
卫星应用(2022年7期)2022-09-05 02:36:02
卫星应用(2022年3期)2022-05-23 13:44:30
卫星应用(2022年1期)2022-03-09 06:22:20
环球慈善(2019年6期)2019-09-25 09:06:24
少年博览·小学高年级(2018年10期)2018-12-10 09:00:04
小天使·一年级语数英综合(2017年7期)2017-08-04 18:58:39
桃之夭夭B(2017年2期)2017-02-24 17:32:43
小天使·一年级语数英综合(2017年2期)2017-02-16 20:38:53
小天使·一年级语数英综合(2017年2期)2017-02-16 10:18:24
小天使·五年级语数英综合(2017年1期)2017-02-08 20:15:05
