
双向匹配向量空间算法在智能阅卷系统中的应用
2021-05-24 07:59季天凯朱轩周汉清
电脑知识与技术 2021年12期
季天凯 朱轩 周汉清

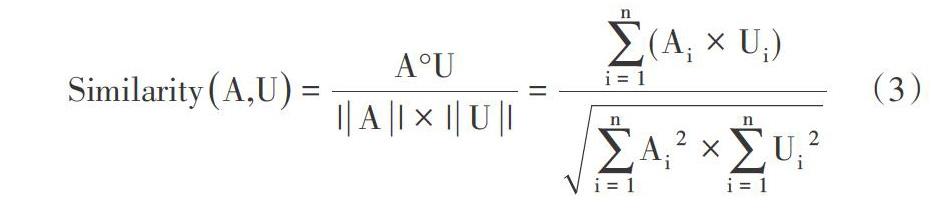
摘要:目前,主观题自动化阅卷的准确度是智能阅卷系统能否有效的关键要素,通过提出双向匹配向量空间算法,使用盘古分词组件进行文本预处理,利用算法中的双向匹配和向量空间计算关键词匹配和文本相似度,实现主观题自动阅卷的评分功能,并通过C#.NET语言开发智能阅卷系统。通过系统实验结果证明,该算法下的自动阅卷与人工阅卷的结果误差率较小,具有良好的应用前景。
关键词:中文分词;双向匹配;向量空间;相似度计算
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2021)12-0079-03
Abstract: Currently, the accuracy of automatic marking of subjective questions is the key factor for the effectiveness of intelligent marking system, by proposes a bidirectional matching space algorithm, use Pangu word segmentation for text preprocessing, use keyword bidirectional matching and vector space model to calculate keyword matching and text similarity, and C#. Net design marking system. Experimental results show that the result of automatic marking under the guidance of this algorithm is less different from that of manual marking, and has a good application prospect.
Key words: Chinese word segmentation; bidirectional matching; vector space; similarity computation
1 背景
智能閱卷是指通过计算机对学生作答的试题答案进行自动阅卷[1],减少阅卷工作量,提高评卷的公平性和效率。目前,智能阅卷是在线考试领域研究的前沿技术之一[2]。现阶段,针对客观题的智能阅卷已经得到了广泛的应用,例如计算机等级考试、GRE考试以及会计电算化考试等[3],然而由于主观题评阅涉及分词技术与关键词匹配技术等,这使得主观题评阅成为智能阅卷中的技术难点。近年来,随着对自然语言处理理论研究的深入,已经提出了一些相对较为成熟的主观题算法,但是在系统实现和具体应用上面仍然很少[4]。本文主要利用基于双向匹配的中文分词技术和向量空间的文本相似度技术,通过中文分词技术将答案切分成不同的词语,再经过双向关键字匹配,获取关键词得分点;并通过向量空间,计算答案与标准文本的贴近度,完成主观题答案的自动评阅,实现在线考试的智能阅卷功能,并利用实验结果验证智能阅卷的可靠性。
2 双向匹配向量空间算法原理
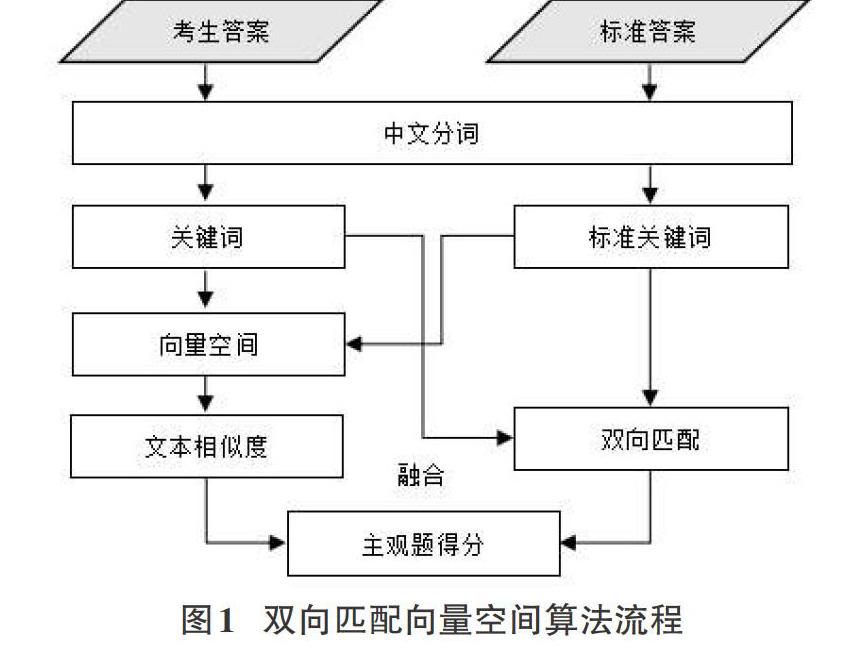
本系统中主观题部分的评阅采用双向匹配向量空间算法实现,算法流程如图1所示。
算法主要包含关键词匹配计算方法,语义相似度计算方法以及综合相似度融合算法。其中,关键词匹配度可以通过关键词双向匹配进行计算,而语义贴近度可以通过向量空间进行量化,答案文本综合相似度则通过关键词匹配度与语义相似度两维度进行融合,最终得出对主观题的智能阅卷得分。
2.1 关键词双向匹配
关键词双向匹配即通过正向匹配和反向匹配相结合的方式,把学生答案中的关键词依次和标准答案中的关键词进行比较,当匹配一致时将字符字数进行累加,最后将正向匹配和反向匹配中匹配字符数值大的一项与标准答案中的关键词字符数进行相除,得出的比值即为学生答案与标准答案关键词的匹配程度。例如设[A0]为考生的答案,[?(T,A0)]为关键词匹配的比值。双向匹配的具体公式为:
在公式1中,[Ti]和[Tj]分别为关键词在正向和反向匹配中匹配成功的字符数;[Ui]为标准答案中关键词的字符数,[?Ti,A0]为考生答案与标准答案某关键词匹配字符的比值;在公式2中,[S0]是题目的分值,[U]是标准答案中关键词的个数,[T]为关键词匹配的最终得分。
2.2 中文分词技术
在主观题智能阅卷中,中文分词的作用十分重要,它可以将中文语句中的词汇,按照一定的规则进行切分,形成一个一个单独的词语。而由计算机自动识别文本中的词,实现切分处理过程的技术就是中文分词技术[5]。例如中文“中国的首都是北京”,分词结果是“中国\的\首都\是\北京”。在分词时,分词的结果受到语义、句法等因素影响。
目前,中文分词技术已经比较成熟,网络上出现很多开源的分词软件,例如盘古分词、IKAnalyzer、Phpanalysis、Paoding等[6]。本文的中文分词技术采用的是开源的盘古分词组件,它是目前能够对中文语句进行准确切词的工具之一。例如,利用盘古分词对中文“操作系统是管理计算机硬件与软件资源的计算机程序。”进行分词,最终的结果为“操作系统\是\管理\计算机硬件\与\软件\资源\的\计算机\程序”。
2.3 向量空间
在向量空间模型中,文本以向量的形式进行表示,通过把文本转化为对向量空间的相似度运算计算文本相似度。向量空间相似度的计算可以用内积、夹角余弦、Jaccard相似度和Dice系数等方法来计算[7]。
本文采用夹角余弦方法计算文本相似度,当向量间的夹角越接近于0°,即夹角余弦值越接近于1,表示两个向量越相似,即文本间的相似程度越高。计算公式为:
在公式3中,其中[A]和[U]表示两个向量,代表考生答案和标准答案,[Ai]和[Ui] 分别表示两个向量中的各个元素。
2.4 相似度融合
在得到答案文本基于关键词的匹配得分以及基于语义结构的相似程度后,采用统计回归的方法将两个维度的相似度以最优的权重融合为答案文本的最终综合相似度。本文将关键词匹配与语义相似度定义为自变量,将考生答案得分与题目满分值定义为因变量,定义的主观题评分公式为:
在公式4中,[S]为考生答案最终得分;[S0]为题目满分值;[T]为关键词匹配得分值;[SimilarityA,U]为考生答案与标准答案间的相似度;[α]和[β]分别为匹配关键词和文本相似度的权重,满足[α+β=1],权重可以根据实际需求自行调整。
3 智能阅卷系统设计
本文中基于双向匹配向量空间算法设计的智能阅卷系统框架主要包括三个重要模块,分别为定义模块、处理模块和响应模块,如图2所示。
定义模块由试题内容、试题分值、标准答案、权重分配和考生答案构成,值得注意的是,在定义主观题阅卷权重时,需要分别设置关键词和相似度的权重,并保证两者权重之和为1。主观题设置界面如图3所示。
处理模块由中文分词组件、关键词抽取、关键词双向匹配和词语相似度计算构成,通过盘古分词组件对中文语句进行切词,滤除与分词无关的干扰项,通过双向匹配和夹角余弦算法对关键词匹配和文本相似度进行计算。
在响应模块,通过对关键词双向匹配和文本相似度两个维度的融合计算,量化并确定题目的最终得分。另外,系统中还加入了人工评阅的功能,对主观题自动评阅的得分进行修正和完善,从而保证系统得分的准确性。阅卷效果如图4所示。
4 实验结果及分析
在完成基于双向匹配向量空间算法设计的智能阅卷系统后,为了验证算法的可用性,选取了50名考生的试卷进行测试,由于每份试卷有4道主观类型的题目,在测试时,先利用中文分词、关键词匹配和夹角余弦相似度计算,进行系统阅卷,然后再进行人工阅卷,最后比较两者的误差率,测试结果如表1所示。其中,误差率=|人工阅卷得分-系统阅卷得分|/满分,误差率越小表示系统阅卷结果可靠性越高。
另外,随机选取其中第二题的阅卷记录,利用折线图的方式更加直观的展示人工阅卷和系统阅卷之间的评分差异性,如图5所示。
通过表1和图5可以发现,双向匹配向量空间算法指导下的系统阅卷虽然与人工阅卷在评分上不完全一致,但是误差率基本控制在20%之内,说明该算法的结果是比较合理的。
5 结束语
本文详细分析了双向匹配向量空间算法的具体应用,在该算法中首先采用双向匹配对关键词的匹配程度进行度量、再通过向量空间量化文本间的相似度,最后通过对两个维度的相似度融合,计算出考生答案与主观题答案最终贴近程度。经过系统的仿真实验结果表明,双向匹配向量空间算法指导下的自动阅卷与人工阅卷之间的误差率较小,在智能阅卷系统领域中具有良好的应用前景和推广价值。
参考文献:
[1] 张帅.基于孪生神经网络的主观题自动阅卷评分技术[J].现代计算机,2020(5):23-25.
[2] 李纪扣,韩建宇,王嫄.基于相似度融合算法的主观题自动阅卷机制[J].天津科技大学学报,2019,34(1):76-80.
[3] 張翠翠,周国祥,俞磊,等.基于MVC的试卷生成及主观题判卷算法研究[J].系统仿真学报,2020,32(1):105-112.
[4] 陈贤武,刘道波.基于语句相似度的主观试题自动阅卷模型研究[J].武汉大学学报(工学版),2018,51(7):654-658.
[5] 冯光,乔丹丹,常静怡.基于分词匹配的主观题自动评阅技术研究[J].计算机与现代化,2013(3):212-214,219.
[6] 宋雪亚,王传安.基于中文分词的主观题自动评分算法研究[J].河北北方学院学报(自然科学版),2017,33(9):7-11.
[7] 秦学勇.基于相似度计算的主观题阅卷系统设计[J].安徽建筑工业学院学报(自然科学版),2010,18(4):77-80.
【通联编辑:谢媛媛】
猜你喜欢
考试与招生(2022年10期)2022-11-17
井冈教育(2022年2期)2022-10-14
中学生数理化(高中版.高考数学)(2022年6期)2022-07-02
校园英语·月末(2021年13期)2021-03-15
通信电源技术(2016年5期)2016-03-22
电源技术(2015年9期)2015-06-05
河南科技(2014年19期)2014-02-27
外语学刊(2011年3期)2011-01-22
