
基于卷积神经网络的农作物病理图像分类算法研究
2021-05-19 12:00刘帅君寇旭鹏莫雪峰
湖北农业科学 2021年9期
刘帅君,寇旭鹏,何 颖,莫雪峰
(云南农业大学大数据学院/云南省信息技术发展中心,昆明 650000)
农业作为中国的重要产业,农作物的产量和质量影响着人民的日常生活。加大农业发展,实现精细化,提高农业智能化、科学化,是农业管理的必经之路,也是中国从传统农业大国走向现代化农业大国的选择。农作物在生长过程中,仍然避免不了病害的威胁,这也是影响农作物收成的原因。为此,实现对农作物病理的快速分类和初步诊断,并针对病理及时做出有效的处理,对农作物增收具有重大意义[1-3]。
在最初的农作物生产管理过程中,只能靠相关领域的专家来到田间进行检查,才能做出判断,查清病理原因,不仅耗费大量的人力和物力,而且需要具有相关领域知识的农业从业者对农作物进行监控。随着计算机图像识别技术的飞速发展,传统机器学习方法在病理识别上表现出较大的优势,以提取病理图像的色泽、光谱、外形等特征为技术特点,例如随机森林(Random forest,RF)、支持向量机(Support vector machine,SVM)算法等[4-7]。虽然传统机器学习方法准确率较高,但也存在一些技术难点,如需要人为手工设计特征,过程较复杂。
随着计算能力提升、大数据时代的到来,使得深度学习算法在非结构化数据上具有较大的应用空间[8,9]。卷积神经网络(Convolution neural network)的快速发展进一步为深度学习在图像识别领域的应用提速。2012 年Alexnet 取得了Imagenet 图像分类竞赛的冠军,是深度学习崛起的标志[10,11]。随后几年 GoogleNet[12]、VGGNet[13]、ResNet[14]等算法提升了图像分类的精度,并在多个领域成功应用。农作物病理图像分类在深度学习算法的帮助下同样取得了较大的突破。而在中国农作物病理识别领域,基于深度学习的农作物病理分类在国内目前还处于起步阶段。刘阗宇等[15]采用Faster-RCNN 方法识别葡萄叶片病斑位置并进行分类识别,提出的模型对病理检测的准确率最高可达75.52%,但该方法由于需要生成大量的锚框使模型较大且速度较慢。曹鹏[16]针对样本不平衡问题,吴国琴[17]通过迁移学习的方法,龙明盛[18]将卷积神经网络算法应用于农作物病虫害识别中,所提出模型准确率均达85% 以上。但进行迁移学习的前提是有相似分布的类别数据集。
本研究提出一种基于卷积神经网络的农作物病理图像分类算法,通过特征增强缓解数据不平衡[19]的问题,同时采用特征融合增强信息传播,使模型在农作物病理分类任务上的准确性与鲁棒性得到提升。
1 农作物病理分类模型
1.1 模型结构
在农作物病理分类任务中,从属于同一类别的病理往往差异性较大,如番茄早疫病和晚疫病,二者存在较大的外观差异但却属于同一类别,这会给分类器的判别增加一定的难度。此外,随着网络层数的加深,单一的图像特征会丢失某些区域的信息,从而导致模型的分类性能变差。针对这一问题,研究使用多次卷积池化并增加BatchNorm 操作以及多尺度的特征融合机制获得不同尺寸的特征来提高模型的表征能力[20]。如图 1 所示,模型将第 10、11、12 层卷积操作提取到的特征归一化后进行总体融合。利用不同尺度的特征信息,避免信息的丢失,从而进一步提升模型的鲁棒性[21]。BatchNorm 层使模型加速收敛,并得到更高的性能。
1.2 数据增强
农作物病理的常见图像朝向、亮度、角度均不同,这对农作物病理分类识别造成了一定的困难。同时不同种类的同类病理以及同种作物的不同病理所包含的图像数量不一致。由于部分种类图像数量较少,而识别的效果取决于数据的多少,所以,为了使模型的泛化能力和鲁棒性得到提高,模型对训练样本进行了数据增强操作,包括随机旋转、水平翻转、随机裁剪等[22]。
1.3 损失函数
模型采用Softmax 函数转换分类器输出标准概率分布的预测值[23]。它将多个神经元的输出缩放到(0,1)范围内,再进行多分类任务。其中V代表一个数组,Vi表示V中的第i个元素。模型使用多分类Cross-Entropy(交叉熵)函数来度量与正确类别标签之间的损失。Softmax 函数如下。
Loss损失函数如下。
式中,x为模型预测的分类概率,x向量的第j维,即xj是输入图像预测为j类的概率,k为输入图像的真实类别索引。
2 设计与分析
2.1 试验环境
试验在16.04.6 LTS 系统下,利用Python 语言,Keras深度学习框架完成。硬件环境为Intel(R)Xeon(R)CPU E5-2689 的处理器,显卡为Nvidia Geforce RTX 2080Ti。模型采用带动量的随机梯度下降法进行优化,具体的模型参数设置如表1 所示。

表1 模型参数设置
2.2 数据集
采用2020 年10 月Kaggle 公开植物病理数据集Plant Diagnosis Data,该数据集已全部标注类别,包括胡椒、土豆、番茄共3 个大类别,每个大类下又包含若干子类别,合计15 个小类别,共计20 639 张图片。具体数据集情况如表2 所示。试验采用8∶2 的比例划分数据集。8 份用作训练数据,其余2 份用作测试数据。数据图片如图2 所示。
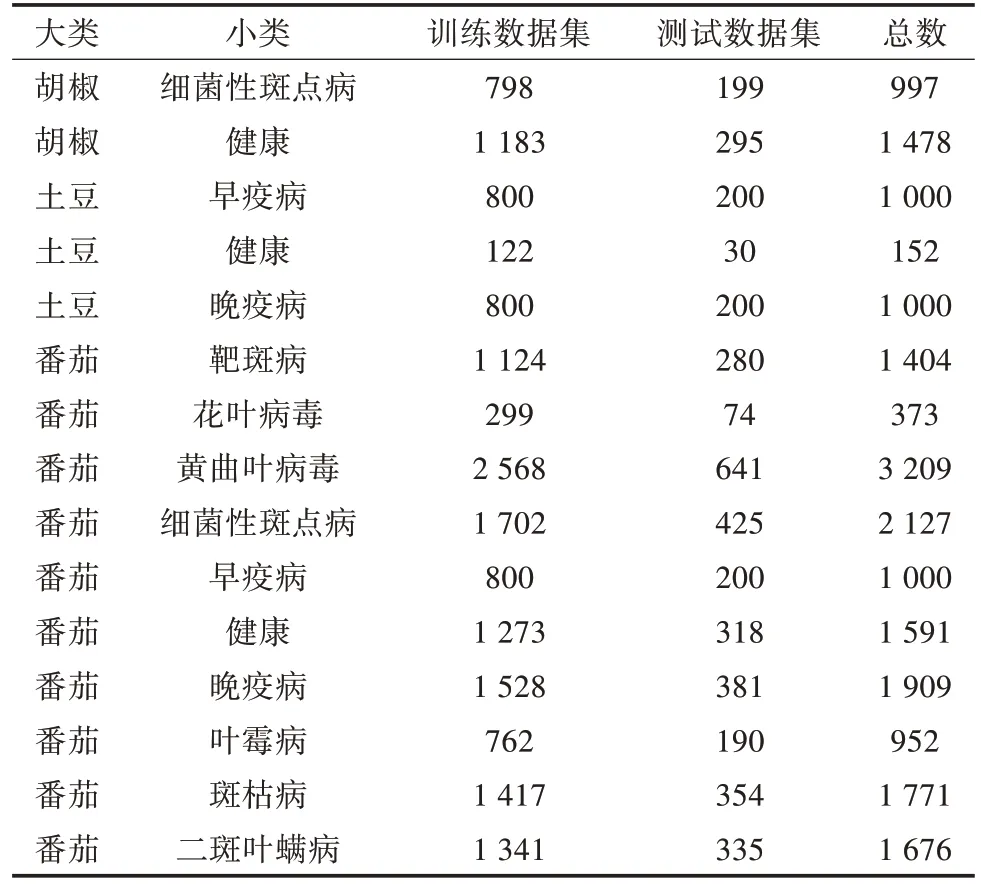
表2 Plant Diagnosis Data 数据集
2.3 评价指标
使用图像分类任务中常用的评价指标:精确率(Precision)、召回率(Recall)和准确率(Accuracy)。表3 是通过混淆矩阵(Confusion Matrix)来说明分类任务。TP(True Positive)表示将正类预测为正类,模型实际预测的样本正类数量。FN(False Negative)表示将正类预测为负类,模型实际预测的样本负类数量。FP(False Positive)表示将负类预测为正类,模型实际预测的样本正类数量。TN(True Negative)表示将负类预测为负类,模型实际预测的样本负类数量。

表3 分类混淆矩阵说明
召回率的定义:真正正确的占所有实际为正的比例。其计算公式如下。
精确率的定义:真正正确的占所有预测为正的比例。其计算公式如下。
2.4 模型对比
研究中的算法是在深度学习框架TensorFlow、Keras 平台实现,用Python 语言进行编程。在模型数据输入阶段,对图像数据进行了数据增强,包括水平翻转、随即缩放、亮度增强等。同时在输入时将图像统一缩放到256×256 大小使其符合模型网络要求。试验在农作物病理各类别识别率、精确率、召回率以及迭代次数对识别率的影响做了详细研究。
2.4.1 不同模型的效果对比 研究提出的框架使用Plant Diagnose Data 集中80%的数据进行训练,然后再使用20%的数据进行测试。为了进一步验证本研究提出模型的有效性与优越性,在测试集中与目前已有的主流框架模型进行对比。其中,VGG16 和VGG19 均为经典VGG 模型结构,只是网络深度不一样。更深的网络能够提取更深层抽象的信息,但也会造成大量抽取信息的丢失。由表4 可知,本研究提出的框架相比目前几种较为流行的方法,得到了最高的分类准确率(94.92%)、最高的精确率(95.34%)以及最高的召回率(94.43%),且支持端到端的病理图像分类,不需要进行其余操作。而AlexNet、VGG16 和 VGG19 模型的分类准确率分别是88.23%、86.67%、87.04%。表明提出的农作物病理分类网络在准确率、精确率、召回率上均优于其他对比模型,能有效完成分类任务。

表4 不同模型效果对比 (单位:%)
2.4.2 不同迭代次数的影响 图3 为MFCPNet 算法在Plant Diagnose Data 上的效果曲线。在保证其他参数不变的情况下,将迭代周期设置为20 次。图3清楚地显示了随样本迭代次数增长各项指标的变化趋势。横轴表示迭代次数,而纵轴表示准确率、Pre⁃cision、Recall、Loss 值。随着迭代次数的增加,Loss值在逐渐下降,其他三项评价标准在逐渐上升并趋于平稳。由于显存限制,模型Batchsize 较小,在模型训练过程中反向传播方向不明确,因此,曲线有一定幅度的振荡。MFCPNet 算法在不同分辨率、不同类型的农作物病理数据集上都达到了最佳效果,证明模型具有较高的鲁棒性和泛化性。随着迭代次数的増加,模型的整体识别准确率呈增加的趋势,在迭代10 次后,模型的准确率己经达到90.2%。结合图3 所示曲线及各项评价指标证明该模型有效。
3 结论
为了解决传统机器学习算法在病理识别上存在的准确率偏低、特征工程构建复杂的问题,通过深度学习构建了一种基于卷积神经网络算法的农作物病理识别模型MFCPNet。该网络通过设计神经网络的卷积结构提取图像的特征后,对全连接层使用BP算法进行训练,不断进行优化,从而得到最优权重参数,最终病理图像的准确识别得以实现。所提出的模型对病理图像特征具有较强的表征能力,在Plant Diagnosis Data 取得了94.92%的准确率,相较于现有的VGG16 算法提升了8.25 个百分点,能够满足实际的应用需求,具有良好的应用前景。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
今日农业(2021年16期)2021-11-26
医学食疗与健康(2021年27期)2021-05-13
中国交通信息化(2018年5期)2018-08-21
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
