
基于深度学习的快速QTMT 划分
2021-05-17 08:00彭双王晓东彭宗举陈芬
电信科学 2021年4期
彭双,王晓东,彭宗举,,陈芬
(1. 宁波大学信息科学与工程学院,浙江 宁波 315211;2. 重庆理工大学电气与电子学院,重庆 400054)
1 引言
随着超高清、高动态、宽色域和全景视频等技术的出现,高效视频编码(high efficiency vi2eo co2ing,HEVC)[1]的压缩效率明显不足,因而多功能视频编码(versatile vi2eo co2ing,VVC)[2]被提出。在相同客观质量条件下,VVC 的比特率约为 HEVC 的 50%。嵌套多类树的四叉树(qua2tree with neste2 multi-type tree,QTMT)[3]划分结构是VVC 编码增益提高的关键[4],但同时带来了编码复杂度的急剧上升。在帧内配置模式下,VVC 编码复杂度约为HEVC 的18 倍[5]。此外,与之前编码标准中帧内编码复杂度远低于帧间编码不同,VVC 中帧内编码复杂度却高于帧间编码,前者约为后者的1.3 倍[6]。因此,降低VVC帧内编码复杂度具有重要意义。
目前已有许多学者对HEVC 和VVC 低复杂度编码进行了研究。研究方法主要分为基于统计和基于学习的方法。在基于统计的快速编码算法中,姚英彪等[7]结合空域相关性和纹理信息提出了快速划分方法。Kuo 等[8]提出一种基于时空域编码单元(co2ing unit,CU)的决策方法,利用已编码相邻编码树单元(co2ing tree unit,CTU)和同位CTU 深度信息,加权预测当前CTU 的深度范围。Jamali 等[9]利用绝对变换残差和(sum of absolute transforme2 2ifference,SATD)代价对率失真代价(rate-2istortion cost,RDC)进行估计,从而减少进行率失真优化(rate 2istortion optimization,RDO)的模式,同时将预测的RDC 建模为正态分布,通过置信区间进一步改进预测效果。Huang 等[10]为平衡率失真(rate 2istortion,RD)性能与编码时间,通过优化率失真复杂度对编码模式进行决策,其中,RD 性能和编码时间通过提取特征来估计。参考文献[8,10]虽然能有效降低编码复杂度,但仅针对HEVC 中QT 划分进行决策,对VVC 编码中QTMT 划分并不适用。Lei 等[11]通过简化粗选模式决策估计不同划分方向的SATD 代价,将子CU 不同划分方向的RDC 作为当前CU 的估计代价,最后根据估计的SATD 代价和RDC 综合决定当前CU 的最优划分方向。Chen 等[12]和Fan 等[13]通过提取方差和梯度特征,对特征设定阈值来决策提前终止和跳过不可能的模式,最终仅对一个模式进行RDO,极大降低了编码复杂度。Park 等[14-15]利用中间编码信息对跳过模式和终止运动估计进行决策。在参考文献[14]中,通过对三叉树划分进行统计分析,提出将已编码CU 代价作为概率决策特征,从而决定是否跳过三叉树划分。在参考文献[15]中,利用已编码CU 的最佳模式对终止仿射运动估计进行决策,利用运动矢量方向缩减仿射运动参考帧的数量。参考文献[12-13]仅在单一的CU 级实施决策,参考文献[14]仅跳过三叉树划分,而参考文献[15]仅对仿射运动估计进行决策,以上方法节省的时间都非常有限。
在基于学习的快速编码算法中,Liu 等[16]改进了传统复杂度特征并作为分类器输入,通过两个支持向量机分类器将CU 分为3 类,并且利用惩罚因子平衡性能损失与时间复杂度。Chen 等[17]引入非对称卷积核来提高特征提取能力,通过置信区间平衡复杂度与性能损失,极大降低了HEVC 编码复杂度,同时,通过预测最小RDO 候选模式数量来加速模式决策过程。Katayama 等[18]充分利用了CU 的空域相关性,将相邻CU 亮度信息作为卷积神经网络(convolutional neural network,CNN)的输入,实现了HEVC 低复杂度帧内编码,但不利于硬件编码。Kim 等[19]建立了基于CNN 的多级二分类模型来决策CU 划分,将CU 亮度信息作为模型的输入,并将编码的中间信息作为外部特征输入模型。Xu 等[20]建立了分层CU 划分映射来描述CTU 的划分情况,提出了提前终止的分层CNN 模型,在保证编码性能的前提下显著降低了HEVC 帧内编码复杂度。Tang 等[21]将可变池化CNN 应用到VVC 帧内编码中,使得CNN 能适应不同形状的CU。然而,在池化层中丢失了特征信息,导致最终模型的预测结果较差。Yang 等[22]通过人工方式提取特征,将特征输入决策树模型进行训练,最终决定CU 是否划分。虽然决策树模型能充分挖掘出特征与划分之间的潜能,但特征选取受人为因素影响较大。Fu 等[23]利用了贝叶斯分类器,将是否跳过垂直模式建模为二分类问题,以当前CU、子CU 划分模式和角度模式作为分类器的输入。Amestoy 等[24]提出一种可调节的机器学习方法,通过调整风险区间的大小来控制VVC 的性能损失。参考文献[16,20]针对HEVC 均提出了有效的快速编码方案,对基于学习的VVC 快速编码方法具有一定的启发意义。参考文献[16,22,24]均通过人为选取特征,不能充分挖掘CU 的特征信息。
上述方法主要将划分决策建模为分类问题,而实际问题中分类边界通常不明确,因此本文将划分决策建模为回归问题。同时考虑到深度学习在编码各领域取得的突出效果[25],本文结合深度学习模型来预测划分模式的概率,提出了一种基于深度学习的快速VVC 划分决策方法。实验结果表明,所提出算法在保证编码性能几乎不损失的同时极大地降低了编码复杂度。
2 快速QTMT 划分方法
本文首先分析了QTMT 的复杂度,然后提出注意力−非对称卷积网络(attention asymmetric CNN,AA-CNN)结构来预测划分模式的概率,最后提出了基于AA-CNN 的快速模式决策模型。
2.1 QTMT 复杂度分析
VVC 中采用QTMT 结构使得CU 能适应不同图像内容。在VVC 编码过程中,每个CU 先按照四叉树(qua2 tree,QT)划分,再在QT 叶节点处按多类树(multi-type tree,MT)递归划分。MT 划分结构包括4 种划分模式,分别为垂直二叉树(vertical binary tree,VB)、水平二叉树(horizontal binary tree,HB)、垂直三叉树(vertical ternary tree,VT)和水平三叉树(horizontal ternary tree,HT)。除上述划分的模式以外,还有不划分的模式Intra,这些模式组成了QTMT 的划分模式列表(partition mo2e list,PML)。最优模式m*为PML 中RDC 最小的模式,计算式如下:
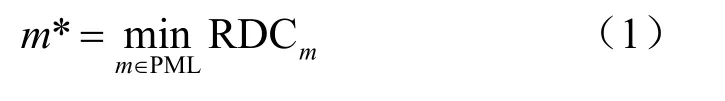
其中,PML={1,2,3,4,5,6},分别对应{Intra, QT, HB,VB, HT, VT},RDCm的计算式如下:

其中,Dm和Rm分别为编码模式m产生的失真和所需要的比特,λ为控制RD 性能的拉格朗日乘子。实际码流中仅模式m*被编码,因此QTMT 结构包括了大量冗余模式。虽然VVC 快速划分策略[26]能跳过部分划分模式,但仅对纹理较为平坦的区域有效。
2.2 划分模式概率预测
2.2.1 数据集构建
不完全的PML 会影响模式的真实分布,使得模型的预测准确率降低。本文建立训练数据集时,仅采用具有完整PML 的CU。从A1、A2、B、C、D 和E 6 类标准测试序列中分别挑选了序列Campfire、ParkRunning3、Cactus、BQMall、BasketballPass 和Johnny,每个序列选取60 000 个数据样本,其中大小为32×32 和16×16 的CU 各30 000 个,并利用3 次插值将16×16 的CU 上采样为32×32 的CU。数据集中样本分别用4 个量化参数(quatization parameter,QP) 22、27、32 和37进行编码,总样本数量为60 000×6×4=1 440 000,每个样本包括CU 亮度信息、CU 大小和QP,样本标签为CU 最优划分模式。数据集被随机地划分为训练集(9/10)和校验集(1/10)。
2.2.2 AA-CNN 结构
本文采用CNN 来预测划分模式的概率,结合MT 划分非对称性和特征重要性,提出了AA-CNN结构。MT 划分非对称性体现在子CU 形状非正方形,为提高非对称特征的提取能力,本文引入了非对称卷积核。注意力模块可实现特征通道[27]和卷积核[28]的权重分配,因此在本文中引入该模块。本文通过压缩原始图像来获取注意力,以便从全局控制特征权重的分配,如图1 所示,首先将32×32 的CU 展开为1×1 024 的向量,再通过1 024×128 和128×N两个维度逐渐减小的全连接层进行压缩得到1×N的注意力向量,其中N为被控制的特征向量通道数,并且QP 作为外部特征被加入全连接层,最后通过Softmax 函数进行激活。此外,为了加快模型的收敛速度,激活函数引入了参考文献[28]中所使用的温度控制,即对Softmax 函数的输入除以一个温度系数τ,τ随着训练次数发生改变。τ初始值为30,使得各特征权重相当,可有效加快收敛速度,随着训练次数的增加,τ逐渐减小,当τ=1 时激活函数退化为原始Softmax 函数。
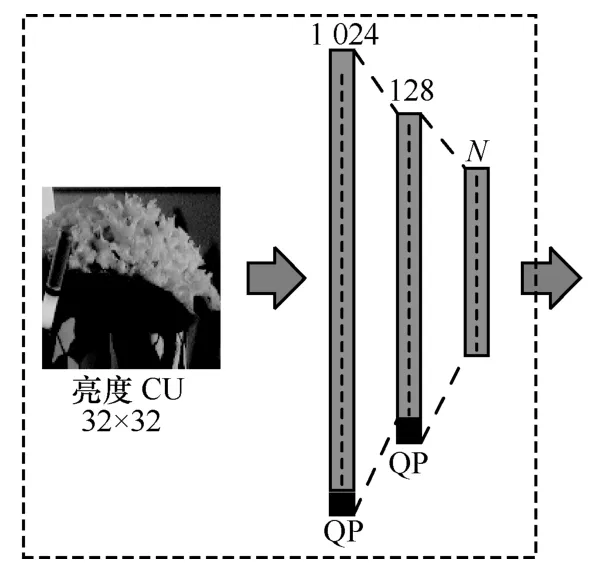
图1 注意力模块
本文设计的AA-CNN 结构如图2 所示,分为数据预处理、特征提取、特征拟合以及结果输出4 部分,具体如下。
(1)获取亮度CU 并将大小缩放至32×32,再进行归一化处理。
(2)该结构包括L1、L2 和L3 3 个非重叠卷积层,每层包含3 个分支,第一层各分支的卷积核大小分别为4×2、4×4 和2×4(滤波器数量为16),第二层和第三层各分支的卷积核大小均分别为2×1、2×2 和1×2(滤波器数量为24 和32)。与对称卷积核相比,非对称卷积核可以提取不同方向的特征,更加适应MT 划分。此外,通过压缩输入CU 获得注意力向量,再根据注意力向量对每个特征通道进行权重分配。每个注意力模块对应一个卷积模块,共9 个,分别为注意力1~9,该模块的引入可有效提高网络容量并消除特征冗余。
(3)将每个分支提取的特征展开并拼接为1×2 176的特征向量,然后通过3 个大小分别为2 176×128、128×96 和96×6 的全连接层L4、L5 和L6 进行特征拟合,并且在每个全连接层中将QP 作为外部特征加入特征向量。
(4)采用Softmax 函数激活预测值并输出1×6的预测概率向量,分别对应PML 中各模式为最优概率。
交叉熵用于度量两个概率分布间的差异性,差异越大交叉熵越大,反之越小。因此,本文采用交叉熵作为训练AA-CNN 的损失函数,计算式如下:
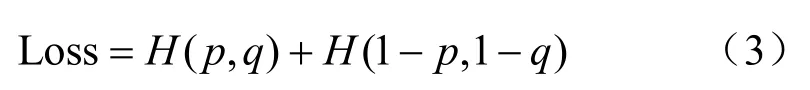
其中,H(.)为交叉熵运算符,p和q为预测和标签向量。
2.3 模式决策
2.3.1 快速模式决策
为有效平衡编码性能与时间,应在尽可能保留最优模式的情况下保留最少模式数量,本文所提出的快速模式决策流程如图3 所示。首先调用AA-CNN 模型得到预测概率向量p;再按概率对PML 进行降序排序,可表示为:

其中,L和p′分别为排序后的模式列表和预测向量;然后累加概率,并设定阈值φ确定最小保留模式数量n,计算式如下:


图2 AA-CNN 结构
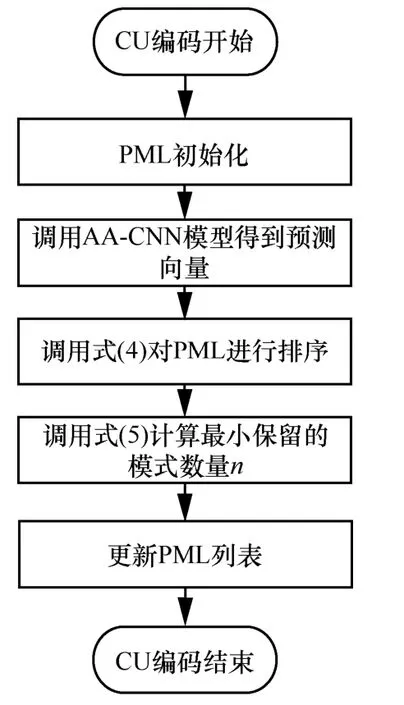
图3 快速模式决策流程
其中,x为可保留模式数量,pk′为p′中第k个元素;最后,根据n更新PML 为L′,L′={Li|1≤i≤n},Li为L中第i个元素。因此,本文提出的快速编码方法仅对n个模式进行RDO,n∈[1,6],极大地降低了编码复杂度,并可通过φ来控制性能的损失。
2.3.2 阈值决策
为选取最佳阈值φ*来平衡编码性能与时间,本文提出了性能与时间的代价函数。模型预测准确率α能表征编码性能,α越大则性能越高;L′的模式数量n能表征时间节省(time re2uction,TR),n越小则时间节省越多。因此,定义代价函数如下:
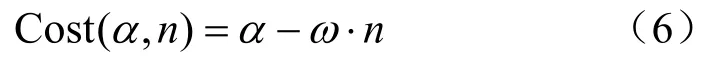
其中,ω为两者的平衡因子,当ω<1 时,可以节省更多的时间;当ω>1 时,性能更高。
α与φ直接相关,为建模二者的关系,本文在QP=32、CU 大小为32×32 的条件下对多个序列进行了统计分析。统计结果如图4 所示,随着φ增加,α也增加,其中实线通过线性拟合获得。显然,对于所有序列两者均符合线性关系。因此,本文建模α为关于φ的线性函数,计算式如下:

其中,μ和ν是与训练模型和图像相关的参数。
同理,本文对n与φ进行了统计分析。统计结果如图5 所示,随着φ增加,n的趋势呈现指数增长。因此,本文将n建模为关于φ的指数函数,指数函数有exp1 和exp2 两种类型,计算式
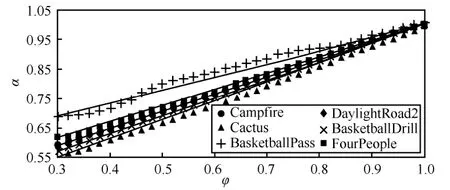
图4 α 随φ 的变化关系

图5 n 随φ 的变化关系
如下:
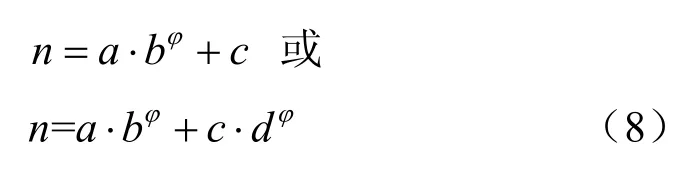
其中,a、b、c和d均为与模型和图像相关的参数。
此外,本文给出了每个模型的拟合系数R-square,见表1。对于α,线性函数具有非常高的拟合度;对于n,显然exp2 模型比exp1 模型拟合效果更好,本文选择exp2。

表1 R-square
因此代价函数改写为:

对于最佳阈值φ*的求解,令Cost(φ)′=0,得:

为估计式(10)中参数μ、a、b、c和d,本文考虑了序列的时域连续性。通过编码序列第一帧获得样本的预测向量和标签向量,进而计算得到不同阈值φ下的α及n,最后根据式(7)和式(8)即可求解参数,表2 为部分序列的参数。

表2 部分序列参数
3 实验结果与分析
3.1 实验配置
本文提出的算法在VVC 测试平台(VVC test mo2el,VTM)7.0[29]上实现,采用的学习模型在TensorFlow 平台上完成,测试条件采用标准测试配置中的全I 帧(all intra,AI)[30]。测试序列共22 个,包括了从类A1 到类E 的6 个类,其中A1和A2 为10 bit 超高清序列,类B 包括了10 bit 和8 bit 高清序列,类C~类F 为不同分辨率的8 bit序列。本文的算法性能通过BDBR[31]和平均时间节省ATR 进行测量,ATR 为不同QP 下TR 的均值,计算式如下:

其中,To(i)和Tp(i)分别表示在QP=i时原始平台和所提出算法的编码时间,Ω={22,27,32,37}。
3.2 实验结果
本文提出的快速决策算法可通过改变平衡因子ω将算法性能调整到不同档次。为了方便对比,本文通过探索发现ω=0.85 时算法性能与参考文献[11,23]的性能相似,ω=1 时算法的ATR 与参考文献[22-23]的ATR 相似。本文共给出了3 个不同档次的结果,见表3。其中,ω=∞(φ=0)为算法能达到最大时间节省点,“*”表示构建训练集时采用的序列。此外,实验结果还给出了各档次下BDBR 和ATR 的标准差STD,其大小可以反映该指标在不同序列下的稳定性。

表3 算法性能比较
实验结果表明,本文算法在略微损失RD 性能的条件下,编码时间节省最大能达到67.83%。同时,被用于训练模型的序列与其他序列的实验结果高度一致,这说明所提出算法具有良好的泛化能力。在ω=0.85、1、10 不同档次下,算法在不同序列下的ATR 均值分别达到48.62%、52.93%以及62.01%,性能损失分别为1.05%、1.33%以及2.38%。可见,在不同档次下,ATR 和BDBR 均可达到较好的平衡,随着档次值的提高,算法更倾向于时间节省,ATR 及其稳定性增加,这表明ATR 的增加是以牺牲RD 性能及稳定性为代价的。此外,本文算法对8 bit 深度序列的效果优于10 bit深度序列,因为10 bit 深度序列具有更微小的纹理细节,而在构建数据集时无法区分bit 深度,导致训练模型忽略了部分细节。
本文算法结果与Lei 等[11]、Yang 等[22]及Fu等[23]提出的算法结果进行了对比,对比数据见表3。结果表明,在ω=1 时,本文算法无论是时间节省还是RD 性能均优于Yang 等[22]提出的算法。同时,本文算法在相同时间节省情况下,RD 性能更加稳定,这是因为本文算法将模式决策建模为回归问题,通过设定阈值来实现划分模式决策,更易于控制时间节省与性能损失之间的平衡。因此,本文算法可以在节省相同时间的情况下,具有更优的RD 性能。在ω=0.85 时,通过与Lei 等[11]和Fu等[23]提出的算法结果对比可知,在具有相同RD性能的条件下,本文算法时间节省更多。Fu 等[23]提出的算法的时间节省与序列分辨率相关,分辨率越高时间节省越多,而本文算法除个别序列外均具有更好的时间节省和RD 性能。虽然Lei 等[11]提出的算法在稳定性和算法性能上能达到较好的平衡,但时间节省更少。
本文进一步分析了所提算法与VTM7.0 的性能比较,并给出了性能损失最大序列RitualDance和最小序列PartyScene 的RD 曲线,如图6 所示。对于RitualDance 序列,本文算法的最大性能损失仍能与原始平台保持一致,对于PartyScene 序列,本文算法与VTM7.0 的RD 曲线基本重合,表明本文算法的性能损失可以忽略不计。因此,本文算法能极大地降低编码复杂度,并且性能损失与原始平台基本保持一致。
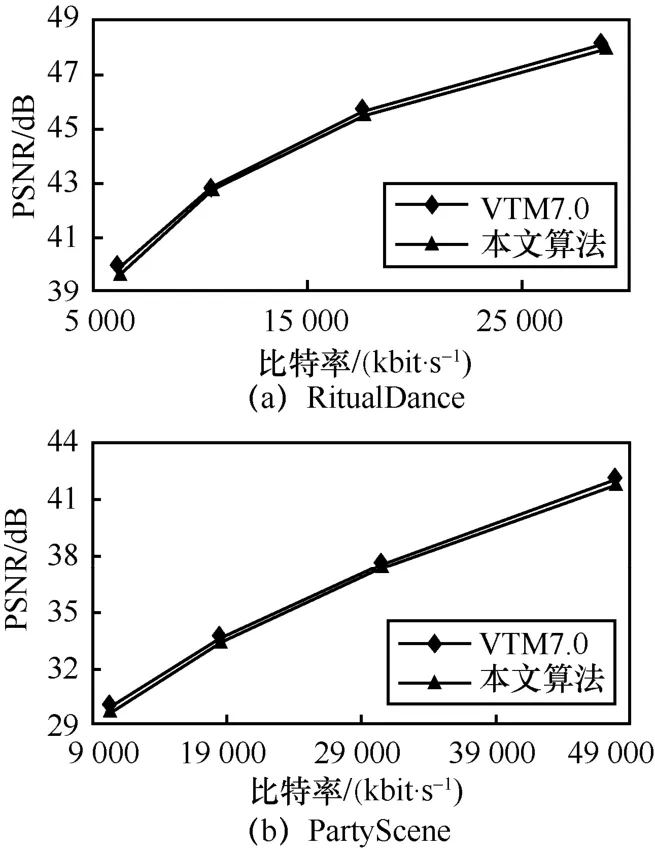
图6 RD 曲线对比
4 结束语
针对VVC 中QTMT 划分结构带来的高编码复杂度问题,本文提出了一种快速QTMT 划分策略,并提供了不同档次的时间节省和性能损失多种组合的灵活调整。首先,提出了基于AA-CNN的模式概率预测模型和快速划分决策模型。然后,为获得平衡编码性能与时间的最佳阈值,建立了对应的代价函数,提出了阈值决策模型。最后,将所提算法整合到VTM7.0 进行实验及分析,并与其他快速算法进行了对比。实验结果表明,本文算法最大平均节省时间达到62.01%。
猜你喜欢
英语文摘(2022年5期)2022-06-05
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
汽车与新动力(2019年5期)2019-11-07
中国惯性技术学报(2019年6期)2019-03-04
疯狂英语·新读写(2018年3期)2018-11-29
海峡姐妹(2017年7期)2017-07-31
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
