
基于深度学习的大米垩白分割算法研究
2021-05-26 08:41:06尚玉婷
中国粮油学报 2021年4期
邓 杨 王 粤 尚玉婷
(浙江工商大学信息与电子工程学院,杭州 310018)
大米的外观是关乎大米品质的一项非常重要的指标。正常大米呈白色透明状,垩白区域因大米含水分过高或水稻收割时未成熟而造成,呈白色不透明状,边界不清晰,通常位于大米的腹部。含有垩白区域的大米因为缺少有助于人体代谢的磷酸烯醇式丙酮酸,营养价值低。大米质量安全关系到国人的生命健康,如何更加准确、快速的检测出大米是否有垩白,垩白度为多少就显得尤为重要。
基于机器视觉的大米外观质量检测是农作物外观检测的热点问题,传统方法主要为基于阈值分割及支持向量机的算法。Cardarelli等[1]通过SVM算法,以大米图像的R、G、B平均分量值作为特征数据,对正常米粒和垩白米粒进行识别。侯彩云等[2]开发了一套用于稻谷垩白检测的图像处理系统,通过阈值的设定提取稻谷中的垩白区域,并计算垩白度和垩白粒率,但基于经验设定的阈值给检测结果带来了较大的误差。Sun等[3]根据灰度值的差异提取垩白区域和普通米粒,再采用SVM算法对大米垩白区域进行分类。王粤等[4]用直方图不同的分布区分普通米和垩白米,采用改进的最大类间方差进一步分析米粒的垩白度、垩白率等信息。基于传统的机器视觉或机器学习的垩白米识别方法对光照条件,米粒上的划痕,以及胚芽部分的干扰等因素比较敏感,从而造成识别精度受到较大的影响。
近年来,随着卷积神经网络在图像分类领域获得的巨大成功,基于卷积神经网络的语义分割也成为计算机视觉领域中另一个重要的研究热点。由Long等[5]在2015年提出的全卷积网络(Fully Convolution Networks,FCN)正式将卷积神经网络引入语义分割领域。随后的SegNet[6]、U-net[7]、DeeplabV3+[8]均取得了较好的分割结果。虽然这些网络有很好的分割效果,但大量的计算也还是限制了其在移动设备上的部署。Howard等[9]提出了轻量级网络MobilenetV2,使用深度可分离卷积(Depthwise Separable Convolution)代替普通卷积,极大地减少了网络参数量。PASZKE等[10]使用轻量级语义分割网络ENet,实现嵌入式端的语义分割,且分割精度优于SegNet。Wang等[11]提出了实时语义分割(Real-time Semantic Segmentation)网络LEDNet,编码结构中通过channel split and shuffle降低计算成本,同时保证分割准确度,解码器加入注意力金字塔网络(APN,attention pyramid network),减轻网络的复杂度。
虽然语义分割在很多领域获得了较大的成功,但将其应用到农作物大米的外观质量检测中的研究并不太多。孙志恒[12]采用改进的全卷积神经网络FCN-8s,并结合超像素分割技术,对大米、大米垩白、大米胚芽进行分类识别,将深度学习应用到了大米垩白区域的智能检测中,但FCN-8s网络参数量较大,实时操作有难度。本研究提出了一个轻量级大米垩白米垩白区域识别网络IMUN,该网络不仅能实现对大米上的垩白区域进行精确像素级分割,同时网络模型小,适合于集成到嵌入式可移动设备中。
1 IMUN网络的构建
语义分割网络通常由编码结构和解码结构组成,解码部分将编码结构中学习到的特征从语义映射到像素空间,从而获得每个像素的类别。为了获得较好的分类效果,通常采用VGGNet、ResNet、GoogleNet等网络,这些网络虽然有较好的分类性能,但参数量大、运算时间长,严重限制了语义分割在移动设备和嵌入式设备端的应用。考虑到农作物外观质量的检测通常都需要到现场实地检测,那么面向移动及嵌入式设备的轻量级语义分割网络就是很好的选择。因此,本研究编码结构采用了MobileNetV2网络结构,并做了以下改进:在倒残差冗余块的深度可分离卷积中注入空洞卷积,加大视觉感受野,获取更多特征信息,同时,线性瓶颈结构(Linear bottlenecks)使信息的输出不经过Relu6层,从而更好地保留了特征信息。解码部分基于UNet的解码结构,上采样过程中获取的高层特征信息较为抽象,将上采样过程中恢复的特征,与同层编码结构进行特征连接,有助于恢复信息损失,并且能保留更多细节信息。模型整体设计呈非对称结构,极大地减少了网络参数,提高了训练效率。目前,大部分在移动端的深度学习任务都是依赖云服务器完成计算的,本研究模型的提出使得网络训练可以不通过云端,直接在移动设备本地完成,避免了系统延时和额外数据开销等问题。IMUN的整体网络框架如图1a所示,编码结构如表1所示。
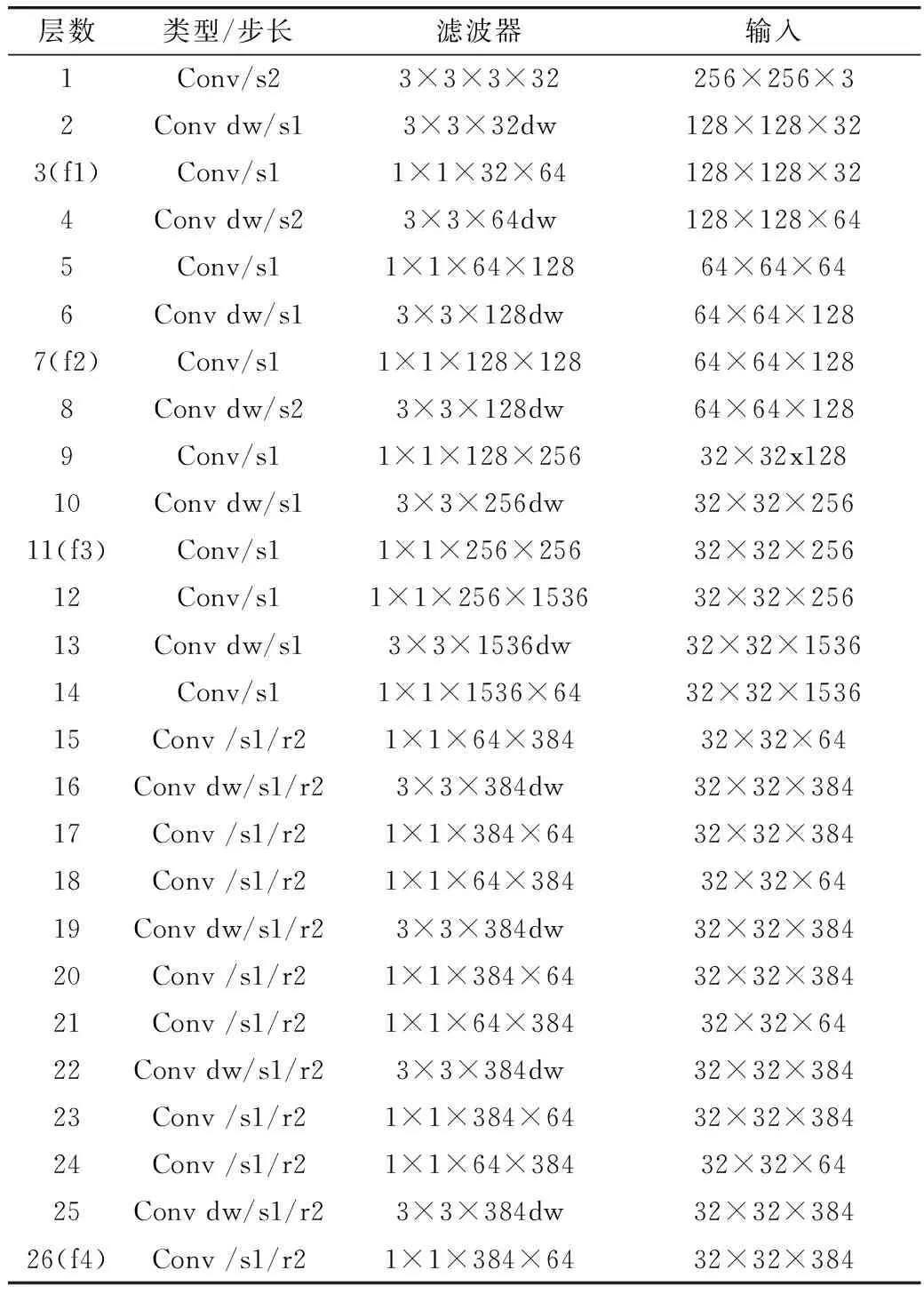
表1 编码结构
1.1 编码结构
如图1所示,网络的编码结构由11个块(Block)组成,网络的输入图像为256×256×3的米粒图像。首先经过1次3×3的普通卷积,并对其做标准化(BatchNormalization,BN),激活函数采用Relu6函数;接着通过5次深度可分离卷积,表1中的Conv dw即为深度卷积(Dwpthwise Convolution,DW);当DW卷积完成后,再利用1×1的PW卷积(Pointwise Convolution,PW)做通道调整,对其做标准化(BatchNormalization,BN),激活函数采用Relu6函数。接着,进入5个倒残差空洞卷积冗余块,结构如图1b所示。
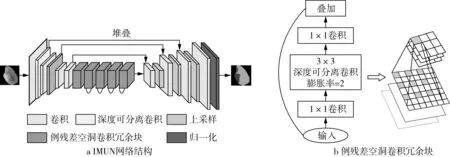
图1 IMUN网络结构和倒残差空洞卷积冗余块
MobileNetV2延用了MobileNetV1的深度可分离卷积,并加入了倒残差冗余块,先对输入信息做1×1卷积升维,再通过DW卷积和PW卷积。倒残差冗余块的引入增强了梯度信息的传播,同时减少了推理所需内存。此外,加入线性瓶颈结构直接对结果进行线性输出,防止Relu6层带来的信息丢失,保留了特征的多样性,提高了网络的鲁棒性。网络中在第一个倒残差结构中不对结果做加法输出。
实际检测中,米粒图像的像素分辨率较低,大量的卷积会导致小物体的特征信息无法重建,也会导致空间级化信息丢失,对分割的准确度有一定的影响。而空洞卷积则可以在不损失空间信息的情况下,很好的保留全局信息,使得每个卷积输出都包含较大范围的信息。因此,本研究在f3之后均采用了倒残差空洞卷积冗余块,改用膨胀系数为2深度可分离空洞卷积,从而使网络在扩大感受野的同时,能捕获到更多的特征信息。
1.2 解码网络
本研究的解码结构如表2所示,与编码结构呈非对称,在一定程度上减少了网络参数量,加速了推理过程。首先将编码网络的f3、f4特征层连接,作为解码网络的输入,经过卷积和上采样操作,与f2特征层的信息进行连接,再通过卷积和上采样与f1特征层连接,最后做卷积和上采样操作,输出与输入图像尺度相同的图像。
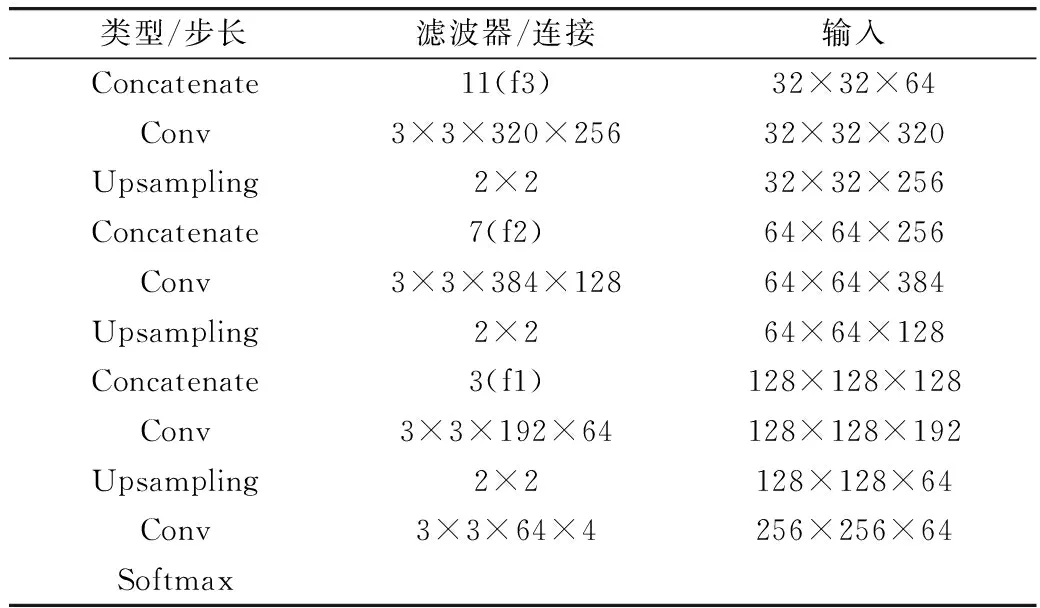
表2 解码结构
1.3 损失函数的优化
为了得到更准确的分割结果,需要选择合适的损失函数减少预测值和真实值之间的差距。交叉熵损失函数是语义分割多分类问题中最常用的损失函数,但是这种方法在样本不均衡的情况下表现得并不好。在一些语义分割场景中,往往一幅图像中的目标像素比例较小,加剧了网络训练的难度。在本研究中,垩白和胚芽部分的像素点相对较少,仅仅选择交叉熵作为损失函数无法进行准确的分割。Tversky loss可以用来描述真实区域和预测区域的相似程度,在目标不均衡的场景下有较好的表现。针对语义分割多分类任务,本研究提出一种融合了交叉熵损失函数和Tversky系数损失函数的方式,通过交叉熵计算全部类别的损失值,再通过Tversky loss计算米粒和垩白区域的损失值,这两个损失值的加权作为整个网络的损失值。具体定义如下:
MLoss=-λ∑p(x)logq(x)+(1-λ)
(1)
式中:p(x)为预测值,q(x)为对应的真值,TP(True Positive)表示实际为正样本预测正确的样本,TN(True Negative)表示实际为负样本预测正确的样本,FP(False Positive)表示实际为负样本预测错误的样本,FN(False Negative)表示实际为正样本预测错误的样本,α是控制FP和FN的权重因子,λ为控制交叉熵损失函数和Tversky系数损失函数权重因子。
2 材料与环境
2.1 数据集采集
本研究选取了市面上比较常见的米粒作为样本,分别选择正常粳米、籼米(无垩白区域的透明完整米),垩白粳米、籼米(带垩白区域完整米)以及碎米(由于加工、运输等原因造成的米粒破损)。使用大恒HV1341UC相机,25 mm真彩色高清摄像镜头,俯视角度拍摄,配合环形光源,尽可能保证采集样本不失真,背景托盘采用了黑色无纹路面板,方便后续对采集到的样本进行一系列预处理。采集样本在图像分辨率为1 024×768,共采集300幅米粒图像,每幅图像约含15粒米,拍摄样例如图2所示。
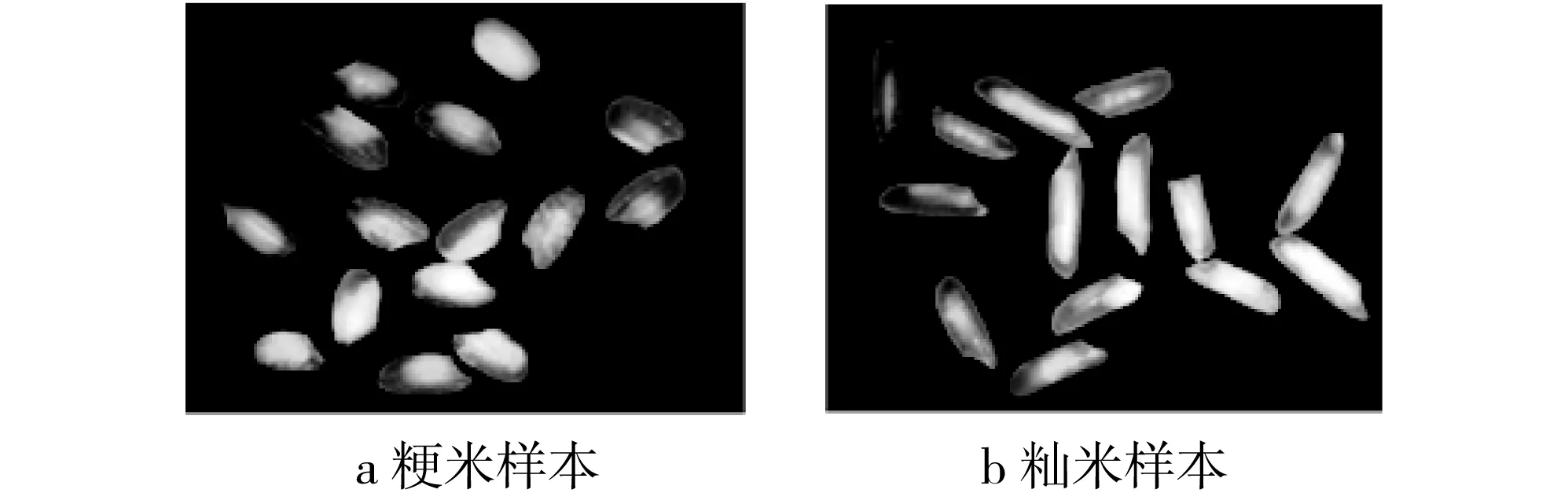
图2 米粒拍摄样本

图3 米粒原图及标注图像
2.2 数据集制作
考虑到用于深度学习的米粒数据集中最好是多幅单个米粒的图像,因此,上节获得的米粒图像需要做预处理,对其进行自动切割,由于样本是随意放置在拍摄台上的,米粒之间可能会出现粘连,必须要通过一定的切割算法,让其自动形成单个米粒的多幅图像。本研究根据王粤等[13]提出的粘连米粒的分割算法,首先获取米粒的轮廓线,然后,根据轮廓线上的各像素点的曲率方向判断米粒是否有粘连,若有,则寻找并计算最佳粘连点对,实现米粒的粘连分割,由此可以获得每颗米粒的完整轮廓线。之后就可依据每颗米粒的轮廓线信息,获取对应的米粒的图像信息,这样,上节采集到的图像中的每粒米都可对应生成一副新的背景为黑色的图像。
通过对粘连米粒的分割,得到2 000幅单个米粒样本,其中包括936粒正常米,1 049粒垩白米,15粒碎米。为了防止样本数据太少造成的训练结果过拟合,对分割后的的2 000个米粒样本进行数据增强,分别进行镜像、旋转等操作,并随机选取样本进行颜色抖动,最终得到10 000幅训练样本,其中8 000幅为训练集,1 000幅为验证集,1 000幅为测试集。使用开源工具Labelme,对采集到的大米图像中的无垩白区域米粒、垩白区域及胚芽3个部分进行标注,数据集中共有米粒、垩白、胚芽、背景4类。图3为分割后的米粒样本与其对应的标签。
2.3 实验环境
本研究基于Ubuntu 16.04操作系统,处理器为2颗8核Inter E5-2620V42.0Ghz,128G内存,2 400 MHz,GPU为2块NVIDIA TITAN XPPASAL。模型的搭建与训练验证通过Python语言实现,基于Keras2.1.5深度学习框架,并行计算框架使用CUDA 9.10版本。Batch_size设置为16,初始学习率(Learning Rate)设置为0.0001,训练40代(Epoch),通过ReduceLROnPlateau调整学习率,当评价指标不再提升时,减少学习率。
3 结果与分析
3.1 不同权重因子对分割结果的影响
为了验证损失函数的有效性,寻找更合适的权重因子,得到更高准确度的分割结果,本研究做了九组对比实验,如表3所示。从实验结果可以看出,当控制Tversky loss的权重因子α=0.9,控制MLoss的权重因子λ=0.7时,垩白区域的Intersection Over Union(IOU,交并比)值最高,达到94.11%,同时Mean Intersection Over Union(MIOU,平均交并比)达到92%,Pixel Accuracy(PA,像素准确精度)和Mean Pixel Accuracy(MPA,平均像素精度)分别为98.61%和96.34%。当α=0.9,λ=0.7时,网络在迭代30代之后,训练集的训练精度呈稳定状态,接近99.5%,验证集的训练精度在98%~99%之间波动;训练集的损失值最后稳定在5.41~5.92,验证集的损失值在迭代了35代之后逐渐稳定。
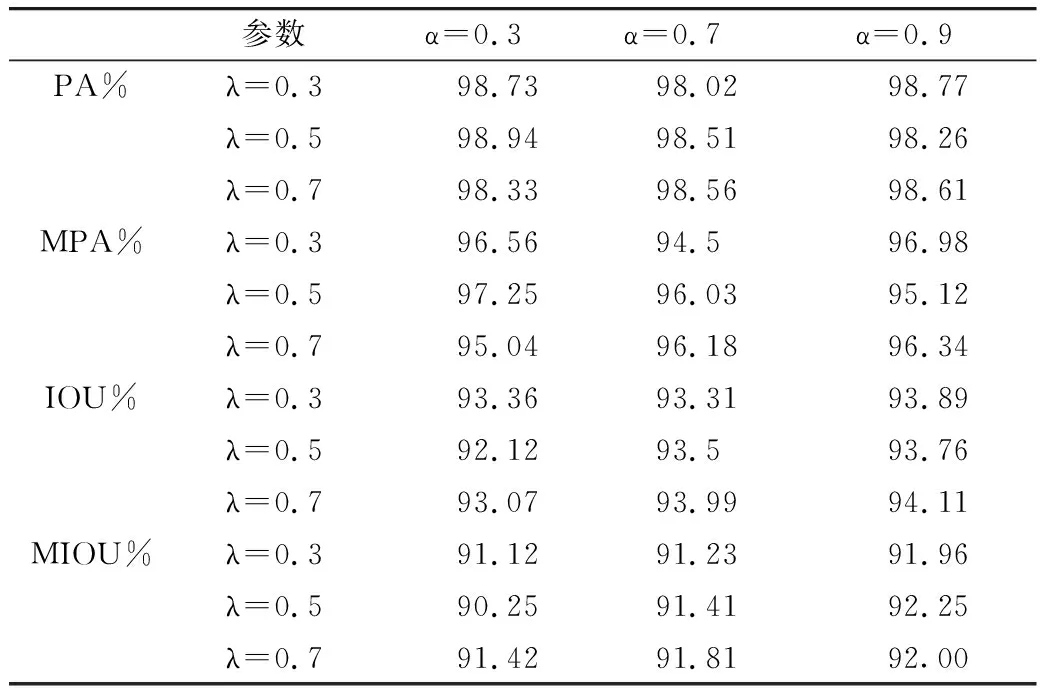
表3 不同权重因子下的评价指标
3.2 与其他语义分割网络的结果对比
本研究模型旨在尽可能保证准确度的同时,降低模型参数量。本研究的IMUN与其他各种网络结构的比较结果如表4所示,可视化结果如图4所示。基于MobilenetV2网络和基于VGG16网络的解码结构与本研究模型均选择了Unet,由表4可以看出:二者的参数量分别为本研究模型的3倍和14.8倍,即便是参数量较少的MobilenetV2-Unet模型,IOU和MIOU也比本研究模型低了2.65%和2.55%。而LEDnet和Enet作为经典的轻量级语义分割网络,参数量虽然比本研究模型少,但IOU比本研究模型低了3.55%和6.37%,MIOU低了3.82%和5.16%;Segnet和基于Xception的DeeplabV3+有较好的分割效果,垩白区域的IOU分别达到95.97%和97.45%,但参数量分别为本研究模型的4.9倍和19.7倍,虽然获得了较高准确率,但参数量较大。
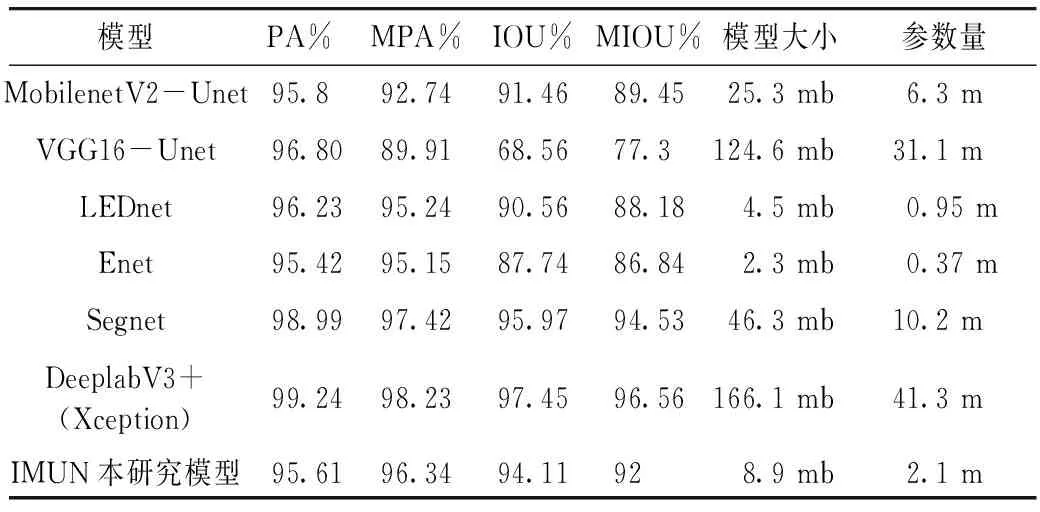
表4 不同模型下的评价指标

图4 不同分割方法的可视化结果
4 结论
本研究提出了一个轻量级的语义分割网络IMUN,与参数量较大的经典语义分割网络相比,在几乎不损失准确度的情况下减少了网络参数量;与轻量级语义分割网络相比,参数量在同一量级,但对垩白区域的分割能力更为突出。接下来的研究将对网络进一步优化,提升大米垩白区域的分割准确度;并以本网络结构为核心,添加图像采集、图像预处理、图像粘连分割等模块,从而能实时在线检测包括垩白度和垩白率在内的各种大米外观信息。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
少先队活动(2020年6期)2020-12-18 01:08:56
开放教育研究(2020年2期)2020-03-31 01:54:14
今日农业(2019年15期)2019-01-03 12:11:33
幼儿智力世界(2017年1期)2017-04-26 20:38:21
现代语文(2016年21期)2016-05-25 13:13:44
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
小学科学(2015年9期)2015-09-28 22:21:29
小学科学(2015年8期)2015-09-06 18:01:49
