
基于高表征能力特征处理模块的小目标检测
2021-05-20 06:50向华桥崔文超刘世焯孙水发
计算机工程与设计 2021年5期
向华桥,崔文超,刘世焯,孙水发
(三峡大学 计算机与信息学院,湖北 宜昌 443000)
0 引 言
随着人们对于目标检测技术越来越广泛的应用,对于一些特定场景下小目标的准确识别有了更多需求。同时小目标检测性能的提高是目前目标检测技术中的一个难点问题,改善小目标检测性能对于整体目标检测技术的更好应用有着重要意义。目标检测主要包括两个方面的内容,一是对图像中感兴趣目标的定位,二是对定位边框中目标的分类。小目标目前没有特定的大小定义,其具有尺寸较小,分辨率低,特征不明显等特点,往往根据不同的应用背景小目标的尺寸定义略有不同,在MS COCO数据集中往往将尺寸小于32×32像素的目标定义为小目标。
传统非深度学习的目标检测算法[1]往往分为3个步骤,生成候选区域、特征提取、目标分类,生成候选区域后使用特征模板进行特征提取,然后对提取的特征信息用分类器分类后得到检测结果。而基于深度学习的检测算法[2]使用卷积神经网络学习目标特征,通过反向传播误差实现网络系数自动更新,再将特征应用于具体的检测过程。2012年以来,基于卷积神经网络(CNN)的目标检测研究取得了重大的突破。基于深度学习的目标检测算法往往又可以分为单阶段和两阶段两大类[3],其中RetinaNet[4]是经典的单阶段算法之一,Faster RCNN[5]是经典的两阶段算法之一。现阶段大部分目标检测算法以及各种不同的改进都是针对常规尺度的目标,而对于小目标检测效果不够理想。相关研究[3,6,7]表明小目标检测的瓶颈主要在于分类任务:小目标分辨率低,特征信息已经不够明显,但传统深度网络的目标检测方法在特征处理过程中的下采样等操作会进一步导致信息损失,极大限制了其检测的精度。
本文从减少特征处理过程中特征信息损失这个关键影响因素入手,结合CARAFE和HRNet的设计思想,提出了一种特征信息处理模块CHRNet,用于整体目标检测模型的特征信息处理部分,同时针对样本不平衡问题对Focal Loss[4]进行一定调整,加上合适的anchor设计。以上改进在两种代表性的目标检测方法RetinaNet和Faster RCNN上加以应用,在MOCOD和VEDAI[8]两个数据集上进行实验。具体来说,本文的主要贡献包括:
(1)针对小目标检测中特征信息损失问题,提出了一种高表征能力的特征信息处理模块CHRNet;
(2)针对小目标检测样本不平衡问题对损失函数进行了改进调整,以及设计了更适合小目标的anchor,相对更加全面地对影响因素进行了研究改进。
1 相关工作
对于特征信息损失问题,目前主流做法有两种,一是使用图像金字塔结构,即将原始图像进行一系列缩放,结合超分辨率等,但是目前被证明会大幅增加内存和计算开销;二是在输入图像的特征信息上进行操作,相对开销较小。基于后者的思想,于2017年提出的特征金字塔网络(FPN)[9]是取得的最大进展之一。自下而上通路是CNN对特征图逐层前向卷积的过程,低层的网络更关注细节信息,高层的网络更关注语义信息,自上而下通路是对特征图上采样的一个过程,然后将处理过的低层特征和高层特征进行融合,利用低层特征准确的位置信息和高层特征提供的语义信息,使得输出的特征图具有更好的表征能力,现有各种更优秀的特征金字塔结构[10]都是基于FPN发展而来。同样基于对特征信息的处理,于2019年提出的HRNet针对人体姿态估计问题从分类网络的主体部分着手,由于常用的分类网络学到的表征分辨率较低,很难在空间精度敏感的任务上取得准确的预测结果,其用并行连接不同分辨率的卷积子网代替传统的串行连接,在不同分辨率的并行子网间进行多次信息交换和特征融合,进而提高了整体网络的表征能力。于2019年提出的CARAFE上采样算子从特征信息处理过程中常用的上采样操作入手,整个算子相对于传统的上采样方法,它能够在一个较大的感受野内聚合信息,能够动态适应特定实例的内容,同时保持一定的计算效率,相对能够更有效提取目标特征信息。其它相关的方法[11-14]也对该方面有所改善。
对于样本不平衡问题,一直是影响目标检测精度的重要因素。样本不平衡问题是指在训练的时候各个类别的样本数量极不均衡,负样本的数量远大于正样本,简单样本远大于难例,从而导致训练无法收敛到很好的解。对于小目标而言,由于小目标往往占据整幅图很小一部分,其正负难易样本往往是更不平衡的。目前有不少针对样本不平衡问题的解决方法提出,比如OHEM(在线难例挖掘)[15]、GHM(梯度均衡化)[16]、Focal Loss、DR Loss[17]等。
以上工作从不同角度有效改善了小目标的检测性能,但是很多只是对小目标检测有一定帮助且针对特定的需求场景,而且小目标和常规目标的检测性能仍然存在着显著差异,因此具有一定改进优化的空间。
2 特性信息处理模块CHRNet
在减少特征信息损失方面,从整体模型的特征信息处理部分入手,利用改进的高分辨率表征的HRNet[18]网络对特征信息初步处理,而后结合FPN网络进行特征信息细化处理,同时在FPN中加入CARAFE[19]上采样算子进一步减少特征信息处理过程中的损失,随着特征信息的处理进程,在多次特征图融合中设计了不同的融合方法,同时对相应环节采用了越来越有效的上采样方法,在保持一定计算效率的条件下最大化整体特征信息处理模块的表征能力。
2.1 网络架构
本文设计的特征信息处理模块CHRNet的网络结构如图1所示。
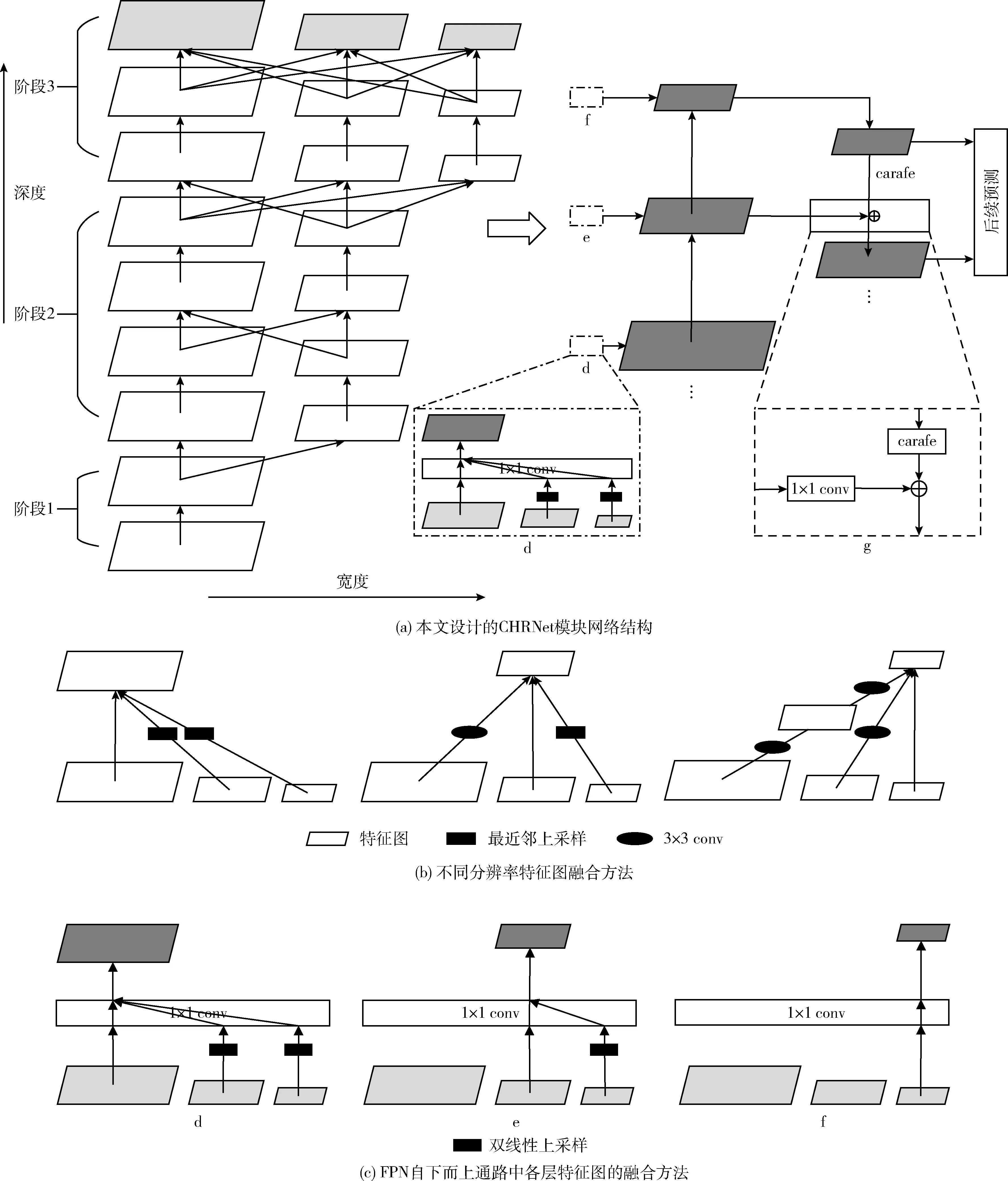
图1 CHRNet特征信息处理模块
2.2 处理流程
上采样可以简单理解为进行图像的放大或者图像的插值,在目标检测任务中,上采样操作可以表示为每个位置的上采样核和特征图中对应领域的像素做点积。传统常用的上采样方法有最近邻插值法、双线性插值法等,双线性上采样相对计算量较大,但上采样效果更好,而CARAFE上采样算子相对于传统的插值方法,在保持一定计算效率的同时能够更有效保留特征信息。
该模块作为整体模型的特征信息处理部分,在输入一张图片后,首先是对其特征图进行前向卷积,同时保留不同分辨率的多个子网构成并行网络,图1(a)中有3个并行网络,同时网络可分为3个阶段,每个阶段比上一个阶段多一条分支,新增分支是上一阶段的不同分辨率的特征图进行3×3跨步卷积融合后的结果,分辨率是上一分支分辨率大小的一半,通道数为上一分支的两倍。同时在每一阶段的并行分支中保留残差单元保证网络延伸时不会梯度弥散以及网络退化。图1(a)中的高层特征图是对上一阶段的特征图进行图1(b)所示的相关操作后再通过1×1 conv 融合得到,其中上采样采用最简单的最近邻上采样方法。在并行子网反复交换特征信息以及不同分辨率的特征图进行融合后,该部分网络的表征能力得到了增强。
在特征图输入到FPN网络前,不是简单用高阶段得到的特征图作为输入,而是对高阶段网络的所有不同分辨率的特征图(图1(a)中有3个)经过图1(c)中的对应操作后得到。图1(c)中在不同分辨率特征图进一步融合的时候,为了避免下采样(跨步卷积)带来的信息损失,只进行相对低分辨率特征图的上采样,然后通过1×1 conv融合,其中上采样采用更为有效的双线性上采样。融合后的不同特征图之间的分辨率依然保持两倍的关系,刚好符合FPN网络后续特征图进一步融合的分辨率要求,从而直接得到了FPN自下而上通路中不同层的特征图。
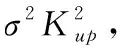
最后在FPN自上而下通路中,如虚线框g所示,将经过CARAFE上采样后的特征图与自下而上通路中相应的特征图进一步融合,然后经过一个3×3 conv消除上采样的混叠效应后得到最终的输出特征图,用于模型后续的分类等操作。
3 其它关键因素的改进
本文的模型主体结构[6]是基于经典的单阶段方法RetinaNet和经典的两阶段方法Faster RCNN。将以上CHRNet模块应用于上述两类方法,同时从整体模型的损失函数入手,加入并改进常用的Focal Loss损失函数,其中Faster RCNN模型中,结合小目标检测的特点,主要将Focal Loss用于RPN部分,进而改善样本不平衡问题;最后针对小目标设计了更合适的anchor,也是有效提高了整体模型的检测精度。
3.1 缓解样本不平衡
Focal Loss主要是为了解决单阶段目标检测中正负样本比例严重失衡的问题,该损失函数降低了大量简单负样本在训练中所占的权重(小目标检测中往往是大面积的背景),使得模型在训练时更专注于难分类的样本(小目标检测中往往是部分小目标以及部分误检的负样本)。
Focal Loss是在交叉熵损失函数基础上进行的修改,下面是Focal Loss损失函数(二分类)的形式
(1)
y′是分类器预测后经过激活函数的输出,是在0到1之间的一个概率值,当存在大量简单负样本时,交叉熵损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。Focal Loss则加了两个关键参数γ,α, 其中γ主要是解决难易样本不平衡问题,使得易分类样本(分类器预测值y′高)的损失减少,使其更关注于难分的样本,有效缓解了那些误检和漏检的情况。此外,平衡因子α主要是用来平衡正负样本本身的比例不均。
COCO数据集中将像素大小0×0到32×32的目标定义为小目标,将像素大小32×32到96×96的定义为中等目标,由于在小目标检测中负样本往往是大面积的背景,根据不同尺寸目标之间的面积大小关系,为了更好地平衡小目标情况下的正负样本比例,将Focal Loss损失函数修改为如下形式
(2)
同时,实验发现检测结果中误检(比如将某块背景检测为目标)和漏检(比如有些小目标直接没有检测出来)的情况相对比较多,同时随着γ的增大,易分类的样本的损失比重会变得越来越小,在小目标检测中存在较多的误检和漏检的样本以及小目标本身往往是难分类的样本,所以尝试合理增大γ, 从而改善小目标检测的精度。
3.2 合适的anchor设计
现有的大部分基于深度学习的目标检测算法都有预先的锚框(anchor)设计,预设一组尺度不同位置不同的固定参考框,每个参考框负责检测与其交并比大于阈值的目标,anchor将目标检测转换为了“这个固定参考框中有没有认识的目标以及目标框偏离参考框多远”的问题,从而有效提高了模型的检测精度和效率。
设anchor矩形框的宽为W,高为H,W/H=anchor_ratios, 针对小目标尺寸相对较小的特点,相对于常规的目标检测情况,可以做以下设置,其中W即anchor_strides=[4,8,16,32,64] (与默认配置有5个值保持一致), anchor_ratios=[0.5,1.0,2.0], 即针对参考框宽高的3个不同缩放比例,同时设定anchor整体的缩放因子anchor_scales=[4], 这样小点的anchor尺寸为(4*4=16)16×16, 符合一般小目标尺寸往往在32×32附近的要求,这样在每一个位置会生成更符合小目标尺寸的anchor,回归的好不如预设的好,进而改善小目标的检测性能。
4 实 验
4.1 数据集
本文实验主要在MOCOD和VEDAI这两个数据集上进行实验。MOCOD数据集是2019年清华大学举办的小目标检测竞赛的数据集,该数据集基于虚拟仿真环境创建,模拟无人机在低空飞行时对城市道路上行驶的多种车辆进行航拍,共有超过13 000张图片。识别目标包括12种车辆(BMW、Nissan、Mustang、Mini、Volkswagen、Policcar、Lincoln、Tazzar、Jeep、Truck、Bus、SUV);VEDAI数据集是一个包含不同交通工具的航空影像数据集,其中绝大部分都是符合小目标尺寸的不同交通工具,本实验主要在其中1024×1024尺寸的1246张图片上进行,由于数据量相对较小,为了防止网络出现过拟合等不好的情况,对其进行了对比度增强、水平翻转、随机方向旋转等数据增强手段,将数据扩充至约5000张图片,其目标类别主要包括不同的交通工具(car、truck、pickup、tractor、camping car、boat、motorcycle、bus、van)。以上所有数据集都被处理为标准COCO数据集格式,其中约80%作为训练集,约20%作为测试集。
4.2 实验设置
实验环境为ubuntu18.04,CUDA9.2,python3.7.4,pytorch1.2.0,mmdetection v1.0c1[20],CPU为Intel(R) Xeon(R) E5-2680 v3,GPU为2个2080Ti。
实验基准以mmdetection上默认方法为准,其中Faster RCNN为faster_rcnn_r50_fpn_1x,即主干网络默认经过预训练的ResNet50[21]且采用了fpn网络,1x表示训练迭代次数为标准的12个epoch,类似的,RetinaNet为retinanet_r50_fpn_1x。本文考虑到和默认的ResNet50的网络参数量和计算复杂度相近,实验中选择基于系列网络中最小的HRNetV2-W18[22]网络进行改进,其中W18表示的是最后3个阶段高分辨率子网络的宽度,和ResNet50中50表示的网络深度含义类似。优化函数采用常用的带动量的SGD,学习率根据线性缩放规则动态调整,比如在4 GPUs和2 imgs/gpu 的条件下有lr=0.01,则2 GPUs和1 img/gpu的条件下lr=0.01/(4*2/2*1)=0.0025, 不同数据集上由于图片尺寸不同学习率略有调整。
4.3 实验结果及分析
本实验主要关注检测精度mAP和检测速度FPS两个主要指标,mAP以COCO数据集的精度评估为标准,其评估了在不同交并比(IOU) [0.5∶0.05∶0.95] 下的AP,以这些阈值下平均AP作为最终结果mAP,相较于VOC数据集格式而言COCO数据集的评测标准更加严格。
4.3.1 数据集MOCOD
在MOCOD数据集上对改进后Focal Loss测试不同γ对mAP的影响,见表1。
在MOCOD数据集上对CARAFE测试不同Kup和Kencoder对mAP的影响,见表2。
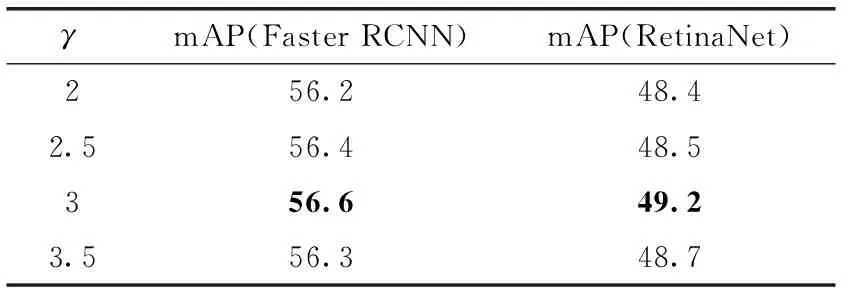
表1 MOCOD数据集上不同γ对于mAP的影响
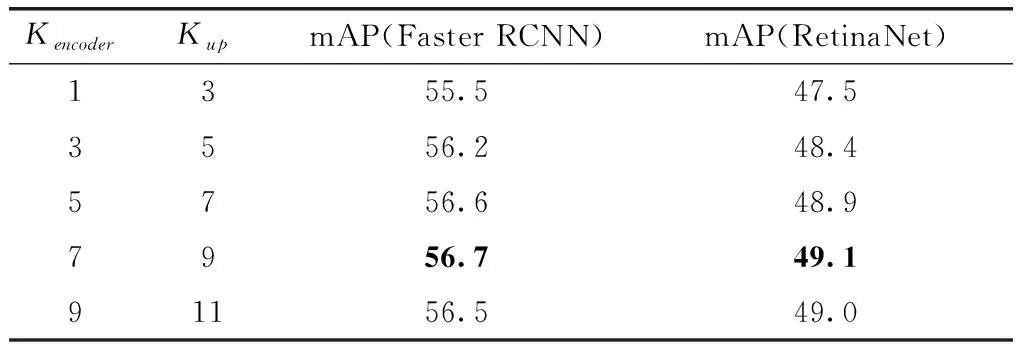
表2 MOCOD数据集上不同的Kup,Kencoder对于mAP的影响
从表1中可以看出,适当增大γ, 进一步缓解了小目标中的样本不平衡问题,相对于默认的γ=2,γ=3时在两种方法中对于小目标的检测是更有帮助的。
从表2中可以看出,适当增大Kup和Kencoder可以有效提升CARAFE上采样过程中上采样核和对应点积特征图的分辨率,相对于默认的Kup=5,Kencoder=3, 小目标检测情况下Kup=9,Kencoder=7的时候检测效果更优。
(2)稻作产业缺乏品牌,且售价低廉,无额外附加值,且土地多质次,病虫害影响较大,约占当年产量的20%~30%。
表3是加入相应因素后的测试结果,随着不同部分的加入,mAP得到了稳定的提升,其中Focal Loss的加入和anchor的设计改动对检测速度FPS几乎没有影响,更多参数量的CARAFE上采样算子使FPS略微降低约1个点;同时表3中也在更深的ResNet上进行了实验,mAP同样得到了进一步提升,验证了在加入各种因素后整体模型的稳定性。
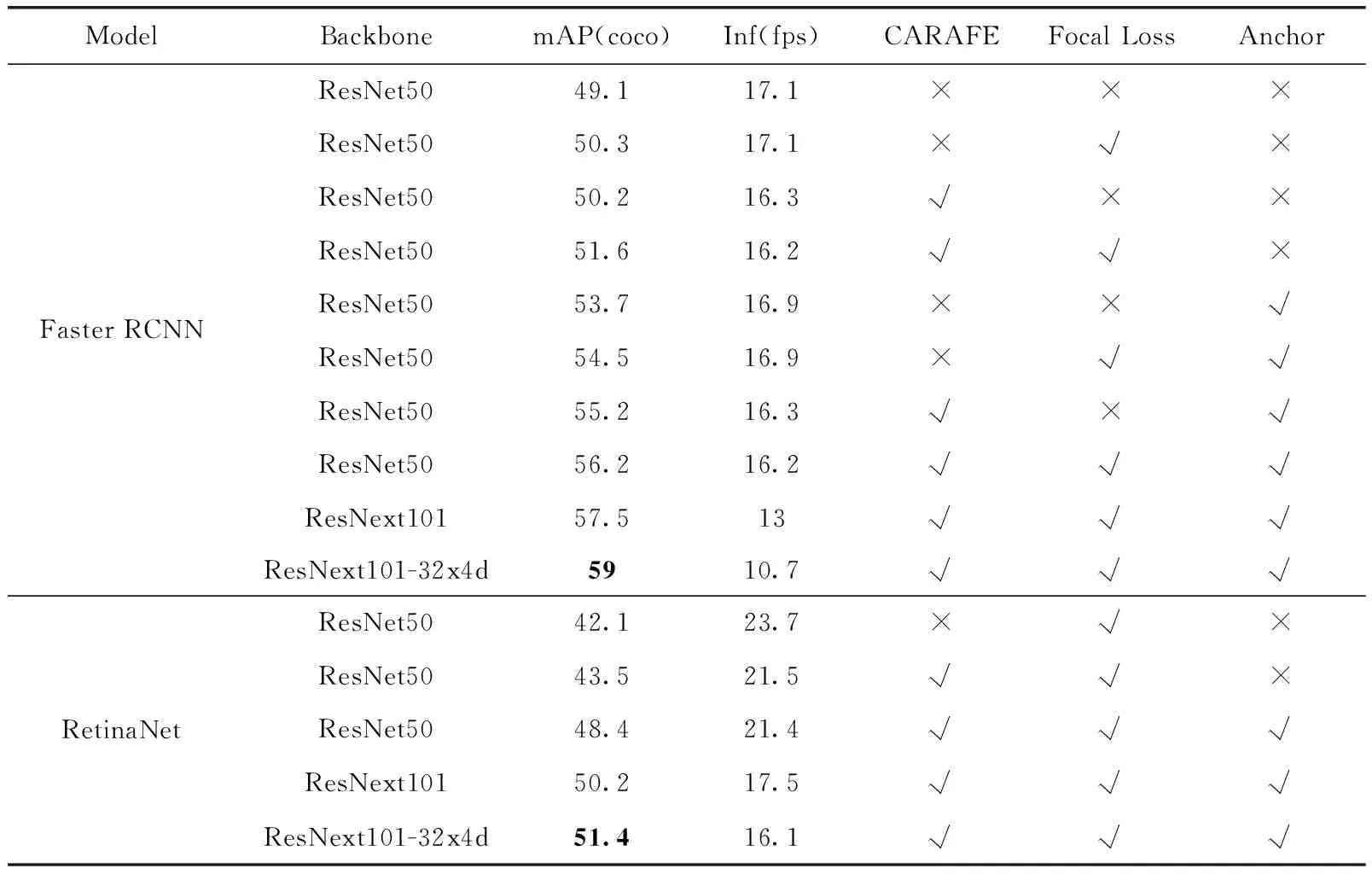
表3 默认方法基础上加入Focal Loss、CARAFE和anchor设计以及在不同网络深度下的实验结果
表4则是进行相应改进后的实验结果,在损失少量检测速度的情况下,可以看到相较于改进前检测精度mAP有了很大提升,其中CHRNet带来的精度提升最高,Faster RCNN中提升了3.6个百分点,RetinaNet中提升了4.1个百分点。
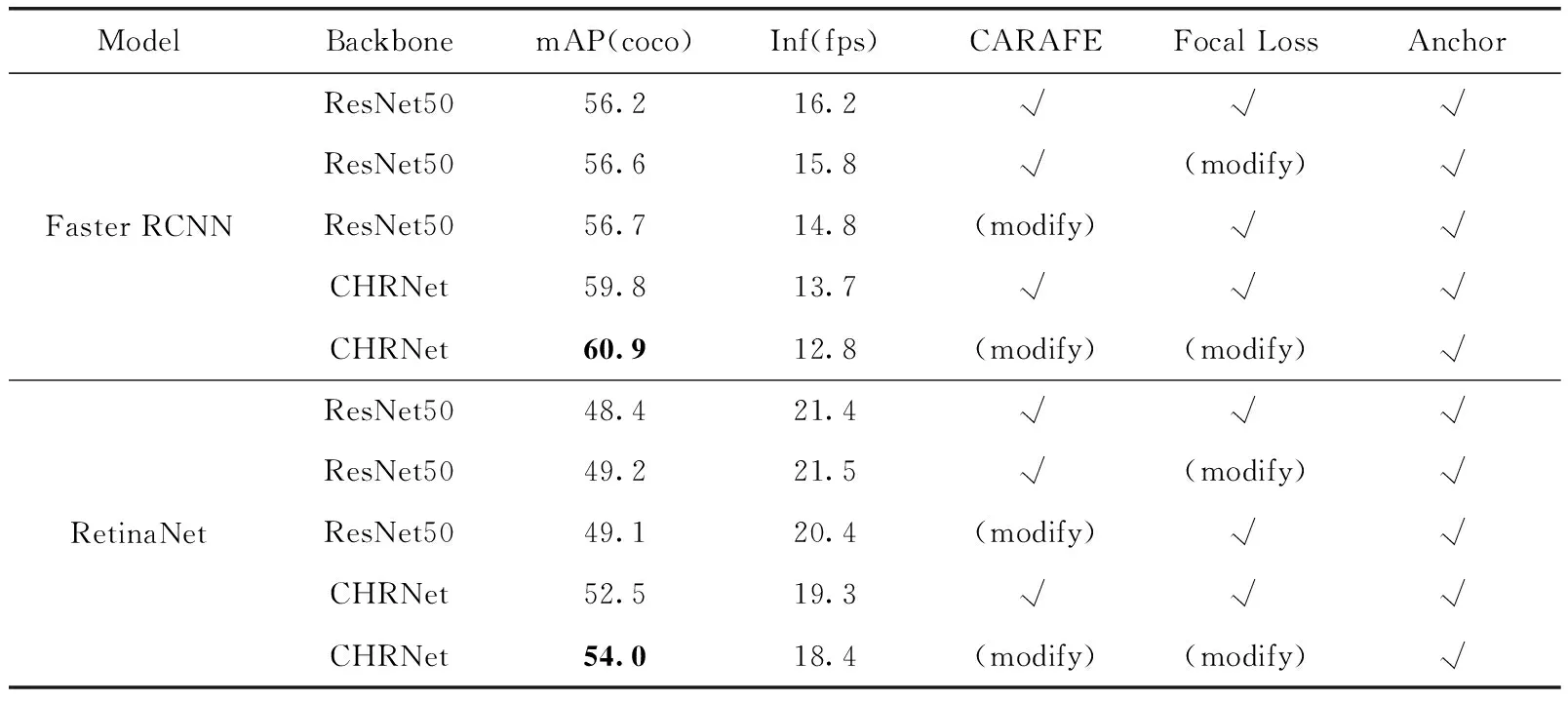
表4 加入上述3种因素且分别进行相应改进后的实验结果
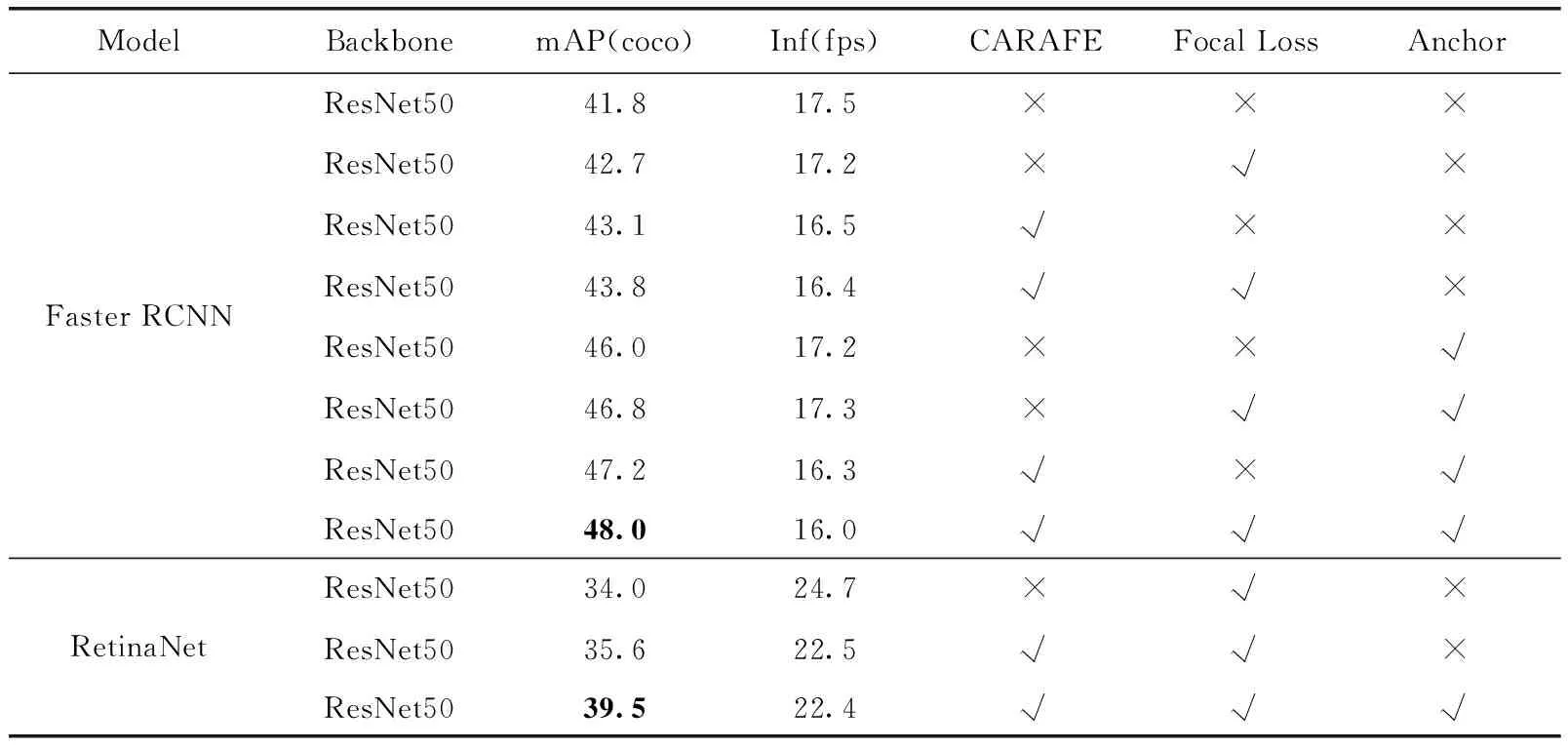
表5 默认方法基础上加入Focal Loss、CARAFE和anchor设计后的实验结果
4.3.2 数据集VEDAI
由表5和表6可以看出,在加入各种因素以及进行相应改进后,mAP同样有稳定的提升,和MOCOD的数据集上的实验结果相似。由表6中可以看到,CHRNet带来的提升最大,Faster RCNN中提升了4.1个百分点,RetinaNet中提升了3.6个百分点。
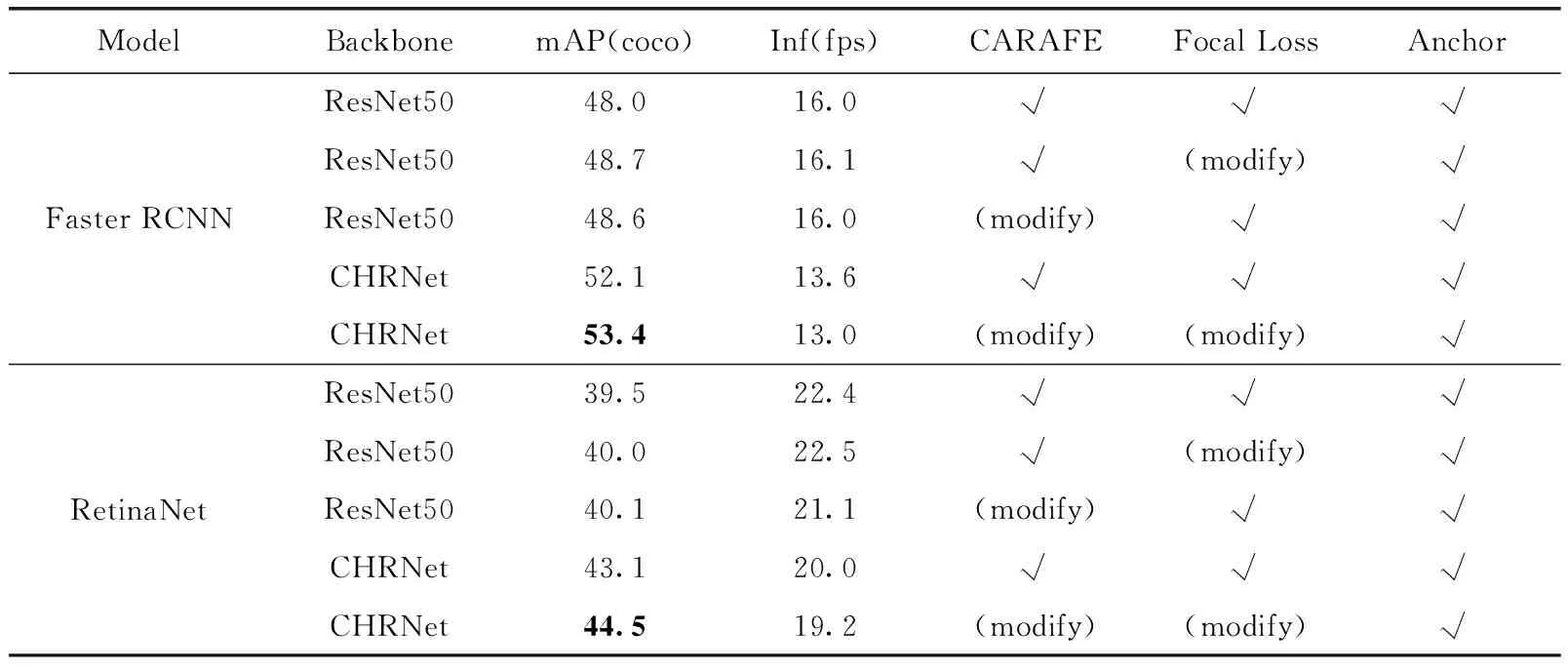
表6 加入上述3种因素且分别进行相应改进后的实验结果
从以上实验结果可以看出,在Faster RCNN的RPN阶段用Focal Loss代替默认的交叉熵损失的时候,mAP有1个百分点左右的提升,Focal Loss改进后均有0.6个百分点左右的提升,对检测速度FPS几乎没有影响;加入CARAFE时,mAP均有1个百分点左右的提升,改进后均有0.5个百分点左右的提升,同时检测速度FPS略微降低约1个点;加入提出的特征提取模块CHRNet后,mAP有3.8个百分点左右的提升,同时检测速度FPS小幅降低2个点左右;加入合适的anchor设计后,mAP均有5个百分
点左右的提升,对检测速度几乎没有影响。
图2是应用CHRNet后在不同数据集上的部分检测结果。

图2 不同数据集的检测结果

图3 应用CHRNet前后部分检测结果
从上面不同数据集的部分检测结果示例图和应用前后对比图中可以直观看出,应用CHRNet后,检测结果的置信度整体上得到了提高,同时漏检等情况也得到了改善,说明在检测过程中特征信息损失减少,对于目标的分类更加准确,进而有效提高了小目标检测的精度。
综合考虑,本文的研究对于提升小目标检测性能有一定帮助,同时自己的一些改进也是有不错效果,特别是合适的anchor设计和提出的特征提取模块CHRNet带来的提升最大。
5 结束语
本文针对小目标检测问题,从减少特征信息损失这个主要影响因素着手,同时针对样本不平衡问题也进行一定改进,并结合合适的anchor设计,在常用的单阶段方法RetinaNet和两阶段方法Faster RCNN进行了实验;针对特征信息损失问题,在特征图处理过程中,通过设计合适的特征图融合方式以及采用越来越有效的上采样方法,结合HRNet和CARAFE上采样算子的设计思想,在保证一定计算效率的条件下设计了一个具有高表征能力的特征提取模块CHRNet,同时对CARAFE上采样算子进行了针对性调优;针对样本不平衡问题,对Focal Loss进行了改进调整,同时对关键参数γ进行了实验调优;在两个符合小目标条件的数据集上进行了相关实验,结果表明,本文的改进在一定程度兼顾检测速度的条件下有效提升了小目标检测的精度,在COCO数据集标准下相对于默认方法mAP均有约10个百分点的提升,其中本文的改进有约4.5个百分点(不包括anchor设计),CHRNet带来的提升约占80%。
未来将考虑从以下方向来进一步研究改进:一是尝试将简单有效的Focal Loss结合其它方法进一步缓解小目标检测中更突出的样本不平衡问题;二是考虑进一步改进CHRNet模块使得对检测精度的提升更大,对检测速度的影响更小;三是考虑结合更优秀的目标检测方法,从整体方法上改善;从而进一步提升小目标检测的性能。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化·高一版(2021年2期)2021-03-19
数学物理学报(2019年3期)2019-07-23
今日农业(2019年15期)2019-01-03
家庭影院技术(2018年9期)2018-11-02
知识经济·中国直销(2018年8期)2018-08-23
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
