
基于共词分析的国内文本挖掘研究*
2021-05-15 06:48:44宋卓远阚乾超陈镱尹杨云帆杨秀璋罗子江
图书馆学刊 2021年4期
关键词:出版社
宋卓远 阚乾超 赵 凯 陈镱尹 杨云帆 杨秀璋 罗子江
(贵州财经大学信息学院,贵州 贵阳550025)
在信息迅速发展的时代,人们从以往对信息数量的需要转变为对信息质量的需求,而之前较少被人们注重的文本内却包含着海量潜在价值。文本的来源多种多样,有书本、论文、期刊、新闻、邮件、各类网络评论、聊天记录和社交媒体数据等,这些都和人们的生活息息相关。因此对文本进行有效挖掘具有重要价值。
文本挖掘主要是从诸多复杂的文本数据中发掘隐形的、有用的数据模式、内在关联、规律、发展趋势等,从而被个人、企业和机构等进行有效利用[1]。文本挖掘涉及多个领域,可以辅助相关领域的研究,如杨亚楠等[2]基于多视图协同的方式,对政策文本背后规律进行深入分析,证明了该技术框架的有效性;沈健等[3]提出一种基于文本挖掘的生物领域实例获取方法,提高了该领域的文本检索效率;张坤等[4]采用文献计量、社会网络分析等方法,对智慧图书馆文献的外部及内部特征进行分析,并揭示其学科特色和整体格局;李梦杰等[5]利用LDA模型和聚类算法,对某互联网教育平台中课程信息进行研究,有效挖掘出学员所选课程背后隐含的关注点和兴趣点;余本功等[6]基于机器学习和主题模型,对专利摘要进行内容挖掘,并构建出技术创新评价体系;戴德宝等[7]将文本挖掘和机器学习应用到股票数据的分析中,有效提高股指走势预测的精度。
以上皆是对文本挖掘领域的具体研究,然而国内学者对该领域的整体研究还相对较少,陈红琳等[8]虽然通过共词分析等方法对国内文本情感分析的研究成果进行热点分析和趋势预测,但未能揭示文本挖掘在其他研究方向的进展状况。谭章禄等[9]采用聚类分析和卡方统计等定量化方法对国内文本挖掘文献进行主题分析,该研究方式较为单一,很难全面挖掘出关键词间的联系及各主题的动态演化过程。针对以上问题,笔者提出一种基于共词分析的方法,通过构建矩阵发掘高频关键词间的相互关联,有效确定当前研究热点;利用层次聚类算法对各主题词进行计算,并划分成不同的研究主题,明确文本挖掘领域主要的研究方向;借助知识图谱等可视化技术使分析结果直观展现,利于研究者梳理该领域各主题的发展脉络及更好预测未来趋势。
1 数据和方法
1.1 数据来源与预处理
笔者数据爬取自中国知网期刊数据库,于2019年6月6日,以“文本挖掘”为检索主题,设定“核心期刊+CSSCI”为来源类别,对数据库进行精确检索,共获得相关文献627篇。经人工筛选,剔除会议通知、重复和信息缺失等无效文献,实际得到有效文献556篇。
1.2 研究方法
笔者主要基于共词分析法对文献数据进行研究,总体思路如图1所示。
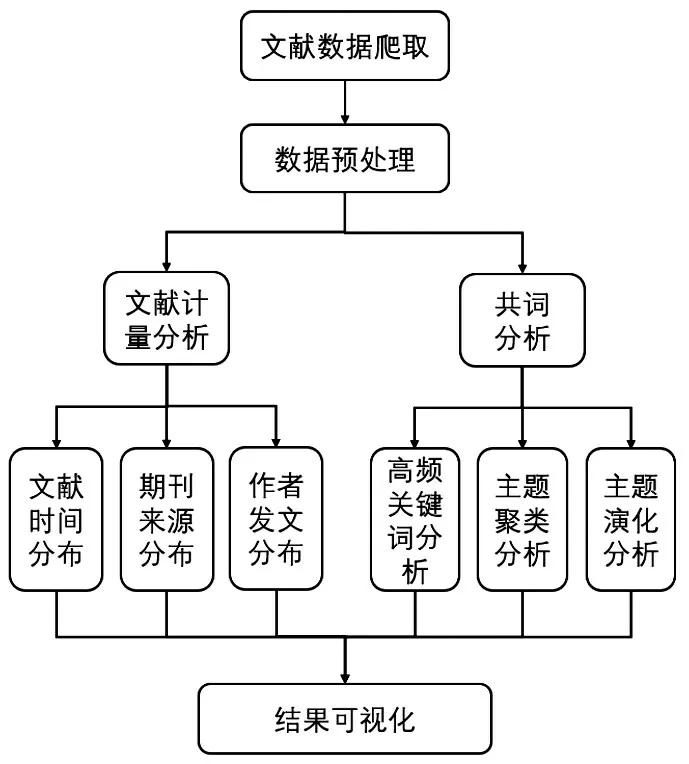
图1 文本挖掘研究思路
具体研究步骤如下:
(1)通过Python技术完成文本挖掘文献的爬取,并保存至本地,获得数据包括文献标题、作者、关键词、发表年份、出版社、引用次数、下载次数和摘要8个特征;
(2)对所获的文献数据进行人工预处理,剔除无效数据71篇,最后共得556篇有效文献;
(3)利用Excel、Ucinet软件对已处理数据进行文献计量分析,包括文献时间分布、期刊来源分布和作者发文分布3个方面的研究;
(4)使用Python抽取文献关键词,并对其中高频关键词构建共现矩阵、相似矩阵和相异矩阵;
(5)采用共词分析法实现高频词共现、主题聚类、主题演化等研究,并借助Gephi软件和Python技术使分析结果可视化。
2 文献计量分析
2.1 文献时间分布
对文献数量年分布进行统计分析,结果如图2所示。我国从1998年开始就有学者对文本挖掘进行过相关研究[10],此时正值该领域探索阶段。2000年至今文献量迅速增加并总体呈幂指数上升趋势,用函数Y=1.499X1.1731拟合文献曲线,拟合度R2=0.9172,表明拟合函数基本符合文献实际发文情况,也间接反映出未来与文本挖掘相关的文献还将继续增加。同时,从文献的累积量看,可用曲线Y=1.4112X2-3.3338X+10.036拟合,R2=0.9971,拟合程度良好,此趋势线正处于抛物线的上升区间,意味着文本挖掘的研究进入黄金发展期,有很大前景。
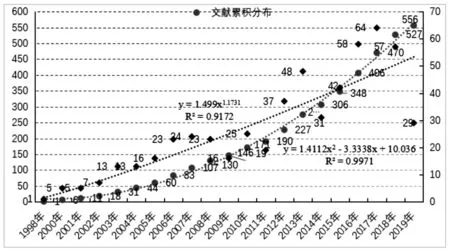
图2 文献时间分布
2.2 期刊来源分布
据统计,556篇文本挖掘论文分布于191种期刊中,平均每种期刊载文2.91篇。表1列出期刊载文量不少于5篇的所有期刊,其中《情报杂志》载文量最多,共刊载30次;《计算机研究与发展》总引用量最多,5篇文献共被引用858次。依据布拉德福期刊划分定律[11],将期刊按其载文量降序排列并大体均分为3个区:核心区(9种期刊、190篇论文)、相关区(34种期刊、193篇论文)和边缘区(148种期刊、173篇论文)。其中,核心区每种期刊载文量大于13篇,相关区每种期刊载文量3至6篇,边缘区每种期刊载文量1至两篇。3个区域内期刊数量之比(9:34:148)近似满足1:a:a2的规律,可推算出布拉德福系数a≈4。
对每个区域分析发现,34.17%的论文约占期刊总数的4.7%,68.9%的论文约占期刊总数的22.5%,这折射出研究文本挖掘的文献主要分布在少数期刊。这些期刊集中于3个学科领域,分别为图书情报领域、计算机领域和生物医学领域,即当前文本挖掘的热门领域。
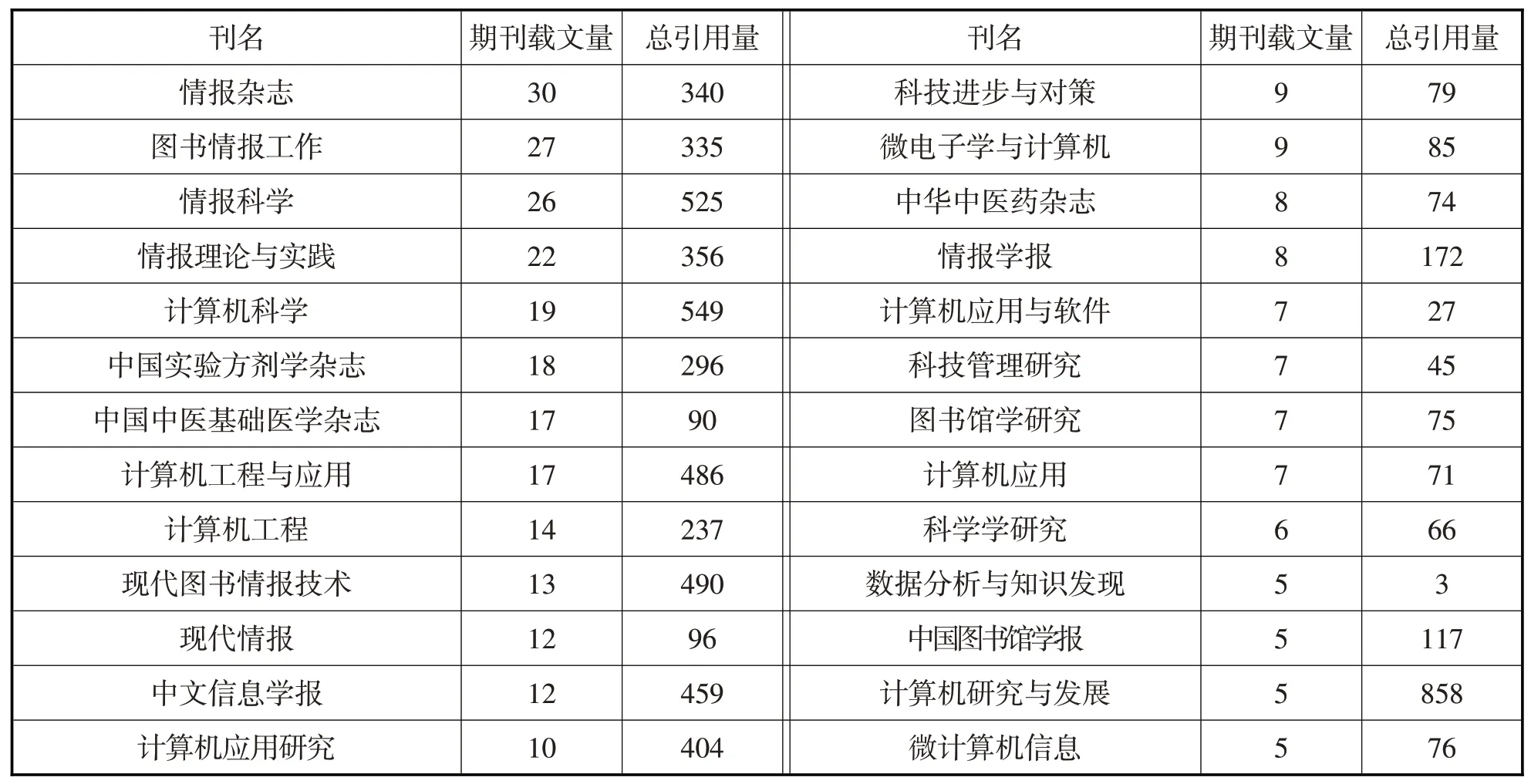
表1 期刊来源分布(载文量≥5)
2.3 作者发文分布
经统计分析,数据中发文量不少于3篇的作者有47人,用软件Ucinet对其绘制作者合作网络图谱,如图3所示。图中,方块代表发文作者,连线表示作者间的合作关系,每种颜色对应不同发文量,其中紫色代表发文量大于12的作者,红色表示发文量为7至12篇的作者,绿色表示发文量在5至6篇的作者,黄色和蓝色分别表示作者发文量等于4和3。
图3中可知,本领域作者分布稀疏,表明大多作者基本是在独立研究。3人以上团队仅有3个,其中以郑光、吕爱平为首的团队合作规模最大,主要研究文本挖掘在生物医学方面的应用,代表著作有《基于文本挖掘技术初步探讨雷公藤应用相关的生物学基础》《基于文本挖掘方法探索糖尿病中医养生理论与方法的规律》;肖卫东团队主要对多文本的比较性话题进行研究,该团队曾提出一种PCCMix混合模型,有效解决了公共话题和特有话题的识别问题[12];汪雪锋团队以语义挖掘和主题词簇的研究为主,并提出一种以SAO为主的形态识别方法,弥补了基于关键词方法的不足[13]。

图3 作者合作网络
3 共词分析
3.1 高频关键词分析
关键词是论文主要内容的高度浓缩和概括,能够反映论文的研究主旨或方法等内容。其中高频关键词能很大程度代表该论文研究领域中的研究热点,有助于学者对该领域目前及未来的研究方向更好地把握。研究前,笔者对关键词进行合并、删除等预处理操作[14],如将“文本挖掘技术”“文本挖掘”和“网络文本挖掘”等近义词合并为“文本挖掘”;删除部分对研究无价值的关键词。统计显示556篇论文共涉及1248个关键词,其总频数为2326,平均每个关键词频数为1.864。为便于研究,文中仅截取词频不低于5的50个高频关键词给予分析(见表2),这些关键词词频总和为936,占所有关键词的40.24%,高于知识图谱构建规定的27%[15],达到分析标准。
从表2中可知,“文本挖掘”词频最高,达433次;“文本聚类”“文本分类”“领域本体”“信息抽取”“主题模型”等词的频数也较高,这在一定程度上反映出文本挖掘领域较多注重挖掘方法、技术和相关模型的研究。

表2 高频关键词统计
3.2 关键词共词分析
高频关键词虽能一定程度上反映研究领域的热点主题,但无法揭示高频词与主题间的相互关系及动态变化。因此,文中采用共词分析法构建一个50×50的高频词共现矩阵,如表3所示,表中对角上数值表示高频关键词的词频,其他区域内数值表示行列分别对应的高频词共同出现在一篇论文中的次数。其矩阵构建规则如公式(1)所示:

式(1)中n为两两关键词的共现次数;wi为第i行对应的关键词;wj为第j列对应的关键词。
为了消除共现矩阵内数值差异较大带来的影响,笔者采用皮尔逊相关系数法将其转换成数值在[0.1]间的相似矩阵,如表4所示,表中值越大,则说明两词间相关性越紧密,反之相关性越小。
在后续的层次聚类分析中,相似矩阵内过多的0值会干扰实验结果,有必要用1减去相似矩阵内各数值,从而得到相异矩阵,计算结果如表5。
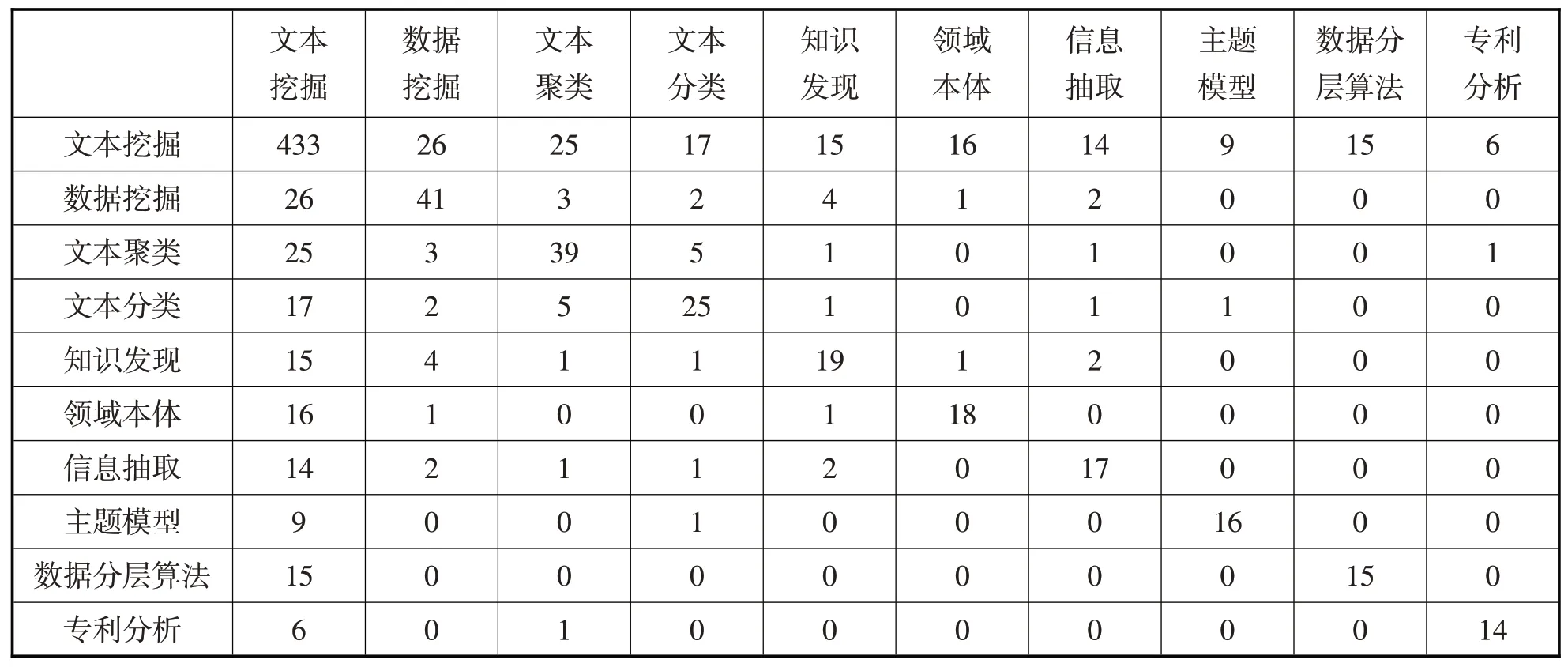
表3 高频词共现矩阵(部分)

表4 高频词相似矩阵(部分)
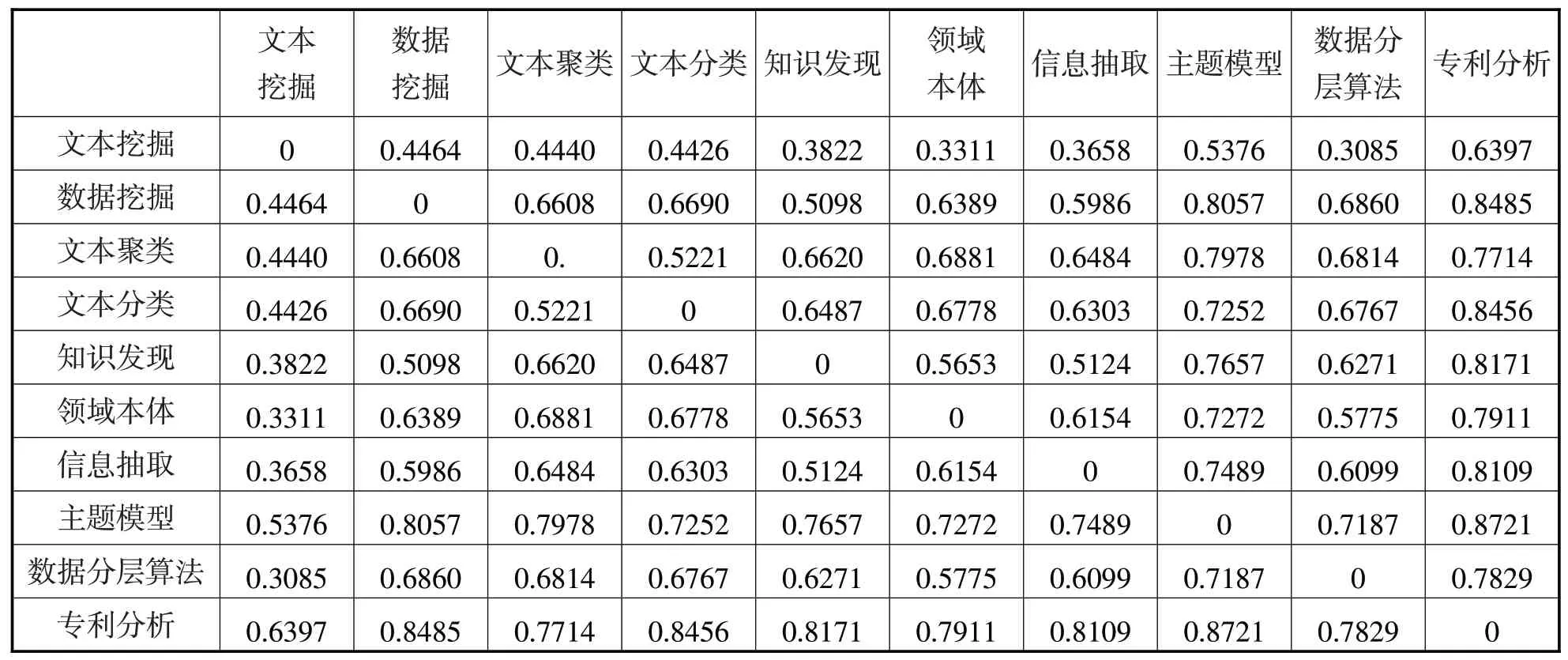
表5 高频词相异矩阵(部分)
3.3 高频关键词共现知识图谱
借助Gephi软件根据表3绘制文本挖掘高频关键词共现知识图谱,结果如图4所示,图中圆圈代表关键词,其大小为词频高低,连线代表词间的共现关系,线的粗细表示词共现频次高低。图4显示,位于中心位置的是“文本挖掘”,和周围“数据挖掘”“文本聚类”“文本分类”“情感分析”和“知识发现”等词共现较多,联系紧密,表明这些词共同形成了整个图谱的主体结构,即文本挖掘领域的热点内容。其他关键词逐渐向边缘地带扩散,连线变细,词间联系渐少,说明这些研究点关注度较小,还尚处在发展阶段,但同时也意味着可能会有很大的研究空间。
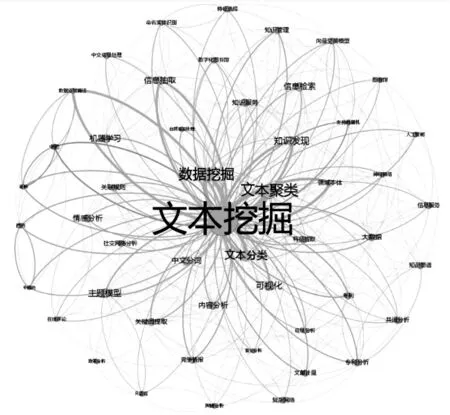
图4 高频关键词共现知识
3.4 主题聚类分析
主题层次聚类是一种依据变量间距离和相似性将高频关键词自动分类的技术。文中调用Python对高频关键词的相异矩阵进行聚类分析,算法中method和metric参数分别选用ward和euclidean。其中欧式距离(euclidean)的计算公式如下:
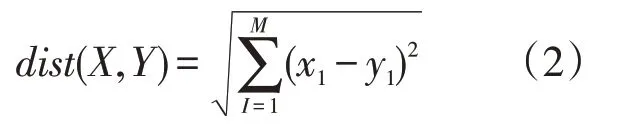
式(2)中dist(X,Y)表示X和Y两点间的欧式距离;m表示空间维度,这里取值为2;xi表示X点的第i维坐标;yi表示Y点的第i维坐标。
聚类结果如图5所示,横坐标轴为各类别间的距离,纵坐标轴为各主题高频词。图中显示出国内文本挖掘主题形成了4个类别:第一类为人工智能下的知识管理,包括“人工智能”“自然语言处理”“机器学习”“知识管理”“知识服务”等关键词;第二类为挖掘技术及算法研究,包括“语义分析”“命名实体识别”“神经网络”“情感分析”“特征提取”“文本分类”“文本聚类”等关键词;第三类为生物医学,包括“证候”“中药”“数据分层算法”“中成药”“西药”等关键词;第四类为文本挖掘应用研究,包括“舆情分析”“政策分析”“图书馆”“专利分析”“知识图谱”等关键词。

图5 文本挖掘主题聚类分析
3.5 主题演化分析
为更好地把握文本挖掘领域热点主题的动态趋势,对556篇论文的时间和高频词绘制主题演化趋势图谱,如图6所示。图中将论文时间划分成3个阶段:(a)1998-2006年、(b)2007-2012年、(c)2013-2019年。从中可知:
(1)总体情况:从各阶段的网络节点及密度可以看出,第一阶段节点数较少且分布稀疏,最后阶段节点规模最大且分布密集,主题热点数总体呈上升态势,表明了文本挖掘领域的整体发展状况。其中各阶段热点均有变动,如2006年之前主要热点有“文本挖掘”“数字化图书馆”“知识发现”“信息检索”等;2007-2012年主要热点有“文本挖掘”“机器学习”“领域本体”“中药”等;2013-2019年主要热点有“文本挖掘”“情感分析”“知识图谱”“大数据”等。但是各个阶段的年节点都以文本挖掘为中心发散分布,这说明以文本挖掘为主的聚类、分类等主题一直是该领域的主要研究内容,具有较好的延续性。
(2)各阶段情况:第一阶段皆为新兴主题,正值文本挖掘领域探索阶段,其中“图书馆”“信息检索”“知识发现”等词出现年份较早,表明该阶段研究主要源于图书馆现状解析,较为贴近实际。
第二阶段中“机器学习”“命名实体识别”“中药”等主题开始出现,其中值得注意的是,“中药”“西药”“中成药”“证候”等主题词集中出现于2011至2012年,表明该时期文本挖掘在生物医学方面的研究受到广大学者的重视。相较于第一阶段,“信息抽取”“中文信息处理”“专利”“可视化”等节点变大,反映出这些主题处于成长状态,相关内容及技术的研究增强了人们提取信息的能力。而“自然语言处理”“人工智能”“竞争情报”等节点没明显变化,热点持续较低,态势平缓,有待发展。
第三阶段,主题数量迅速增加,增长率远超前两个阶段,各主题间关系也越为紧密、复杂。此阶段的新兴主题有“大数据”“知识图谱”“情感分析”“主题模型”等,究其原因,可能是近年以来4G普遍及5G兴起的缘故。和前两个阶段相比,“社交网络分析”“专利”“竞争情报”等主题快速发展起来,表明其研究领域在不断成熟,其中“专利”类主题3个阶段均有存在,演化最为持久。同时,“中成药”“证候”等生物医学方面的主题节点逐渐变小且仅在2013至2014年间出现过,说明该类主题热度在不断下降直至消失,虽然在个别年份受到较大关注,但延续性较差,没有得到进一步发展,属于消亡主题。此外,2015到2019年,“自然语言处理”及“人工智能”类主题继续沿之前态势发展,持续时间较为长久,表明未来极有可能成为热点。

图6 主题演化趋势图谱
4 结语
笔者提出一种共词分析和文献计量相结合的方法,对国内文本挖掘的相关文献进行挖掘和计量。通过构建高频关键词共现知识图谱和主题层次聚类揭示和分析国内文本挖掘领域的核心主题和研究热点。同时,文中将文献按时间分为3个阶段,利用共词分析对每阶段主题详尽分析,并借助有关工具对结果进行可视化展现,大致理清该领域的总体发展状况和各主题的演化过程。实验结果发现,本研究方法能够有效洞悉文本挖掘领域的研究现状及进展,发掘关键词和主题间的动态关系,为未来研究提供一种新的视角和参考依据。
猜你喜欢
科教新报(2024年4期)2024-03-17 09:48:21
燃料化学学报(2022年11期)2022-12-14 07:23:18
绿色环保建材(2021年4期)2021-04-25 09:47:18
读者(2021年5期)2021-02-05 02:52:39
华人经济(2017年6期)2017-08-18 04:10:14
校园英语·下旬(2017年1期)2017-03-15 11:55:37
少年博览·小学低年级(2016年7期)2016-11-23 20:15:41
卷宗(2015年11期)2015-12-19 18:59:49
全国新书目(2014年7期)2014-09-19 20:45:40
全国新书目(2014年7期)2014-09-19 16:00:53
