
一种面向视频传输应用的联合上下采样超分辨率框架
2021-05-26 01:13:58刘鹏宇王聪聪贾克斌
北京工业大学学报 2021年5期
刘鹏宇, 王聪聪, 贾克斌
(1.北京工业大学信息学部, 北京 100124; 2.先进信息网络北京实验室, 北京 100124;3.北京工业大学计算智能与智能系统北京市重点实验室, 北京 100124)
高质量、低码率是视频传输中永恒不变的追求,如何在保证视频质量的前提下降低带宽成本是整个视频传输应用中重要的一环. 然而,目前用于视频压缩传输的主流编码技术,从MPEG1[1]到H.264[2],再到H.265[3],每隔10年时间,视频的压缩率仅能提升1倍左右,平均每年压缩率提升只有不到7%,远远低于视频数据量的增长率.
为了提升视频压缩率,通常在发送端对高分辨率视频进行降分辨率的下采样操作,然后在信道中传输低分辨率的视频,最后在接收端应用图像超分辨率技术还原出高分辨率的视频[4],这种方法可以有效缓解视频传输过程中的带宽压力. 然而,在发送端进行下采样时,由于丢失了大量原始高分辨率视频中的高频信息,使得在接收端应用图像超分辨率技术进行还原时面临高度的病态性问题,正是由于在映射空间中存在不止一组对应的高分辨率图像和低分辨率图像,这无疑给重建原始高分辨率视频带来极大的困难.
为了缓解视频传输应用中使用图像超分辨率技术带来的高度病态性问题,本文提出一种联合上下采样的超分辨率框架. 该框架的优势是通过设计卷积神经网络模拟图像的降采样过程,使得原始高分辨率图像的信息能够“隐匿”在降采样后的图像中,然后再与图像超分辨率模型进行端到端的训练. 实验表明,这种通过引入原始高分辨率图像信息、上下采样过程联动的方式可以有效缓解超分辨率重建中的病态性问题,大幅提高重建图像质量.
1 超分辨率技术
超分辨率技术是一种将低分辨率图像重建为高分辨率图像的技术[5]. 提升图像的分辨率不仅能带来良好的视觉体验,还能提高后续视觉任务的检测效果,是一项重要的图像处理技术,也是计算机视觉领域重要的课题之一.
早期的研究使用插值的方法来解决超分辨率问题[6],但是这些方法在预测细节、真实感和纹理方面存在局限性. 之后,有研究使用基于统计学习的方法来解决超分辨率问题[7],其原理与基于深度学习的方法类似,大都是研究低分辨率图像和高分辨率图像之间的映射关系.
近些年来,深度学习技术凭借其强大的特征提取能力在各项图像任务中取得非凡的成果[8],包括图像识别[9-10]、目标检测[11-12]、图像处理[13-14]等,其中还包括图像超分辨率. 利用深度学习处理超分辨率任务的本质是通过建立卷积神经网络模型来拟合低分辨率图像与高分辨率图像间的映射关系. 具体来说,主要有以下4种框架:
1) 前置上采样超分辨率
这种框架首先使用传统方法(如双三次插值)对原始低分辨率图像进行上采样得到“粗高分辨率图像”,然后通过卷积神经网络去拟合“粗高分辨率图像”与真实高分辨率图像之间的映射关系[15-18]. 该方法只需要对“粗高分辨率图像”进行精细化处理,大大降低了模型的拟合难度. 但是,这种方法会放大原始图像中的噪声和模糊,同时由于拟合发生在高维空间,计算复杂度相对较高.
2) 后置上采样超分辨率
与前置上采样超分辨率框架相对的一种框架是后置上采用超分辨率[19-22],该方法使用卷积神经网络以不改变尺寸的方式提取原始图像特征,最后使用一个可学习的上采样层对模型进行端到端的训练. 这种框架的计算主要在低维空间进行,相较于前置上采样框架可大幅降低计算复杂度,但由于其在上采样层的学习难度很大,重建性能不够稳定.
3) 逐步上采样超分辨率
一种折衷的想法在Laplacian Pyramid SR Network[23-24]和progressive SR[25]中被提出,即将最后的大的上采样分解成数个小的上采样,在每一个小的上采样前使用卷积神经网络来提取图像特征. 如此,通过将一个困难的任务分解成数个简单的任务,极大地降低了学习难度,获得更好的性能. 但这种方式的缺陷在于模型复杂,训练难度大.
4) 迭代上下采样超分辨率
这种框架采用类似U-Net的结构[26],通过在模型中交替使用上采样和下采样意在更充分地挖掘低分辨率图像与高分辨率图像对之间的深层关系[27],从而提供更高质量的重建结果.
一般来说,峰值信噪比(peak signal-to-noise ratio,PSNR)高于40 dB表明处理后的图像非常接近原始图像,但目前图像超分辨率方法很难达到这一指标. 其关键在于上述4类超分辨率框架都存在上采样这一步骤,由于原始信息的缺乏,这个步骤是高度病态的. 如何降低高度病态性,是突破现有超分重建技术的关键所在. 本文从视频传输的角度重新思考超分辨率的框架设计,将原始高分辨率图像的信息引入图像的上采样过程中,以缓解上采样引发的高度病态性问题.
2 联合上下采样超分辨率框架
2.1 理论分析
超分辨率问题可以表示为
L=fbic(H)
(1)
记原始高分辨率图像为H,其对应的低分辨率图像为L,这个低分辨率图像一般由双三次插值得到,其中fbic为双三次插值函数,超分辨率的目的是找到一个“逆函数”fsr,使得
H=fsr(L)
(2)
显然这样的变换是高度病态的,直接使用卷积神经网络去拟合这样的变换关系存在困难,因为低分辨率与高分辨率图像之间的映射空间过于庞大,一个低分辨率图像可以映射为多个高分辨率图像.
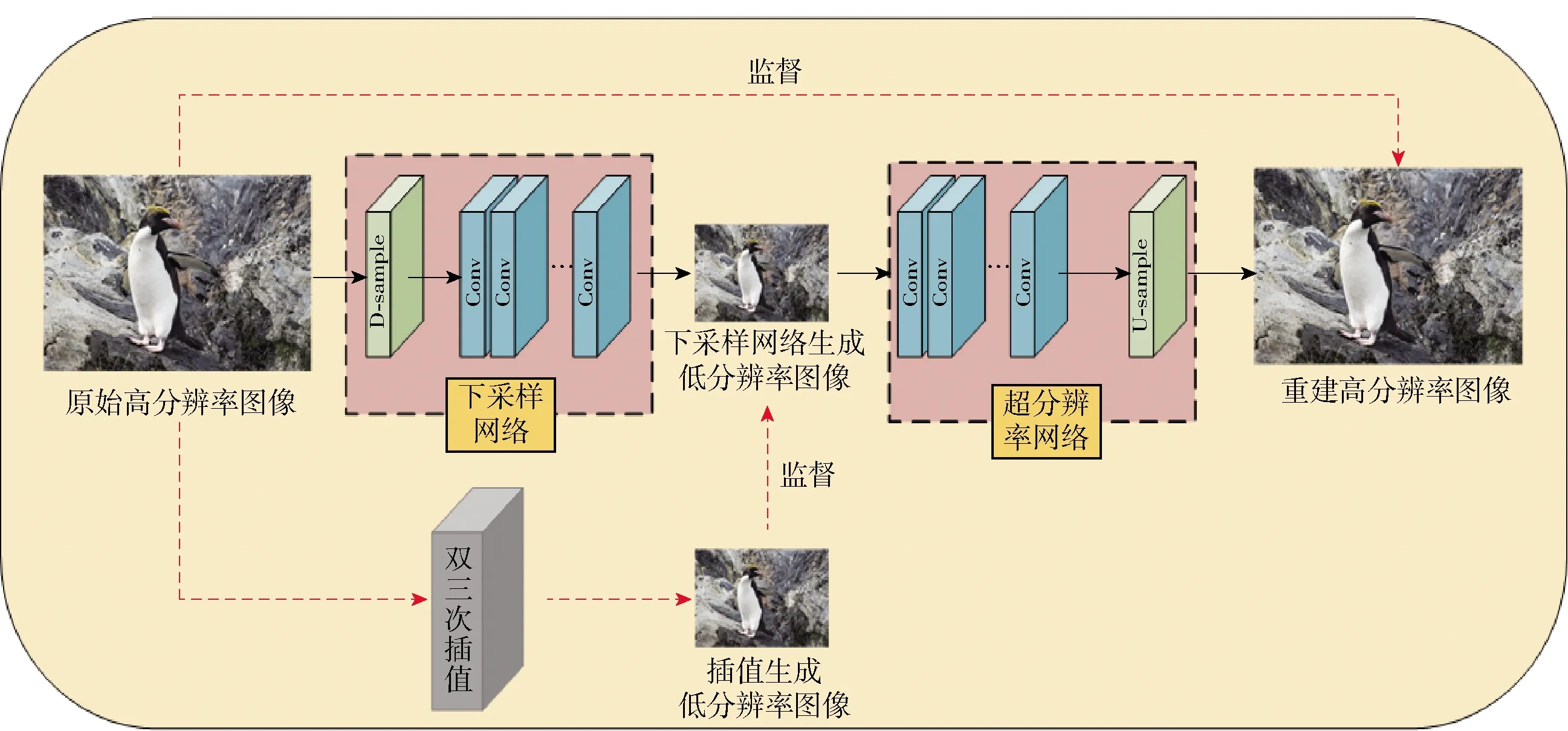
图1 联合上下采样超分辨率框架Fig.1 Joint up-and-down sampling super-resolution framework
这个问题在图像超分辨率中是无解的,因为输入数据在经过双三次插值后,已经损失了大量高分辨率图像信息. 为了解决这个问题,本文拟通过约束超分辨率过程中的映射空间来提升超分辨率的性能. 具体而言,在训练低分辨率图像和高分辨率图像的映射关系时,通过额外训练一个高分辨率图像到低分辨率图像的映射关系来限制低分辨率图像的映射空间,表达式为
H=fsr(fds(H))
(3)
式中:fsr为低分辨率图像到高分辨率图像的映射函数;fds为高分辨率图像到低分辨率图像的映射函数. 通过联合训练这2个映射函数,可以有效限制超分辨率过程中映射空间的大小.
进一步,根据Hoeffding[28]不等式
P[R(f)-(f)≥
(4)
对任意的f∈F,R(f)是期望风险,(f)是经验风险,N为样本数量,为泛化误差,[ai,bi]为样本区间,在本任务中可以记为[0,C],其中C为常数,则式(4)可进一步化简为
P[R(f)-(f)≥
(5)
由于F={f1,f2,…,fd}为一个有限集合,d为映射空间尺寸,故
P[∃f∈F:R(f)-(f)≥]=
(6)
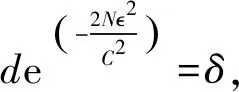
2.2 框架结构
基于理论推导,本文提出一种联合上下采样的超分辨率框架,如图1所示.
所提出的框架主要由下采样网络和超分辨率网络构成. 下采样网络用于对高分辨率图像进行降采样操作,使用由传统退化方法(双三次插值)得到的低分辨率图像进行监督训练. 在这个过程中,相比“粗暴”的插值方式,更多的高分辨率信息被隐匿在生成的低分辨率图像中,同时在结构上又与插值方式生成的低分辨率图像相同,不影响主观视觉效果. 超分辨率网络即为普通的超分辨率网络,不同的是,其输入为保留了高分辨率图像信息的低分辨率图像,使得还原的难度更低. 最后,整个框架进行联合训练,降采样过程与超分辨率过程互相约束,总体上减小了映射空间的尺寸,有效提升了模型性能.
框架的具体结构如表1、2所示. 为了便于对提出的方案进行验证,超分辨率网络部分直接选用了一种流行的超分辨率模型——EDSR[22]模型,这种模型结构简洁,性能强大,便于进行实验效果的对比. 而下采样网络在设计过程中遵循超分辨率网络的设计范式,取消批归一化层,通过堆叠残差块的方式提升模型能力[29],缓解网络训练过程中可能出现的梯度消失和梯度爆炸.

表1 下采样网络结构

表2 超分辨率网络结构
下采样网络结构和超分辨率网络结构均包含Head、Body、Tail三个模块,其中Head模块由一层3×3的卷积层组成,用于扩展模型的整体宽度,使得特征的映射在一个较大的空间内进行,以提升性能;Body模块为主要的特征提取层,具体结构如图2所示,包含2个3×3的卷积层和1个激活函数层,并使用残差连接的方式进行组合;Tail模块的作用是改变输入维度,实现降采样或超分辨率,分别由带步长的卷积层和Pixelshuffle[30]构成.
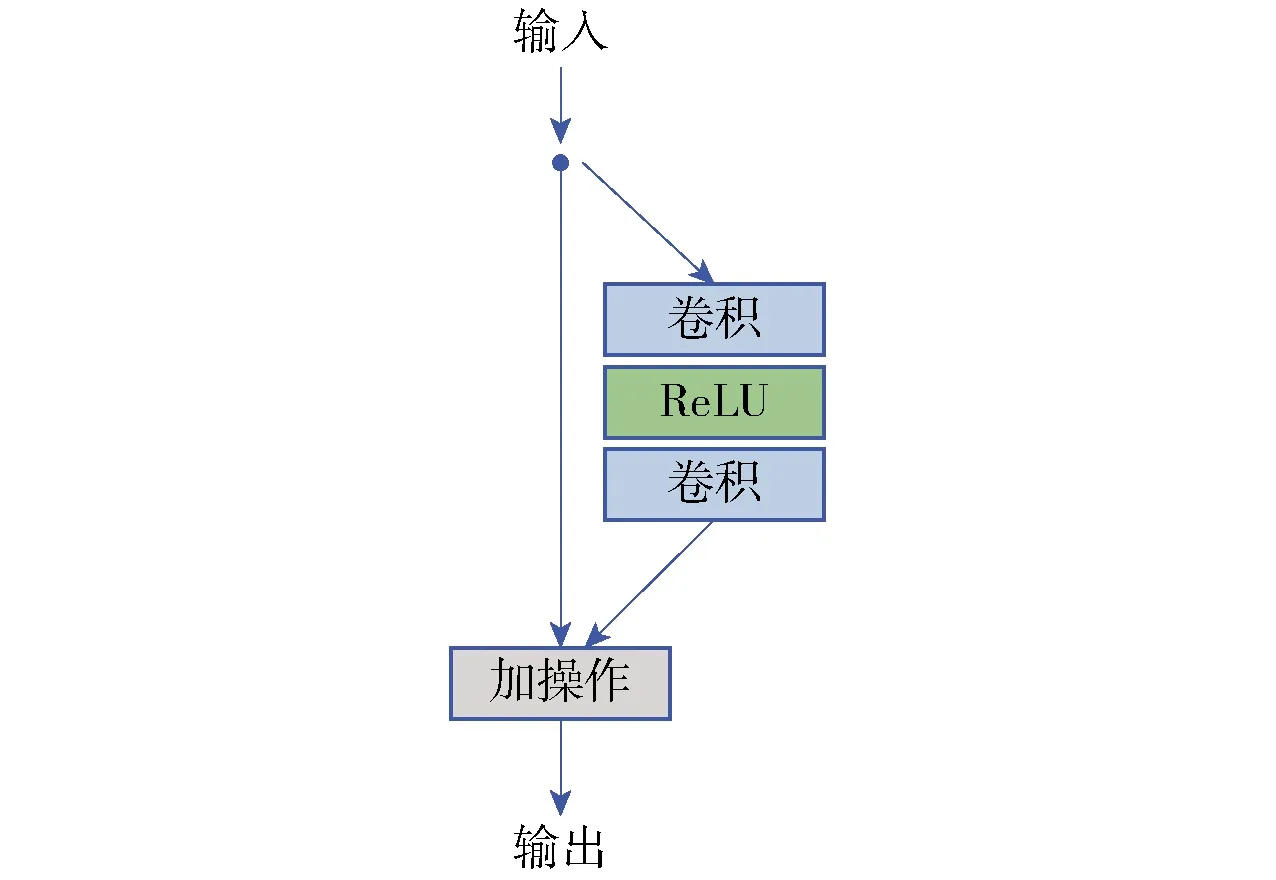
图2 残差块Fig.2 Resblock
2.3 训练流程
图1所示的联合上下采样超分辨率框架同目前主流的超分辨率框架一样,需要使用成对的高、低分辨率图像进行训练(低分辨率图像由双三次插值方法退化得到). 区别在于,其总体结构上输入为高分辨率图像,输出也为高分辨率图像,而低分辨率图像能够用于监督上采样网络的输出.
另外值得注意的是,由于下采样网络的输出结果为浮点类型,为满足实际应用场景的需求,输出需要通过量化转化为整形. 而这一量化过程是不可导的,导致无法通过反向传播进行训练. 因此,训练过程分为2步. 即首先不加入量化过程,进行下采样网络和超分辨率网络的联合训练;在模型收敛后,在模型中加入量化步骤,加载联合训练后的权重作为初值进行微调,即可完成整体框架的训练.
3 实验与结果
本文将所提出框架在主流超分数据集和HEVC标准测试序列与框架中采用的超分辨率模型EDSR进行了2倍、3倍、4倍的超分辨率实验对比,以下是实验参数和实验结果展示.
3.1 数据集
为保证公平,所有模型均基于超分辨率数据集DIV2K[31]的前800张图片进行训练,DIV2K数据集可使用图像共900张,其中100张用于验证,800张用于训练,图像平均分辨率1 972×1 734,包含风景、动物、植物、人、食物、建筑、车辆、手工艺品等多种类别,是被最为广泛使用的超分辨率数据集.
测试使用的图像超分辨率数据集包括Set14[32](见图3(a)),Manga109[33](见图3(b)),BSD100[34](见图3(c)),Set5[35](见图3(d)),Urban100[36](见图3(e)),其中,Urban100主要为建筑图像,Manga109为漫画图像.

图3 测试图像数据集Fig.3 Test image data sets
此外,选取了5种分辨率和场景各异的HEVC标准测试序列进行了测试,如图4所示,均选取时长为10 s的片段,利用视频编码常用工具FFmpeg将视频序列保存为RGB图像,根据其帧率的区别每个序列获得240~500张图像.
3.2 实验设置
实验基于深度学习框架PyTorch[37]进行,硬件设备为RTX2080TI. 使用图像Y通道上的PSNR和结构相似度(structural similarity,SSIM)为指标进行性能评判标准,同时也进行主观效果的对比展示.
在训练过程中,与通常的超分辨率模型训练方法相同,将图像切为192×192的小片进行训练,推断则在整张图像上推断. 使用Adam优化器,初始学习率为1×10-4,以余弦退火策略进行学习率的调整,使用L1(第一范数)损失作为损失函数.

图4 测试视频数据集Fig.4 Test video data sets
3.3 实验结果
在图像超分数据集和HEVC标准测试序列上的结果分别如表3、4所示. 其中,Bicubic[38]代表使用双三次插值的方式进行上采样的超分辨率结果,
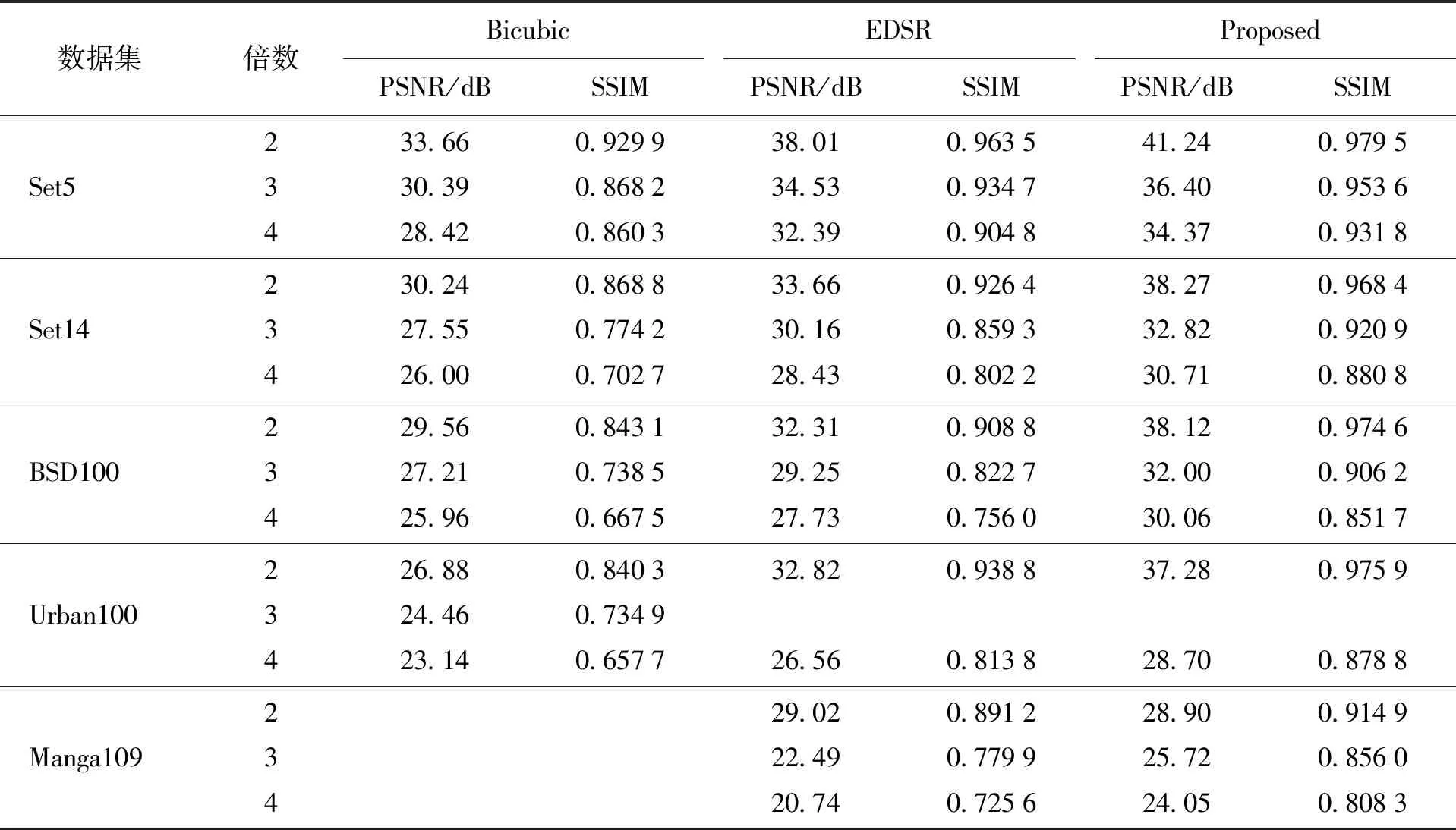
表3 在图像数据集上的性能对比
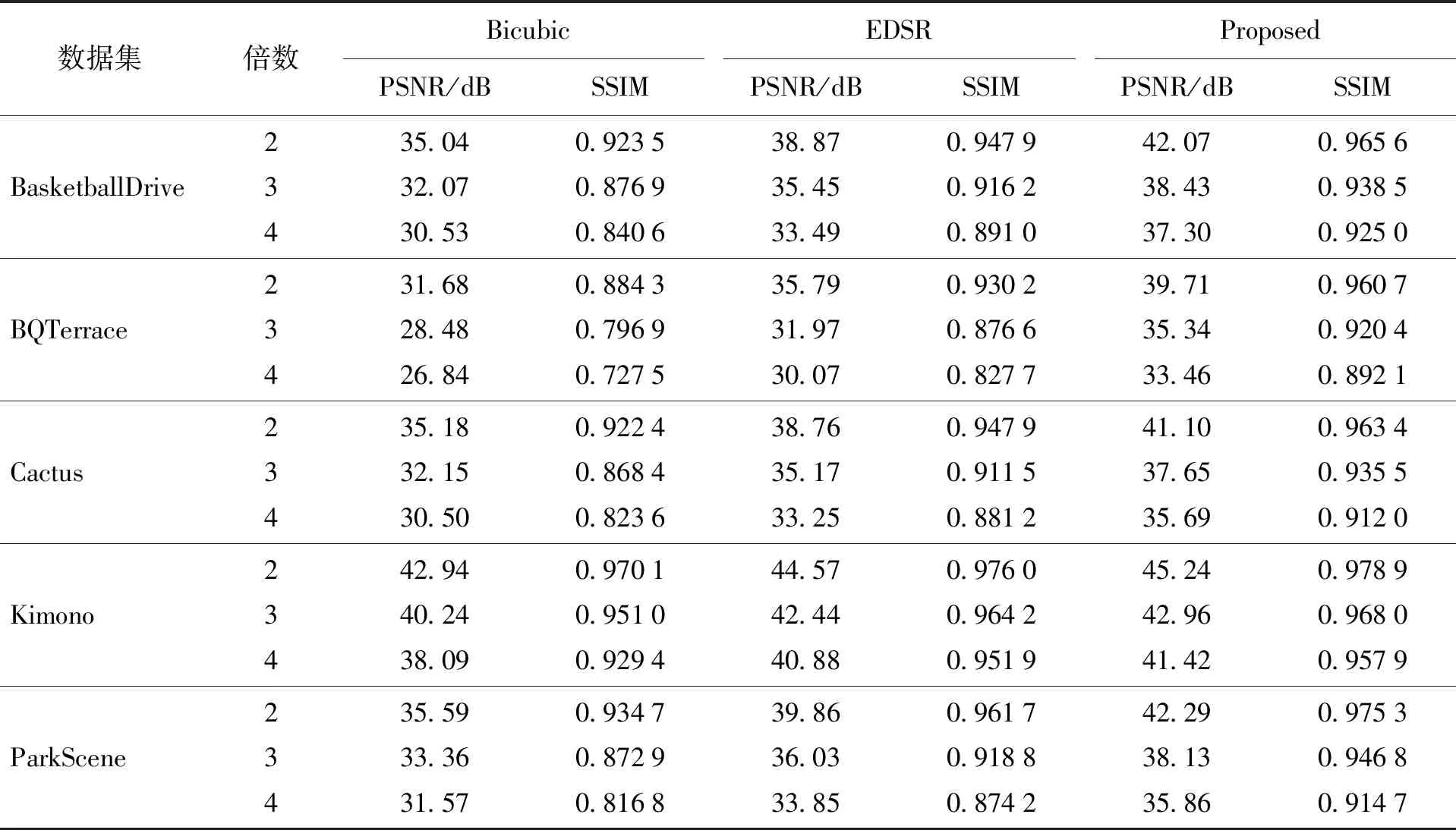
表4 在视频数据集上的性能对比
其数值可以在一定程度上代表数据集的还原难度,一般作为实验的基线展示. EDSR为所对比的超分辨率模型,Proposed为提出的联合上下采样的超分辨率框架.
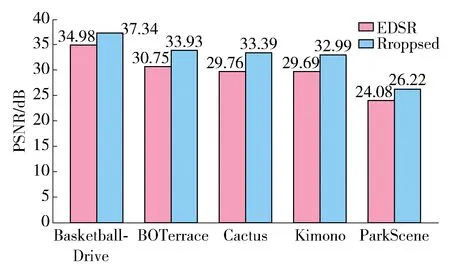
图5 图片数据集上的平均PSNR性能对比Fig.5 Average PSNR performance comparisons on image data sets
图5、6分别为各个图像和视频数据集下不同超分倍数任务的平均PSNR指标,可以看到,在几乎所有的图像超分辨率数据集上以及超分辨率倍数任务中,所提出框架相较原始的EDSR模型均有较明显的提升,在图像数据集上相比原始的EDSR模型平均提升超过2.9 dB. 这表明通过约束超分辨率任务的函数映射空间,能够有效缓解超分辨率任务中的病态性问题. 值得注意的是在HEVC标准测试序列中,所提出的框架甚至能达到无损(PSNR超过40 dB)的程度,相比原始的EDSR模型平均提升超过1 dB,证明本文提出的方法对于视频传输具有十分积极的意义.
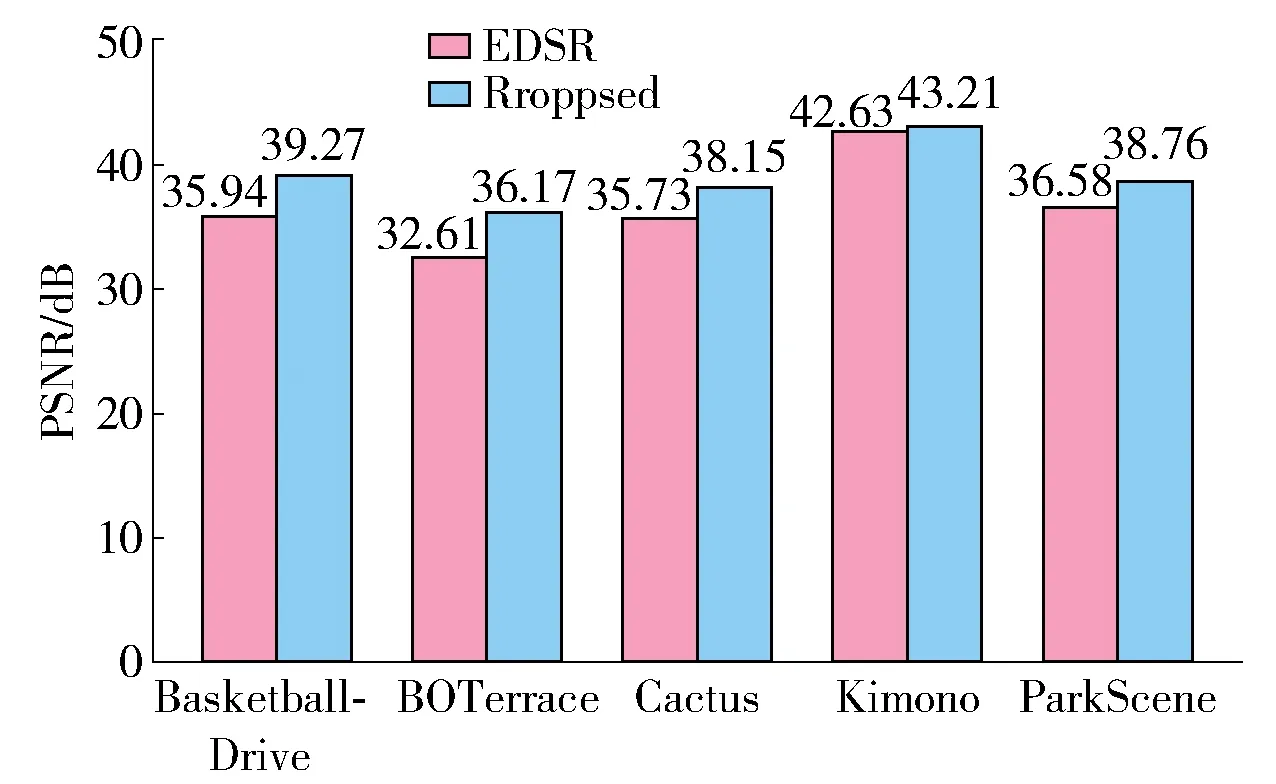
图6 视频数据集上的平均PSNR性能对比Fig.6 Average PSNR performance comparisons on video data sets
在图片数据集上的主观效果对比如图7所示,图7(a)为原始高分辨率图像,图7(b)为双三次插值的恢复结果,图7(c)(d)分别为EDSR模型和所提出的框架的恢复效果,可以看到,使用所提出的方法,一些细节和纹理能够被更好地恢复. 图8为在视频序列上的测试效果,图8(a)为原始图像,图8(b)为双三次插值恢复的图像,图8(c)(d)分别为EDSR模型和所提出框架的恢复结果,可以明显看出细节部分的质量提升. 因此,从主观效果上来看,所提出的框架具有更有竞争力的效果.
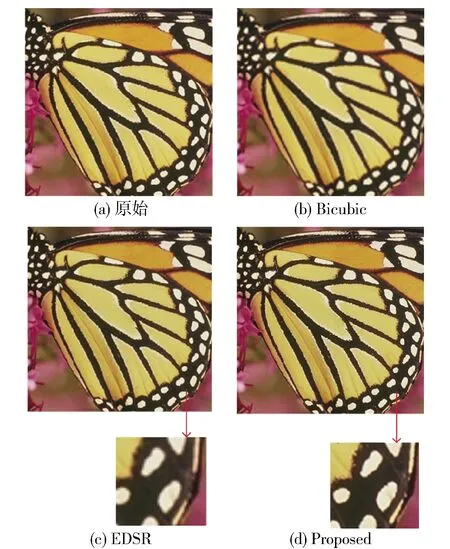
图7 图像恢复质量主观对比Fig.7 Image restoration quality subjective contrast

图8 视频恢复质量主观对比Fig.8 Video restoration quality subjective contrast
3.4 计算效率分析
本文从模型的参数量、浮点运算数和显存占用3个角度分析所提出模型的计算效率,并与原始的EDSR模型进行对比,如表5所示. 表格中为2倍、3倍、4倍超分辨率任务下输入尺寸为192×192切片情况下的计算效率统计,可以看到,由于增加了一个全新的上采样模块,相比原始的EDSR,模型的参数量、浮点运算数和显存都有较大的消耗. 一般来说,神经网络参数量越多,拟合能力就越强[29],为消除参数量的影响,进一步进行了有关参数量的消融实验.
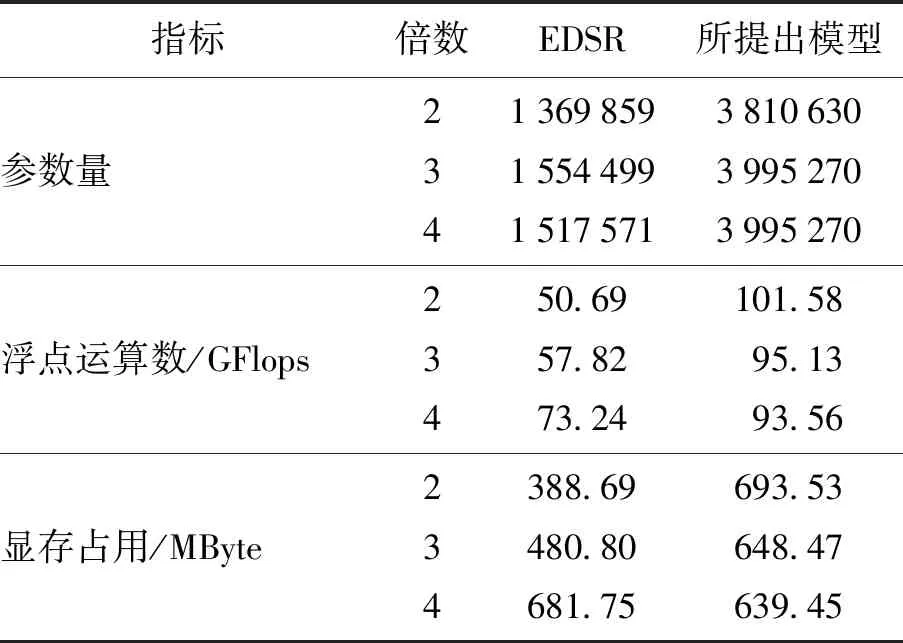
表5 计算效率分析
不改变框架整体结构,通过将目前框架的宽度(通道数)减半并适当减少残差块数量的方式训练了2倍超分辨率任务下的新模型,新模型的参数量与EDSR模型相当,在图像和视频数据集上的表现如表6所示. 需要注意的是,尽管低参数量模型的超分辨率部分不再与EDSR完全相同,但依然采用了一致的设计范式. 可以看到,在消除了参数量的影响后,所提出的框架依然具有有竞争力的结果.
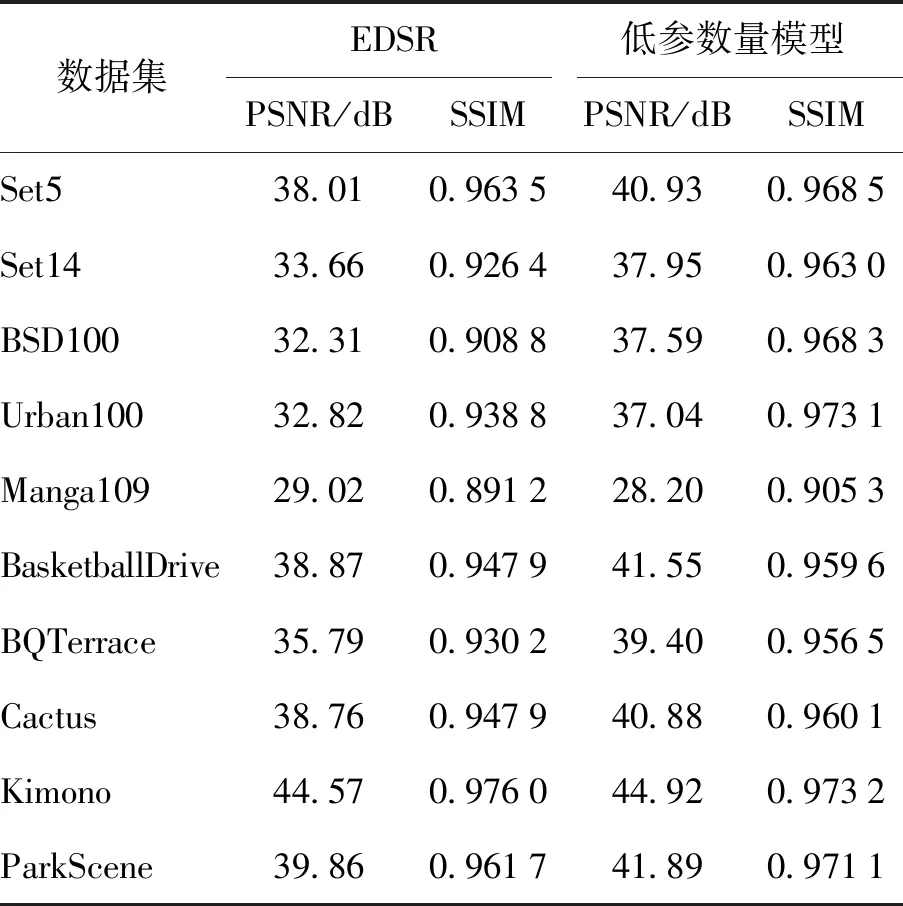
表6 低参数量模型性能
4 结论
1) 针对超分辨率技术中的高度病态性问题,本文面向视频传输应用提出一种联合上下采样的超分辨框架.
2) 针对所提出的超分辨率框架,在模型泛化能力层面上,给出其在理论上具有更佳表现的证明. 即通过减少超分辨率中映射函数的空间尺寸,可以有效提升模型的能力.
3) 基于所提出框架构建了深度学习模型,通过在框架的超分辨率模型使用EDSR模型并与原始的EDSR模型进行对比实验. 实验结果表明,所提出框架在图像数据集上相比原始EDSR模型可以提升超过2.9 dB的PSNR指标,在HEVC标准测试序列上可以达到近乎无损,并且主观效果提升明显,证明所提出框架的有效性.
猜你喜欢
红外技术(2022年11期)2022-11-25 08:12:22
电子产品世界(2022年9期)2022-05-30 20:41:07
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
雷达学报(2020年3期)2020-07-13 02:27:16
数学物理学报(2019年6期)2020-01-13 06:08:16
艺术科技(2018年2期)2018-07-23 06:35:17
数学物理学报(2017年5期)2017-11-23 07:51:31
太空探索(2015年8期)2015-07-18 11:04:44
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:19
航天返回与遥感(2014年4期)2014-07-31 17:47:42
