
对抗样本生成及防御方法综述
2021-05-16 16:46刘海燕吕涵
现代信息科技 2021年22期
刘海燕 吕涵


摘 要:随着人工智能的不断发展,机器学习在多个领域中取得了很好的应用效果。然而对抗样本的出现对机器学习模型的安全性造成了不容忽视的威胁,导致了机器学习模型的分类准确性降低。文章简述了对抗样本的起源、概念以及不同的对抗攻击方式,研究了典型的对抗样本生成方法以及防御方法,并在此基础上,展望了关于对抗攻击和对抗攻击防御的未来发展趋势。
关键词:机器学习;对抗样本;神经网络;对抗攻击
中图分类号:TP18 文献标识码:A文章编号:2096-4706(2021)22-0082-04
Abstract: With the continuous development of artificial intelligence, machine learning has achieved good application effects in many fields. However, the emergence of adversarial samples poses a serious threat to the security of machine learning models and reduces the accuracy of machine learning model classification. This paper briefly describes the origin, concept and different adversarial attack methods of adversarial samples, studies typical adversarial sample generation methods and defense methods, and on this basis, puts forward the future development trend of adversarial attack and adversarial attack defense.
Keywords: machine learning; adversarial sample; neural network; adversarial attack
0 引 言
人工智能技術促进了新兴技术的快速发展,它的重要驱动力之一就是机器学习算法,机器学习算法已广泛应用于各种领域,如自动驾驶,医疗和恶意软件检测等。但是研究表明,机器学习算法面临着一系列对抗性威胁,影响其安全性问题的关键就是对抗样本。对抗样本的产生使得机器学习模型的分类准确率大大降低,因此,研究对抗样本的生成及防御方法变得尤为重要。而且,由于多数机器学习算法是黑盒模型,其构造的分类模型具有不可解释性,进一步研究对抗样本对于解释机器学习尤其是深度学习算法有所帮助。
2013年,Szegedy等人[1]第一次提出了对抗样本的概念,Goodfellow等人[2]解释了对抗样本的基本原理,证明了高维线性是导致攻击效果显著的根本原因。此后,关于机器学习算法的安全性问题的研究越来越多,包括如何提高对抗攻击的成功率和分类模型的鲁棒性。本文总结了近年来对抗样本生成以及防御方法取得的进展,并简述了其存在的问题以及未来的发展趋势。
1 对抗样本及对抗攻击
1.1 对抗样本的起源和概念
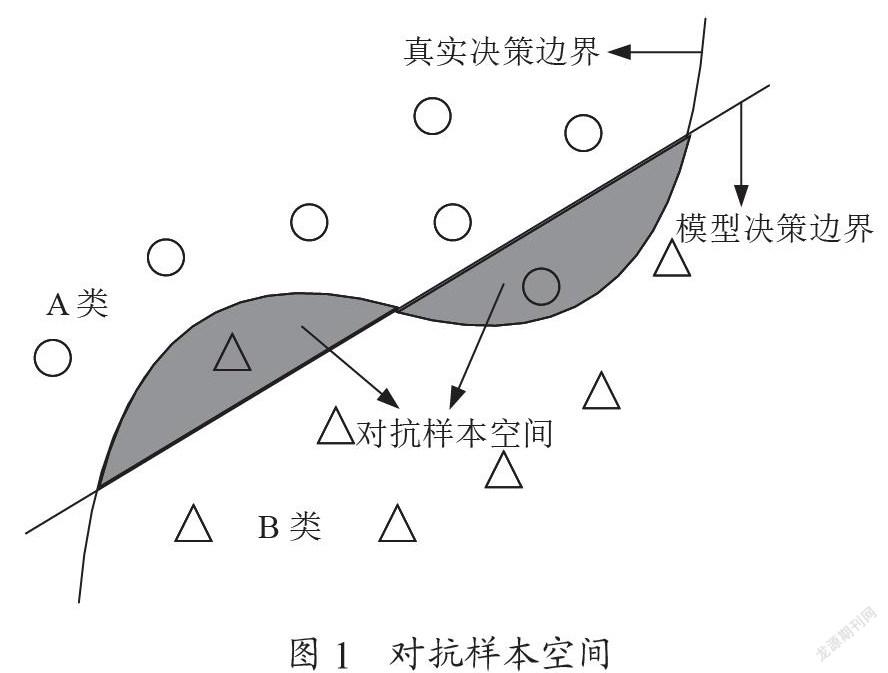
假设决策边界决定样本的分类,如图1所示,A类和B类分别代表不同的样本空间,由于机器学习模型并不能做到覆盖全样本特征,模型决策边界与真实决策边界之间还存在一定差异,这两者之间的差别体现在其相交的区域,即对抗样本空间。
对抗样本是指在原始样本中加入细微扰动并使模型错误分类的一种合成样本。对抗攻击是指用对抗样本攻击分类模型,使其分类的准确性下降。对抗攻击也可以说是对抗样本生成的过程。对抗攻击具有可迁移性,即用针对某分类模型生成的对抗样本攻击其他分类模型。
1.2 对抗攻击的分类
对抗攻击按照不同的分类标准可分为不同的类型:
(1)按照攻击目标的不同,对抗攻击可分为无目标攻击(non-targeted attack)和目标攻击(targeted attack)。无目标攻击是指攻击者使输入样本被分类到任意错误类别;目标攻击是指攻击者使输入样本被分类到指定错误类别。
(2)按照攻击者对模型信息的获取程度,对抗攻击可分为白盒攻击(White-box Attack)和黑盒攻击(Black-box Attack)。白盒攻击是指攻击者掌握目标模型的结构、参数和训练数据等详细信息。黑盒攻击是指攻击者不了解目标模型的关键信息,仅能通过对模型输入样本得到输出信息来推理模型特性。
(3)按照算法的迭代过程,对抗攻击可分为单次迭代攻击和多次迭代攻击。单次迭代算法可以快速生成对抗样本;多次迭代算法攻击效果好但效率较低。
(4)按照攻击的过程不同,对抗攻击可分为投毒攻击、逃避攻击、模仿攻击和逆向攻击。投毒攻击是将生成的对抗样本加入训练数据中,使机器学习模型的分类准确性下降;逃避攻击是指生成能够逃避检测的对抗样本;模仿攻击是指生成与原始样本类似的对抗样本,使模型将其分类为正常样本;逆向攻击是指通过模型预测接口接收信息从而窃取模型信息。
2 对抗样本生成
生成对抗样本的具体方法就是在原样本上添加允许范围内的扰动量,使得修改后的样本在模型上的损失函数最大化(非定向攻击)或最小化(定向攻击),即对抗样本生成算法可以转换成空间搜索的优化问题。在对抗攻击过程中,为了使得对抗扰动无法被察觉,需要计算原始样本与对抗样本之间的距离,来量化样本之间的相似性,通常用L-范数来度量。扰动量的度量计算公式为:
其中,L0,L2和L∞是最常用的样本距离衡量指标。在对抗样本生成方法中,L0是指添加扰动的数量,L2是指原始样本与对抗样本之间的欧几里得距离,L∞是指扰动的最大改变强度。
基于不同的生成特征,常见的对抗样本生成算法可分为:基于梯度信息的攻击如FGSM、JSMA,基于决策边界的攻击如Deepfool,基于优化的攻击如 L-BFGS算法和C&W,基于生成模型的攻击如生成对抗网络。本文介绍的对抗样本生成方法主要是为经典的计算机视觉任务开发的,并且多用于实验研究而非真实场景中,根据典型的数据集如Imagenet、MNIST和CIFAR10来验证各种算法的性能。
2.1 L-BFGS算法
Szegedy等人提出L-BFGS对抗样本生成方法,通过对图像添加少量扰动,使神经网络模型错误输出。该方法通过寻找最小的损失函数添加项来替代复杂的扰动方程求解,将求解最小扰动方程问题简化为凸优化求解问题。L-BFGS算法生成效率较低,可迁移性较差。
2.2 快速梯度符号法
快速梯度符号法(Fast Gradient Sign Method,FGSM)通过在神经网络模型梯度变化最大的方向加入微小扰动使模型错误分类。公式为:
其中,ε是调节系数,sign是符号函数,xL(x,y)是损失函数对x的一阶导数。实验证明,在一张以55.7%置信度被认为是熊猫的图片中加入用FGSM算法生成的扰动后,该图片以99.3%的置信度被认为是长臂猿。FGSM算法仅需一次梯度更新即得到对抗扰动,简单有效,但扰动强度较大且只适用于线性。Kurakin等人[3]提出了基于迭代的快速梯度攻击法BIM(Basic Iterative Method),通过多次小步梯度更新生成对抗样本,可用于非线性目标函数并优化扰动强度。
2.3 Jacobin映射攻击算法
Jacobin映射攻击算法(Jacobin-based Saliency Map Attack, JSMA)通过对原始样本添加有限个特征数量的扰动来构造对抗样本。JSMA算法[4]包括计算分类模型对输入样本的雅可比矩阵、构建对抗显著映射和选择扰动因素三个步骤。其中,雅可比矩阵用来计算输入到输出的特征,通过雅可比矩阵構建对抗显著映射,用来量化特征值对分类器的影响。每次只改变影响最大的一个特征的值来生成对抗样本,就可以在给出尽可能小扰动值的条件下实现对抗攻击。原始样本与对抗样本的距离由0-范数来计算,修改特征数量最少的即为期望扰动向量。扰动向量公式为:
其中,Δδ为期望扰动向量,δ为任意扰动向量,f为分类器,x为原始样本。此公式表示在攻击成功的条件下,找到0-范数最小的扰动向量δ。实验证明,在改变原始样本4%的特征时,JSMA算法的对抗成功率可以达到97%。JSMA算法攻击成功率较高,但由于计算复杂使生成效率较低。
2.4 深度欺骗攻击
深度欺骗攻击(Deepfool)通过计算原始样本与对抗样本的决策边界的最小距离得到扰动大小。它根据损失函数迭代生成满足条件的扰动向量,迭代一次增加一个指向最近决策边界的扰动向量,直到对抗样本跨越决策边界。原始样本与对抗样本的距离用2-范数来衡量,欧式距离最短的即为期望扰动向量。在线性二分类模型f(x)中,添加的最小扰动为原始样本x到分割超平面F={x:ωT · x+b=0}的正交投影。扰动向量公式为:
其中,Δδ为期望扰动向量,δ为任意扰动向量,f为分类器,x为原始样本。此公式表示攻击成功的条件下,找到2-范数最小的扰动向量δ。与FGSM相比,DeepFool能够计算出更小的扰动,同时具有类似的对抗性,但它无法将分类器误导至指定类别。
2.5 C&W
Carlini和Wagner等人[5]提出了针对防御性蒸馏的C&W攻击(Carlini and Wagner attacks),它包括L0,L2和L∞三种范数形式的约束。通过实验对比,L2范式下的C&W攻击能力最强。C&W攻击对现有的多数深度学习模型能达到很好的攻击效果,对比 L-BFGS、FGSM、JSMA 和 DeepFool攻击,C&W的攻击效果更强,但为了找到约束扰动的合适的参数导致效率较低。
2.6 边界攻击
Brendel等人[6]提出一种黑盒攻击方法——边界攻击(Boundary Attack),其针对目标分类器的分类结果进行攻击。该方法首先找到一个初始对抗样本,然后通过特定的搜索迭代方法逐渐找到决策边界上与原始样本最近的对抗样本,并保证扰动小于阈值且对抗样本依然具有对抗性。该方法只依赖模型最终决策信息的攻击方法较为简单,但由于其对模型访问次数巨大造成效率较低。基于此,Boundary Attack++对该算法进行优化,大大提高了该算法的效率。
2.7 生成对抗网络
基于生成模型的对抗样本生成方法,通过抽取原始样本学习其概率分布,从而生成与原始样本分布相同而又不完全相同的样本。Goodfellow在2014年提出生成对抗网络(GANs),它由生成模型G和判别模型D两部分组成。生成模型学习真实数据分布生成伪数据,判别模型区分真实数据和生成数据。生成对抗网络通过生成模型和判别模型的不断对抗和优化,最终达到纳什均衡。实验证明,利用生成对抗网络构造的对抗样本,在有防御的情况下具有较高的攻击成功率。
表1列举了不同的对抗攻击方式,按照攻击类型、攻击目标、攻击频次、扰动范围、攻击强度、特点以及应用场景这几个方面进行了对比。
3 对抗样本防御
对抗攻击防御就是针对不同对抗攻击设计不同防御方法,使分类模型将对抗样本正确输出,或使生成的对抗样本的成功率显著降低。现有的对抗样本防御方法主要分为两大类,修改数据和修改网络结构。
3.1 基于数据修改的防御方法
这类方法主要通过对输入数据进行预处理来检测出对抗样本并剔除,或将对抗样本加入训练集加强训练来提高模型鲁棒性。
3.1.1 對抗训练
在迭代训练中,将生成的对抗样本加入到训练集中进行训练,加强深度神经网络模型在对抗环境下的鲁棒性。但单步对抗训练可能会导致模型过拟合。使用集成对抗训练,将不同模型生成的对抗样本进行再训练,可以增强模型面对黑盒攻击时的鲁棒性。
3.1.2 特征压缩
特征压缩通过去除不必要的输入特征来进行压缩,当模型对压缩数据的预测与对原始数据的预测结果的1-范数差大于设定值,即认为它是对抗样本。实验证明,特征压缩能防御FGSM、Deepfool、JSMA和C&W攻击。特征压缩是一种对抗攻击检测方法,可与其他防御方法相结合。
3.1.3 数据随机化处理
随机调整对抗样本的大小或添加一些高斯随机化处理。基于随机调整大小和填充的对抗防御机制,通过输入变换消除扰动,同时可以在预测阶段修改输入数据,使得损失梯度难以计算。这种防御机制能与其他防御方法结合使用。
3.2 基于网络模型修改的防御方法
面对人眼无法察觉的小型扰动,深度学习模型更容易受到其影响而错误输出。通过改变或隐藏模型的结构,能够提高神经网络模型面对小扰动的鲁棒性。
3.2.1 梯度正则化或梯度隐藏
针对可微分模型进行输入梯度正则化,通过惩罚输出相对输入变化的变化幅度,从而达到隐藏梯度的目的,来提高神经网络模型的鲁棒性。这表明小型扰动不能够大幅改变训练模型的输出。实验证明,梯度正则化与对抗训练相结合,可以很好的防御FGSM和JSMA攻击。
3.2.2 防御性蒸馏
防御性蒸馏是针对神经网络模型产生的对抗样本而提出的防御方法,它的基本思想是将在复杂模型中学习的“知识”作为先验传递到简单模型中去,从而降低神经网络的梯度,有效防御基于梯度的小型扰动攻击。这种方法面对FGSM和JSMA攻击时具有很好的鲁棒性,但不适用于C&W等较强攻击方式。
3.2.3 生成对抗网络
生成对抗网络利用生成器和判别器两个网络交替训练,既可以检测对抗样本,又可以提高模型的鲁棒性。实验证明,该方法可以提高目标网络模型对原始图像以及添加扰动的图像的识别准确率。
4 结 论
机器学习的发展促进了各个领域向智能化的转变,但对抗样本的存在对机器学习技术尤其是深度学习带来了极大的安全挑战,研究对抗攻击是为了帮助网络模型更好的抵御恶意攻击,训练出更加稳健的模型。当前对于对抗样本的研究仍有许多问题亟待解决,进一步研究对抗样本,对于深度学习原理性解释以及人工智能安全具有重大意义。
对抗攻击的提出源于研究深度学习在计算机视觉中的应用,后经过大量研究与发展,对抗攻击的应用已扩展到恶意软件检测、语音识别和自然语言处理等领域。
本文简述了对抗样本的概念及原理,介绍了经典的对抗攻击方法及防御方法。现有的对抗攻击的研究从梯度攻击发展到决策攻击,所需的信息量越来越少,满足了攻击者很难获取到模型具体信息的现实情况。尽管对抗样本算法已取得较大进展,但在计算成本和攻击稳定性方面仍有不足。未来对于攻击性更强更稳定的黑盒攻击将是研究的重点。
对抗攻击的防御方法,理论上修改网络结构能达到更好的防御效果,然而这种方法针对性较强且成本较高。在实际应用中,多使用修改数据和添加网络工具的防御方法,可以应用在不同模型中,更具有泛化性。未来可能会采取不同防御方法相结合的方式来防御对抗样本攻击。现有的对抗攻击防御方法多是针对特定的已知攻击算法有效,泛化性较差。此外,对抗样本防御方法缺乏系统的评估机制,很多防御方法仅通过小型数据集进行实验,测试效果不够严谨。未来这方面的研究重点是建立一个有效防御对抗攻击的系统化防御机制。
参考文献:
[1] SZEGEDY C,ZAREMBA W,SUTSKEVER I. Intriguing properties of neural networks [J/OL].arXiv:1312.6199 [cs.CV].(2013-12-21).https://arxiv.org/abs/1312.6199.
[2] GOODFELLOW I J,SHLENS J,SZEGEDY C. Explaining and Harnessing Adversarial Examples [J/OL].arXiv:1412.6572 [stat.ML].(2014-12-20).https://arxiv.org/abs/1412.6572v3.
[3] KURAKIN A,GOODFELLOW I,BENGIO S. Adversarial examples in the physical world [J/OL].arXiv:1607.02533 [cs.CV].(2016-07-08).https://arxiv.org/abs/1607.02533v1.
[4] 刘会, 赵波, 郭嘉宝, 等. 针对深度学习的对抗攻击综述 [J].密码学报, 2021, 8(2): 202-214.
[5] CARLINI N,WAGNER D. Towards Evaluating the Robustness of Neural Networks [J/OL].arXiv:1608.04644 [cs.CR].(2016-08-16).https://arxiv.org/abs/1608.04644.
[6] BRENDEL W,RAUBER J,BETHGE M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models [J/OL].arXiv:1712.04248 [stat.ML].(2017-12-12).https://arxiv.org/abs/1712.04248.
作者简介:刘海燕(1970—),女,汉族,北京人,教授,博士,研究方向:信息安全与对抗技术;吕涵(1993—),女,汉族,江苏连云港人,硕士研究生,研究方向:信息安全与对抗技术。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年11期)2022-08-22
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
软件(2017年6期)2017-09-23
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
