
面向驾驶员的个性化健康导航
2021-05-26 01:14:04牟伦田赵艺远赵鹏飞BaharehNakisaRameshJain尹宝才
北京工业大学学报 2021年5期
牟伦田, 周 朝, 赵艺远, 赵鹏飞, Bahareh Nakisa, Ramesh Jain, 尹宝才
(1.北京工业大学信息学部北京人工智能研究院多媒体与智能软件技术北京市重点实验室, 北京 100124;2.迪肯大学科学工程与建造环境学部信息技术学院, 维多利亚 3216, 澳大利亚;3.加州大学欧文分校未来健康研究所, 尔湾 92697, 美国)
据世界卫生组织(world health organization, WHO)报道[1],道路交通事故每年造成全球约130万人死亡、2 000万~5 000万人受到非致命性伤害. 联合国《2030年可持续发展议程》[2]确定2020年全球道路交通碰撞死亡和伤害数量减半的宏伟目标,这一目标已经无法实现,减少道路交通伤害仍然任重道远. 根据WHO的统计[1],引发交通事故的主要风险因素包括超速、在酒精或其他精神活性物质影响下驾驶、不系安全带和分心驾驶等. 根据美国国家公路交通安全管理局的报告[3],大约94%的交通碰撞事故是由于驾驶员的认知错误、决策错误、操作错误和非操作错误(比如瞌睡)造成的. 因此,在加强道路安全执法的同时,从技术上和源头上对驾驶员的身心健康状态和驾驶行为进行实时监测并采取相应的风险预警和健康调优措施是减少道路交通事故、提升驾驶安全性的迫切需要.
传感技术与物联网技术的发展使得实时获取驾驶员、车辆、道路和环境的多模态大数据变得容易,而机器学习等技术则为数据到知识的转化提供了引擎. 针对驾驶员的健康,国内外研究者已在压力检测、情绪检测和疲劳检测等方面取得一定研究进展[4-6]. 例如,通过采集驾驶员心电图(electrocardiogram,ECG)数据来检测压力,因为在有压力的情况下驾驶会激活自主神经系统(autonomic neural system, ANS)的交感神经部分,从而导致心脏活动的突然增加[7]. 或者通过记录脑电图(electroencephalogram, EEG)来对睡眠进行评分,因为睡眠发作和睡眠阶段是根据脑电图来定义的[8]. 有的研究人员用面部表情识别驾驶员因压力引起的愤怒、厌恶等负面情绪[9]. 也有研究人员提出一种广泛使用的基于车辆数据的驾驶员睡意水平检测方法,使用转向角传感器测量方向盘运动[10].
采集单一的数据对驾驶员压力、情绪和疲劳的检测都有各自的优点和缺点,而使用多模态的混合数据可以有效提高检测准确率. 一些研究表明,基于行为数据和车辆数据相结合的检测方法,其准确性和可靠性明显高于使用单一传感器的方法[11-13]. 针对情绪检测,基于包括生理信号(如EEG)、环境数据(如天气)、视频数据(如捕获的面部表情和手势)以及车辆的运动和位置数据在内的多模态数据进行建模,使用卷积神经网络[14](convolutional neural network, CNN)和长短期记忆网络[15](long short-term memory, LSTM)的混合神经网络对情感状态进行识别. 结果表明,基于深度学习方法的人类情感分类性能表现出色,并且多模态数据模型的性能优于单模态数据模型[16]. 为了有效融合多模态数据,本文引入注意力机制. 注意力机制早期用于机器翻译,可以快速提取稀疏特征以完成自然语言处理任务[17]. 自注意力机制是注意力机制的一种改进方法,它可以减少对外部数据的依赖并捕获较长数据或特征的内部关系[18]. 自注意力机制可用于处理LSTM的隐藏状态以完成分类任务. 近年来,研究人员将CNN- LSTM网络[19]与自注意力机制结合起来. 在场景文本图像和视频脚本的脚本识别问题中,研究者提出一种基于自注意力机制的CNN- LSTM框架来提取局部和全局特征,从而对特征进行动态加权[20].
基于生理和行为数据的驾驶员压力、情绪和疲劳检测方法已取得一定进展,但离应用还有较远的距离. 究其原因,一是单模态模型的检测性能还有待提升,二是接触式检测不便于实际推广应用. 虽然基于多模态数据的检测方法已经受到研究者的关注,但主要聚焦于驾驶员本身的生理数据和行为数据的结合,对车辆[21-22]和驾驶环境[23]等变化数据评估驾驶员健康状态的重要性尚缺少深入研究. 另外研究者对于驾驶员的健康状态还停留在检测阶段,忽略了对驾驶员的健康状态进行持续的引导和优化.
针对上述的问题和挑战,本文的主要工作如下:
1) 提出面向驾驶员的个性化健康导航架构. 具体而言,首先基于驾驶员的日志构建个性化健康模型,然后结合实时采集的多模态数据(驾驶员、车辆和环境等)对驾驶员的当前健康状态做出全面评估,从而针对驾驶员预设目标健康状态,给出可操作的行为建议.
2) 提出基于注意力的CNN- LSTM网络的多模态融合模型,以构建一个精确的驾驶员健康检测系统. 这种多模态融合模型不仅可以自动提取特征,还可以权衡来自不同模态的特征,以提高驾驶员健康等级分类的性能.
3) 面向压力、情绪和疲劳检测分别构建具体的多模态融合模型. 对于驾驶员压力和情绪检测,结合了眼部、车辆和环境的多模态数据,相比于生理数据可减少对驾驶员的干扰.
1 驾驶员个性化健康导航架构与方法
1.1 总体架构
受启发于Nag等[24-25]提出的个性化健康导航(personal health navigation, PHN)研究范式,本文提出面向驾驶员的个性化健康导航(personal health navigation for drivers, PHN- D)架构,如图1所示. 首先,根据驾驶员历史日志,建立驾驶员个性化健康模型与个性化健康状态空间. 然后,根据对驾驶员、车辆和道路环境实时监测得到的各种数据进行多模态分析,并结合个性化健康模型进行健康状态估计,获得驾驶员当前健康状态. 最后,对比当前健康状态与目标健康状态,并依据一定的优化策略给驾驶员提供可执行的健康状态优化行为建议. 针对架构中最关键的健康状态估计环节,本文分别提出驾驶员压力、情绪和疲劳检测方法,以获得对驾驶员健康状态的综合表征. 下文将详细介绍各检测方法,并给出实验验证.
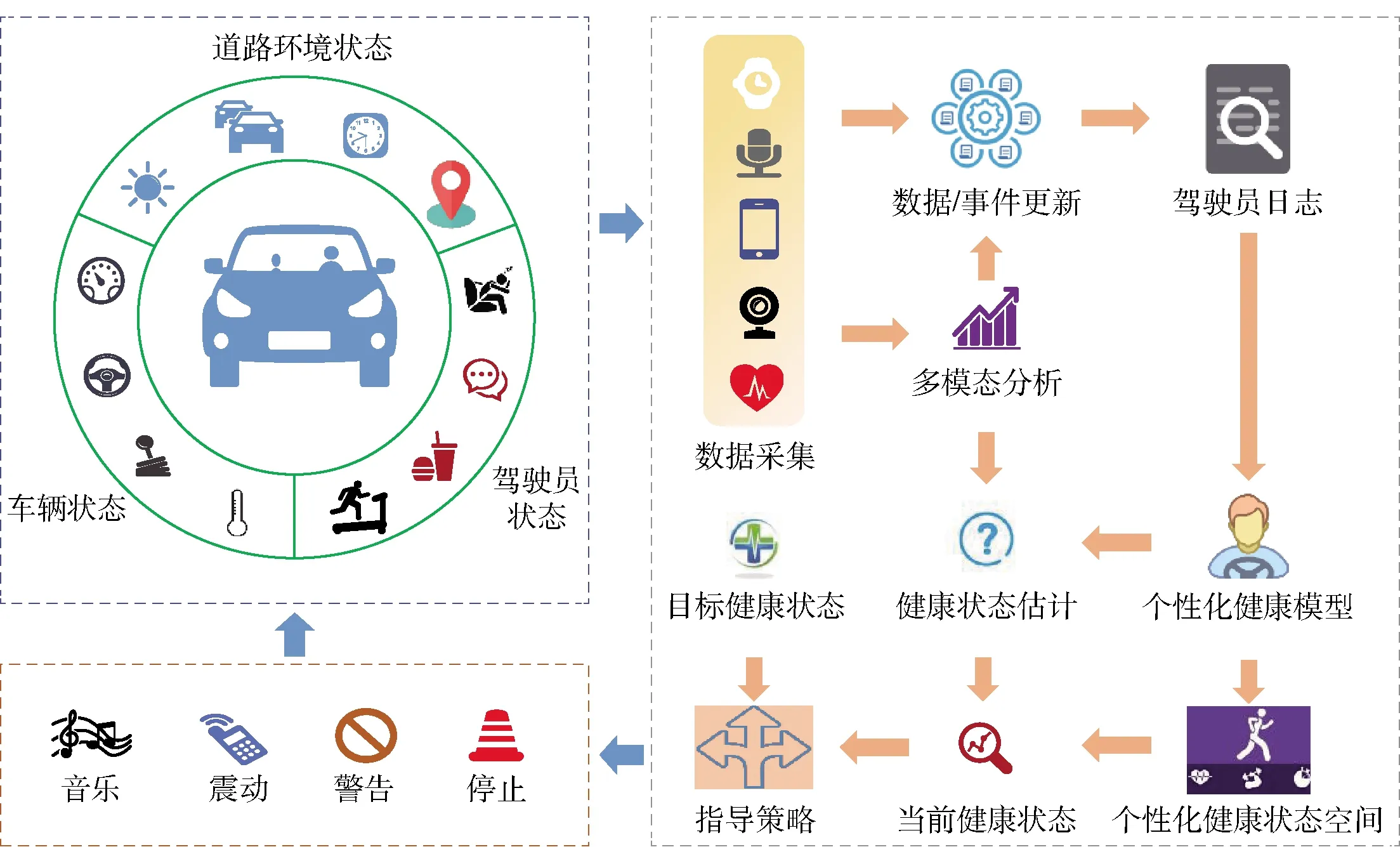
图1 驾驶员个性化健康导航架构Fig.1 Architecture of personalized health navigation for drivers
1.2 压力检测方法
针对压力检测,提出基于注意力的一维(1D)CNN- LSTM网络的多模态融合模型,如图2所示. 提出的模型通过融合眼部、车辆和环境数据来提取与压力相关的特征,以对驾驶员的压力水平进行分类. 每位模拟驾驶员的驾驶数据均以随机的顺序在5个驾驶场景(城市1、城市2、高速公路、CBD1和CBD2)中采集. 每个驾驶场景都包含多个不同的压力源,如表1所示,以使驾驶员产生不同程度的压力. 数据标签是通过口头问答获得. 每种场景下,每2 min要求驾驶员对他们的平均压力水平提供简短回答. 即要求他们给出自己在0~3.0的压力水平(0表示无压力,3.0为高压力). 这些数字随后被映射到3个不同的压力级别(0.1~1.0为低,1.1~2.0为中,2.1~3.0为高). 所提出的驾驶员压力检测模型包括4个步骤:预处理、特征提取、特征融合和分类,分述如下.
首先,使用滑动窗口方法将每个模态的每个特征划分为具有固定窗口大小和重叠度的时间窗口. 新的训练数据集由生成的时间窗口组成,每个时间窗口的标签与原始数据集相同. 为了减少驾驶员之间数据的个体差异,将所有数据特征(X)进行标准化和标准偏差.
(1)
式中:μ和σ分别为每个参与者所有特征的平均值
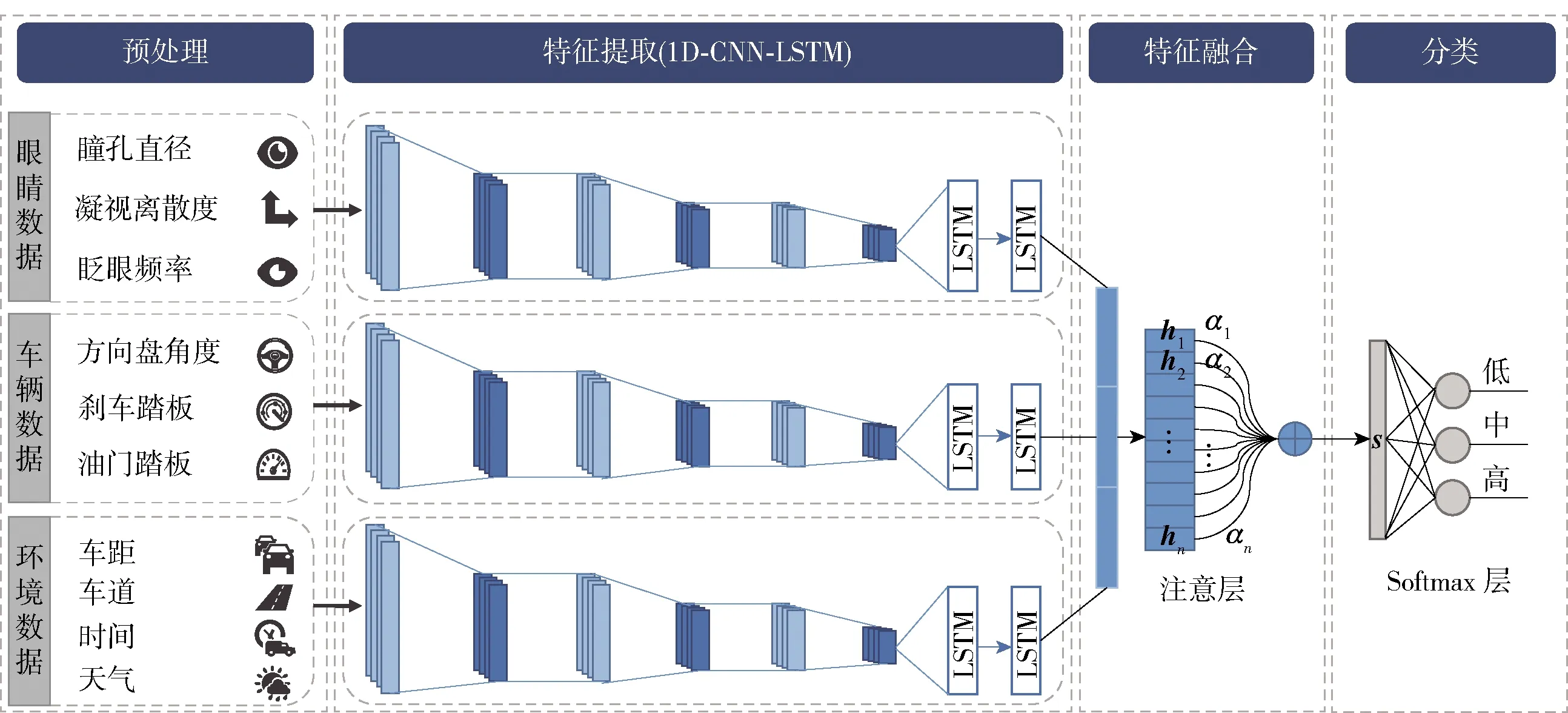
图2 面向驾驶员压力检测的多模态融合模型Fig.2 Multimodal fusion model for driver stress detection

表1 摇不同驾驶场景中的不同压力源 Table 1 Different stressors in different driving scenarios
在特征提取步骤中,将每种模态的训练数据集输入到1D- CNN- LSTM框架以提取特征. 具体而言,训练数据集的分段时间窗口数据首先被送入1D- CNN来自动学习特征. 由于时间窗口是时间序列,因此使用1D卷积层. 该特征提取框架由3个1D卷积层、3个最大池化层和2层LSTM组成. 表2列出了详细的参数设置. 通过反复实验选择具有最佳检测精度的参数组合和模型框架. 卷积层使用滑动滤波器提取有效特征. 卷积层的激活函数是指数线性单元(exponential linear unit,ELU),可以加快收敛速度并提高模型的鲁棒性. 每一层卷积后都有一个最大池化层. 为了降低数据复杂度,最大池化层将数据量减少到原始的一半. 为了避免过度拟合,在池化层之后采用了退化(dropout)层. LSTM网络通过门控机制处理时间序列,该门控机制包括遗忘门f、输入门i和输出门o,以及存储单元c. 在每个时间步骤t,LSTM首先

表2 压力检测的1D- CNN- LSTM模型参数
计算门激活it(2)和ft(3),将存储单元从ct-1更新到ct(4). 然后计算输出门激活ot(5),最后输出隐藏表示ht(6). LSTM的输入是输入观察值xt和来自前一个时间步的隐藏表示ht-1,LSTM的更新操作公式为
it=σg(Wi*xt+Ui*ht-1+Vi∘ct-1+bi)
(2)
ft=σg(Wf*xt+Uf*ht-1+Vf∘ct-1+bf)
(3)
ct=ft∘ct-1+it∘σc(Wc*xt+Uc*ht-1+bc)
(4)
ot=σg(Wo*xt+Uo*ht-1+Vo∘ct-1+bo)
(5)
ht=ot∘σh(ct)
(6)
式中:Wi、Wf、Wo和Wc分别为输入门、遗忘门、输出门和存储单元的权重矩阵;Vi、Vf和Vo分别为窥视孔连接的对角线权重矩阵;此外,Uw为隐藏表示的连接权重矩阵(其中w∈{i,f,o,c});bw分别为输入、遗忘、输出和存储单元的偏置向量(其中w∈{i,f,o,c});σg(·) 为逻辑sigmoid函数;σc(·)和σh(·)为tanh激活函数;“*”为矩阵乘法;“∘”为元素乘法.
在特征融合步骤中,将从眼部数据、车辆数据和环境数据生成的n个隐藏表示ht串接成隐藏表示族H
H=(h1,h2,…,hn)
(7)
由于不同的隐藏表示对压力检测的影响程度不同,因此引入自注意力机制来权衡所有隐藏表示. 隐藏表示ht通过注意力层计算出向量表示s,其公式为
ut=tanh (Wht+b)
(8)
(9)
(10)
式中:W为权重矩阵;b为偏置向量,u为一个可训练的参数向量,用于表示上下文信息. 首先,将隐藏表示ht送入全连接层,激活函数为tanh,得到ut作为ht的向量表示.ut的转置乘以可训练的参数向量u,得到注意力的对齐系数. 然后,利用softmax函数对对齐系数进行归一化处理,得到注意力向量αt. 最后,利用注意力向量αt计算出ht的加权和,得到向量表示s.
在分类步骤中,Softmax层将向量表示s转换成条件概率分布. 该模型可以通过反向传播的方式进行端到端训练,其中目标函数(损失函数)为交叉熵损失(L). 设y和分别为目标分布和预测分布,训练的目标是使y和之间的交叉熵误差最小化,公式为
=softmax(Wss+bs)
(11)
(12)
式中:Ws和bs分别为Softmax层的权重矩阵和偏置向量;i为样本索引;j为类别索引. 压力分类器包含低、中、高3种压力级别.
1.3 情绪检测方法
将基于注意力的CNN- LSTM网络的多模态融合模型应用在情绪检测中,提出面向驾驶员情绪检测的多模态融合模型,如图3所示. 此模型在总体结构上沿用压力检测模型框架.
首先,模型共享压力检测同一数据集,但对数据标签进行了针对情绪的标注. 为了描述驾驶员复杂的情感,采用基于认知心理学的愉悦度- 兴奋度- 支配度(valence-arousal-dominance,VAD)三维情感模型. 其中,愉悦度(valence)表示情感从消极到积极的愉悦程度;兴奋度(arousal)表示情感从平静到激动的兴奋程度;支配度(dominance)表示从被支配到处于高度支配的控制程度[26]. 情感维度标记的方法采用自我评估人体模型表[27](self-assessment manikins,SAM),如图4所示,愉悦度等级从左边皱眉的图形依次过渡到最右边开心的图形,表示从消极到积极的愉悦程度(1~9). 兴奋度等级从左边闭眼平静的图形依次变化到最右边睁眼激动的图形表示从平静到激动的兴奋程度(1~9). 支配度的等级从左边到右边图形依次变大,图片越大表示支配程度越高(1~9). 图中每一维度的人体模型只有5个,任意2个人体模型图之间的等级为介于2种等级之间更精细的等级.
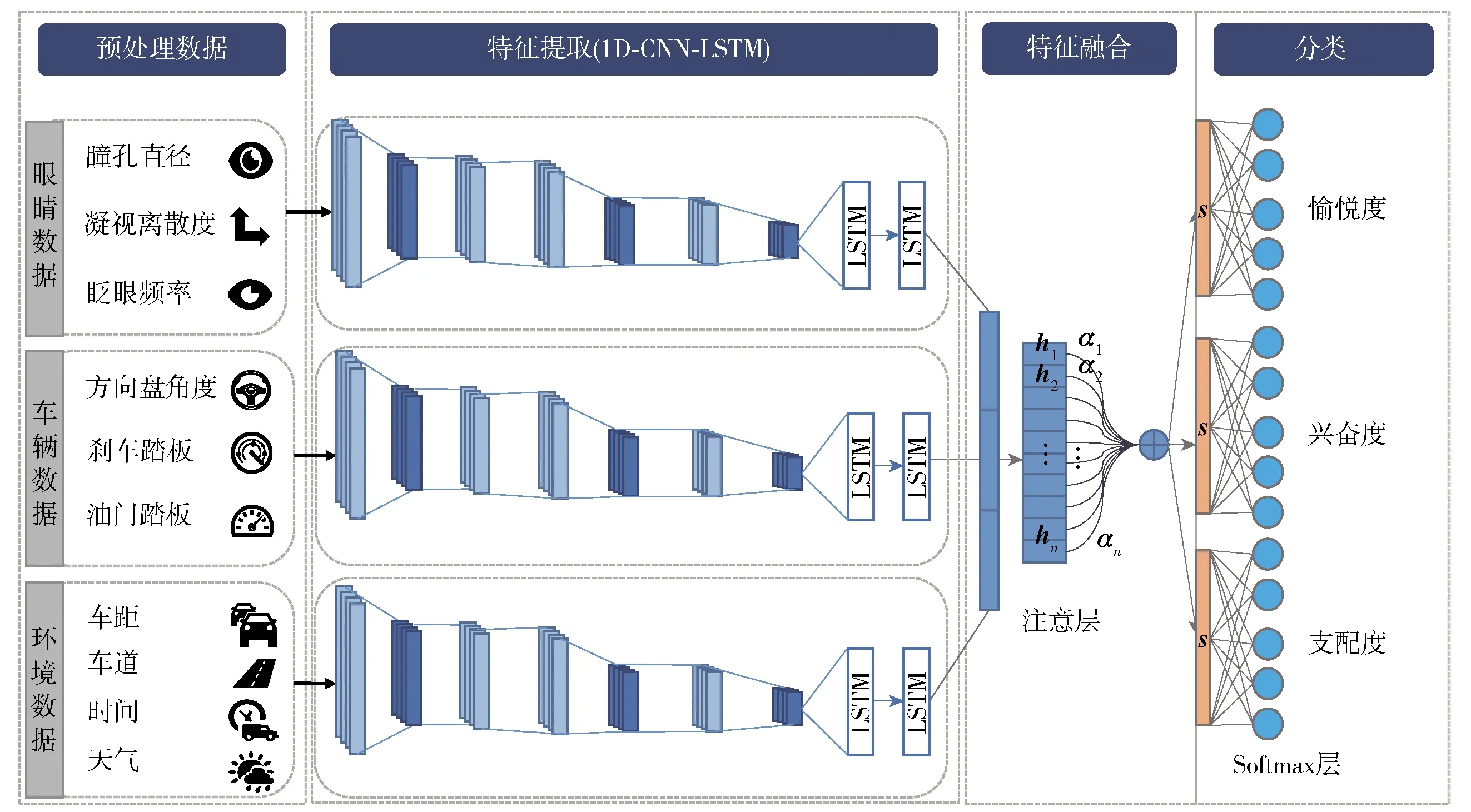
图3 面向驾驶员情绪检测的多模态融合模型Fig.3 Multimodal fusion model for driver’s emotion detection
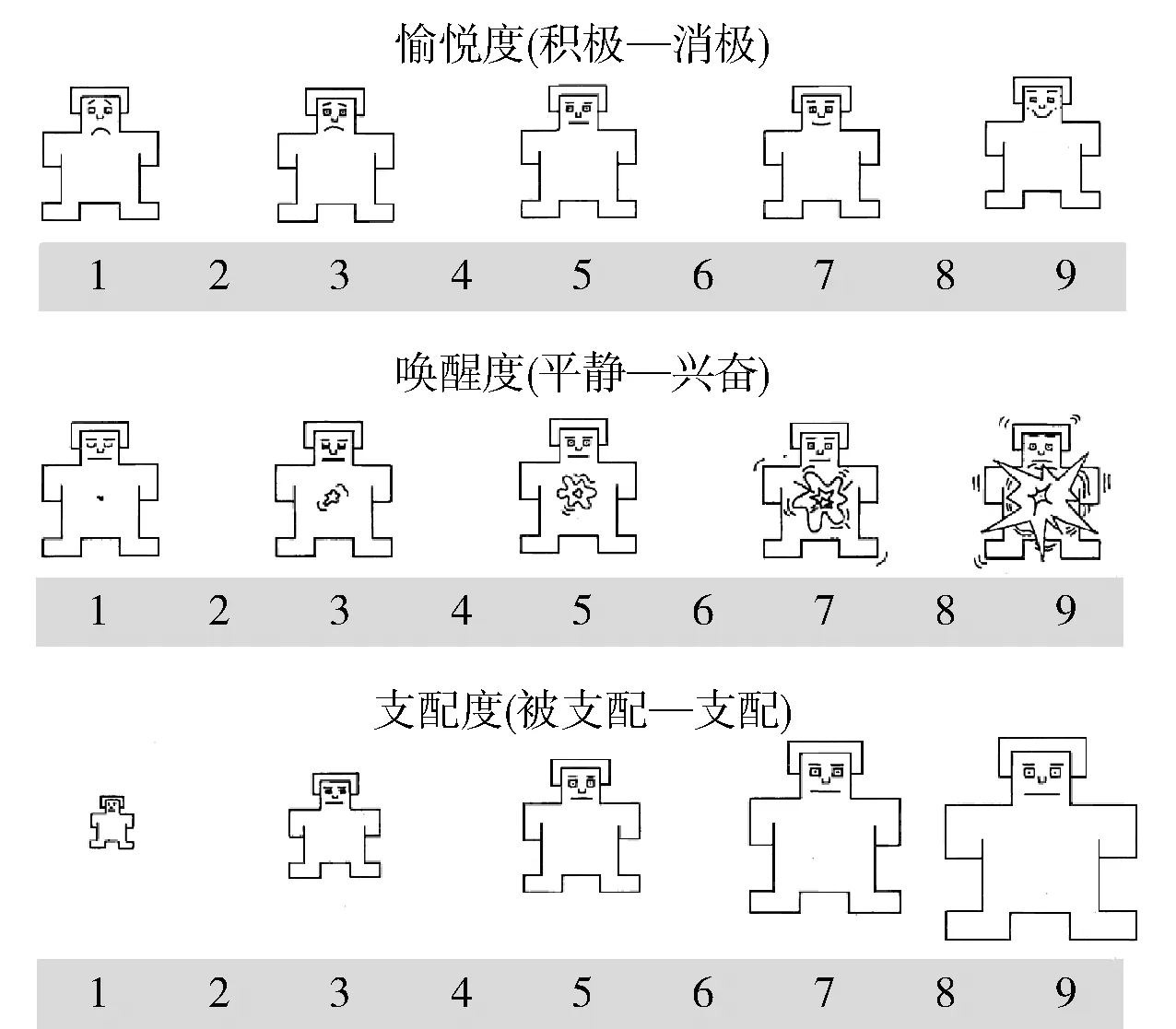
图4 自我评估人体模型描述维度情感的等级Fig.4 SAM used to describe levels of dimensional emotion
维度情感的标注具体过程开始于驾驶前. 首先在开始实验前,要求参与实验者放松几分钟以便记录其生理基线. 然后,参与者被要求驾驶车辆通过6种驾驶场景,第1个驾驶场景是一条简单的道路,参与者驾驶车辆通过这条道路去熟悉车辆模拟器的驾驶操作和实验流程. 经过一些实验操作的训练后,参与者要在其余5个场景(城市1、城市2、高速公路、CBD1和CBD2)中进行实验. 在参与者驾驶的过程中传感器会持续采集眼部、车辆和环境等模态数据,而且在每个场景驾驶结束后由参与者在自我情绪评估表上选上自己的各维度情感等级. 由于一些标签的缺失以及考虑到各标签的均衡性问题,作者把每个维度由原来的9个等级聚合为5个等级(1~2为等级一,3~4为等级二,5为等级三,6~7为等级四,8~9为等级五).
在特征提取步骤中,对1D CNN模型的结构进行了微调,如表3所示,将中间卷积层的卷积核使用多个较小的卷积核级联代替,在保持感受视野不变的同时,减小了计算的参数量,从而缩短了模型训练时间,此外,这种改变增加非线性的变换操作,使模型性能进一步提升.
在分类步骤中,由于要实现对目标情感的多分类任务,因此,引入3个Softmax层同时对3个维度的情感(愉悦度、兴奋度和支配度)进行识别检测. 最后,模型通过最小化3个交叉熵损失函数的损失值总和进行反向传播,对模型网络权重更新,从而实现对模型的优化,以实现对驾驶员维度情感的准确识别.
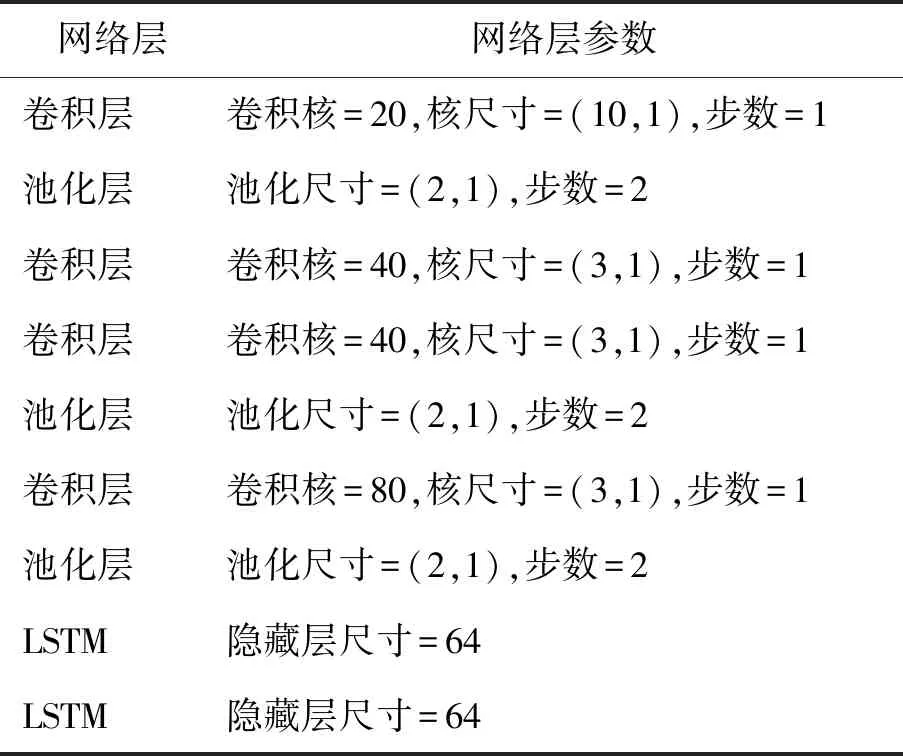
表3 情绪检测的1D- CNN- LSTM模型参数
1.4 疲劳检测方法
将基于注意力的CNN- LSTM网络的多模态融合模型应用在疲劳检测中,提出面向驾驶员疲劳检测的多模态融合模型,如图5所示. 此模型在总体结构上沿用压力检测模型框架.
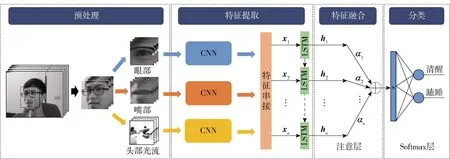
图5 面向驾驶员疲劳检测的多模态融合模型Fig.5 Multimodal fusion model for driver’s fatigue detection
在预处理步骤中,使用预训练的人脸检测器来提取面部图像,该检测器是对定向梯度的标准直方图和线性支持向量机(support vector machines, SVM)的改进[28]. 然后,利用面部标志点定位和提取眼部、嘴部图像[29]. 最后,使用改进的全变差(total variation, TV)正则化和鲁棒的L1范数(TV-L1)来实时提取头部图像相邻帧的光流图像[30].
在特征提取步骤中,由于ResNet[31]的残差网络可以解决或缓解深度神经网络训练中的梯度消失问题,并且考虑到模型的复杂度对计算资源的要求,因此采用ResNet18作为图像编码器. 残差网络的结构如图6所示,残差网络块提供了快捷连接,它将原始输入信号x的身份映射添加到堆叠层的输出. 残差映射函数为
F(x)∶=H(x)+x
(13)
式中:H(x)为期望的底层映射;F(x)为堆叠的非线性层. 原始映射重新定义为F(x)+x. 残差网络的结构既不会增加额外的参数,也不会增加计算的复杂性,并能加快网络训练速度. 在图像处理中,ResNet能很好地提取图像特征,是一种成功的图像识别架构. 由于在同一模型下训练的3种模态会相互干扰模型参数,因此采用独立的ResNet18模型对眼部、嘴部和头部光流的图像进行特征提取. 由于ResNet18的全局平均池化特征可以很好地保持图像的空间结构,因此作者提取各模态图像序列中每一帧的全局平均池化特征. 然后,利用2层LSTM模型在时间维度上对驾驶员的状态进行分析,其隐藏层维度为128. 最后,隐藏状态族H经过注意力层进行特征融合,并通过Softmax层判断驾驶员状态是清醒或疲劳. 模型的损失通过使用二分类交叉熵损失函数计算.
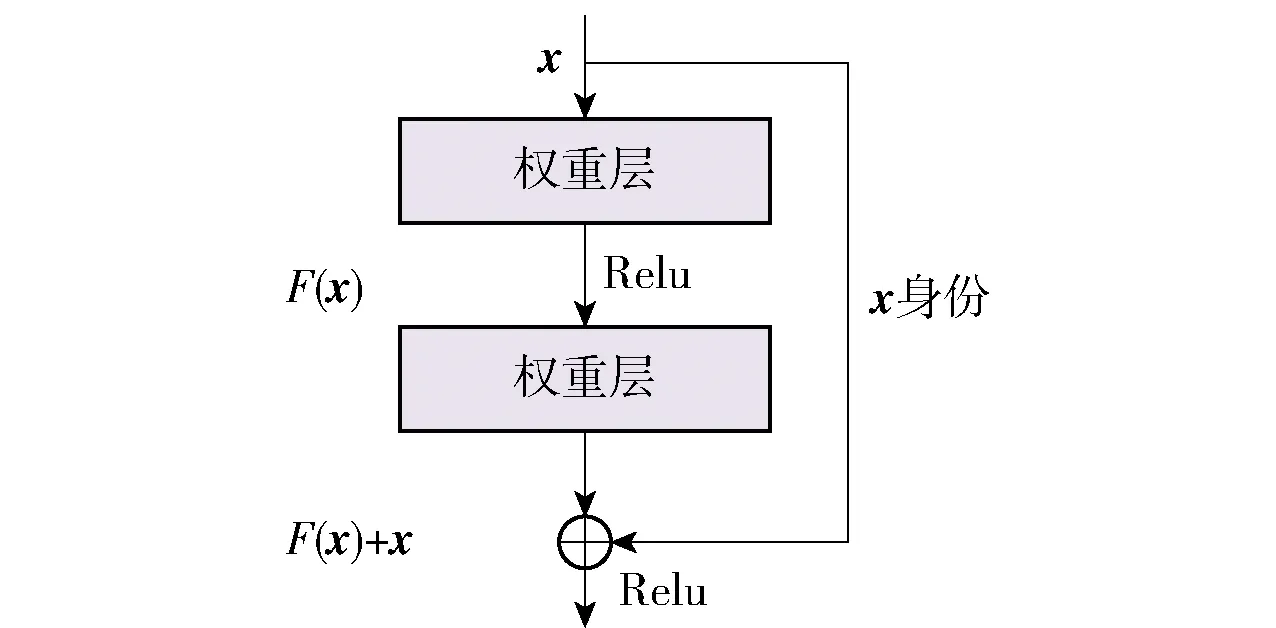
图6 残差网络的架构Fig.6 Structure of the residual network
2 实验结果
2.1 数据集
针对驾驶员压力和情绪检测实验所需数据集,在澳大利亚昆士兰科技大学的CARRS- Q高级驾驶模拟器[32]上获取眼部数据、车辆数据和环境数据并实时监控驾驶员的压力和情绪状态,每个模态包含的特征如表4所示. 如图7所示,该模拟器包括180°的前视屏幕、后视镜图像、真实的驾驶舱、可模拟驾驶环境的音频系统和一个六自由度的运动平台,以及SCANeRTM系统[33]和FaceLABTM远程视频眼动仪[34]. 在实验中,22位参与者参与了数据收集,年龄21~40岁(男性55%).

图7 CARRS- Q高级驾驶模拟器Fig.7 CARRS- Q advanced driving simulator
针对驾驶员疲劳检测实验,利用公开的视频数据集(NTHU- DDD)检测驾驶员的疲劳状态[35]. 该数据集包含22名参与者和380个视频. 受试者坐在椅子上,用模拟驱动轮和踏板玩简单的驾驶游戏时其数据被记录下来. 每个受试者记录的序列可以被视为2个分支:清醒和疲劳. 视频数据集是在5种不同的情况下收集的(白天戴眼镜、白天不戴眼镜和太阳镜、夜间不戴眼镜、夜间戴眼镜),每种情况都包括正常驾驶、缓慢眨眼、打哈欠、点头和说笑,如图8所示.

图8 NTHU- DDD数据集的一些样本帧Fig.8 Some sample frames of NTHU- DDD dataset

表4 不同模态下的特征数据
2.2 压力检测实验结果
对于数据集的划分,压力检测实验采用10折交叉验证方法来验证模型的性能. 具体来说,将数据集随机打乱并分成10个等份,然后将其中1份用作测试集,将其余部分依次用作训练集. 最后,实验结果是10次压力检测结果的平均准确率,下文简称为平均准确率.
表5展示了在单模态数据和多模态数据下不同模型的压力检测性能. 这3个多模态融合模型依次是基于LSTM的多模态融合模型、基于CNN- LSTM的多模态融合模型和基于注意力的CNN- LSTM网络的多模态融合模型(CNN- LSTM- Attention),显然,3个多模态融合模型的准确率都优于单模态模型,这意味着每种模态的信息可以通过融合模型互补. 其中,眼部数据和车辆数据对压力水平检测结果的影响较大,而环境数据的影响较小. 由于不同模态的数据差异很大,因此利用注意力机制来处理具有不同影响程度的特征. 最终,基于注意力的CNN- LSTM网络的多模态融合模型的平均准确率达到95.5%,比传统的CNN- LSTM模型高了4.7%,表明其在驾驶员压力检测中具有优越性能.
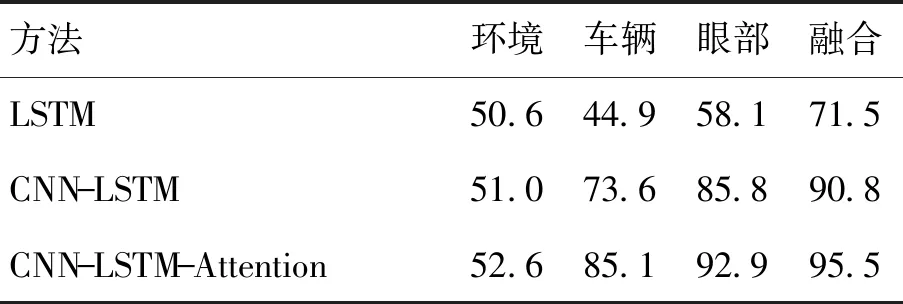
表5 不同模型在不同模态下的驾驶员压力检测的平均准确率
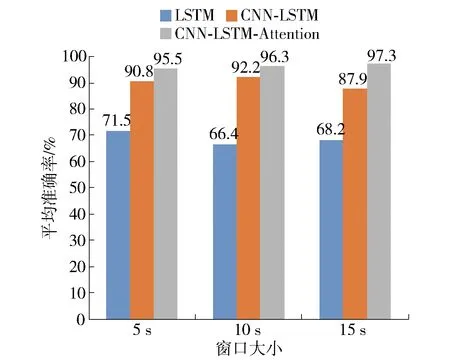
图9 融合模型在不同窗口大小下的平均准确率Fig.9 Average accuracy of the fusion model in different window sizes
在不同窗口大小下,基于注意力的CNN- LSTM网络的多模态融合模型与其他模型的比较结果如图9所示. 结果表明,提出的多模态融合模型在不同的窗口大小下都具有最优的性能. 随着窗口大小的增加,提出的多模态融合模型的平均准确率在10 s和15 s窗口下分别提高了0.8%和1.8%. LSTM模型的平均准确率不会随着窗口大小的增加而提高. 尽管CNN- LSTM模型在10 s窗口中获得良好的结果,但其平均准确率仍低于提出的多模态融合模型. 特别地,提出的多模态融合模型在15 s窗口中的平均准确率达到97.3%,与LSTM模型和CNN- LSTM模型相比,分别提高了29.1%和9.4%. 尽管大的窗口可以提高模型的平均准确率,但提升的幅度并不明显,并且5 s窗口下提出的多模态融合模型的平均准确率仍高于其他模型. 本研究的目标是建立一个自动的驾驶员压力检测系统,以便在实际情况下实时应用,因此选择了较小的窗口大小.
2.3 情绪检测实验结果
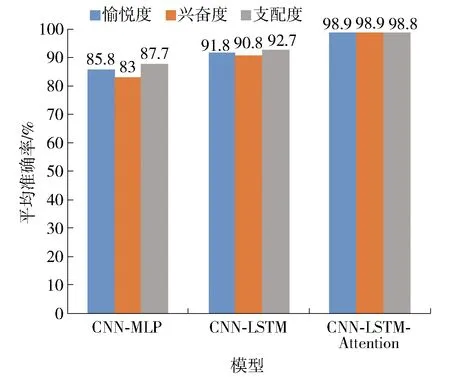
图10 各情感维度在不同模型下的平均准确率Fig.10 Average accuracy of each emotional dimension in different models
对于数据集的划分和平均准确率的计算标准,情绪检测实验采用与压力检测的相同方法. 如图10所示,实验结果为愉悦度、兴奋度、支配度3个情感维度在不同模型结构下的平均准确率. 其中CNN- MLP是基于卷积神经网络和多层感知机的多模态融合模型. 从图中可以清晰地看出在3个模型下各情感维度的平均准确率呈现一种逐渐上升的趋势,其中在提出的多模态融合模型下的各情感维度的平均准确率最高. 通过3个模型的对比可以得知LSTM网络在处理序列数据上的有效性,以及在LSTM层基础上引入注意力层使得模型性能有了很大提升. 这是因为引入LSTM网络层是考虑了各个特征数据序列之间的时间信息,加入注意力层能够有效地权衡不同模态的特征进而突出有效特征信息的作用.
在不同模态数据融合下,情感的各维度平均准确率性能指标如表6所示. 在仅使用环境或车辆单一模态数据时可以看出整体的平均准确率较低,而使用眼部模态数据时有较高的平均准确率,这表明眼部数据对于情感识别有着很大的相关性. 在使用任意2种模态数据相结合时可以看出各个情感维度的性能都有较大的提升. 以环境模态数据为例,虽然在仅使用环境的数据时测试出整体的平均准确率很低,但在与不同模态数据结合时都使各维度的平均准确率在原来单一模态数据基础上有所提升. 由此可得出虽然使用单一模态时模型识别的平均准确率很低,但可能在与其他模态数据结合时发挥重要作用,因为它可能对与其他模态数据存在着一定程度的影响关系,比如环境的变化可能会引起司机驾驶车辆行为或者眼部的变化. 在环境、车辆和眼部数据模态相融合时,在兴奋度这一维度的平均准确率略低于环境和眼部数据融合时的平均准确率,但总体上3种模态相融合时的平均准确率较高. 综上所述,多模态数据融合对于模型情感识别的性能有着很重要的影响,同时也证明了多模态数据融合对于提升驾驶员情绪检测性能是一种有效的方法.
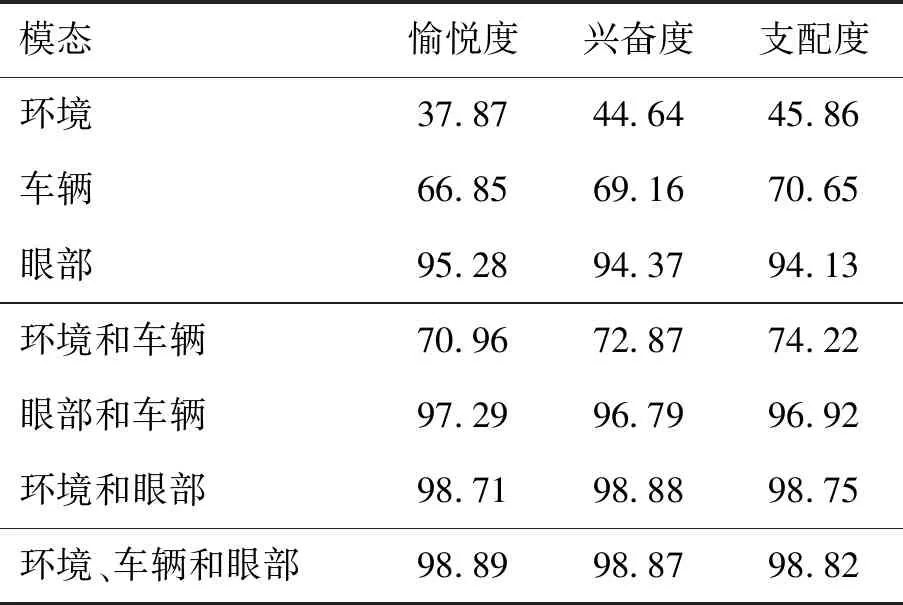
表6 不同模态下的各情感维度的平均准确率
2.4 疲劳检测实验结果
在驾驶员疲劳检测方法中,数据集的视频被分割成5 s的视频段. 驾驶员眼部、嘴部和头部图像序列中视频段的帧数(T)是不同的,对于眼部图像序列T=75,对于嘴部图像序列和头部生成的光流图像序列T=25. 为了公平地比较模型的性能,选择每个数据集中70%的视频片段作为训练集,10%作为验证集,20%作为测试集. 每个数据集的所有视频片段被随机分割5次,并报告5次疲劳检测结果的平均F1值和平均准确率. 遵循疲劳检测的常规评估指标[35],不仅将平均准确率用作评估指标,而且还使用了F1评估指标,因为它可以对不平衡的样本进行合理的评估.F1由精度P和召回率R计算得出,即
(14)
为了验证基于注意力的CNN- LSTM网络的多模态融合模型在疲劳检测方面的有效性,在不同模态下对融合模型的性能进行了对比实验,如表7所示. 从实验结果可以看出,单模态的平均F1值和平均准确率低于多模态组合. 其中眼部和嘴部的组合与单眼部模态相比平均准确率提高了4.15%,眼部和头部光流的组合与单眼部模态相比平均准确率提高了3.35%. 嘴部和头部光流的平均F1值和平均准确率低于其他2个组合,结果表明眼部在3种模态中起着关键的作用. 最终,将眼部、嘴部和头部光流数据结合起来,提出的多模态融合模型的平均F1值和平均准确率分别达到94.66%和93.77%,相比单模态眼部的平均F1值和平均准确率分别提高了3.88%和4.57%. 结果表明,基于注意力的CNN- LSTM网络的多模态融合模型在驾驶员疲劳检测方面具有优越的性能.
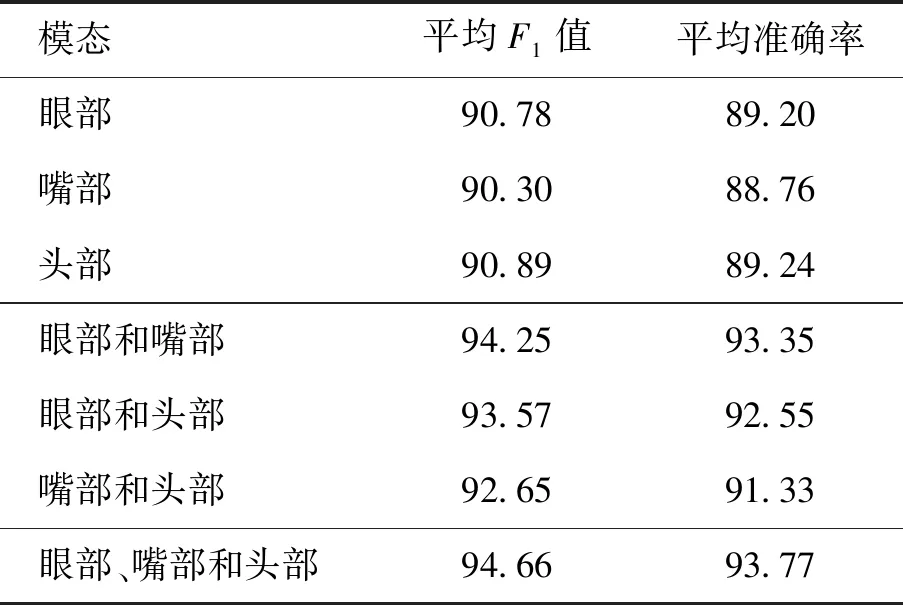
表7 融合模型在不同模态下的疲劳检测性能
3 结论
1) 本文提出了一种面向驾驶员的个性化健康导航研究架构与方法. 针对传统研究只监测驾驶员驾驶风险的做法,提出基于控制论基本原理的个性化健康导航方法,构建从驾驶员个性化健康建模到健康状态估计(多模态分析)再到健康状态优化的闭环控制系统,从而使驾驶员健康得到持续优化、驾驶安全得到持续提升.
2) 针对驾驶员压力、情绪和疲劳检测,提出了一种基于注意力的CNN- LSTM网络的多模态融合模型. 模型具有无接触、高精度和实时性的特点. 在高级驾驶模拟器采集的数据集和公开数据集上,进行了大量的实验来验证模型的性能. 实验结果表明,所提出的多模态融合模型可以有效地补充和权衡来自眼部、车辆和环境数据的信息,并且可以有效地融合来自眼部、嘴部和头部光流的面部信息.
3) 下一步的工作将按照提出的个性化健康导航架构完成系统的开发,并对健康状态估计算法进行改进,利用无监督学习[36]在未标注的数据上学习与驾驶员健康状态相关的特征,从而解决标注数据费力、烦琐、不准确的问题. 同时,也希望能够争取到企业的合作,获得真实的数据集,以便更加有效地开展研究和推广应用.
猜你喜欢
汽车实用技术(2022年14期)2022-07-30 06:13:42
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
汽车实用技术(2022年4期)2022-03-07 06:07:20
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
公民与法治(2016年4期)2016-05-17 04:09:26
