
基于最频繁项提取和候选集剪枝的THIMFUP算法
2021-05-26 02:23曲福恒刘俊杰
吉林大学学报(理学版) 2021年3期
杨 勇, 张 磊, 曲福恒, 刘俊杰, 陈 强
(1. 长春理工大学 计算机科学技术学院, 长春 130022; 2. 长春师范大学 教育学院, 长春 130032)
关联规则挖掘技术是数据挖掘[1]领域最常用的技术之一, 其可从复杂的数据中得到不同项集之间的隐藏规律, 从而为各行业的发展提供辅助决策, 目前关联规则挖掘技术已得到广泛关注.
目前, 对关联规则增量挖掘算法的研究相对较少, 其主要分为两类: 第一类是以Apriori算法[2]为基础的基于迭代的增量算法, 如FUP(fast update algorithm)[3],FUP2[4],IUA(incremental updating algorithm)[5]等; 第二类是以FP-growth[6]为基础的基于树结构的增量算法, 如Cat-tree[7]和Can-tree[8]等, 该类算法以树结构[9]为基础, 挖掘过程不会生成候选集, 也不需要扫描数据库, 但过于依赖事物的顺序, 并且当数据集过大时, 生成的树结构太复杂, 对内存消耗较大, 不适合大数据集环境下的规则挖掘. 因此, 本文主要考虑基于迭代的关联规则增量算法. 除FUP算法外, 针对增量规则挖掘问题, 目前基于FUP算法已提出了很多改进算法, 如黄德才等[10]提出了Pruning FUP算法, 通过减少对数据库的扫描次数提高算法效率; 闫仁武等[11]提出了基于时间权值的增量更新算法, 通过对不同时期数据加权[12]以控制效率和规则的准确性; 朱晓峰等[13]提出了基于MapReduce[14]的FUP算法, 利用并行化提高了运算效率; 尹艳红[15]提出了IUTS算法, 结合FUP和IUA算法的思想, 从支持度和数据库两个角度解决了挖掘问题; 张步忠等[16]对已有的增量算法进行了详细综述; 耿志强等[17]提出了基于矩阵的关联规则增量算法(MFUP), 利用矩阵避免了数据库的重复扫描; Zhang等[18]提出了FUP-HAUIMI算法, 在性能较高的条件下提高了规则的实用性; 曾子贤等[19]提出了MIFP-Apriori算法, 通过结合矩阵和改进频繁模式树减少候选集冗余.
FBCM算法[20]是对MFUP算法的进一步改进, 利用矩阵压缩[21]的思想减小解的搜索空间, 并将算法对数据库的扫描运算转化成Boole矩阵[22]的逻辑“与”运算, 使数据库的扫描次数降低到一次, 对增量挖掘效果较好. 但当数据库过大或支持度较小时, 该算法并未考虑到两个问题: 一是原数据库DB生成的原频繁项集库LDB的规模也会很大, 频繁对LDB进行扫描会降低算法性能; 二是算法挖掘过程中生成大量的候选集, 对候选集的处理也会影响算法效率. 针对上述问题, 本文基于数据库中最频繁项[23], 降低算法对LDB的扫描次数, 并结合候选集剪枝思想, 减少算法生成候选集的数目, 对FBCM算法进行优化改进.
1 相关定义
原频繁项集库LDB: 表示原数据库DB挖掘得到的频繁项集集合;
总频繁项集库LDB∪db: 表示加入数据库db后挖掘得到的最新频繁项集集合;
最小支持度[24]阈值Sup: 支持计数大于该阈值的项集为频繁项集;
最频繁项THI: 表示数据库中出现次数最多的项目;
项目个数NP: 表示从数据库中选择THI的个数;
项目列表TH: 表示从数据库中选择THI构成的列表;
TH的非空子集列表TI: 包含TH列表内项目所有可能的非空组合.
TI中每个项目集的长度为1~NP(最大项目集), 本文将TI的每个成员称为THIT(THI的项目子集),THIT的数量为2NP-1. 因为NP通常很小, 所以THIT的数量(TI的大小)也很小. 例如NP=4, 并且2,5,8,10是从数据库中选出的THI, 则TH={2,5,8,10}.TH的所有非空子集都是THIT(如{2,5,8}和{2,10}). 因此|TI|=24-1=15, 所以
2 FBCM算法问题分析
FBCM算法源于FUP算法, 是解决支持度不变前提下数据库增加的规则挖掘问题, 相对于FUP算法, 该算法挖掘的效率更高, 在挖掘过程中避免了对数据库的重复扫描. 首先将数据集转化成Boole矩阵MatrixDB和Matrixdb, 然后利用生成的可压缩Boole矩阵对频繁项集进行挖掘. 挖掘过程中需要多次迭代, 每次迭代前都对MatrixDB和Matrixdb进行压缩, 以释放存储空间并减少逻辑“与”操作的时间消耗. 该算法的关键步骤是矩阵转换、 矩阵运算和矩阵压缩. 虽然FBCM算法较FUP算法性能有较大提高, 但该算法仍存在生成候选集过多、 频繁扫描LDB的问题.
本文利用Accidents数据集和T10I4D100K数据集对FBCM算法进行测试, 从这两个数据集内各抽取100条数据作为新增数据库db, 实验测试结果如图1和图2所示. 测试1是取T10I4D100K数据集, 不断缩小支持度所得到的算法效率. 测试2是使用Accidents数据集, 测试LDB递增时的算法效率. 图1和图2的实验结果很好地显示了FBCM算法存在的问题:
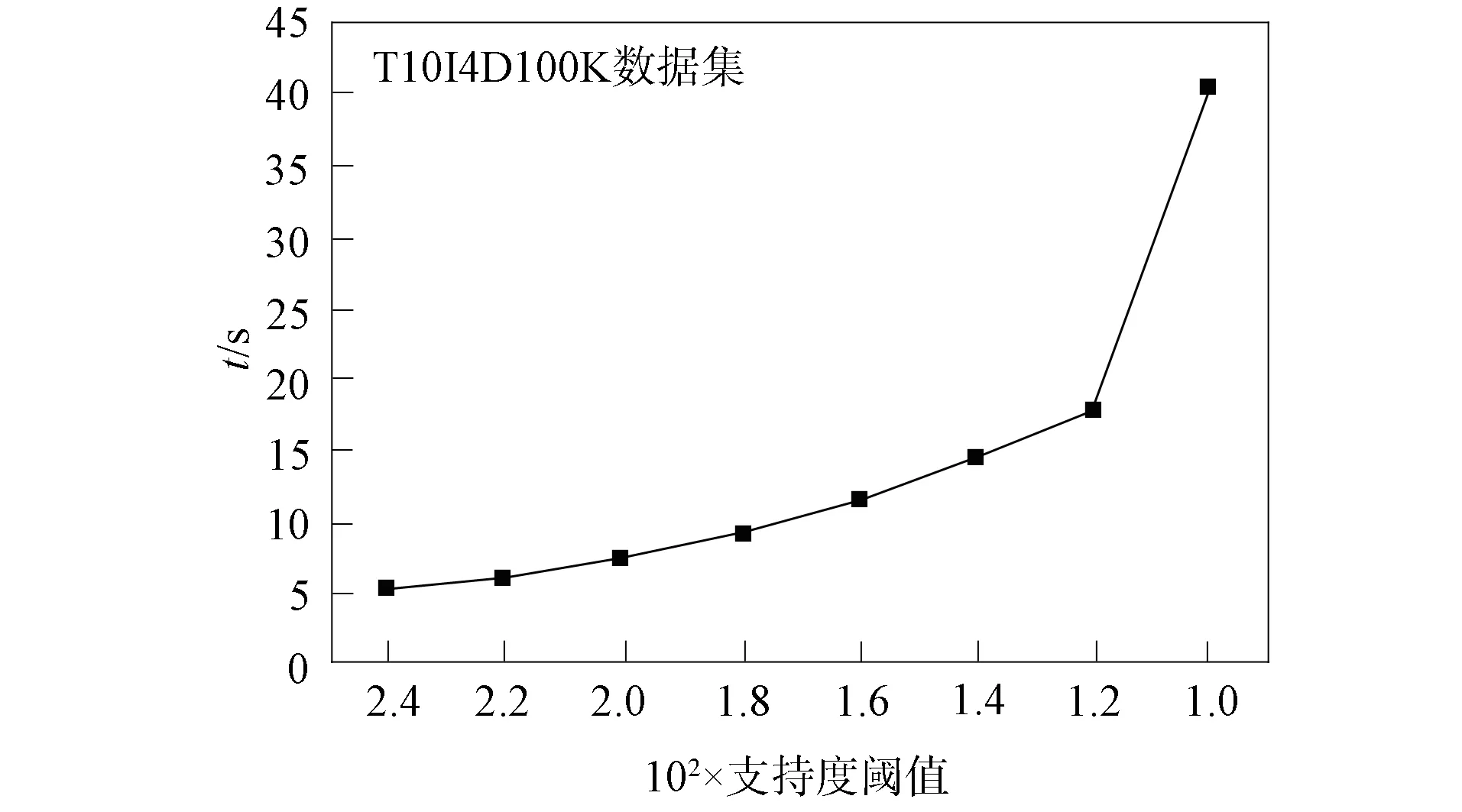
图1 不同支持度下的FBCM算法效率

图2 不同LDB的FBCM算法效率
1) 由图1可见, 支持度为0.012时是为曲线的拐点, 当支持度小于拐点时, 算法的时间消耗快速增长, 其原因是当支持度减小到拐点时, 算法产生的候选集数目会迅速提升, 处理大量的候选集会增加算法的时间消耗;
2) 由图2可见, 当LDB逐渐增大时, 曲线的斜率越来越大, 算法挖掘过程消耗的时间与LDB的增加并不成正比, 而是以类似指数的形式快速增长, 这使算法的挖掘效率越来越低, 其原因是算法每代新频繁项集的确定都要多次扫描LDB, 随着LDB逐渐增大, 频繁的扫描耗时也会快速增加, 且LDB越大, 生成的候选集越多, 对候选集的支持计数和筛选工作耗时也会增加.
3 FBCM算法的优化改进
由上述分析可知, 虽然FBCM算法改进了FUP算法频繁扫描数据库的问题, 但算法运行过程中仍存在两个影响算法效率的问题:
1) 每次迭代时都要频繁扫描原频繁项集库LDB;
2) 每次迭代都会生成过多和无用的候选集.
因此, 为进一步提高关联规则增量挖掘的效率, 本文针对上述两个问题对算法进行优化.
3.1 LDB扫描次数优化
对于FBCM算法, 每次迭代产生候选集都需要扫描LDB, 以此判断该候选集是否进行后续的操作, 所以每次迭代过程中候选集的数量决定对LDB的扫描次数. 因此, 只需降低迭代过程中的候选集数目即可达到算法优化的目的.

图3 取出THI前需扫描LDB候选集构造
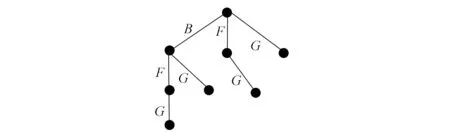
图4 改进后需扫描LDB的候选集构造
与其他项集相比, 数据库中的THI在每次迭代生成候选集中重复出现的次数最多, 并且包含THI的项集在LDB中也占比很大. 因此取出数据集中的THI, 使其不参与正常的迭代过程. 根据Apriori算法给出的迭代剪枝性质[1], 每次迭代时, 候选集生成阶段会忽略这些项目及其超集, 从而将原来迭代过程中要生成的候选集分成两部分, 一部分像FBCM算法在迭代中处理, 而取出部分单独处理, 进而大量减少迭代过程中候选集的数目, 如图3和图4所示. 通过这种每代候选集的改变, 使算法极大降低了对LDB的扫描次数.
取出的THI不参与迭代过程, 对其进行重组生成TI集合, 利用TI中的所有THIT与每代正常迭代生成的频繁项集进行拼接组成新项集, 利用Boole矩阵的逻辑“与”操作对该项集进行支持度计数, 将数目大于支持数阈值的项集加入到LDB∪db中, 通过该步对取出的项集进行处理, 从而不影响整个算法结果的精度.
3.2 候选集剪枝
定理1若一个项X在所有频繁(K-1)项集中出现的次数小于k-1, 则所有包含X的(K-1)项集都不能再与其他项集连接生成频繁K项集.
证明: 关联规则挖掘的剪枝性质为频繁项集的子集都是频繁的. 根据该性质, 如果迭代过程中生成多个频繁K项集, 则每个包含项X的K频繁项集, 都会有(k-1)个包含项X的频繁(K-1)项集作为子集, 且这些子集都是频繁的. 由于频繁K项集的个数可能有多个, 所以项X在所有频繁(K-1)项集中出现的次数至少为k-1, 从而结论成立.
例如: 频繁2项集
L2={{AC},{AB},{BC},{AD},{AF},{CF}},
L2中A出现4次,B出现2次,C出现3次,D出现1次,F出现2次, 则在用L2中项集生成C3候选集前将项集{AD}从L2中删除.
算法优化的目的是减少迭代过程中的候选集数目, 从而减少对LDB的扫描次数. 但后续对取出的THI处理过程使算法整体的处理候选集数目并未减少, 所以为减少处理候选集数目, 本文根据定理1, 在下一代候选集生成前对其进行剪枝, 以避免无用候选集的生成. 减少候选集数目会降低算法在支持计数和筛选工作的耗时, 从而提高算法的挖掘效率.
3.3 算法流程
对FBCM算法优化后, 得到THIMFUP算法的流程如下.
算法1THIMFUP算法.
输入: 原数据库DB, 原频繁项集库LDB, 新增数据库db;
输出:LDB∪db.
步骤1) 矩阵转换: 将数据库DB和db转换为两个事务与项关系的Boole矩阵, 当项在事务中存在时用“1”表示, 否则用“0”表示;
步骤2) 求出db的一频繁项集, 与LDB中的一频繁项集进行交叉得到一候选集合C1, 对C1中集合计数, 得到最新的一频繁项集L1DB∪db, 并将LDB中变成不频繁的项集单独储存在X中, 用于筛选后续项集;
步骤3) 根据得到的新一频繁项集对矩阵进行纵向精简, 删除不是频繁项集项目的列;
步骤4) 按照NP从L1DB∪db取出THI, 对THI重组得到TH和TI, 对TI内的元素THIT进行计数处理, 保留大于支持度阈值的THIT加入到LDB∪db中;
步骤5) 利用X中存储的项集对LDB进行筛选, 并将筛选后不频繁的项集存入X中, 然后对矩阵进行横向精简, 删除矩阵行中“1”的个数小于迭代次数的行;
步骤6) 用L1DB∪db中剩余的项集生成下一代候选集, 并用矩阵对候选集进行支持计数, 将计数大于支持数阈值的项集加入到LDB∪db中, 并将这部分频繁项集称为正常迭代产生的频繁项集, 记为La;
步骤7) 将上一代La中的项集与THIT连接生成新项集, 并利用矩阵对新项集进行支持计数, 将支持计数大于支持数阈值的项集加入到LDB∪db中;
步骤8) 在进行下一次迭代前, 利用定理1对La中项集进行剪枝, 并用剪枝后的La进行下一次迭代;
步骤9) 重复步骤3)~8)直到找到所有的频繁项集, 算法结束.
3.4 复杂度分析
本文算法每次迭代主要分为两步: 1) 更新LDB中原频繁项集; 2) 利用更新后的频繁项集生成新的候选集, 并对新候选集进行筛选. 针对每次迭代, 下面给出算法的时间复杂度分析, 以说明本文算法与FBCM算法在时间复杂度上的关系, 并给出两种算法的空间复杂度.
假设k表示生成的第k代项集, 1 在挖掘第k代频繁项集时, 本文算法的第一步操作时间复杂度最差时,LDB中的m个项集都要统计其在db中的计数以更新项集的支持计数, 对于每个项集采用矩阵的逻辑“与”进行计数, 只需统计结果中“1”的个数, 开销为d, 所以该步算法的开销为md. (1) (2) 本文算法和FBCM算法的空间复杂度为O(Nω), 其中N为数据库事务总数,ω为事务的平均宽度. 算法的空间复杂度主要消耗在数据集转化的Boole矩阵的存储上, 即矩阵的长度×宽度. 实验环境: AMD Ryzen7 3.2 GHz 8核处理器, Windows10 64位操作系统, 内存为16 GB, Eclipse开发平台. 使用JAVA编程语言进行算法实现. 实验采用的数据为从Frequent Itemset Mining Dataset Repository(http://fimi.ua.ac.be/data/)网站下载的关联规则挖掘算法的经典测试数据集. 其中, Mushroom是蘑菇生长记录的真实数据集, 共有事务数8 124个, 事物平均长度为23, 记为A1; T10I4D100K是IBM Almaden Quest研究组生成器合成的数据集, 共有事务数100 000个, 事物平均长度为10, 记为A2. 实验均在同一环境下进行, 为保证实验的客观性与准确性, 实验最终结果均是多次实验取平均值, 并且为了测试本文THIMFUP算法的性能, 实验将FUP算法、 FBCM算法在同等条件下的实验结果与其进行对比. 实验用A1和A2两个数据集对3种算法进行测试, 以A1和A2作为DB, 在A1和A2中分别抽取100条数据作为各自的新增数据集db, 用数据集A1测试时给定NP=5, 用A2测试时, 给定NP=2. 4.2.1 生成频繁项集的准确性对比 根据给定的实验条件, 不断缩小3种算法挖掘时的支持度阈值, 计算3种算法在不同支持度阈值下生成频繁项集的数量, 实验结果如图5和图6所示. 由图5和图6可见, 在两个测试数据集中, 支持度阈值越小, 3种算法挖掘得到的频繁项集个数越多, 相同的支持度阈值下, 本文算法挖掘得到的频繁项集数目与FUP和FBCM算法相同, 表明本文算法保证了对规则挖掘的准确性, 并未牺牲挖掘结果的精度提升挖掘速度. 图5 数据集A1在不同支持度下的频繁项集数 图6 数据集A2在不同支持度下的频繁项集数 4.2.2 支持度变化算法效率对比 根据给定的实验条件, 不断缩小3种算法挖掘时的支持度阈值, 比较3种算法在不同支持度阈值下的挖掘效率, 实验结果如图7和图8所示. 图7和图8是3种算法效率测试的对比, 由于FUP算法在同等条件下耗时过高, 为更好体现实验效果, 实验结果以FBCM算法作为过渡. 根据图7和图8, 在使用两个数据集实验时, 相同的支持度阈值下, 本文算法和FBCM算法时间消耗远低于FUP算法, 并且由图7(A)和图8(A)可见: 在数据集A1上本文算法的效率比FBCM算法提高了50%以上, 最高达60%; 在数据集A2上提高了15%以上, 最高达50%. 随着支持度阈值的不断降低, 3种算法挖掘的时间消耗都在增加, 但本文算法的增加速度明显低于FUP和FBCM算法, 并且支持度阈值越低3种算法的差距越大, 本文算法优势越明显. 图7 数据集A1在不同支持度下的算法效率对比 图8 数据集A2在不同支持度下的算法效率对比 由上述实验结果可见, 在实验条件相同的前提下, 在两个测试数据集上, 本文算法与FUP算法和FBCM算法相比性能更优. 在最佳的NP参数下, 对于支持度阈值较小、 数据集较大且生成较多频繁项集数的情形, 本文算法的挖掘效率提升更明显. 并且数据集A2和A1中的THI分布是有差异的, 根据统计数据, 在A2中THI出现的频数为7 828, 在总事物数中占比极小, 几乎可忽略不计, 而在A1中THI的出现频数占总事物数的99%. 再结合图7(A)和图8(A)所示的效率增长情况可知,THI在数据集中占比越高, 算法在该数据集上的性能越优越, 而实际应用中交易数据形成的数据集, 因为生活必需品的存在, 其中THI的频率通常较高, 因此本文算法应用价值较大. 综上所述, 针对FBCM算法在增量挖掘过程中频繁扫描LDB并生成大量候选集的问题, 本文提出了一种THIMFUP算法, 算法通过提取数据集中THI降低了迭代过程中候选集的数量, 减少了对LDB的扫描次数, 并对取出的THI与迭代中生成的频繁项集进行拼接处理, 保证了算法挖掘的精度, 利用定理1对每代候选集进行剪枝, 减少了算法对候选集计数和筛选的时间消耗. 实验结果表明, 本文算法在保证未损失挖掘结果的情况下, 效率较FBCM算法提高了15%以上, 最高达60%. 这种效率的提升与THI在数据库中的占比有关,THI在数据集中占比越高, 算法的效率提升越明显, 而在实际应用中交易数据集THI的占比通常较高, 从而使算法具有较大的应用价值.




4 实验分析
4.1 实验环境与实验数据
4.2 实验方法与结果




4.3 实验结果分析
猜你喜欢
保健医苑(2022年5期)2022-06-10
数学小灵通(1-2年级)(2021年11期)2021-12-02
成都信息工程大学学报(2021年6期)2021-02-12
中等数学(2020年8期)2020-11-26
计算机应用(2020年5期)2020-06-07
小学生学习指导(低年级)(2020年4期)2020-06-02
天津科技大学学报(2018年4期)2018-08-22
数学小灵通·3-4年级(2017年11期)2017-11-29
天津诗人(2017年2期)2017-03-16
网络安全与数据管理(2010年1期)2010-05-18
