
基于数据挖掘的个性化旅游推荐系统研究与实现
2021-05-19 12:00欧丹
湖北农业科学 2021年9期
欧 丹
(四川信息职业技术学院消费者行为研究中心,四川 广元 628000)
智慧旅游[1]的概念最近受到学术界和实践者的广泛关注。该概念旨在通过发展互联网、通信、大数据等技术为基础,加快服务创新,改善旅游体验,增强目的地竞争力。特别是随着社交网络不断发展,大量用户在网上分享自己的旅游体验,照片和视频在网络信息中占有很大的比例,并且在不断添加或更新,这为多媒体、数据挖掘以及地理相关的研究和应用提供了新的研究机遇和挑战[2]。
近几年来,基于数据挖掘的个性化推荐一直是一个热门研究课题,备受国内外学者广泛关注。孟祥武等[3]对大数据环境下的推荐系统关键技术、效用评价以及应用实践等进行了概括、比较和分析,并对大数据环境下推荐系统有待深入研究的难点和发展趋势进行了展望。李杰等[4]提出了适用于个性化推荐的强关联规则,并给出一种基于矩阵的强关联规则挖掘算法,避免了对冗余规则的挖掘,从而提高了挖掘效率。徐国虎等[5]分析了大数据环境下的O2O 电商用户数据特征,提出O2O 电商用户数据挖掘框架。刘树栋等[6]从分析基于位置的社会化网络的结构特征入手,对基于位置的社会化网络推荐系统的基本框架、基于不同网络层次数据挖掘的推荐方法及应用类型等进行概括、比较和分析。
然而在旅游推荐的媒体数据(例如照片)不仅包含诸如标签、标题、注释和描述之类的文本信息,而且还被标记为拍摄照片的时间上下文(即拍摄照片的时间)和空间上下文(即以纬度和经度表示的位置)。
为此,主要研究了基于地理标记照片的上下文感知的个性化推荐系统,该结构能够实现地理标记的社交媒体处理语义上有意义的个性化旅游地点推荐的动态查询。
1 基础知识
在介绍个性化旅游推荐系统之前,先给出一些基本概念和术语。
定义1:(地理标记照片)地理标记照片p可以定义为p=(id,t,g,X,u),其中id为照片的惟一标识。g为地理标记,表示照片的拍摄地理区域。t为时间戳。u为贡献照片的用户标识。每个照片p可以用一组文本标记X进行注释。
定义2:(照片集合)所有游客贡献的照片集合可表示为P={P1,P2,…,Pu,…,Pn} ,其中Pu是用户u提供的照片集合。
定义3:(位置)位置l表示热点旅游或景点的地理区域,例如公园、湖泊或博物馆等。
定义4:(上下文感知查询)上下文感知查询Q定义为Q=(t,w),t表示时间上下文,w表示天气上下文。
基于数据挖掘的个性化旅游推荐系统旨在根据用户给定的地理标记照片集合,定位和总结旅游地点,并建立每个用户的旅游历史,以获得其旅游偏好,从而进行上下文感知的个性化查询,推荐最适合其兴趣的旅游地点。
2 个性化旅游推荐系统
2.1 系统体系架构
个性化旅游推荐系统架构如图1 所示。通过利用照片的空间位置来寻找旅游地点,并结合Web 服务提供的信息,对照片进行注释的文本标记来丰富聚集地点的语义注释。进一步,利用地理标签和带有照片注释的时间标签获得时间上下文信息。同时,通过查询第三方天气Web 服务检索天气状况获得天气上下文信息。接着,通过绘制用户和旅游景点之间的关系来模拟用户的出行偏好。然后,利用这些用户的偏好来估计用户之间的相似度。为了提供个性化推荐,研究首先根据上下文约束过滤位置,然后根据个性化得分对位置进行排序。
2.2 识别旅游地点
从地理标记照片集合中识别旅游地点是一个典型的聚类问题。给定一组照片P,本研究使用PDBSCAN[7]对照片进行聚类,根据照片的地理标签来识别旅游地点。P-DBSCAN 的输出是一组位置(照片簇)L={l1,l2,…,ln} 。每个元素l={Pl,gl} ,其中Pl是一组地理上聚集的照片,gl表示照片的簇Pl的质心地理坐标。
2.3 位置的语义标注
利用基于空间邻近度的聚类算法识别出的旅游景点,可以在用户UI界面上进行可视化显示。为了给出位置的语义标注,研究提供了一种新方法,该方法使用文本标签对照片进行注释,并结合在线Web 服务提供的信息,自动生成每个旅游地点的文本描述。
2.4 分析位置
当完成利用照片的空间邻近性对照片进行聚类,找到旅游景点,并对景点进行语义标注后,接下来将对位置进行分析,从而建立旅游景点概况和偏好旅游景点数据库。
首先从不同用户在旅游景点拍摄的照片中识别用户的位置信息。对于每个位置l∈L,根据每个用户u的照片拍摄时间对照片进行排序。时间t时,用户u在位置l拍摄的照片p记为用户访问v。注意,用户u可在同一v中在同一位置拍摄多张照片。因此,如果同一用户在同一地点拍摄的2张照片(p2.t-p1.t)的时间戳之差小于访问持续时间阈值Tv,则认为这两张照片属于同一次访问。此外,将与照片相关的时间戳中位数记为用户的某次访问时间v.t。
2.5 相似性分析
在识别不同用户对不同地点的访问后,接着建立了一个地点数据库LDB={l1,l2,…,ln} ,其中每个位置li={Vli,pop(w),pop(t)} ,Vli是不同用户对位置li的访问,pop(w)是天气上下文信息,pop(t)是位置li的时间上下文信息。
为了描述用户群U对一组位置L的兴趣程度,构建了用户U和位置L之间的链接(即访问集V),这一过程可描述为一个无向图GUL,定义为式(1)。
式中,U和L分别表示用户集合和位置集合的节点。EUL和WUL是U和L之间的边和边权重的集合,表示用户的访问量和访问特定位置的次数。
在给定m个用户和n个位置的情况下,构造了图GUL的m×n邻接矩阵MUL。
式中,vij表示第i个用户访问第j个位置的次数。
在邻接矩阵MUL中,用户up的旅游兴趣可以记为数组Rp=
进一步,根据用户的旅游偏好计算用户之间的相似度,并构建用户相似度矩阵MUU。
式中,sim(up,uq)为用户up和uq的相似性程度,计算公式如式(4)所示。该值越大意味着两个用户在出行偏好方面更为相似。
3 推荐过程
令某次查询记为Q=(t,w)。个性化旅游推荐过程可总结如下。首先,需要使用时态上下文概念抽象时态上下文t,使用天气上下文概念抽象天气上下文w。其次,从满足查询中给定的上下文约束的位置数据库检索目标城市的位置,从而生成一组过滤后的旅游位置L。再次,利用用户偏好的用户-位置矩阵MUL和表示用户之间相似性的MUU进行个性化推荐。从MUU中,系统将检索访问过目标城市的N个最相似用户U′之间的相似度,并利用公式(5)从L中预测每个位置li的偏好。主要采用了协同过滤算法[8],将推荐用户一些过去有相似品味和偏好的人喜欢的旅游景点。
接着,使用用户up和uq之间的相似度sim(up,uq)作为权重来计算每个位置li的排名分数。因此,up和uq越相似,rqi在li预测中的权重就越大。最后,在计算用户对L中每个位置li的偏好后,根据偏好得分对位置进行排序,并返回k个位置作为查询结果。
4 仿真与分析
为了衡量系统的性能,使用了精确度、召回率、F1 分数和平均精度(MAP)等指标。
表1 为本文方法与传统数据挖掘Apriori、Eclat、决策树及逻辑回归等算法的比较。由表1 可以看出,所有模型都会随着推荐列表的增加,精确度下降,召回率上升,且本文方法模型优于其他方法,实现了53%的F1 和74%的MAP,而最差的是Apriori方法达到了48%的F1和58%的MAP,二者之间MAP相差16 个百分点。
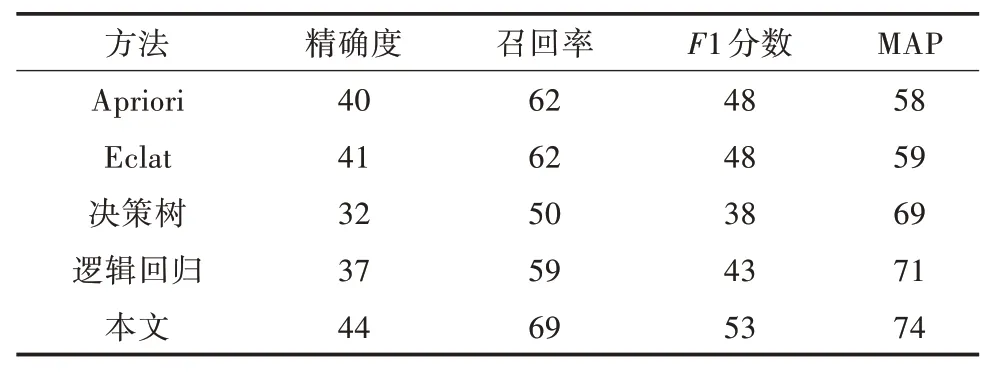
表1 网络安全验证包的比较 (单位:%)
本研究进一步考虑了标签向量的维数。根据标签向量的大小将测试数据集分为6 组,每组用相应大小的项集建议进行评估。图2 为最终测试结果。由图2 可以看出,本文方法、逻辑回归和决策树方法基本上都优于Apriori 和Eclat 算法。本文方法最终平均推荐准确率能够达到80%左右。
5 小结
研究了数据挖掘中个性化旅游推荐问题,并提出利用多媒体、数据挖掘以及地理信息相关技术实现满足时间上下文及空间上下文的个性化旅游推荐系统。此外,还提出了一种根据用户的当前情境对旅游地进行过滤,然后以协同过滤的方式对旅游地进行排序,从而进行个性化推荐的方法。
猜你喜欢
新闻传播(2018年12期)2018-09-19
电力与能源(2017年6期)2017-05-14
汽车与新动力(2016年6期)2017-01-04
信息通信技术(2015年6期)2015-12-26
中国卫生(2015年1期)2015-01-22
首都外语论坛(2014年1期)2014-03-20
电子设计工程(2014年18期)2014-02-27
